




hoppers99
Members
-
Joined
-
Last visited
Everything posted by hoppers99
-
Fair point. I've had issues with temperature warnings on my NVME before and I noticed that the 2 NVME drives are part of the drive list returned within the script so I guess I had assumed I'd be able to use them on one of my fan sets to help bump the airflow if they were heading that way again. If they are cool, then the hdd's should be fine, but the other way around is less reliable (especially as my stack of 8 drives is at the front of the case so they get the first chance at cooler air coming in.
-
Hey Team, Not sure if it's intended etc. and can't find anything specifically related. I have the Fan Auto Control working brilliantly, however it only appears to use the main array drives. The hottest running drive I have generally is the my cache (nvme) drive. The main drive pages in Unraid show the temp of my nvme drives, and the fan control plugin shows those drives in the exclude list (which I obviously hasn't excluded). I wonder if someone could confirm if including the cache drive in the temp monitoring is just not supported or if I've got something I need to fix. No idea what info specifically is useful in any investigation but I've attached diagnostics for now anyway. Love the Dynamix plugins and use a few, so cheers for all the good work and TIA to anyone who can help me understand my dilemma! artemis-diagnostics-20240122-1815.zip
-
Hi Team, Recently I've spotted "out of memory" issues a few times in my Plex container (binhex-plexpass). It appears to be related to a plex media scan, but I don't know enough to interpret much past that. Overall I have never seen the server itself short of memory, but I'm not sure if that's just because I wasn't watching it at the time - I'm not sure if there is anywhere to look to to validate. Jan 21 06:40:11 Artemis kernel: Out of memory: Killed process 5456 (Plex Media Scan) total-vm:23361576kB, anon-rss:23032432kB, file-rss:0kB, shmem-rss:0kB, UID:99 pgtables:45256kB oom_score_adj:0 Now the Fix Common Problems has highlighted OOM also, and I'm still unclear from some googling if this is the entire server or a less than specific flag brought on by Plex. I wonder if anyone is able to better interpret the logs (diagnostics attached) or has any other pointers. I've also been having some random transcoding issues which while I don't expect to solve at the same time, I wonder if they may have been memory related. I do have a fairly large library so it's conceivable that that is resulting in some resource issues but I'm not sure if it's something I can address at the container layer or if the server just needs more ram overall. TIA. artemis-diagnostics-20240121-0335.zip
-
Another round of updates incase anyone has been following along! Little has changed in my server up until today really. While everything is running well, I've change and am changing a few things, mainly around storage. Drives and HBA I've purchased 2 x WD Red Pro 22TB drives to expand my array with. The first of these, logically, is going in to replace the existing 10TB parity drive (in fact it's rebuilding parity as I type). I'll swap another of the 10TB drives out for the other 22TB, giving me a net increase of (sadly) only 12TB. But... as I mentioned above, I've also got an LSI 9300-8i HBA card and splitter cables on the way, with the intention being the removed drives will be re-added hanging off that card (the MB can't accept any more drives directly) reclaiming the other 20TB. Overall this will take me from 50TB to 82TB all going well! I also have to find 2 drive trays for my Fractal case before I can mount the extra 2 drives and as yet I haven't found a supplier but I haven't had much time to search yet so fingers crossed. (Never mind, after an exhaustive 3 minute search I found and ordered some 😆) I am slightly concerned about drive temperatures with the extra 2 drives added in as this will fill the entire column of drives down the front of the case (at present there's a couple of spare slots which I arranged to be part way through the stack hoping it would help with airflow). My drives hover around 41C when they are all spinning, but the weather is still cool and I'm never really sure which version of "safe hdd temp" anyone recommends is accurate. With summer coming, I'm not sure I have any real options if the temperature starts climbing short of shutting it all down which is obviously not ideal. I'm open to suggestions if anyone has any! NVMe Earlier in the year I had a scare with the failure of one of my NVMe drives (Cache pool). Thankfully the mirrored pool held up and no data was lost, but it still caused outage of all my docker containers. Thankfully with some luck, guess work, and forum support (here) I got things working again. It took me a while to understand that the drive failure was the cause, but I RMA'd the faulty drive once things were stable again. Instead of getting a replacement like-for-like and with my faith in the particular ones I was using rather knocked, I opted to order 2 brand new drives of a different brand, and upgrade my cache from 1TB to 2TB at the same time. This time I opted for 2x Samsung 980 Pro PCIe 4.0 NVMe M.2 SSD's. After no small amount of finger crossing, that swapout went okay and that's been happy since. Midnight Commander (Fan Controller) The other change I can think of is that, while I wasn't really unhappy with it, I removed the Midnight Commander and moved all the fans back to the controller (probably not technically a controller but it'll do) built in to the case and the dynamix fan plugin. The Midnight Commander had done fine, but it hadn't really done better enough to stand out, and I did like having the fan speed etc. available in Unraid itself. Also a friend was building a new machine and I decided to pull it out and let them try it before they decided if they wanted to buy one. I can't say I've noticed much difference, but even when the fans go to 100% the overall build choices mean that it's not an overly noisy machine anyway so even if it's doing that a bit more than it might have otherwise, it doesn't really matter. Of particular note, as I mentioned concern about the hdd temp earlier, the drive temps showed no discernible difference with either setup so it's not like putting it back in is a likely solution. Summary I haven't changed much as I haven't really needed to! But also, life gets in the way of tinkering. The server is still going strong with the only real issue I have being that I can fill up about 2TB more than I have at any point in time (a problem no doubt many of us have) so after some time being a little frugal about what content I get, it's time for an upgrade. While the step up to larger drives has a high overhead to get the parity drive large enough, now working through other drives will allow me to better add more space over time. I think that's about it. More updates once the HBA card has had (hopeful) success and some time to bed in.
