



.png.09a6e6756a1058c09d4c8b3c1e95b829.png)
Phuriousgeorge
Members
-
Joined
-
Last visited
-
Just wanted to say thank you @Rysz for putting this together, it's been on my wish list for awhile now as an alternative setup! Time to put my concept to the test and though I'm horrible at it, hopefully I'll report back.
-
Phuriousgeorge changed their profile photo
-
Actually had my header info lost on a drive not long after migrating data due to a power loss I believe and lost about half the data on the drive. This would be very much appreciated.
-
You cannot choose the container. Relevant section of the docs: https://github.com/tubearchivist/tubearchivist/wiki/Settings#download-format I've got a pretty specific format preference, for 1080 it's: (bestvideo[vcodec^=av01][height=1080][fps>30]/bestvideo[vcodec^=vp9.2][height=1080][fps>30]/bestvideo[vcodec^=vp9][height=1080][fps>30]/bestvideo[vcodec^=avc1][height=1080][fps>30]/bestvideo[height=1080][fps>30]/bestvideo[vcodec^=av01][height=1080]/bestvideo[vcodec^=vp9.2][height=1080]/bestvideo[vcodec^=vp9][height=1080]/bestvideo[vcodec^=avc1][height=1080]/bestvideo[height=1080]/bestvideo[vcodec^=av01][height=720][fps>30]/bestvideo[vcodec^=vp9.2][height=720][fps>30]/bestvideo[vcodec^=vp9][height=720][fps>30]/bestvideo[vcodec^=avc1][height=720][fps>30]/bestvideo[height=720][fps>30]/bestvideo[vcodec^=av01][height=720]/bestvideo[vcodec^=vp9.2][height=720]/bestvideo[vcodec^=vp9][height=720]/bestvideo[vcodec^=avc1][height=720]/bestvideo[height=720]/bestvideo[vcodec^=av01][height=480][fps>30]/bestvideo[vcodec^=vp9.2][height=480][fps>30]/bestvideo[vcodec^=vp9][height=480][fps>30]/bestvideo[vcodec^=avc1][height=480][fps>30]/bestvideo[height=480][fps>30]/bestvideo[vcodec^=av01][height=480]/bestvideo[vcodec^=vp9.2][height=480]/bestvideo[vcodec^=vp9][height=480]/bestvideo[vcodec^=avc1][height=480]/bestvideo[height=480]/bestvideo[vcodec^=av01][height=360][fps>30]/bestvideo[vcodec^=vp9.2][height=360][fps>30]/bestvideo[vcodec^=vp9][height=360][fps>30]/bestvideo[vcodec^=avc1][height=360][fps>30]/bestvideo[height=360][fps>30]/bestvideo[vcodec^=av01][height=360]/bestvideo[vcodec^=vp9.2][height=360]/bestvideo[vcodec^=vp9][height=360]/bestvideo[vcodec^=avc1][height=360]/bestvideo[height=360]/bestvideo[vcodec^=avc1][height=240][fps>30]/bestvideo[vcodec^=av01][height=240][fps>30]/bestvideo[vcodec^=vp9.2][height=240][fps>30]/bestvideo[vcodec^=vp9][height=240][fps>30]/bestvideo[height=240][fps>30]/bestvideo[vcodec^=avc1][height=240]/bestvideo[vcodec^=av01][height=240]/bestvideo[vcodec^=vp9.2][height=240]/bestvideo[vcodec^=vp9][height=240]/bestvideo[height=240]/bestvideo[vcodec^=avc1][height=144][fps>30]/bestvideo[vcodec^=av01][height=144][fps>30]/bestvideo[vcodec^=vp9.2][height=144][fps>30]/bestvideo[vcodec^=vp9][height=144][fps>30]/bestvideo[height=144][fps>30]/bestvideo[vcodec^=avc1][height=144]/bestvideo[vcodec^=av01][height=144]/bestvideo[vcodec^=vp9.2][height=144]/bestvideo[vcodec^=vp9][height=144]/bestvideo[height=144]/bestvideo[height<=?1080]/bestvideo)+(bestaudio[acodec^=opus]/bestaudio)/best This sets my preferred codecs for 1080, then if that's not available, 720, and down all the way to give me whatever the #$&$^% you can Embed metadata and thumbnail are completely separate settings:
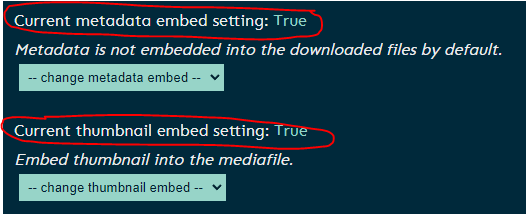
-
Current redis does work, however the migration issue with corrupting the db hasn't been resolved that we're aware of. This isn't an issue with TA itself & I've not seen a fix from redis. What we've had to do to overcome is: Copy out any non-default settings from your settings page Update redis If the fault occurs, delete the TubeArchivist/redis/dump.rdb (path dependent on your installation settings) Restart redis Apply settings copied from step 1 If using your YT cookie, you'll have to re-add it as well
-
This is very odd indeed. I've been using TA extensively with just under 800k videos in my archive. I would personally suggest using Discord or GitHub for support, as the dev of the app will respond there and it's just us users monitoring here
-
Apparently this is a known potential issue that can affect new or updated installations. The fix is documented under "Common Errors" on the projects' GitHub here: https://github.com/tubearchivist/tubearchivist#permissions-for-elasticsearch
-
Looking into this... might be a difference between updating vs starting fresh then. Thanks for the reports, we're looking into it.
