




audioclass
Members
-
Joined
-
Last visited
Everything posted by audioclass
-
Yes, I have the same issue. It is particularly annoying as the ls.io team doesn't seem to be demonstrating ANY consistency in how they push the updates. Sometimes they build the container after maintenance mode has been disabled, sometimes before. Manually updating may not have been as smooth, but it was far more predictable and I wish we could go back. As it stands now, it is a complete shit-show, for lack of a better term. It is completely unpredictable and the only way around it is to verify you are out of maintenance mode after every update and run the following if not. docker exec -it nextcloud occ maintenance:mode --off I would also suggest disabling the automatic container updates, you'll break something at some point at an inconvenient time by allowing updates to just blow through at random times.
-
This is probably the second or third time this has happened, but when updating the container, maintenance mode ends up being left on. Is this intentional? It's trivial to shut off, but seems odd that it only occurs sometimes.
-
Could we get an option to link container shutdowns? For example, tdarr and tdarr_node being shut down and backed up together? If one or the other writes to to a log file (they share a directory) during a backup, verification will fail. You can *sometimes* work around this as posted previously by only enabling one of the backups to take these folders into consideration, but that can't fully prevent the issue from occurring, as the online container could still write to those areas during the backup. It would be useful if I could specify that when shutting down container X, also shut down container Y, before backing up and restarting the containers. Of course, selecting the option to shut down all containers at once is a workaround, but not one that is probably desirable since the downtime will be significantly higher.
-
Wow, this might be the issue. The xml does not contain an entry for ManualPortMappingMode. I'm going to backup the file and then add that entry and see what happens. If this fixes it I'll feel dumb Edit: I shut down the container, edited the file to include that setting, and started the container only to find the setting unchecked again. Blast! BUT! After repeating the process and adding both that setting AND ManualPortMappingPort="32400" (from the preferences.xml documentation, it worked! Upon starting the container remote access was enabled, and after a couple restarts it is STILL enabled! Woohoo! I'm going to keep holding my breath over the next few days to see if it happens again, but so far I think you've helped me solve the issue. Thank you @extcon !
-
Yeah, exactly that. It all works fine, I can set a certain bandwidth (ex 10MB/s) for remote users and they can reach that quality. Then, for whatever reason if the container has to restart for any reason (updates, regular backups which restart the container, etc.) the setting becomes unchecked, at which point remote access is disabled and they are forced through the plex relay which has a paltry 2MB/s limit and looks terrible.
-
I think most people are confusing what I mean. It isn’t just a matter of people being randomly unable to connect to me. The actual SETTING in Plex is unchecking itself randomly any time the container restarts due to updates or backups. It is the only setting that this occurs with.
-
I do have plexpass. But I fail to see how giving family access will resolve this issue, since they would STILL be unable to access remotely once it decides to switch itself off again in two days. I don’t wish to use a reverse proxy or UPnP, as the built-in remote access is the solution I’m looking for. Anyway, thanks for the replies, it seems I’m probably on my own to figure this out. I will try some different containers as suggested to see if it is unique to the LS container. Sent from my iPhone using Tapatalk
-
Unfortunately, it isn’t just a cosmetic issue. It seemed like it at first, because it would often still say it was reachable. Now, though, I’ve confirmed that it forces my users onto the relay, locking them at SD resolutions. I also don’t have this issue with a test server that isn’t containerized. Sent from my iPhone using Tapatalk
-
Sorry to keep dragging this up, but is nobody else running manual port mapping and having this issue? It is driving me wild that every couple days this setting just reverts itself and my users are stuck with plex relay quality. I really don't want to enable UPnP or give direct access via a reverse proxy, but I'm running out of ideas. I can't find any information on this. Do I have something misconfigured?
-
Anyone have any clue on this? Every time I update I have to change this setting back again, and any time it is disabled my users are passed through the plex relay which limits bandwidth/resolution.
-
This worked, I stopped the container, added the steamapps directory to the gameserver's appdata folder, restarted and everything seems to be coming online.
-
Oh, that was only done because of this issue. I tried running as privileged just in case that was the cause, but as you can see, it wasn't 🤣
-
Yes, I have tried removing the containers, and completely deleting the associated folders (steamcmd, valheim(after grabbing a backup) and conanexiles) before grabbing a fresh container from CA. Sadly even this seems to have no effect. Is it an issue with my appdata folder itself perhaps? I'd prefer not to wipe that out if possible, but it is seeming more and more likely
-
Yes, the path /mnt/cache/appdata/conanexiles exists, as does the /mnt/user/appdata/conanexiles. I have tried both just in case. Here is a screencap of the docker settings screen. I believe it is mostly default aside from having swapped the /serverdata/serverfiles/ path back and forth between /mnt/user and /mnt/cache during this troubleshooting process. Sorry if the image is huge, 4k monitor: Edit: Also, if it is worth mentioning, the rest of my containers are working alright(nextcloud, mariadb, sonarr radarr etc.), updating fine and such. And, my valheim server worked fine in the past, but has the same symptoms as this conanexiles container now. Edit 2: I also just noticed I appended / to the end of conanexiles, but not steamcmd. I tried removing this just in case that was somehow causing problems but the issue persists.
