



JSE
Members
-
Joined
-
Last visited
Everything posted by JSE
-
When creating a btrfs filesystem (mkfs), the -O bgt option should be set to enable the block-group-tree. This is particularly useful on large filesystems with lots of data, as mounting a large btrfs filesystem can take minutes (!!) to mount without it, vs just a couple seconds. Even just 4TiB disks I have can take around 30 seconds to mount (SSDs not such a big deal) as the filesystem has to walk the entire extent tree to mount vs with the block group tree enabled. ie benchmarks from reddit but can confirm it's the same. Some performance benchmarks: # time mount -v /mnt/Backup mount: /dev/sde mounted on /mnt/Backup. real 0m25.962s user 0m0.006s sys 0m0.282s # time mount -v /mnt/Backup mount: /dev/sde mounted on /mnt/Backup. real 0m0.610s user 0m0.005s sys 0m0.019s The feature is supported in all kernels since 6.1 and it is a safe feature that can be rolled back with btrfs tune to disable it if users need to.
-
I would like to eventually see bcachefs pools be added to unraid someday, but it still misses a lot of functionality. Namely, the ability to easily monitor an array, scrub, rebalance when adding/removing devices, and a proper process for device replacement. Not to mention there have been several major data loss bugs since the 6.7 merge. The filesystem is still considered experimental for a reason. I would prefer we hold off until it has had time to mature and become a better, well rounded solution before it's considered for inclusion in unraid. Especially given we already have ZFS which has Arc caching, which is much better than linux's native caching.
-
As @JorgeB mentioned NOCOW is no longer default for any shares, but even if you set NOCOW, you need to keep in mind that not only is redundancy compromised with the use of nocow, compression will not work whatsoever on those files. Compression needs copy on write to function. Nocow is equal to nocsums and no compression. This is true, however the zstd compression algorithm is more than fast enough on most modern CPUs to discard any files that can't be compressed and store them normally. For the files that are compressible. Alternatively unraid could use the `btrfs property set /path/to/share/on/btrfs compress zstd` on a directory or subvolume which will work identical to compress-force on the filesystem wide option. This would allow users to set compression on a per-share basis much like nocow. It doesn't allow setting a compression level, however given unraid defaults to 3 anyway, this option also defaults to 3 which I'd argue is a good default anyway. Given that ZFS supports compression on a per-dataset basis this might be a better solution rather than per filesystem basis in the long term, however the option would need to be set at share creation time to be most effective. Given that btrfs should be using subvolumes for shares this should depend on this feature request being implemented as well (though this option doesn't technically need to be on a per-subvolume basis like it does for ZFS datasets). IMO this would be an ever better way of handling compression as you could leave compression disabled for media shares so no CPU time is wasted whatsoever on media, but have it enabled for shares you know compression would be beneficial as it would use the force compression without any mount options at all.
-
Yep creating and deleting subvolumes is as simple as a directory. Currently, a share on unraid is just a directory on the top level (root) of a disk or pool in unraid. So if you `mkdir myshare` on a disk it will create a share called "myshare". Alternatively, a subvolume is made as simple as `btrfs subv create myshare` and it for all intents and purposes works just like a directory, but with the added performance benefits and ability to snapshot it. Deleting it is the same as deleting a directory. You can `rmdir myshare` the subvolume and it will delete it much the same as `btrfs subv delete myshare` does (the latter is faster though). No formatting necessary
-
This sounds perfect, exactly what we need. My thought was have the stats appear on pool page as well, possibly around the balance/scrub options with a button to clear the stats. But 100% we're on the same page here, definitely need this type of monitoring for pools. I haven't tested ZFS that much since it was added but if it's also missing monitoring we need that too
-
Currently, when you format a disk or pool to btrfs in unraid, an option is provided to enable compression. While unraid does use the efficient zstd compression with the default level 3 compression level which I think is a very optimal default, it's using the `compress` mount option rather than `compress-force` option on the filesystem. Btrfs has a very rudimentary algorithm when you use the `compress` mount option where it will abandon even attempting compression on a file if the first few KiB is not compressible. This results in a lot of files that have portions that could compress not get compressed, and in a lot of cases behaves as if you didn't have compression enabled whatsoever. It makes the current unraid compression behavior to arguably be not very useful. Now if you were using some of the other algorithms like zlib, force compression could actually have a negative impact. However, zstd compression is smart enough to not store any compression it attempts if it doesn't yield an improvement in storage. This request is thus to use the compress-force option instead so compression actually happens on files that have headers that can't compress, or at least provide an option to enable force compression so those of us who do wan't compression can force it (such as a check box or an alternative option). This yields much more space savings for me than the current option, but I currently have to resort to remounting my disks with the compress-force option via the shell or a script rather than rely on the option unraid provides.
