paululibro
Members
-
Joined
Everything posted by paululibro
-
I fixed it. Since mailing list and other forums were of no help I tried finding the solution myself. I figured that if I can't bring xfsprogs to my drive, I will bring the drive to xfsprogs. I had an old OptiPlex laying around so I installed the latest version of Arch Linux which had xfsprogs 5.18 available. Since it only had one power cable I had to power my drive from another PSU while connected through SATA to the OptiPlex. First run of xfs_repair -nv /dev/sdb1 ended with Segmentation fault. I then created metadata dump of the filesystem with: xfs_metadump /dev/sdb1 /home/p/metadump.meta xfs_mdrestore /home/p/metadump.meta /home/p/metadump.img and verified it with: xfs_repair -nv /home/p/metadump.img Test run on the image was successful so I ran xfs_repair -vL /dev/sdb1 (-L flag was required) and the program finished without any errors. I moved the drive back to my server and everything works fine again. I also had one machine with Fedora on it with xfsprogs 5.14.2 and it was giving the same assertion failed error as 5.13
-
This package wasn't updated from 5.13 in almost a year. Would it be possible to build 5.18 from source files on unRAID?
-
Where did you get 5.14.2 from? slackware64-current only lists xfsprogs-5.13.0-x86_64-3.txz as current. I've also found xfsprogs-5.18.0 is the latest (?) version
-
root@Orion2:~# xfs_repair -V xfs_repair version 5.13.0 It only crashes on md3. I tried running it on other drives and it was completing and exiting with no errors
-
Still getting the same error after updating to 6.10.2. I've used xfs_repair on 6.9.2 a few times and it was working fine before EDIT I've also found this thread with the same error message (there are only two threads with it, including mine) but I don't see anything there that would help me
-
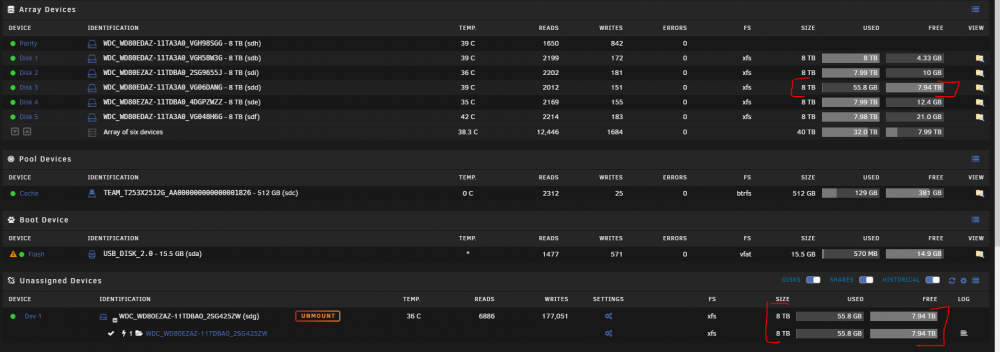
One of my drives was showing as unmountable so I started the array in the maintenance mode and ran "xfs_repair -nv /dev/md3" but got this error: Phase 1 - find and verify superblock... - block cache size set to 305128 entries Phase 2 - using internal log - zero log... zero_log: head block 1124625 tail block 1124610 ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... agf_freeblks 5759502, counted 5759493 in ag 0 agi_freecount 62, counted 61 in ag 0 agi_freecount 62, counted 61 in ag 0 finobt sb_fdblocks 27013023, counted 40637666 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 1524704c7700: Badness in key lookup (length) bp=(bno 0x2217a80, len 16384 bytes) key=(bno 0x2217a80, len 4096 bytes) imap claims in-use inode 35748416 is free, correcting imap data fork in ino 35748420 claims free block 4468551 imap claims in-use inode 35748420 is free, correcting imap data fork in ino 35748426 claims free block 4468550 imap claims in-use inode 35748426 is free, correcting imap data fork in ino 35748433 claims free block 4468549 imap claims in-use inode 35748433 is free, correcting imap data fork in inode 35748440 claims metadata block 4468560 correcting nextents for inode 35748440 bad data fork in inode 35748440 would have cleared inode 35748440 - agno = 1 data fork in ino 2147483777 claims free block 268435458 imap claims in-use inode 2147483777 is free, correcting imap [...] - agno = 2 data fork in ino 4327071235 claims free block 540883903 imap claims in-use inode 4327071235 is free, correcting imap [...] - agno = 3 data fork in ino 6453720963 claims free block 806715119 imap claims in-use inode 6453720963 is free, correcting imap [...] - agno = 4 data fork in ino 8609098822 claims free block 1076137360 imap claims in-use