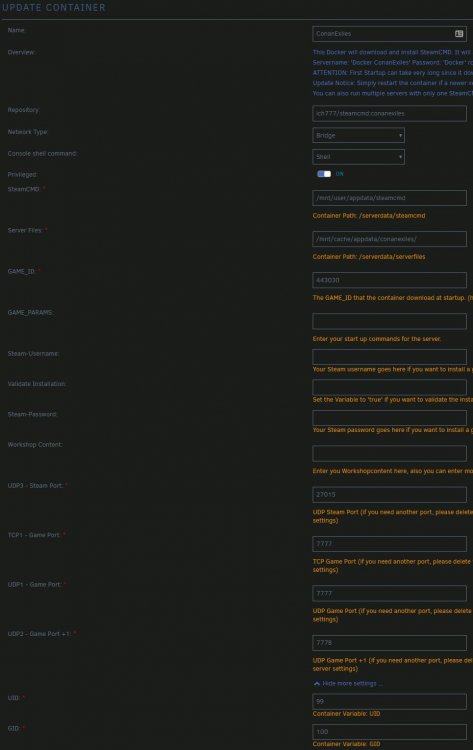
-
Error is persisting after this ---Checking if UID: 99 matches user--- usermod: no changes ---Checking if GID: 100 matches user--- usermod: no changes ---Setting umask to 000--- ---Checking for optional scripts--- ---No optional script found, continuing--- ---Starting...--- ---Update SteamCMD--- Redirecting stderr to '/serverdata/Steam/logs/stderr.txt' [ 0%] Checking for available updates... [----] Verifying installation... Steam Console Client (c) Valve Corporation -- type 'quit' to exit -- Loading Steam API...OK. Connecting anonymously to Steam Public...Logged in OK Waiting for user info...OK ---Update Server--- Redirecting stderr to '/serverdata/Steam/logs/stderr.txt' [ 0%] Checking for available updates... [----] Verifying installation... Steam Console Client (c) Valve Corporation -- type 'quit' to exit -- Loading Steam API...OK. "@sSteamCmdForcePlatformType" = "windows" [0m Connecting anonymously to Steam Public...Logged in OK Waiting for user info...OK ERROR! Failed to install app '443030' (Disk write failure) ---Prepare Server--- ---Looking for config files--- ----------------------------------------------------------- ---Something went wrong can't find folder 'ConanSandbox'--- --------------Putting Server into sleep mode--------------- I checked access after with stat: root@Serenity:/mnt/user/appdata# stat steamcmd File: steamcmd Size: 100 Blocks: 0 IO Block: 4096 directory Device: 32h/50d Inode: 13510798885729765 Links: 1 Access: (0777/drwxrwxrwx) Uid: ( 99/ nobody) Gid: ( 100/ users) Access: 2021-06-07 22:48:32.915992336 -0400 Modify: 2021-06-08 12:00:26.725914370 -0400 Change: 2021-06-08 12:00:26.725914370 -0400 Birth: - root@Serenity:/mnt/user/appdata# stat conanexiles File: conanexiles Size: 0 Blocks: 0 IO Block: 4096 directory Device: 32h/50d Inode: 13510798885729766 Links: 1 Access: (0777/drwxrwxrwx) Uid: ( 99/ nobody) Gid: ( 100/ users) Access: 2021-06-07 22:48:32.915992336 -0400 Modify: 2021-06-07 22:48:32.915992336 -0400 Change: 2021-06-08 12:00:24.142910874 -0400 Birth: - Edit: The weird part is that the container MADE these folders successfully, and was able to download/extract all of the info to steamcmd folder without trouble. I'm lost haha.
-
Yes I can get to them in the terminal, what exactly should I do?
-
My cache is set to prefer for appdata and I’ve confirmed that everything appdata related IS on the cache. Any other ideas what it might be?
-
Hi, I'm having some trouble getting any of these containers to work now. I replaced my cache drive a few weeks ago, restored everything from a backup and haven't really gamed since then. Now, whenever I try to run, or even re-install (for example) conan exiles, I get the following in my logs. Connecting anonymously to Steam Public...Logged in OK Waiting for user info...OK ERROR! Failed to install app '443030' (Disk write failure) ---Prepare Server--- ---Looking for config files--- ----------------------------------------------------------- ---Something went wrong can't find folder 'ConanSandbox'--- --------------Putting Server into sleep mode--------------- I've searched as much as I could, and didn't run into anyone with this specific issue. What am I look for here exactly to get these back up and working? Any help is appreciated, and let me know what else I need to post info-wise. Thank you!
-
I'm experiencing a minor issue/inconvenience on a consistent basis. Any time my container is restarted, my Settings > Remote Access configuration is unchecking the 'Manually specify public port' setting, which prompts the screen to indicate that my server is not accessible remotely. I can recheck the box, and press apply, and I then get the green 'Fully accessible outside your network' message again. So far, this has not actually impacted the ability of my users to access, despite the message, but it is annoying to have to keep turning it back on again. I also fear that if my firewall states get cleared during that period it WILL cause issues. Any idea why this setting does not persist through a restart? I've tried searching for similar cases but haven't had much luck. Of course, if I switch to UPnP this is a non-issue, but I'm keen to keep this disabled on my firewall for obvious security concerns.


