




ds123
Members
-
Joined
-
Last visited
Everything posted by ds123
-
Hi, I switched to safe mode lasy friday and disabled all docker containers and VMs. About 5 days later, the server crashed. This time the server didn't restart by itself - I found the server off and had to press the power button to start it again. Nothing relevant was logged to the local syslog file, in fact there are no logs from the day the crash occurred. Does this mean it's a hardware problem? What is the next step?
-
What capabilities are affected by switching to safe mode? will the array be inactive? If it's a hardware issue, how to identify the faulty hardware?
-
It configured correctly, there is a syslog file in the share and logs are written, it just don't have any log from the crash
-
Hi, I enabled the syslog server logging to a local cache share (to avoid a lot of writes to the flash drive). Today, a week after, the server crashed again and started a parity checl again. However, the local syslog file doesn't have logs prior to the crash (the last log before the crash was written an hour earlier). Two questions- 1. Is using a local file for the syslog server problematic to catch crash issues? If so, will writing to the flash drive help? 2. Is it safe to stop the parity check? it's the third time over the past 3 weeks the system runs a parity check due to this issue.
-
Hi, My server crashes randomly every once in a while (twice already this month) causing multiple parity checks. This started happening recently even though no new containers or plugins were installed. Attaching diagnostics taken after the last crash. What could be the issue and what is the best way to find the root cause? tower-diagnostics-20231124-0040.zip
-
Thanks. Changed to ipvlan, so far no issues.
-
Thanks for the quick reponse. Will I be able to keep the same network settings in each of my docker containers? including my user-defined network, br0 and host? Or should something change?
-
Hi, After upgrading from 6.11.5 to 6.12.1 I received the following error from the Fix Common Problem plugin - I never had this error before 6.12.x. For now, the server is working properly so there is currently no impact. Can someone please help in understanding this error? Should I change to ipvlan? What are the implications of doing this? In terms of my docker network types - I created a custom network for most of my containers. In addition to that, I have one container that uses br0 (pi hole) with fixed ip address and another containers that use host network (plex and duckdns). Wanted to make sure nothing breaks if I change the docker custom network type to ipvlan. Thanks,
-
So after about a year that this problem occured relatively rarely, in the last few weeks Disk 1 (the same disk) disappears every few days and even several times a day (until restart), so now I'm worried and looking into it more deeply. I switched both the SATA and power cables of Disk 1 with another disk in the array to see if the problem recurs with another disk. To my surprise, today the problem occurred again with the exact same disk - Disk 1. The log is the similiar to the log JorgeB referred above (this time with ata6) - Since it always happens with the disk, even with different SATA and power connectors, does that mean there is a problem with the disk itself? or maybe 7 disks are too much for the MB/PSU (still unclear why it's always the same disk). should I replace it and activate warranty in this case? other than disappearing, the disk is healthy.
-
Happened again, attaching diagnostics (before reboot) - tower-diagnostics-20220322-1339.zip
-
I have attached the diagnostics of my system after rebooting. I currently don't have the diagnostics when the problem occurs, but I will try to download next time it happens. tower-diagnostics-20220310-2128.zip
-
Over the past few weeks, in two different cases Disk 1 was missing and the array was stopped. Restarting the system solved the problem. The SMART test is ok, and parity check has passed without issues. What could be the problem? this is a new disk (about 5 months old).
-
Could you please elaborate how you migrated to MySQL? I have thousands of records and I don't want to rebuild the DB from scrtach.
-
have you managed to solve the problem?
-
I have the same issue.
-
So if pricing is not a factor, are you saying it doesn't really matter whether it's an enterprise drive or not? I'm mainly concerned about the noise level and temperatures, because enerprise drives are designed for use in data centers, where noise is less important and where there are massive cooling systems.