inode 8609098822 is free, correcting imap imap claims in-use inode 8609098829 is free, correcting imap [...] - agno = 5 data fork in inode 10773946882 claims metadata block 1346743359 correcting nextents for inode 10773946882 bad data fork in inode 10773946882 would have cleared inode 10773946882 [...] - agno = 6 imap claims in-use inode 13657483776 is free, correcting imap data fork in ino 13657483780 claims free block 1707185480 [...] - agno = 7 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... free space (0,4468567-4468567) only seen by one free space btree free space (0,4468576-4468577) only seen by one free space btree free space (0,4486063-4486063) only seen by one free space btree - check for inodes claiming duplicate blocks... - agno = 2 - agno = 1 - agno = 0 entry ".." at block 0 offset 80 in directory inode 2147483777 references free inode 13658521470 - agno = 3 entry ".." at block 0 offset 80 in directory inode 2147483794 references free inode 13658521470 [...] Metadata CRC error detected at 0x459c09, xfs_dir3_block block 0x2217a80/0x1000 bad directory block magic # 0x494e41ff in block 0 for directory inode 35748440 corrupt block 0 in directory inode 35748440 would junk block no . entry for directory 35748440 no .. entry for directory 35748440 problem with directory contents in inode 35748440 would have cleared inode 35748440 [...] - agno = 4 - agno = 5 data fork in inode 10773946882 claims metadata block 1346743359 correcting nextents for inode 10773946882 bad data fork in inode 10773946882 would have cleared inode 10773946882 [...] - agno = 6 entry ".." at block 0 offset 80 in directory inode 13657483780 references free inode 13658521470 [...] - agno = 7 entry ".." at block 0 offset 80 in directory inode 13657483816 references free inode 13658521470 [...] xfs_repair: rmap.c:696: mark_inode_rl: Assertion `!(!!((rmap->rm_owner) & (1ULL << 63)))' failed. Aborted xfs_repair: rmap.c:696: mark_inode_rl: Assertion `!(!!((rmap->rm_owner) & (1ULL << 63)))' failed. Aborted The same thing happens after rebooting server. Attached diagnostics before and after reboot. What should I do next? after_reboot.zip before_reboot.zip
-
Someone on the nordvpn subreddit suggested to swap my current openvpn tcp cert file with the udp one. Not only did it fixed my problem but now I’m getting over 10MiB/s download speed up to 16MiB/s. Still don’t know why my previous config stopped working but now it working better than ever.
-
I tried 3 different servers including the one I checked on PC but it didn't change anything. Then I realised that I only moved appdata, not the Docker vDisk file. But after moving it back to the cache, download speeds on both clients are even slower ~380KiB/s Checked SSD speeds Timing cached reads: 18452 MB in 1.99 seconds = 9260.07 MB/sec Timing buffered disk reads: 1588 MB in 3.00 seconds = 528.79 MB/sec and moved vDisk back to array: downloading is still at 380KiB/s I'll have to create a new thread about this since it's not the image fault
-
I've been using this image for the last 6 months without any problems but now something has changed and I can't fix it. I'm using binhex/arch-qbittorrentvpn:4.3.9-2-01 tag, running the container with my NordVPN account and was usually getting around 8MiB/s download speed. I had container config directory mapped to appdata share on my cache drive, but last week this drive has died and I had to buy a new one. In the meantime I recreated appdata on my array from backups to keep my containers running. Everything was working fine except the fact that now I was getting total of 1.8MiB/s download speed. I thought that's because