-
High time it gets included then . Do you have a link? .... lack of this and lots of people can lose data, and could be recoverable right now and not even know it. I'm on a raid (ha, no pun intended) of recommending some changes to improve the reliability of btrfs pools since I do a lot of this stuff manually in shell but it really should be included in a more user friendly way since most people are not familiar or have the experience in managing a btrfs pool from shell, and honestly, they shouldn't need to.
-
On ZFS with unraid, if you create a share and it exists on a ZFS volume, it's created as a dataset. This makes creating snapshots, rolling back, etc much easier. This feature request is to extend this behavior to btrfs subvolumes, where the top level directory (aka a share) should always be a subvolume instead of a regular directory. A subvolumes in btrfs is also it's own independent extent tree; it acts as if each subvolume is it's own independent filesystem even though they merely appear as a directory. What this means is, by using subvolumes per share, any filesystem locking behavior is limited only to the subvolume in question rather than the filesystem overall (in most cases). This allows for higher levels of concurrency and thus better performance, especially for pools with different shares that have high IO activity.
-
With btrfs, if you have a live running pool and a disk disappears from the system (ie you pull it or a cable flakes out), or if the disk straight up just fails while the array is running, btrfs doesn't provide any indication via most of the monitoring commands to detect the missing disk. For example if you run `btrfs filesystem show` after a disk has dropped from a pool, it will still show a reference to the disk even though it's missing. Even if it's just a flaky cable and the disk reappears to the system, it will still remain unused until you fully remount the filesystem (and then scrub, not balance would be all that's necessary to resync but I digress). If you unmount the pool and remount it with the disk still missing, you will need the degraded option which unraid handles, but it's only after that remount with the degraded option that `btrfs filesystem show` will indicate any missing devices. It's also only after stopping the array will unraid indicate there are any missing devices with a pool. This means unraid users are in the dark if a disk fails or flakes out or completely fails while the array is running. If the user doesn't stop the array often, they could be in the dark that their pool is degraded for months even. Btrfs does however provide a means to detect device failures and issues via the `btrfs device stats` command. If any device stats show a non-0 value, this indicates there is an issue with the array and it's possible it's degraded. When a disk flakes out or fails for example, the device stats will indicate write errors. It is absolutely critical to monitor btrfs device stats to detect a degraded array event for a running array. Thus, this feature request is to have this critical feature be included in the unraid GUI when you're viewing a pool, and also have any non-0 value device stats be notified to the admin so they can act on it. Given that being able to reset these device stats to make detecting errors later possible, we'd also need a GUI option for resetting device stats after any issues are addressed. I have some other ideas to make btrfs pools more resilient and efficient (particularly around the fact I feel unraid will run balances much more than necessary) but that is left for a separate feature request, device stat monitoring is the most critical feature request I believe is a requirement for proper pool monitoring.