-
They actually seem to be sold at a much lower price, for example - WD RED Plus 14TB - 410$ https://www.amazon.com/Western-Digital-14TB-Internal-Drive/dp/B08V13TGP4 Toshiba MG Series Enterprise 14TB - 330$ https://www.amazon.com/Toshiba-14TB-SATA-7200RPM-Enterprise/dp/B07DHY61JP
-
Perhaps the question is more general, whether enterprise drives are suitable for a home unraid system. Does anyone have any experience with such drives?
-
Hi, Toshiba Enterprise hard drives seem to be sold at a much lower price than traditional NAS hard drives like WD RED. Are they suitable for home use in an Unraid system? In terms of reliability, noise, temperatures. Specifically asking about MG08 14TB with helium inside - https://www.newegg.com/toshiba-mg08aca14te-14tb/p/N82E16822149785 My current setup: Wanted to replace the 6TB data HDD (which is more than 5 years old) with 14TB. Thanks
-
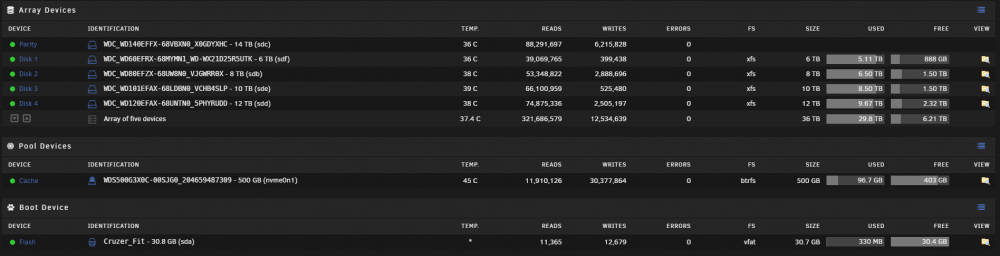
Sure, thanks. tower-diagnostics-20210821-1129.zip
-
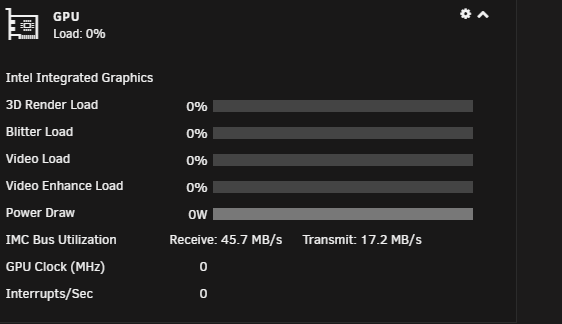
IMC Bus Utilization is always active, is this normal? Also, the Power Draw also seems to be "full" even though 0W is consumed
-
Thanks
-
@mason MediaElch continues to crash also in 2.8.10
-
I think there is a bug in the latest release. Sometimes when clicking on "reload all concerts", the containr crashes and stops. Didn't happen in the previous version. My settings - Logs - MediaElch 2021-05-03 19:07:43.092 DEBUG : [ConcertFileSearcher] Adding concert directory "/concerts" MediaElch 2021-05-03 19:07:43.094 DEBUG : Index is invalid [services.d] stopping services [services.d] stopping app... [services.d] stopping x11vnc... caught signal: 15 03/05/2021 19:07:43 deleted 50 tile_row polling images. 03/05/2021 19:07:43 Restored X server key autorepeat to: 1 [services.d] stopping openbox... [services.d] stopping statusmonitor... [services.d] stopping logmonitor... [services.d] stopping xvfb... [services.d] stopping nginx... [services.d] stopping certsmonitor... [services.d] stopping s6-fdholderd... [cont-finish.d] executing container finish scripts... [cont-finish.d] done. [s6-finish] syncing disks. [s6-finish] sending all processes the TERM signal. [s6-finish] sending all processes the KILL signal and exiting.

-
https://github.com/qbittorrent/qBittorrent/issues/11150 It fails because qbittorrent doesn't have access to private trackers. I found a workaround - install the Jackett docker, then configure an indexer for the private tracker, then enable the Jackett search plugin in qbittorrent, search and download from there.