it's now running from HDD instead of SSD so it's slower. Today I installed new cache drive and moved appdata but the problem is still occuring and download speed stays around 1.8MiB/s. I saw it go to 1.9-2.1 a few times so I don't think it's capped. What I tried: - checked if speed/rates are limited within the app - restarted container - installed qBittorrent (normal app, not dockerized) on my PC, connected to the same VPN provider with the same account and tried downloading ubuntu-22.04 iso. Got speeds ~15MiB/s so my ISP is not throttling the connection - checked the same ubuntu torrent on my unraid but still got slow download - created new container with empty config from scratch but it didn't help either - ran speedtest on my server to make sure it's using full link Any ideas what else can I try to fix this? Edit: I also installed your binhex-rtorrentvpn and both clients are "stuck" at ~1.8MiB/s while downloading simultaneously. So I don't think that's the image fault
-
I've been using this image for over 3 months without any problems but today the container just stopped with 135 exit code. Logs: 2022-03-23 22:17:59.808371 [info] Host is running unRAID 2022-03-23 22:17:59.840674 [info] System information Linux 51c011541462 5.10.28-Unraid #1 SMP Wed Apr 7 08:23:18 PDT 2021 x86_64 GNU/Linux 2022-03-23 22:17:59.883313 [info] OS_ARCH defined as 'x86-64' 2022-03-23 22:17:59.940215 [info] PUID defined as '99' 2022-03-23 22:17:59.981057 [info] PGID defined as '100' 2022-03-23 22:18:00.159134 [info] UMASK defined as '000' 2022-03-23 22:18:00.198197 [info] Permissions already set for '/config' 2022-03-23 22:18:00.244633 [info] Deleting files in /tmp (non recursive)... 2022-03-23 22:18:00.282188 [info] VPN_ENABLED defined as 'yes' 2022-03-23 22:18:00.311848 [info] VPN_CLIENT defined as 'openvpn' 2022-03-23 22:18:00.339490 [info] VPN_PROV defined as 'custom' 2022-03-23 22:18:00.393104 [info] OpenVPN config file (ovpn extension) is located at ---- 2022-03-23 22:18:00.459289 [info] VPN remote server(s) defined as '----' 2022-03-23 22:18:00.486324 [info] VPN remote port(s) defined as '443,' 2022-03-23 22:18:00.512464 [info] VPN remote protcol(s) defined as 'tcp-client,' 2022-03-23 22:18:00.539455 [info] VPN_DEVICE_TYPE defined as 'tun0' 2022-03-23 22:18:00.570833 [info] VPN_OPTIONS not defined (via -e VPN_OPTIONS) 2022-03-23 22:18:00.599547 [info] LAN_NETWORK defined as '192.168.0.0/24' 2022-03-23 22:18:00.631824 [info] NAME_SERVERS defined as '84.200.69.80,37.235.1.174,1.1.1.1,37.235.1.177,84.200.70.40,1.0.0.1' 2022-03-23 22:18:00.662492 [info] VPN_USER defined as '----' 2022-03-23 22:18:00.693711 [info] VPN_PASS defined as '----' 2022-03-23 22:18:00.726052 [info] ENABLE_PRIVOXY defined as 'no' 2022-03-23 22:18:00.757326 [info] VPN_INPUT_PORTS not defined (via -e VPN_INPUT_PORTS), skipping allow for custom incoming ports 2022-03-23 22:18:00.786478 [info] VPN_OUTPUT_PORTS not defined (via -e VPN_OUTPUT_PORTS), skipping allow for custom outgoing ports 2022-03-23 22:18:00.819120 [info] ENABLE_AUTODL_IRSSI defined as 'no' 2022-03-23 22:18:00.858633 [info] ENABLE_RPC2 defined as 'yes' 2022-03-23 22:18:00.887232 [info] ENABLE_RPC2_AUTH defined as 'yes' 2022-03-23 22:18:00.915570 [info] RPC2_USER defined as 'admin' 2022-03-23 22:18:00.971581 [warn] RPC2_PASS not defined (via -e RPC2_PASS), using randomised password (password stored in '/config/nginx/security/rpc2_pass') 2022-03-23 22:18:01.011645 [info] ENABLE_WEBUI_AUTH defined as 'no' 2022-03-23 22:18:01.053345 [info] Starting Supervisor... I didn't change anything in the configuration, vpn account is still active. Any idea how to fix it?
