




kubed_zero
Community Developer
-
Joined
-
Last visited
Everything posted by kubed_zero
-
https://github.com/kubedzero/unraid-snmp/blob/main/source/install/doinst.sh#L38 The configuration in which the community string is set is /etc/snmp/snmpd.conf. Note that this gets recreated at every boot (as with the rest of Unraid's OS) so you'll need a command in the /boot/config/go startup script to overwrite the default value or made modifications, along with a command to restart SNMP to take the new changes.
-
I just tested on RC2 and CA version 2021.02.19a and was able to search for and install SNMP without issue.
-
I can't comment on the functionality of CA, but there is nothing on my end that's keeping it from showing up in CA https://github.com/kubedzero/unraid-community-apps-xml/blob/main/snmp.xml If CA becomes a problem, feel free to install it directly as I've tested it to be working on 6.9 https://raw.githubusercontent.com/kubedzero/unraid-snmp/main/snmp.plg
-
What should we know about the Icon tag? What image formats are supported, is transparency supported, what are the minimum and maximum dimensions, optimal file size, optimal ratio, etc?
-
It sounds to me as if you need an SNMP collector, and this plugin is just meant to add SNMP output to Unraid. Perhaps you could mod this plugin's snmpd.conf file and write a script to collect the APC and QNAP metrics, but you'd still need something outside this plugin to actually read the SNMP data and get it to Telegraf/InfluxDB.
-
It should be fully functional. I'm currently running 6.8.3 without issue.
-
It appears that @dlandon has un-deprecated the Open Files plugin for Unraid 6.9 https://github.com/dlandon/open.files/commit/8afb5a773896f0e351076b35fd338d10642e5e55 🤣 so no fork is needed. Happy to step in in the future though!
-
Understood, I'm proactively making these changes to my repositories I have tested that if I push an update on the master branch pointing to the PLG+TXZ on the main branch, it effectively migrates users to the new branch. That, I think, is a second option for getting onto the correct version. My question had actually been more about the CA XML update, as I wasn't sure if something on the CA side of things was tracking the XML on a specific branch. Sorry for the miscommunication!
-
As a heads up to consumers of this plugin, I'm working on changing the branch name from "master" to "main" following Github's recent announcement. At this moment, I have the plugin's original "master" branch on the current version 2020.10.04 in addition to the new "main" branch with a bumped version 2020.11.20 containing the exact same data. I'm doing some investigation on whether I'll be able to seamlessly transition people using the existing version of SNMP over to this new branch. Of course, the other option is to just uninstall the existing installation of SNMP and