-
Yep the issues with NOCOW being used by default go well beyond unraid, thankfully unraid has reverted this default in newer versions it seems. Now on to libvirt. I've also noticed some distros (like Arch) are utilizing systemd-tmpfiles to set the +C attribute on common database platforms as well, such as mysql/mariadb and postgresql. It's nice to see bcachefs finally merged and I hope to one day see unraid support it since it does potentially provide the same flexibilities as btrfs, potentially without the caveats that btrfs has. It too supports NOCOW and from my testing before it was marged, it was a mkfs option rather than a file attribute, at least at the time i tried it, so it seems in that regard nocow won't be an issue since you just wouldn't use it lol. It does however still need a lot more attention with regards to it's raid functionality and is missing features like scrub, rebalance, device monitoring, etc. When it sees improvements in these areas and proves itself to not be a data eater, I'd be happy to migrate over to it one day
-
Unraid is open source as far as the storage stack is concerned. 1. The UnRAID array uses a modified version of MD RAID, which has all of its corresponding sources stored right on USB that you could use to compile your own kernel with 2. Pools use Btrfs (and ZFS as of 6.12). A pool created on UnRAID is completely usable on other systems without any tinkering. XFS pools are single disk and mount like any single disk filesystem. 3. Disks inside your UnRAID array are independent formatted disks individually, with a dedicated parity disk. Nothing is striped, nor stored in any obscure, proprietary format. Even without the custom patches, all the data on disks are fully available and mountable on any standard linux distro. Additionally, docker containers use standard docker which can be used on standard linux. You can quite literally take the variables you set in the UnRAID docker web UI, pass them to docker on any standard linux distro, pass in the same data/mounts, and everything works perfectly. VMs are the same. They use bog standard KVM via Libvirt and QEMU, also readily available on most common distros. Rest assured, you're never locked in when it comes to your data with UnRAID. The true magic of UnRAID is the web UI and ease it provides for managing and monitoring the array. For that, it's very much worth it, even with some of its shortcomings imo, it still gets the closest to what I want in a storage+compute OS for personal use
-
The current unraid default when you enable compression on btrfs in 6.12 is compress=zstd. (can be confirmed with mtab). However, this is generally not recommended by most in the btrfs community. Instead, compress-force should be used instead. The reason is, with compress, if the first 64KiB of a file is not compressible, Btrfs will not even attempt to compress the rest of the data. Compress-force meanwhile will attempt to compress the entire file, even if the first 64KiB isn't compressible (which can definitely be the case for many files). Using compress-force wont have any noticeable impact on performance, and in no case will it use more disk space. ZSTD compression is blazing fast, and any data that isn't compressible will be discarded anyway. Doing this will significantly increase compression ratios. Benchmarks a few years ago show default level 3 compresion, which Unraid is using will achieve over 800MiB/s on a Xeon E3 1650, so only on NVMEs would it potentially be a bottleneck. That's a rather old CPU as well, newer CPUs will be even faster.
-
I'm aware of that, but what I mean is, I still want to create individual shares at the directory level (or more specifically, subvolume) for security reasons (each user gets their own share), but not have it run through shfs... in other words, *not* through /mnt/user. A disk share exposes the entire disk/pool, which is undesirable. My "hacky script" does exactly that. Since I don't use the unraid array at all, I rewrite the /mnt/user path to /mnt/storage (name of my btrfs pool) in samba's config to bypass the shfs bottleneck. I also add in shadow copy paths to snapshots so I can have shadow copy support, but at the very least, would be nice to bypass shfs when pools are exclusively used to avoid the bottleneck of shfs on faster networks.
-
I'm curious, does unraid 6.12 bypass shfs (Sharefs) if you use ZFS (and potentially btrfs pools). I find shfs is my biggest bottleneck, and since I exclusively use Btrfs anyway, I'd like to have a way to bypass it. Currently, I have a user script I wrote that rewrites the samba config at startup and then restarts samba lol. That's hacky imo, wish there was an official way to bypass that, especially with stuff like ZFS coming.