-
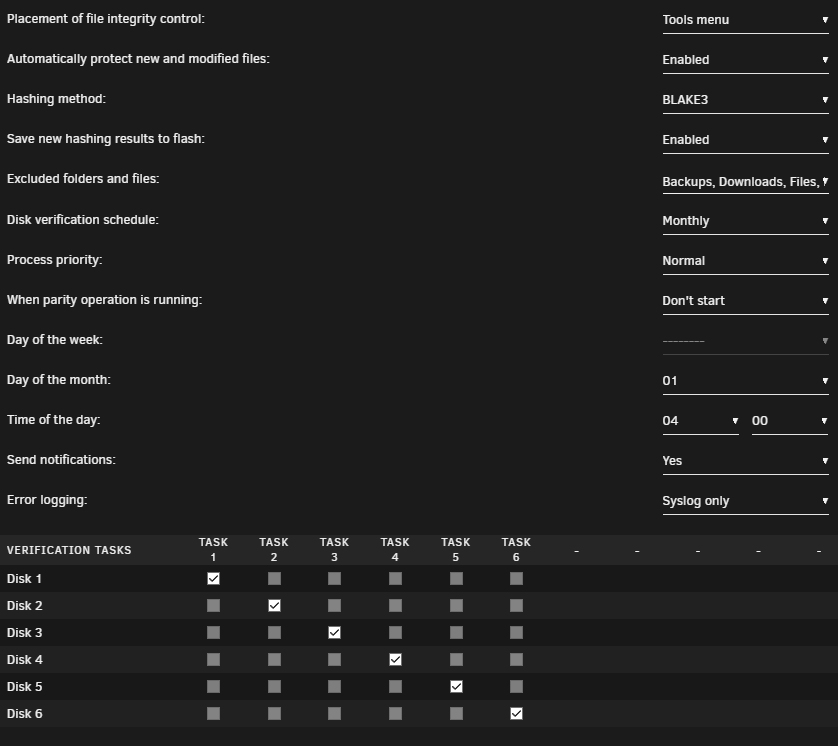
I think I've got this. There is a built-in help when you click on "Disk verification schedule" label and it says: But mostly important:
-
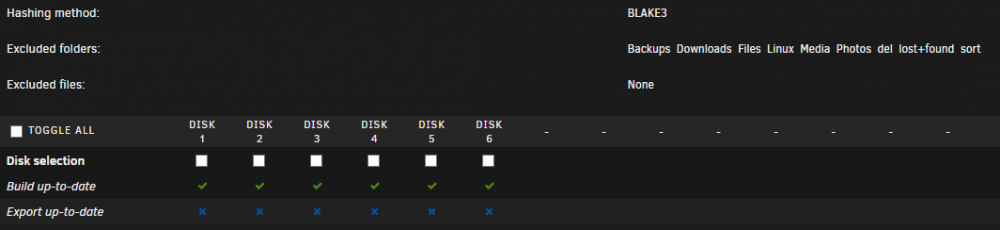
I changed it from monthly to daily to check how it works and it only checked Disk 5. So do I have to click "Build" every now and then manually and when I want to check validity: "Export" and "Check Export" also manually?
-
Hi. Just installed this plugin and configured it as such: And then clicked "Build" with all disks selected: Do I need to do anything else or will it automatically calculate hashes for new files (as they are created) and verify the existing ones (on monthly basis) on its own?
-
I thought I deleted this thread. Yes, I fixed it 10 minutes after posting. Restarted array without rebooting whole server, shares went back online. One disk was unmountable but xfs_repair fixed it.
-
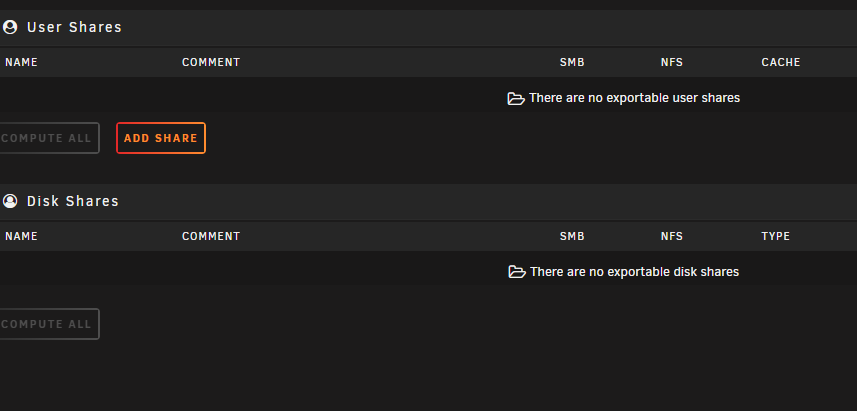
I was messing with my user groups to give it write rights to some dirs created by one Docker container. I did: > groups pm pm : users > usermod -a -G root pm > groups pm pm : users root > usermod -g root pm > usermod -a -G users pm > groups pm pm : root users > usermod -g users pm > groups pm pm : users root After running the last usermod command all my shares are now inaccessible. And GUI shows none of them (attached image). Listing content of /mnt directory: > ls -la /mnt /bin/ls: cannot access '/mnt/user': Input/output error /bin/ls: cannot access '/mnt/user0': Input/output error /bin/ls: cannot access '/mnt/disk1': Input/output error total 16 drwxr-xr-x 12 root root 240 Jan 20 16:05 ./ drwxr-xr-x 21 root root 460 Jun 21 2020 ../ drwxrwxrwx 1 nobody users 80 Jan 23 22:45 cache/ d????????? ? ? ? ? ? disk1/ drwxrwxrwx 11 nobody users 166 Jan 31 12:19 disk2/ drwxrwxrwx 10 nobody users 151 Jan 23 22:45 disk3/ drwxrwxrwx 10 nobody users 151 Jan 23 22:45 disk4/ drwxrwxrwx 10 nobody users 151 Jan 23 22:45 disk5/ drwxrwxrwt 2 nobody users 40 Jan 20 16:05 disks/ drwxrwxrwt 2 nobody users 40 Jan 20 16:05 remotes/ d????????? ? ? ? ? ? user/ d????????? ? ? ? ? ? user0/ -ls -la /mnt/disk2 drwxrwxrwx 11 nobody users 166 Jan 31 12:19 ./ drwxr-xr-x 12 root root 240 Jan 20 16:05 ../ drwxrwxrwx 7 nobody users 105 Jan 27 14:00 Backups/ drwxrwxr-x 16 nobody users 4096 Feb 3 20:12 Downloads/ drwxrwxrwx 9 nobody users 132 Dec 17 12:39 Files/ drwxrwxrwx 2 nobody users 51 Nov 26 09:14 Home/ drwxrwxrwx 29 nobody users 4096 Feb 4 02:47 Media/ drwxrwxrwx 4 nobody users 46 Jan 24 16:16 Photos/ drwxrwxrwx 2 nobody users 6 Jan 31 12:19 del/ drwxrwxrwx 10 nobody users 8192 Feb 2 12:09 sort/ All data is still there I just can't access it. How can I revert that?
-
It took almost 2 days to copy everything but all files are now on a new disk and everything seems to be working fine. It copied ~8TB without any I/O errors and I was getting them quiet often before. Thanks for help