reinstall using the new link: https://raw.githubusercontent.com/kubedzero/unraid-snmp/main/snmp.plg I've also updated the Community Apps XML repo with the same branch change, and have modified the XML in both "master" and "main" to point at the "main" version of the SNMP plugin. I'm hoping this will get new adopters on the version I'll be supporting in the future. @Squid is there anything further I need to do to change CA from tracking https://raw.githubusercontent.com/kubedzero/unraid-community-apps-xml/master/snmp.xml to instead track https://raw.githubusercontent.com/kubedzero/unraid-community-apps-xml/main/snmp.xml ? Finally, I'm going to be editing my posts in this forum topic to point at the new branch, to try and catch new folks. One more time, the new link to the plugin's PLG install file is https://raw.githubusercontent.com/kubedzero/unraid-snmp/main/snmp.plg
-
Got it, thanks. Well if @dlandon wants to retire and hand over control, I can fork it, remove the 6.8.9 max version, and keep supporting it from 6.8 onwards (with the CA XML as well). I'd prefer to wait for sign-off before proceeding down that path though
-
Unbalance is just a UI for rsync, so if you configure your rsync flags to preserve hard links, then yes. It looks to be that -H does this in rsync https://linux.die.net/man/1/rsync
-
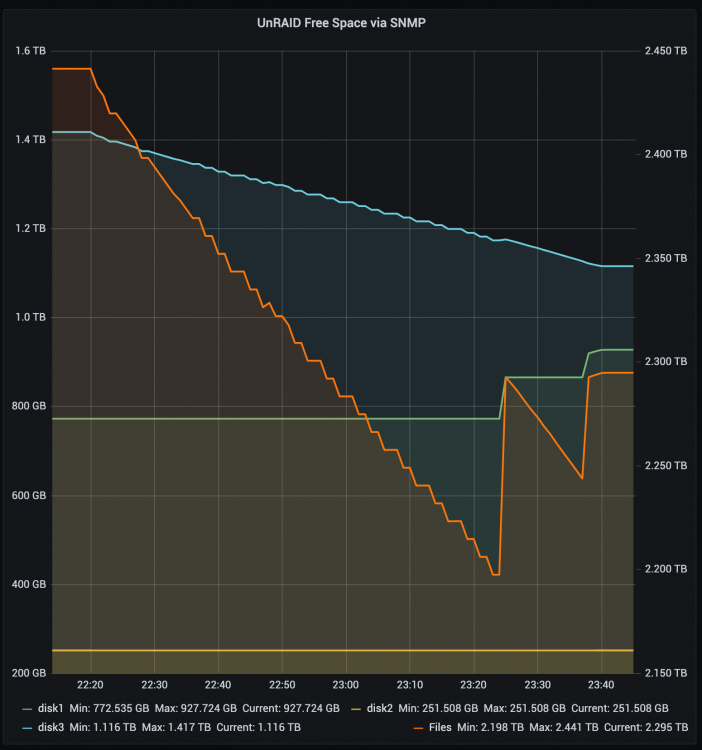
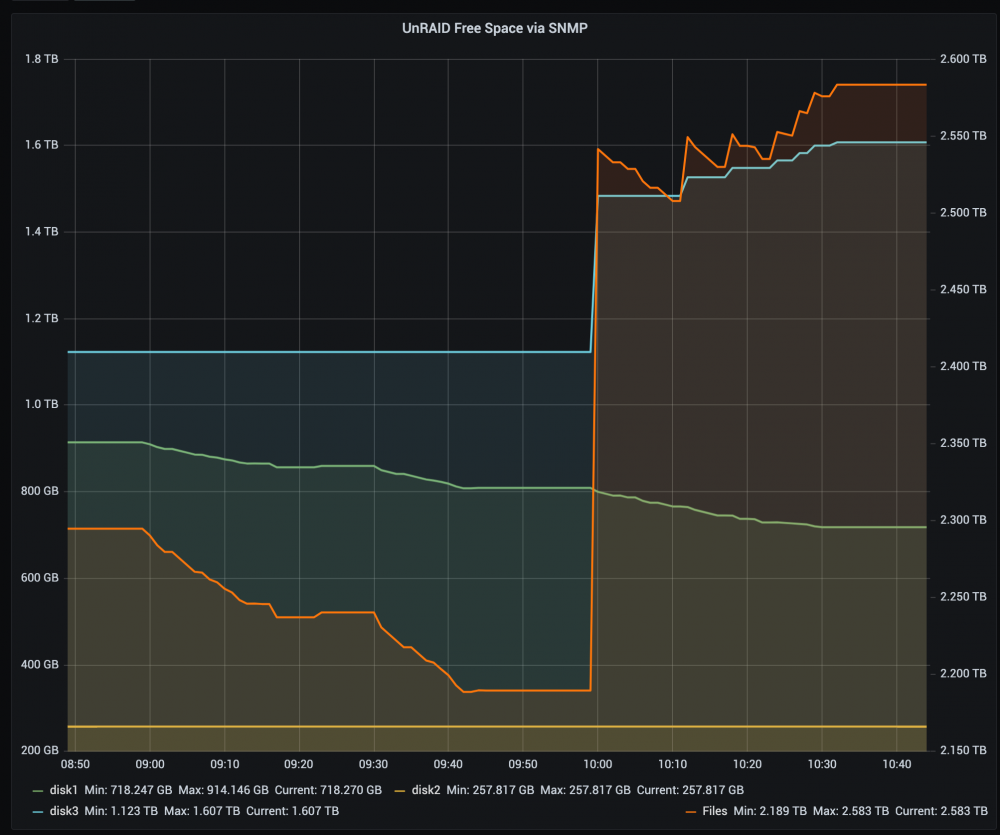
I have three disks + parity and set Unbalance to move about 300GB of files from Disk 1 to Disk 3. I confirmed that I ran the New Permissions script immediately before executing, and I received no permissions warnings when running Plan in Unbalance I have my rsync settings at the default, which seems to just populate the field with -X. I confirmed that during execution it uses rsync -avPR -X "source" "dest" so I think this is set up as intended I have a share called Files that pulls from both disks. Disk 2 is untouched unmodified in this process Unbalance runs, and notes in its email that it has moved about, 300GB of data The free space on Disk 1 goes from 772GB to 928GB, about 156GB removed Disk 3's free space goes from 1417GB down to 1116GB, about 300GB of data added The File share's free space goes from 2441GB to 2295GB, or about 146GB less free space after the move This seems to me as if Unbalance successfully copied the full 300GB set of data from Disk 1 to Disk 3, but was unable to delete 146GB of data from Disk 1 after moving. I would have expected the share to have the same amount of free space before and after moving, but this does not seem to be the case. I've confirmed that the syslog doesn't output any errors or other logs during the Move, and I scanned through /boot/logs/unbalance.log to confirm everything looked OK there. I just had a thought that perhaps this has something to do with the sparse files of my VM disk backups. For example, I