-
Honestly can't fathom how adding this variable is "causing" permission errors within the container. Several of us have updated with no issue so the assumption is user-sabotage by finagling inside the container. My suggestion would be to destroy the container and re-create. As long as your volumes are set up correctly (as with most docker deployments) all persistent data will be unaffected.
-
That's all you need. How about your ElasticSearch Data field? Is it nested inside the main TubeArchivist data folder? Are you sure you've got sufficient space and write permission? Otherwise uncertain how you can be getting the path.repo error with that both those set....

-
Can you confirm you have a Variable setup like the following on your ElasticSearch container? The template update got out a little slow for the update:
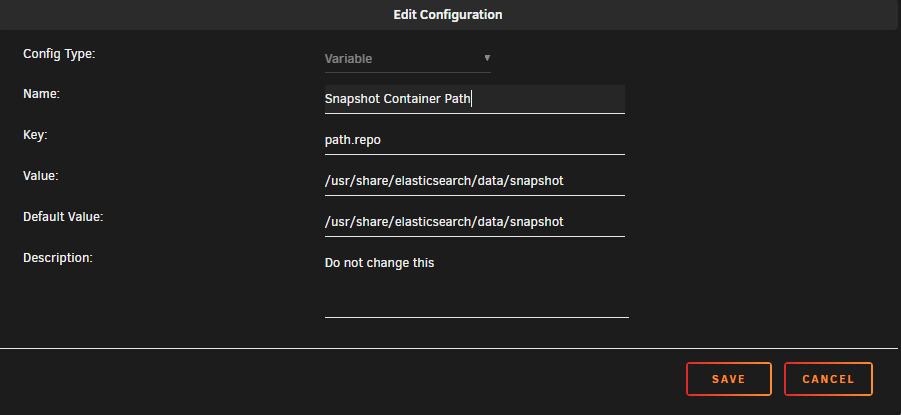
-
Just a note to anyone noticing their docker image size growing leaps and bounds. Found this lovely thread featuring the Calibre developer and his flavor-full short-sightedness regarding an issue which is almost inevitable with Docker or image installs https://www.mobileread.com/forums/showthread.php?t=278484 I had 335GB in my *\appdata\calibre\.local\share\Trash directory. Created a simple userscript to clean it out daily with a simple rm -rf
-
I have no parity in this system at the moment.
-
root@PGVault:~# fdisk -l /dev/sdx Disk /dev/sdx: 9.1 TiB, 10000831348736 bytes, 19532873728 sectors Disk model: WDC WD100EMAZ-00 Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: 8881A93C-7815-4B51-BB9C-B79A125EB4A8 I didn't include the other disk because it consisted of easily-replaceable "Linux ISOs", so I've been experimenting with its headers...and failing.
-
Looking for assistance in recovering two of my data disks (all disks are xfs-encrypted) that have suddenly become "unmountable". I was moving a bunch of small files to the array in Krusader that caused the user mount to go away. I had seen this issue before, as this is a new server setup and I've been mass transferring files, so I made sure everything was stopped and restarted the machine. After entering the decryption key and starting the array, two array disks with content are showing as unmountable and persists through subsequent restarts. From looking at the diagnostics (attached), it appears it's related to: PGVault emhttpd: error: ckmbr, 2263: No such file or directory (2): open: /dev/sdj1 ... PGVault emhttpd: error: ckmbr, 2263: No such file or directory (2): open: /dev/sdx1 Now into my speculations: Somehow it appears these disks have lost their partition table? This is my 1st time dealing with issues on encrypted disks, but I've had to conduct a similar rescue in the past. Is it as simple as re-applying the partition table and viola, the data is accessible again? If so, anyone have a good reference for doing so? It's been awhile and I've got multiples of the same disk type to reference partition layout of. Unraid v6.9.2 pgvault-diagnostics-20211116-1927.zip
-
I'm still in the throws of massive transfers I don't want to bork up. I'll have to attempt again once things slow down.
.thumb.png.05422e9877d5a5eca97995e9303fb269.png)