-
Well in that case, can I ask for it lol? Now that the linux kernel has NTFS3 it'd be nice to support that as well (it has full POSIX ACLs support too for those who need it!!), and it would allow someone to easily move their data over from Windows machines without formatting anything. I've also mulled the idea of being able to easily support "no filesystem", or at least, Btrfs pools within the unraid array. Then you could use a Btrfs RAID0 to take advantage of snapshots a lot easier and gain the read speed benefits. Then I could better take advantage of 10G on the unraid array itself. You'd also have the ability to add and even remove one disk at a time, and since btrfs now now has "degenerate stripes", even if data is already allocated it can still effectively use all the space, minus the speed improvement. It would never be worse than using independent filesystems speed wise, and balance would fix that up. You'd still lose out on write speeds since the parity disk is the bottleneck, but you'd gain "stable" parity protection in the event of a drive failure. I've hacked this together before, but with the current design of Unraid and it's GUI, it's really not ideal. It's flexibility like this that I'd love to see more of from Unraid, more so than ZFS. That said, very excited to see the inclusion of ZFS support
-
Nah I get it, the problem is a lot of those distros are using out of tree drivers which can be a huge burden to maintain and often interfere with other drivers and/or break after a kernel upgrade if they're not well maintained. So it's not as clear cut in unraids case where the maintenance burden is too high to support every possible NIC out there. This is really a realtek specific issue for not having proper mainline drivers.
-
Debian and slackware have nothing to do with it. Limetech maintains their own kernels for unraid and they are much fresher than both Slackware and Debian. The latest in unraid 6.11 is 5.19. It is up to the driver vendors (or linux community in the case of community made drivers) to get their drivers mainlined with the kernel.
-
I don't know what you mean by this. What's not true? You can't run windows as a linux "container", it would need to be virtualized I guess you could run QEMU or something in a container, but it's still going to be a VM at the end of the day, it would be a VM with extra steps. I suppose you could do all the virtualization in software, in a container, but that would be extra slow, so I'm assuming you'd still be using KVM, which is what I mean about a VM with extra steps... might as well just avoid containerizing all that.
-
Just to be clear, LXD also allows managing VMs since it's just a frontend for managing Containers and VMs, so this is how you'd run Windows with LXD. Windows can't run as a container because it's a literally different OS for those wondering. LXC works by sharing the same kernel and containerizing everything, so think of it like a glorified chroot environment. Anyway, it seems totally unnecessary for this purpose, as Unraid already has excellent VM management with libvirt and the webUI. If people need windows for something, use the VM platform unraid comes with.
-
To be clear, if you use a Btrfs pool, Unraid defaults to async discard, so it will TRIM without any configuration needed.
-
Hey, thanks for the prompt relies everyone, glad to see there's interest in addressing it so fast, it's appreciated! Basically not at all. MD and LVM use bitmaps that help it identify if the array is degraded during a crash, but Btrfs has no means of doing this with NOCOW data, checksums of the actual data are the only way under the current design. The metadata is always COW and protected with checksums, and any newly allocated chunks will involve it having new transid, but once it's allocated, it's sort of set in stone unless you run a defrag or something that involves rewriting it. Yep there certainly is, the "Friends don't let friends use Btrfs for OLTP" article showcases it quite well, better than my quick pgbench runs. Yep exactly, and as long as COW can't be done, there would always be a portion of time where the checksum wouldn't match if one went with the RMW option. It would be better do something like a bitmap like MD does, but the impression I get from Btrfs devs just from reading the mailing list is there's not much interest in working on NOCOW. Generally yep, as long as NOCOW is used of course, simply because it (usually) involves allocating large extents from the get go. Depending on how fragmented the free space is, there may be less and less benefits from this, but since a balance operation is effectively a free space defrag, if the fs is well balanced before going in, it should be fine. Yea this is a problem. If you