have a 100GB .vdmk file that only occupies 20GB on disk, and perhaps after rsync it occupies the full 100GB. Put a couple of VM backups together and we have our missing 146GB. In other words, the disk space estimate for Disk 1 was using the occupied space and not the total space, while the rsync move and the files that resulted have matching occupied and total space. I've done some additional testing and confirmed this is what was happening. I had to update the Unbalance rsync settings from the default -X to -X --sparse as I found in the Rsync man page and a forum discussion https://communities.vmware.com/t5/Technical-Community-Resources/copying-virtual-disk-images-with-rsync/m-p/848647 https://linux.die.net/man/1/rsync After making that change in the Unbalance settings and running the transfer again, everything worked exactly as expected. A huge amount of space was freed up on the share, meaning that the VM backups were able to regain their sparseness and only occupy part of the disk. Nice! So as a warning to people out there: If you use Unraid for virtual machine images or other sparse files, make sure to use --sparse as an option when running Rsync.
-
Darn, that's a shame to hear, but THANK YOU for providing it and keeping it up to date and working this long! It's very much appreciated. I just saw the update making 6.8.9 the max version. I still find this really helps when compared to the Active Streams plugin because it lists working directories held open by various SSH sessions, so I can easily track those down and finish what I'm doing when the server is failing to unmount user shares. What's the difficulty in porting this to 6.9? I may be interested in taking over maintenance if you're no longer able, and background on the hurdles would really help
-
I just released another update to the plugin, and the current version is now 2020.10.04. This update adds a Settings page where the SMART standby validation can be disabled. This is for people such as @Ak1rA who want the temperatures to always report, even if it means waking disks from standby. The update also adds a set of memory metric outputs to SNMP. NET-SNMP-EXTEND-MIB::nsExtendOutLine."meminfo".1 = STRING: MemTotal: 25278668800 NET-SNMP-EXTEND-MIB::nsExtendOutLine."meminfo".2 = STRING: MemFree: 230752256 NET-SNMP-EXTEND-MIB::nsExtendOutLine."meminfo".3 = STRING: MemAvailable: 22541844480 NET-SNMP-EXTEND-MIB::nsExtendOutLine."meminfo".4 = STRING: Cached: 23716921344 NET-SNMP-EXTEND-MIB::nsExtendOutLine."meminfo".5 = STRING: Active: 1580380160 NET-SNMP-EXTEND-MIB::nsExtendOutLine."meminfo".6 = STRING: Inactive: 22691184640 NET-SNMP-EXTEND-MIB::nsExtendOutLine."meminfo".7 = STRING: Committed_AS: 1893945344 As a reminder, the PLG file is https://raw.githubusercontent.com/kubedzero/unraid-snmp/main/snmp.plg Let me know if you run into installation or usage issues!