-
Rebuilding finished with 0 errors so I ran xfs_repair with no modify flag and got thousands of these lines: out-of-order bno btree record 344 (108441151 18) block 0/651941 block (0,108917856-108917947) multiply claimed by bno space tree, state - 1 data fork in ino 15034795729 claims free block 37702356 free space (7,69487107-69487108) only seen by one free space btree And thousands of files and directories marked to be junked: entry "Season 1" in shortform directory 106340182 references non-existent inode 2183048375 would have junked entry "Season 1" in directory inode 106340182 Then, I plugged in original disk, mounted it with Unassigned Devices and compared tree command from today and yesterday - all data is still on it. Now: 1. unplug original drive 2. go to maintenance mode 3. click on new drive 4. re-create fs (the only way I see is to set it something else like btrfs and then again to xfs) 5. connect and mount original drive 6. copy all files from orignal drive to the new one Is that correct?
-
Here are new diagnostics. Now I wait for rebuilding to complete orion2-diagnostics-20220111-1532.zip
-
I'm rebuilding to a new disk. Currently at 18% but it already shows "Unmountable: not mounted". All data should still be backed up on the original drive. If recreating will be necessary I can copy from there.
-
If I replace current drive with an empty one, rebuild it from parity and then recreate fs - should it work?
-
I did that and it fixed it for like 10 minutes and then it unmounted again. I repeated the steps, fixed it but after another 30 minutes it happened again. Same disk every time.
-
I just noticed that another of my drives went into "unmountable" state. I just ran xfs_repair -nv and it shows multiple bad magic in block N messages. Last time it happened I lost over 600GB of data so I don't want it to happen again. How should I proceed to avoid data loss? orion2-diagnostics-20220111-0307.zip
-
It should be set to "Custom order": If for some reason you are editing your config file manually, it should be set to: "useOrdering":"orderId"

-
Well, that's unfortunate. Thanks for all your help anyway.
-
I tried to generate it manually: root@Orion2:~# xfs_admin -U generate /dev/sdg1 Clearing log and setting UUID writing all SBs new UUID = ab1f65dd-e188-4c67-afc6-9f89fc139e93 And now both disks are mounted but original disk still shows up as empty: root@Orion2:/mnt/disks/WDC_WD80EZAZ-11TDBA0_2SG425ZW# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/sdg1 7811939620 54499088 7757440532 1% /mnt/disks/WDC_WD80EZAZ-11TDBA0_2SG425ZW /dev/md1 7811939620 7807708212 4231408 100% /mnt/disk1 /dev/md2 7811939620 7802174388 9765232 100% /mnt/disk2 /dev/md3 7811939620 54499088 7757440532 1% /mnt/disk3 /dev/md4 7811939620 7799822864 12116756 100% /mnt/disk4 /dev/md5 7811939620 7791383328 20556292 100% /mnt/disk5 /dev/sdc1 500107576 126153784 372420104 26% /mnt/cache