copy the files to a directory that doesn't have the NOCOW flag set, and the copy is not a reflink copy (ie with cp --reflink=never), then it should generate checksums for the new copy, as this is just the inverse of what the Btrfs wiki suggests for "converting" an existing COW file to NOCOW, but the downside of course means the data needs to be duplicated. Simply moving on the same volume won't convert to COW/generate checksums. That's what led to my other post... there is no great option here for existing setups. Perhaps there could be a yellow icon or something to indicate the redundancy is not perfect or something if the attribute is detected on a share on a cache pool. Better than no indicator at all I guess. I dunno, lots of options here but none are perfect lol. The NOCOW flag does especially make sense on devices that are on the parity protected array for VMs, since any array device should be a single device anyway, and they're usually spinning rust, so it's especially important. Perhaps one could even provide an option to only set NOCOW on the array disks only where it's less risky, but have the cache pool option NOCOW option could be separate and default to COW since it can span devices (and I would guess most users have SSDs in Cache pools anyway). That's on top of warning the user about the option in the Share settings when they click on it, and you could even go one step further and warn them anytime a scrub is ran and any data without checksums is found. While Btrfs scrub doesn't do anything with NOCOW data, it still does indicate it finds data without checksums with the -R flag to indicate nothing can really be done with it. A notification could be triggered after a scrub if this is detected to let the user know unprotected data was found and left untouched, and they may need to manually intervene if they have corruption. Documentation or something could further explain that if a user encounters that notification, the most likely cause was probably because the NOCOW attribute is either used now or in the past, and then it could offer mitigation strategies if the user wants to act on it). This sounds awesome! Hopefully LVM and LVM RAID can be used for more than just VM vdisks too I personally love the ideas behind Btrfs and it's flexibility, the flexibility alone is like no other solution, so that seems to make it a good fit for Unraid, but the quirks sure are plentiful. Here's to hoping Bcachefs eventually makes its way in the kernel someday, performs well, and is stable. Maybe it could be a good successor in a few years
-
I will say, if there is no decision to leave COW enabled going forward, there should at least be a warning included on the option, and if it's been used, unraid should show a yellow circle on the share to show it's not properly protected if any VMs or the directory itself has the nocow attribute set.
-
I'd also like to see some form of LXC or LXD support, it would put the feature set a bit more in line with proxmox and would definitely be more useful to me than docker. +1
-
Definitions and Preamble Skip this section and read the next one if you already understand what COW is and how Btrfs works. To users who are unaware of what COW, and subsequently NOCOW is: COW stands for copy-on-write, as such, NOCOW is the absence of COW. Btrfs (and ZFS) are COW based filesystems, in contrast to something like XFS, ReiserFS, EXT4, NTFS, etc. While those filesystems overwrite blocks in place when an overwrite request is made, copy-on-write filesystems always write any changes to newly allocated space, even if a portion of the file is "overwritten". Once the change is written to new space, it will then update metadata references to reflect the new state of the file. This is how modern filesystems are able to achieve "atomicity" without using a "journal". (Now I recognize this is a simple definition, but I think it gets the point across to those familiar with filesystems, after all, metadata operations also use COW, but this should be enough for most people to understand.) Basically, if any filesystem operation is interrupted on Btrfs or ZFS (such as a system crash, power failure, or a flaky disk), if the change has not been fully committed to the disk(s), the old state is retained on the disk(s). There is no need to run any fsck or do anything extra even for metadata, since the change was not fully committed. That's the idea behind atomicity, either the entire operation is completed in full, or it didn't happen. Most journaling filesystems (apart from ext4 in certain scenarios) do not support journaling of data blocks anyway (doing so would kill performance). There's not really any need to do this anyway, since these filesystems can only ever exist on one disk anyway (as far as they're concerned). If these filesystems are used on any form of RAID, it is that RAID platform that needs to ensure everything is in sync. Whether that's a battery backed raid controller, bitmaps like MD and LVM uses, whatever. Unraid does indeed also work to ensure it's own parity is in sync with a parity sync operation in the event of a system failure for it's array devices. Running a scheduled parity check is also encouraged of course in case something goes wrong during normal operation. While unraid can't avoid the "write hole", at least it can be mitigated. Btrfs and ZFS are different though. As we know, they are the RAID platform in addition to simply being filesystems. There are pools of multiple disks that these filesystem can exists on. Btrfs supports it's own unique spin of "RAID1" (among other profiles) as does ZFS. Since they're handling redundancy, extra thought needs to go into ensuring redundant copies of files are always in sync. When you use a RAID1 profile with Btrfs, a file is replicated across 2 devices, so there's effectively two "copies" of the same file. The Issue Since a Btrfs Cache pool in Unraid can span multiple devices, it needs to ensure atomicity of redundant copies on the pool disks to provide reliable redundancy. It is impossible to write to each disk at the exact same time since they are still two physically different drives. If the system crashes when one disk had a change written to it but the other one didn't, now your redundant copies may be out of sync, similarly to how your parity disk(s) can be out of sync when it comes to the unraid array during a crash. Now, thanks to copy on write, this problem is properly addressed. If either disk is out of sync, the old copy still exists. Btrfs provides checksums that can further be used to verify each copy is exactly the same. If they are not, they will "self repair", and a scrub triggers the filesystem to read each and every file and verify their checksums, repairing it if they mismatch using the other copy. ZFS of course does the same thing. However, when NOCOW is in use, both checksums and atomic updates of the data blocks are gone. While other software RAID solutions do allow for ensuring things are in sync without copy on write, Btrfs does not, as such NOCOW is not intended to be used on anything other than "disposable data". NOCOW makes Btrfs work more like the traditional filesystems for data blocks, but along with that comes significant gotchas that people seem to be quite unaware of. (ZFS has no concept of NOCOW, so it's not an issue for it). There is no way possible to ensure both copies of a NOCOW file is in sync on Btrfs if any of the RAID1,10 or DUP profiles are used. Btrfs does not provide *any* method to fix out of sync NOCOW files when it does go out of sync (scrub only verifies checksums, and since NOCOW has no checksums, it doesn't touch nocow data). To make matters worse, anything as simple as a power failure can trigger this situation if a VM were in use, and anyone using Unraid with VMs can run into this corruption scenario in the default state. Further, Btrfs doesn't have a concept of "master" and "slave" drives, it decides which copy to read based on the PID of the process. To the user, this effectively means the disk a file is read from is "randomly" selected. So in an out of sync scenario with VM disk images, even if one copy was valid, if it reads the invalid copy, it may (and will) end up corrupting the good copy. Then when it reads the other copy, it detects corruption, and so on.... you're stuck in a vicious cycle. There was a long discussion on the Btrfs mailing list about this a few years ago, but the TL;DR of it is while there were patches submitted to allow btrfsck to identify this issue, they were never committed to master, not that anyone let alone Unraid uses btrfsck in the event of a crash, scrub and balance is the usual recommended course of action, depending on the scenario. Using Btrfsck can be dangerous without developer advice anyway. This issue would apply to RAID1, RAID1c3, RAID1c4, RAID10 and the DUP data profiles of Btrfs, since all of these profiles involve making "copies". If the user is using a single disk with the SINGLE profile, if they're using multiple disks with RAID0, or ironically, if they're using Btrfs' grossly unstable RAID5 or RAID6 profiles, the issue doesn't really exist since there is only one copy of the data in these cases (or in the case of RAID5/6, scrub will repair out of sync parity since there is no duplicate copy in that case. Instead, RAID5/6 suffers from the actual same write hole issue Unraid's parity protected array can suffer from). Now users may be wondering: Why is NOCOW even an option then? Well the issue with Btrfs