-
I spoke offline with @Ak1rA and we confirmed that the plugin is working as expected. The issue was that HDDs don't report temperature while they are in standby. The older versions of the plugin would wake disks from standby so they could always fetch a temperature, and the new version does not do this. Instead of waking up the disk to fetch the temperature, it will recognize STANDBY mode and report a temperature of -2. We tested and confirmed that the temperatures report without issue once the disks are spun up. That said, I'm looking into adding a Settings page for SNMP that could toggle this behavior. If you always want drives to report temperatures at the expense of keeping them spun up, the setting should enable this "unsafe temperature checking" behavior. I use "unsafe" in the sense that the theoretically passive act of getting the temperature may change the behavior and standby/active status of the disk. Also in the next update should be a new category of measurements for a few different RAM/memory metrics.
-
Since smartctl -A /dev/sde wakes up the drive to get the temperature and running smartctl --nocheck standby -A /dev/sde afterwards can then capitalize on the fact that the disk is already awake, I'd expect both to print temperatures only after the disk is woken up. My understanding is that the MAIN dashboard's disk state + temp can lag behind the actual temperature. The maintainer noted that this delay is managed by the Settings > Disk Settings > poll_attributes setting, where 1800 (30 minutes) is the default update rate. With that in mind, I'd imagine the MAIN dashboard would eventually show that your drive is spun up and has a temperature after 30 minutes (assuming the spin down time isn't less than that, or that you continuously call smartctl to keep the disk awake) Could you experiment with this and let me know if this explains the issue you are facing? As another experiment, if you change your Settings > Disk Settings > spin down delay to Never (and make sure each of your disks don't override this setting), do you then find that SNMP will always report disk temperatures?
-
@Ak1rA This is the line that grabs the temperature in the current version: https://github.com/kubedzero/unraid-snmp/blob/347d46ed7f938b85a9f9e112df4e350bda348a4b/source/usr/local/emhttp/plugins/snmp/disk_temps.sh#L98 smartctl --nocheck standby -A /dev/sdc What does that print out when you replace "sdc" with your various drives? The old code uses the same command, without the standby check: https://github.com/kubedzero/unraid-snmp/blob/6d4d8a77e4c44e827b19f9814fab5b7debfa90b9/drive_temps.sh#L71 smartctl -A /dev/sdc In comparison, what does that print out when you replace "sdc" with your various drives? The old code would spin the drive up to check the temperature, therefore changing the behavior of the drive simply by monitoring. The new code uses the standby check to avoid influencing the behavior and reporting -2 in that case. -1 would indicate there was an error during parsing, which doesn't seem to be happening here. My guesses here are: Your drives in the array are not spun up, and are therefore correctly reporting in standby mode (The "MAIN" page should also report * values for drive temperature) There is an issue parsing "standby" out of your SmartCTL responses, which if you provide the output I can better debug SmartCTL isn't correctly reporting your drive's standby state or temperature. This could be due to an HBA/RAID card or a number of other reasons If you could provide the printouts of running those commands on your drives, that would be super helpful! I only have recent Western Digital drives directly attached to the motherboard, so your mix of Seagate, HGST, Hitachi, and WD might provide valuable insight. Thanks!
-
Thanks to @makkish for the help in testing. We found a bug that was due to the unraid-snmp-2020.09.19-x86_64-1.txz file containing renamed shell scripts that weren't used. The bug seemed to be that the shares were no longer accessible over the network via SMB or NFS. How a couple extra files affect the behavior of SMB and NFS was not discovered. Removing the scripts and rebuilding the package into unraid-snmp-2020.09.20-x86_64-1.txz resolved the issue. A couple other minor changes were included that do not affect behavior. Updating to 2020.09.20 from plugin version 2020.04.01 was tested to work, as was updating from 2020.09.19. Whether you install directly via the PLG file or install via Community Apps (CA), the latest update should be available. Let me know if you encounter any other issues with installing, calling SNMP, or using other Unraid features!