-
Well if you're late, I'm later to have noticed your message so my apologies. I have just started a round of upgrades to the server and purchased an LSI 9300-8i HBA card based on a mix of what was available, and what was mentioned as having had good results / confirmed working. It hasn't arrived yet so I can't comment on my experience, but fingers crossed. I'll try to come back and update once I've got everything in place and given it a go.
-
Thanks @JorgeB, I had actually tried the latency flag but not the pcie one. I've added them now with the single nvme still. I think I'll look to just replace both cache drives anyway, just to be safe. The failed one should be under warranty if I can find the paperwork! And thanks for the spot on disk4! Beside the logs, is there anywhere I should be watching where I might see that sort of warning?
-
Okay, I've got myself out of immediate failure I think (fingers crossed). I could not stop the array (/mnt/cache would not unmount despite nothing showing using it in lsof) so I disabled auto start and rebooted the server. I then managed to remove the faulty nvme drive from the cache pool, and then (using the small checkbox confirming I really wanted to do it) started the array again. I'm now getting a number of 'reallocating block group' log messages in syslog and the cache files are accessable (I "think" this is btrfs doing a balance itself...). I was also able to start docker again. I'm now going to leave the cache to reallocate whatever else it may want while I go check the dates and warranties on the failed nvme (assuming it's the drive and not an issue with the motherboard slot). I'd still be interested if anyone can help explain if I did the right thing or just took a risky option that fluked ending well. A few forum posts I had read that I took largely some guesswork from (and I say guess as I still have no real understanding of balance or scrub, and only basic guesswork on the actual error I was having...)
-
Hi Team, I'm sorry if this is answered elsewhere but I've read a lot of different things that seem like they are in the right territory and I'm not sure I understand enough still to know the best approach. This morning I had trouble playing something off my plex server. I tried restarting the docker container, and that failed. I soon realised my other docker containers were some sort of broken. This led me to logs, found a lot of BTRFS errors, and the subsequent googling. Best I can tell, one of my 2 nvme drives from my cache is "unhappy" and had unmounted/disconnected/died... I have remounted the pool in ro mode to try and copy data off, which has thrown a lot of IO errors and I'm unsure how successful it could be called. I disabled docker as part of trying to reduce any surplus disk access to the cache while backing up. After rebooting the server, nvme1 shows again and I see some `read error corrected` and other messages about errors on the cache: ... May 7 11:36:28 Artemis kernel: loop3: detected capacity change from 0 to 209715200 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 65536 csum 0xcc09b20c expected csum 0x90ce6228 mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 2, gen 0 May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 390506 off 65536 (dev /dev/nvme1n1p1 sector 1472333904) May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1147752185856 wanted 13961728 found 13961392 May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 0 off 1147752185856 (dev /dev/nvme1n1p1 sector 1945964096) May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 0 off 1147752189952 (dev /dev/nvme1n1p1 sector 1945964104) May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 0 off 1147752194048 (dev /dev/nvme1n1p1 sector 1945964112) May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 0 off 1147752198144 (dev /dev/nvme1n1p1 sector 1945964120) May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1148293398528 wanted 13961753 found 13961464 May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 0 off 1148293398528 (dev /dev/nvme1n1p1 sector 879570784) May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 0 off 1148293402624 (dev /dev/nvme1n1p1 sector 879570792) May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 0 off 1148293406720 (dev /dev/nvme1n1p1 sector 879570800) May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 0 off 1148293410816 (dev /dev/nvme1n1p1 sector 879570808) May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1148299493376 wanted 13961753 found 13961464 May 7 11:36:28 Artemis kernel: BTRFS info (device nvme0n1p1): read error corrected: ino 0 off 1148299493376 (dev /dev/nvme1n1p1 sector 879582688) May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1147449704448 wanted 13961716 found 13961423 May 7 11:36:28 Artemis kernel: BTRFS: device fsid bbb9c5ed-2bf5-4e6b-8af1-280c4be09739 devid 1 transid 1847029 /dev/loop3 scanned by mount (10535) May 7 11:36:28 Artemis kernel: BTRFS info (device loop3): using free space tree May 7 11:36:28 Artemis kernel: BTRFS info (device loop3): has skinny extents May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1148351053824 wanted 13961755 found 13961466 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 26857144320 csum 0x1754e162 expected csum 0x08eeb7e3 mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 3, gen 0 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 26857148416 csum 0xcdb54873 expected csum 0x8941f998 mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 4, gen 0 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 26857152512 csum 0x30afaf5e expected csum 0x8941f998 mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 5, gen 0 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 26857156608 csum 0xfd2a2fd6 expected csum 0x8941f998 mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 6, gen 0 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 26857160704 