in particular is it is not well optimized for workloads that involve a lot of small writes to the same file. This is exactly the type of workload that makes it less than ideal for things like VMs, Databases and even Bittorrent downloads. While ZFS can be tuned and has more complicated caching schemes to mitigate this, Btrfs simply doesn't scale well when it comes to tiny writes to files. Each time a write is made, the metadata tree needs to be updated to reference a new extent that will be rather small. As more and more tiny writes are made, this tree can get very "top heavy", and it too can become fragmented. Processing the tree alone can be expensive on system resources, even when an SSD is used. NOCOW is a way to avoid this fragmentation. I briefly discussed this with @jonp on Discord a while back, with regards to performance, and he suggested to do some benchmarks. So I took the time to do some quick benchmarks to show the difference (and also showcase how sparse allocation isn't the greatest with NOCOW anyway). I've ran these benchmarks with the Phoronix Test Suite. The benchmark was pgbench to show a certain workload that involves a lot of small writes. This all was done on Ubuntu 22.04 using the ext4 filesystem as the VM filesystem (since these are vdisks, Btrfs COW is still at work here). The VMs all used VirtIO SCSI as the vdisk controller, with caching disabled. The Btrfs pool is on a Btrfs RAID1 pool with an 860 EVO and WD Blue SATA SSD. The system specs for the VM were indeed limited (only 2 cores on a Ryzen 5 3400G), however I think it still showcases it quite well. I did three tests. The first was a VM with on a NOCOW Cache pool using a sparsely allocated image, just as unraid behaves out of the box with cache pools. The filefrag indicated this VM had ~30k extents allocated after a single benchmark pass. Over time, as the vdisk fills, this number will increase, but since it's NOCOW, it won't increase once allocated unless snapshots or reflink copies are made. Still, it does not provide the best use of the NOCOW attribute. The second one was a VM on a NOCOW Cache pool but the VM disk image was preallocated using fallocate to reduce fragmentation as much as possible. The filefrag command indicated this VM only had 5 extents both before and after the benchmark. The third was to just straight up use COW (there was no need to make the differentiation between preallocation or not in this case since COW would be used regardless). The filefrag command indicated this VM had ~1.2 million (yikes!) extents after the benchmark ran. You'll notice the difference between the most optimized NOCOW VM and the one with COW is double the average latency. The Unraid default state was dropped somewhere in the middle, so even then, Unraid's current default isn't the most ideal performance wise. However, in the case of cache pools, when redundancy is used, there's no way to escape a corruption scenario. Why not use autodefrag? Autodefrag is proposed to be a solution for desktop use cases, by grouping up small writes to Btrfs to be rewritten in larger extents. However in the case of workloads like VMs, autodefrag ends up causing write amplification, since it is effectively rewriting existing data. It is really only intended for desktop use cases where small databases may be used for applications like web browsers, and the writes to these databases are generally negligible. So what can be done? My suggestion is to simply just leave COW enabled (AUTO) for the domains share by default going forward for all new unraid installs. Users should accept the performance impact it may bring along unless they so choose to disable it, especially since the performance for many use cases may be perfectly acceptable, especially for a home use cases. Btrfs is a COW filesystem, so CoW should be expected to be used unless otherwise disabled. As was mentioned in this "rant" here, regular users don't set NOCOW, "admins" do, and using it "downgrades the stability rating of the storage approximately to the same degree that raid0 does". Leaving the current default gives Unraid users a false sense of redundancy (and I would argue unraid is intended to improve the UX around redundancy, so I think this default option is contrary to that). If users have a performance complaint, it would be better to clearly note the implications of using NOCOW if they so choose, or they can choose to use an XFS formatted cache pool. At least in that case there is no false sense of redundancy. And regardless, there's been feature requests and plugins that propose adding snapshots for VMs anyway. Both XFS and Btrfs support reflink copies after all. Yet doing so triggers Copy-on-Write, completely negating the gains of using the NOCOW attribute.