-
The update changes the config path to /etc/snmp/snmpd.conf instead of the old config path of /usr/local/emhttp/plugins/snmp/snmpd.conf. This is defined in the file used for SNMP startup, /etc/rc.d/rc.snmpd. If you check it, I'd imagine it's pointing to the /etc/ config instead of the /usr/ config. The old versions of the plugin used to modify the /etc/rc.d/rc.snmpd file to point at the /usr config, but not in a way I was super happy with: https://github.com/kubedzero/unraid-snmp/blob/6d4d8a77e4c44e827b19f9814fab5b7debfa90b9/snmp.plg#L243 The new version leaves that part of the /etc/rc.d/rc.snmpd file and instead overwrites the default config at /etc/snmp/snmpd.conf with our own. My reasoning for overwriting the net-snmp package default config and not leaving the default and our custom config both floating around is that /etc/snmp/snmpd.conf never seemed to work properly on Unraid. Providing it as an option seemed more confusing than anything else. The reason that /usr/local/emhttp/plugins/snmp/snmpd.conf and /etc/snmp/snmpd.conf both exist in the new version is that the upgrade from 2020.04.01 breaks if /usr/local/emhttp/plugins/snmp/snmpd.conf is missing and Unraid isn't rebooted. The upgrade process doesn't fix the 2020.04.01 and earlier plugin version's changes to /etc/rc.d/rc.snmpd, only a complete uninstall/reinstall or reboot will do that. I wanted to give users the ability to upgrade cleanly, so both copies of the config exist for now. In a future update (6 months to 1 year), I'll probably move instead of copy the config during install to prevent this confusion. https://github.com/kubedzero/unraid-snmp/blob/83d740bde85f537e9cfff8ed63d76abf572a1be4/source/install/doinst.sh#L35 Hopefully editing /etc/snmp/snmpd.conf will get you the changes you need? Let me know!
-
Hi all, just released a rather large update to the plugin. Feel free to update and test it out. As a reminder, the PLG file is https://raw.githubusercontent.com/kubedzero/unraid-snmp/main/snmp.plg I don't have great coverage since I only have an Intel CPU and Western Digital drives (no Toshiba, Seagate, SSDs or anything else) so the behavior might differ based on hardware. I also only have four drives in my system, no VMs, no cache drive, and the presence of those could introduce variations in behavior as well. Regardless, I tested it on Unraid versions 6.8.3 and 6.9.0-Beta25 and both worked fine. I confirmed on my own system that the plugin update from version 2020.04.01 to 2020.09.19 worked fine, but let me know if you run into issues. Otherwise, I'd recommend uninstalling the existing pre-2020.09.19 plugin, rebooting, and then installing the new plugin. The older versions didn't do the best job cleaning up files on uninstall, so the reboot really helps make sure the .plg doesn't get rerun on the next boot. Anyway, onto the changelog for version 2020.09.19: - Migrate SNMP plugin to .txz style install - Optimized plugin removal for more complete cleanup - Updated net-snmp from 5.8-5 to 5.9 - Updated libnl from 1.1.4 to 1.1.4-3 - Perl 5.32.0 declared as dependency instead of separate install. - Plugin maintainer should keep the version in sync with Nerd Pack to avoid overwriting with an older version - Install logging more clearly states usage of single and double quotes in sample calls - Refactored `share_free_space.sh` for added clarity. - Preexisting behavior: Outputs in bytes - Refactored `drive_temps.sh` - Changed name to `disk_temps.sh` - Preexisting behavior: Five minute TTL cached results for rapid SNMP calls and large arrays - New behavior: Avoids disk spinup, preferring to report standby "temperature" of -2 - New behavior: If an error is encountered during parsing, report a "temperature" of -1 - New behavior: Script originally output nothing if no cached results present. Now it reports whatever results were collected in the first 1000ms - Added `disk_free_space.sh` to print free bytes in /boot, /mnt/disk*, /mnt/cache - Exposed in SNMP as `diskfree` - Added `cpu_mhz.sh` at request of forum user Max to output CPU speed in MHz - Exposed in SNMP as `cpumhz` - Tested with an Intel CPU virtualized under ESXi @Max good news, the update includes CPU MHz in the output. Let me know if it works for you. @cyruspy good news, Perl is now installed as part of plugin install. It was removed at one point because it didn't really matter which version and the original maintainer didn't want to constantly keep in sync with version bumps of Nerd Pack's copy of Perl. I found that the last one to install in the boot process gets to determine the version, even if it's older. So if for some reason this version is older than the version in Nerd Pack, it will still work fine for this use case.