csum 0xecf6f5fe expected csum 0x10a79df3 mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 7, gen 0 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 26857226240 csum 0x47125d6d expected csum 0x7675cf82 mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 8, gen 0 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 26857164800 csum 0xbbe64e09 expected csum 0x8941f998 mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 9, gen 0 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 26857168896 csum 0x5a4ecf38 expected csum 0x8941f998 mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 10, gen 0 May 7 11:36:28 Artemis kernel: BTRFS warning (device nvme0n1p1): csum failed root 5 ino 390506 off 26857172992 csum 0x8941f998 expected csum 0xd5b8699a mirror 1 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): bdev /dev/nvme1n1p1 errs: wr 97755, rd 13117, flush 2864, corrupt 11, gen 0 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1148353626112 wanted 13961755 found 13961466 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1148353478656 wanted 13961755 found 13961466 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1148353183744 wanted 13961755 found 13961466 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1148353200128 wanted 13961755 found 13961466 May 7 11:36:28 Artemis kernel: BTRFS error (device nvme0n1p1): parent transid verify failed on 1148352905216 wanted 13961755 found 13961466 May 7 11:36:28 Artemis kernel: BTRFS info (device loop3): enabling ssd optimizations ... I attach diagnostics output from both before and after reboot. Once the server was rebooted and nvme1 was showing again I tried to start docker again. Docker start failed. And at this point I'm rather lost. My cache was setup in mirrored mode so I went looking for options to just remove the failed drive from the pool but reading stuff about balancing etc. and a number of people who have managed to break things left me confused. I "think" I should be able to remove the broken drive from the pool but thought I'd seek the wisdom of the forum before I lunch anything more than may already be lost. Suggestions or even pointers to doco I should be following for my situation appreciated. artemis-diagnostics-20230507-1157.zip artemis-diagnostics-20230507-1005.zip
-
Yes as @ChatNoir mentioned there is some devil in the detail. I do currently have 2xM.2 + 6xSATA operating perfectly happily.
-
Hey @Nick_J Well, I think it went pretty well. I did a writeup (linked) that you can have a look at for general detail but I'll try to address a couple of your specific concerns. I was worried about the CPU being so new and that it and the associated newer motherboards it required may not be supported, but I've had exactly zero issues with it. I've also happily gotten the iGPU (one of the key drivers for the CPU choice) working well for hardware transcoding with Plex. While it may not be the best CPU for the money, I'm certainly glad I didn't choose something lower spec also, as between my main unRaid stuff, and the Windows VM I'm running (with GPU passthrough of a PCI card) it does occasionally get busy enough that I wouldn't want the contention. That said, I had wondered about power, and after recently getting Home Assistant running and logging some power usage stats, the system is probably averaging around 150W (excluding the internal lighting strips that are independently powered). Following on to the motherboard choice. I did debate a number of different options. This one however has worked perfectly, except for one little niggle... And to be fair it's probably simple but I haven't put any real debug time into it. Some times upon reboot it'll hang, with me having to go into BIOS, exit (editing nothing) and rebooting to get it to boot the OS again. Given I don't plan to reboot often it hasn't been a major, but one day I'll have to solve it or figure out the pattern to its occurrence better as if the power goes out, I'd like the server to start up again when it's back rather than requiring me to manually intervene. The NIC's have gone fine. I only use them at 1Gig, and even then I only actually have one going with the other only tested when I was checking it worked. I should possibly pass it through the the VM but in my office I have a 1G link back to the router so it can't offer me much in the way of bandwidth, and the shared network has been fine for everything I've been doing (except maybe one docker VM that would have had some benefit being on a different MAC to unRaid, but it wasn't enough to make me put effort into it lol). I've also liked that I can run 6 SATA drives as well as 2 M.2 drives where as most boards I found took a SATA port or 2 out of action. If I needed more M.2 it would impact, but 2 run fine so they do my cache marvelously. In hindsight, I might have redesigned some of my system around even more ports, but I'm probably at the more practical place where I'll likely need an expansion card soon to load more drives in... let's just say the content grew faster than anticipated, mainly just because it's so darn easy once the right apps are setup! If you look to do a VM at all, USB can be a slight pain to the point I'm considering a PCI USB card to be able to dedicate a BUS to the VM. But I'm managing for now and if it wasn't for the VM it wouldn't be an issue at all. Happy to answer more specific questions if you have any but hope this helps! Cheers, Dan
-
Thanks for the suggestion. Sadly that doesn't proxy well in a way that is transparent to the user as to make the login URL as the default proxied endpoint runs into the issue that Heimdall then redirects to the actual root of the site. While it's doable, it wasn't easy to make happen reliably. I ended up biting the bullet and removing the existing config and reloading it all which now has it working well and was less effort than trying the login url proxy approach anyway.