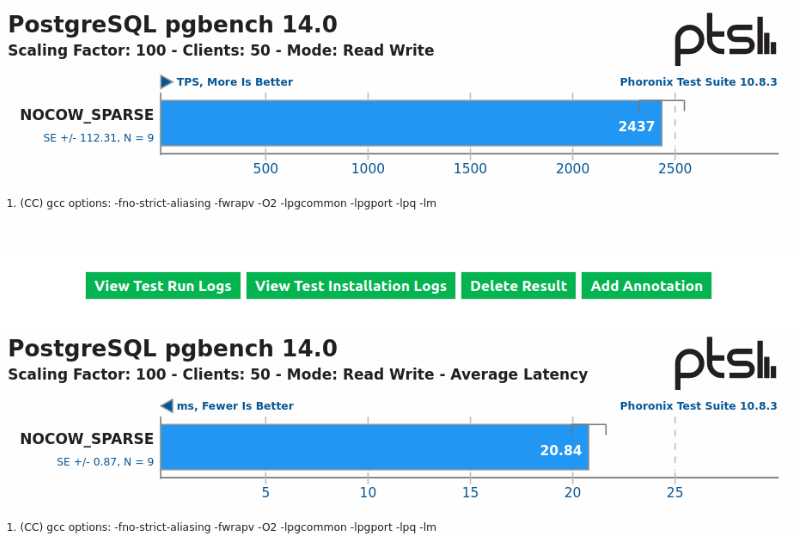
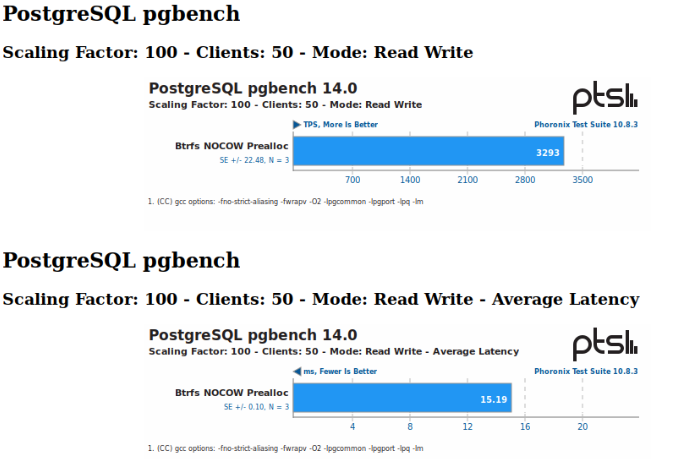
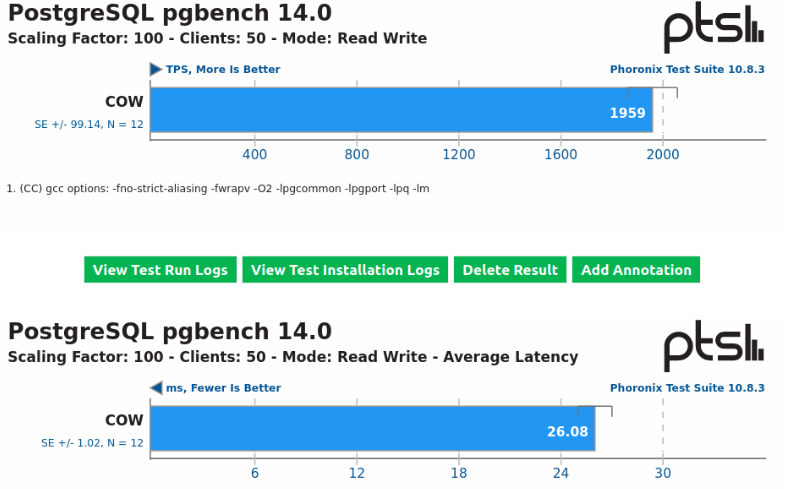
-
From what I read, RTL8156 USB NICs were supported in the past with unraid, however if this is true it doesn't work now, as I just purchased one of these NICs and RC4 and RC5 don't have working drives for it. From what I see this should be in the mainline kernel since 5.13.