-
I was doing some testing on edge cases for a plugin I maintain. This issue is reproducible simply by trying to create a share on a running system. I tried to create a share with the following name: Weird? [naming] & stuff / other stuff As expected, Unraid gave me the following error: You cannot use the following within share names : \ / * < > | " I removed the forward slash and tried again with the following new, supposedly compliant share name: Weird? [naming] & stuff other stuff This time when pushing "Add Share" it hung on Processing Request for a little while, and then took me to a new page with the following error: Share Weird? [naming] has been deleted. Pushing the Done button on that page, I was taken to my Shares overview, where I currently see the share "Weird? [naming] & stuff other stuff" as if it weren't actually deleted However, looking at the syslog, I see the following output. Samba seems to repeatedly restart and fopen seems to be having problems: Sep 19 11:42:56 Tower emhttpd: error: put_config_idx, 619: Invalid argument (22): fopen: /boot/config/shares/Weird? [naming] & stuff other stuff.cfg Sep 19 11:42:56 Tower emhttpd: shcmd (1310): mkdir '/mnt/user/Weird? [naming] & stuff other stuff' Sep 19 11:43:06 Tower emhttpd: shcmd (1311): chmod 0777 '/mnt/user/Weird? [naming] & stuff other stuff' Sep 19 11:43:06 Tower emhttpd: shcmd (1312): chown 'nobody':'users' '/mnt/user/Weird? [naming] & stuff other stuff' Sep 19 11:43:06 Tower emhttpd: error: put_config_idx, 619: Invalid argument (22): fopen: /boot/config/shares/Weird? [naming] & stuff other stuff.cfg Sep 19 11:43:06 Tower emhttpd: Starting services... Sep 19 11:43:06 Tower emhttpd: error: put_config_idx, 619: Invalid argument (22): fopen: /boot/config/shares/Weird? [naming] & stuff other stuff.cfg Sep 19 11:43:06 Tower emhttpd: Starting services... Sep 19 11:43:06 Tower emhttpd: shcmd (1319): /etc/rc.d/rc.samba restart Sep 19 11:43:08 Tower root: Starting Samba: /usr/sbin/smbd -D Sep 19 11:43:08 Tower root: /usr/sbin/nmbd -D Sep 19 11:43:08 Tower root: /usr/sbin/wsdd Sep 19 11:43:08 Tower root: /usr/sbin/winbindd -D Sep 19 11:43:08 Tower emhttpd: shcmd (1325): /etc/rc.d/rc.samba restart Sep 19 11:43:11 Tower root: Starting Samba: /usr/sbin/smbd -D Sep 19 11:43:11 Tower root: /usr/sbin/nmbd -D Sep 19 11:43:11 Tower root: /usr/sbin/wsdd Sep 19 11:43:11 Tower root: /usr/sbin/winbindd -D Sep 19 11:43:11 Tower emhttpd: Starting services... Sep 19 11:43:11 Tower emhttpd: shcmd (1342): /etc/rc.d/rc.samba restart Sep 19 11:43:13 Tower root: Starting Samba: /usr/sbin/smbd -D Sep 19 11:43:13 Tower root: /usr/sbin/nmbd -D Sep 19 11:43:13 Tower root: /usr/sbin/wsdd Sep 19 11:43:13 Tower root: /usr/sbin/winbindd -D Sep 19 11:43:13 Tower emhttpd: error: put_config_idx, 619: Invalid argument (22): fopen: /boot/config/shares/Weird? [naming] & stuff other stuff.cfg Sep 19 11:43:13 Tower emhttpd: Starting services... Sep 19 11:43:13 Tower emhttpd: error: put_config_idx, 619: Invalid argument (22): fopen: /boot/config/shares/Weird? [naming] & stuff other stuff.cfg Sep 19 11:43:13 Tower emhttpd: Starting services... Sep 19 11:43:13 Tower emhttpd: shcmd (1358): /etc/rc.d/rc.samba restart Sep 19 11:43:16 Tower root: Starting Samba: /usr/sbin/smbd -D Sep 19 11:43:16 Tower root: /usr/sbin/nmbd -D Sep 19 11:43:16 Tower root: /usr/sbin/wsdd Sep 19 11:43:16 Tower root: /usr/sbin/winbindd -D Sep 19 11:43:16 Tower emhttpd: shcmd (1364): /etc/rc.d/rc.samba restart Sep 19 11:43:18 Tower root: Starting Samba: /usr/sbin/smbd -D Sep 19 11:43:18 Tower root: /usr/sbin/nmbd -D Sep 19 11:43:18 Tower root: /usr/sbin/wsdd Sep 19 11:43:18 Tower root: /usr/sbin/winbindd -D In terms of bugs, I think there are a couple. Possibly better validation is needed on Share name input, the Share Deleted warning didn't actually appear to delete the share, the Share Deleted warning didn't print the entire name. That said, the folder creation still worked, the shares.ini file seemed to get updated as normal, I was able to edit it relatively normally (save for the long loading times) and I was able to delete without issue. While this is a bug, it appears relatively minor, at least for my use case. Edit: I tried with $ and # in the share name as well and they were considered valid as well
