




Pixel5
Members
-
Joined
-
Last visited
-
this problem still exists and happens on a regular basis sadly.
-
Hello People. im on 6.12.2 right now and along with the problem i posted about here i also have the problem that any time i restart my server it will start a parity check because of an unclean shut down. this never happened on previous unraid versions and the server is in fact restarting without any problems at all except for that parity check starting.
-
soo i guess nobody has any idea whats going on here?
-
Hello People, i have the problem with my unraid setup that some of my disk suddenly dont want to spin down and only a reboot fixes the issue. This happens randomly with 2 - 4 of my 6 disks and theres no logic as to which one does it as which time, they are all running for something at one point and some of them just refuse to spin down afterwards. This is NOT related to anything accessing the disks, they are completely idle with nothing going on, click on spin down and checking the logs shows that the disks that stay active are not even getting a spin down command at all. right in this moment i have 4 of my disks spun up that can not be spun down no matter what and i have no idea why this keeps happening. thevault-diagnostics-20230801-1157.zip
-
does anyone else have the issue that Filebot will always physically move files when it renames them via the AMC script? if i use the UI its just instantly doing its actions but when the AMC script runs i can see it reading and writing the file to the same SSD which obviously takes forever.
-
can confirm the last update broke everything. [amc ] # [amc ] # A fatal error has been detected by the Java Runtime Environment: [amc ] # [amc ] # SIGSEGV (0xb) at pc=0x000014a1e2331030, pid=842, tid=844 [amc ] # [amc ] # JRE version: OpenJDK Runtime Environment (17.0.6+10) (build 17.0.6+10-alpine-r0) [amc ] # Java VM: OpenJDK 64-Bit Server VM (17.0.6+10-alpine-r0, mixed mode, sharing, tiered, compressed oops, compressed class ptrs, g1 gc, linux-amd64) [amc ] # Problematic frame: [amc ] # C [libmediainfo.so+0x131030] ZenLib::BitStream_LE::Get(unsigned long)+0x50 [amc ] # [amc ] # No core dump will be written. Core dumps have been disabled. To enable core dumping, try "ulimit -c unlimited" before starting Java again [amc ] # [amc ] # An error report file with more information is saved as: [amc ] # /tmp/hs_err_pid842.log [amc ] # [amc ] # If you would like to submit a bug report, please visit: [amc ] # https://gitlab.alpinelinux.org/alpine/aports/issues [amc ] # The crash happened outside the Java Virtual Machine in native code. [amc ] # See problematic frame for where to report the bug. [amc ] #
-
none of that is really an issue though as long as you follow the basic security measures of not exposing your unraid server to the internet. there are millions of systems out there running on windows 98 or XP that didnt get patched in decades simply because they will never be exposed to the internet.
-
my mariaDB is stuck in a boot loop now, is anyone else having this problem after the lastest update? 211026 11:00:22 mysqld_safe Starting mariadbd daemon with databases from /config/databases
-
the problem is already evident in your comment, you say crypto currency because you dont want to imply using a certain one. Problem is there are a bazillion crypto currencies now and whenever you start accepting one people will spam around why Doge coin is accepted by Shiba Inu coin is not Then you also need a service in between that updates the pricing as crypto currencies are far from stable so you usually end up with a payment provider which defeats the purpose of using crypto in the first place. Then you also need to convert that crypto back to FIAT currency as crypto usually isnt accepted to pay the bills so they need a tax guy to handle this stuff on top of the usual stuff. Same for customers, depending on where you are buying something with your crypto could be a realized gain which is then taxed so you need documentation to track all this for tax season. Overall its just one giant effort for a relatively small group of people who if they would practice what they preach not use cryptos anyways because they will HODL forever.
-
Hello People, i have a problem that my share are becoming very unresponsive and slow completely randomly which can only be fixed via a restart or just waiting for i dont know what to do its thing. i have yet to find out whats going on here but its always the same process thats going hard on the CPU but generally there is almost nothing going on on the server while this problem persists. As you can see htop shows the process that pegs the server and IO top shows basically nothing. The docker tab shows 0.3% CPU load on the most demanding container and stopping all docker containers does not fix this problem. i already tried to remove the folder caching plugin but the problem still happened when the plugin was gone. All disks are spun down, nothing is going on except for tiny amounts of data being moved on the cache drives. Logs are clean as well. does anyone have any idea whats going on here? thevault-diagnostics-20210731-1607.zip
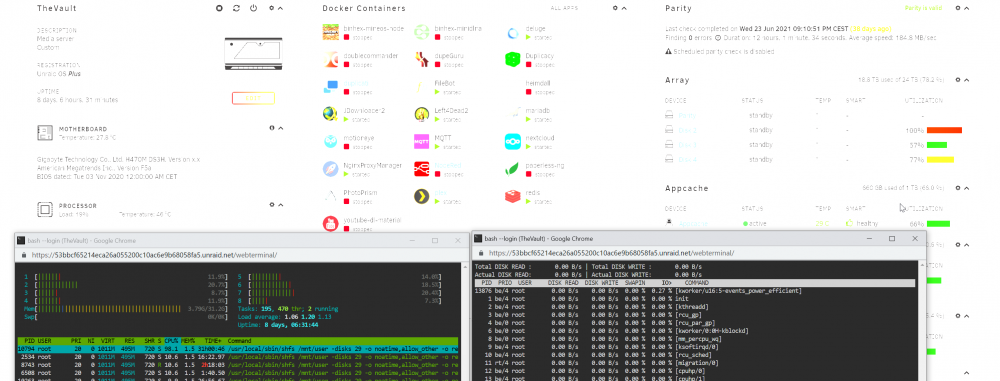
-
is there any chance to get a Wreckfest server running via SteamCMD?
-
i have solved this problem now with the help from some people on the unraid subreddit. the problem was that allowed IP´s needed to contain 0.0.0.0/0 in order to route all traffic through the VPN.
-
im having some issues getting all my traffic routed through my unraid server. I can connect both from my laptop and my phone to via VPN to the unraid server without any issues when its set to remote tunneled access but it seems like not all my traffic is routed through the server as my ip address on my phone and my laptop does not change at all. This was very annoying in the last two weeks as i wanted to use my VPN to make netflix think im still in my home country but it never worked. does anyone have any idea whats going on here?
-
it took about a day of 100% CPU usage and now it is synced so that is working fine now. Problem is anything that i plot on my NAS using the same mnemonic seed does not show up in the GUI on my main PC its all listed under plots not found for some reason. Someone said its related to that my Chia instance in docker has a different private key then my main rig but i though the mnemonic was supposed to make sure that doesnt happen. the big question is now what can i do to make everything use the same private keys and preferably do so without losing any plots? The chia on the unraid system can see all plots just fine for some reason but there also seem to be two wallets here.
-
im currently doing nothing with my Chia install on my unraid system and its basically pegging the CPU at 100% is this because its syncing or is something wrong here?