-
TLDR: 1. Clearer definition of Parity Check + "write corrections to parity disk" versus Parity check (read only), possibly with new naming 2. Documentation or a configurable setting that indicates whether a hard power off and the subsequent parity check on reboot is the read only or the read-write version 3. Parity History popup indicating status of "write corrections to parity disk" in previous runs ___________ I searched through the forums but couldn't find much on this. Basically, when we manually start a Parity check, there is an option to "Write corrections to parity." Without it, the Parity Check will run but not update the Parity drive with any discrepancies between the parity data and the data disks. That means that a Parity Check without the checkbox is more a Parity validation/check. When the checkbox is ticked though, the Parity drive will be rewritten in the event of any discrepancy between the data disks and the parity disks. For ease of reference, I'd love to see these terms clarified. Something that still holds the reverence of a full data read, but something that reflects that Parity disk data will be changed. I think Parity Check is still a fine term to be used for the read and diff to confirm there are no errors, and Rebuild is already taken in the Unraid universe when we need to get back the contents of a disk. Could a new term such as Parity Update or Parity Recompute or Parity Correction be used for instances of Parity runs where the checkbox is enabled? One other thing is that I'm not clear on what type of Parity Check is done on a power loss. Parity Check will start regardless at the next boot, but there's no setting or indication to make this behavior follow one option or the other. Finally, I wonder if it would be possible in the Parity history popup to have a new column that indicates whether or not the Parity disk was corrected to match the data disks. Looking at the history in its current form (or logs or anything else as far as I'm aware) there's no way to know what previous runs were configured as: with or without the "write corrections option" I hope this makes sense and am happy to revise or provide any more detail to submit this feature request for consideration! Alternatively, If I'm missing a feature already present in Unraid that would help me distinguish, please point me towards it. As mentioned I did a scan of the forums after coming up blank in the Web UI, but I could have missed it.
-
Fantastic, glad things got sorted out. I'm a little surprised all the other logging was missing from the installation, I would have expected the notification that Perl was needed to show up when you were installing. Maybe it is different with Community Apps or something, not sure. Adding additional warning about Perl is a good suggestion, I'll look into adding it. Thanks!
-
The PLG file executes in order, and since we see that the README is skipped over the next section with relevance is a bash script to check if Perl is installed: https://github.com/kubedzero/unraid-snmp/blob/main/snmp.plg#L119 I'm unclear as to why the error doesn't show up, but do you have NerdPack/Perl installed? root@UNRAID:~# which perl /usr/bin/perl root@UNRAID:~#
-
Did you include the "exit 1" message in the logs you pasted?