-
Hi Team, I've been playing with Heimdall for a little while and had setup a user through the UI (password working etc.) but have no changed to using Authelia and for the life of me I'm unsure how to disable password requirement in Heimdall. I have no .htpasswd so I wonder if it's stored in the sqlite db? Basically I want just a single populated page with no login requirement in Heimdall and I'm protecting it with Authelia. Any pointers appreciated! I'd rather not blow everything away and start fresh as I have put a number of links and details in that I don't particularly want to redo, but if I have to...
-
Great to hear! Good luck with whatever you're trying to achieve. To help everyone out can I ask that you update the thread title to show it is (SOLVED).
-
That image has amd and arm variants (and 386) as a shared tag (read the Description page of the docker image you're looking at and it'll give you a link to explain what a shared tag is). As the system isn't detecting/selecting the correct architecture automagically, you need to specify a "simple tag". So, read lower on that same page and it will give you links. Which brings me back to... Try: FROM amd64/python:3
-
Try FROM amd64/python:3
-
In case anyone else finds this with the same question, I successfully crated a "new" VM in Unraid with the same settings as old and got it running. I'm sure this is detailed somewhere but I couldn't find it with whatever I was looking for, so I wanted to leave how I solved it for reference. Basic steps: 1. Renamed the old one from "Windows 10" to "Windows 10 Old" 2. Create new VM with same settings as old and named "Windows 10". This naming made Unraid naturally point to the same disks as before but you could manually change this in step 4 if needed 3. Set VM to not start when you save the settings. And save the settings. 4. Go back into the VM settings and double check the drive assignments match the file locations (and possibly sizes if you are manually pointing them to something other than the defaults) 5. Start the VM and enjoy.
-
Hey thanks @ChatNoir. My apologies, I through I had deleted this thread as looking through the diagnostics I found this directory a short time later (I'd never dug into diagnostics and when I didn't see anything obvious in the drives.conf I expected it was beyond my understanding) and managed to resolve the issue. My problem was that a connector was loose on one of the existing drives when I restarted so it was showing a drive missing which threw my confidence in everything. Once I found this directory I realised why it was showing a drive missing (basically I better interpreted what the interface was showing me with the corroborating information), shut down, re-seated the cables and rebooted and got it running correctly. Appreciate you taking the time to assist!
-
Updated photos for the record. New lighting, new drives, new fan controller. Redid the cabling etc.






-
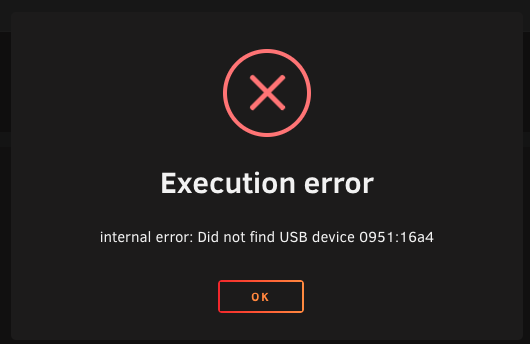
Hi Team, Earlier today I added a couple of new drives to my machine. I took the opportunity to tidy up some cabling also, and now I get an error when I got to boot my VM. Entirely sure something has just changed address but I am not sure how best to diagnose it. Hoping someone can suggest something. Is it is simple as deleting the VM and recreating it with the existing disks? Error and diagnostics attached for reference. Any suggestions appreciated. artemis-diagnostics-20210829-1808.zip
-
So I did a dumb. I shut down to add 2 new disks I'd just pre-cleared and mid recabling realised I hadn't taken a photo of the exiting drive assignments! I do have a diagnostics file from this morning before I took it to bits; can I recover the details from this to ensure I'm not messing up my parity drive (If I remember correctly, the order of the other drives is not important?) Any help would be urgently appreciated! artemis-diagnostics-20210829-0929.zip
-
I'd add a +1 for that. I considered water cooling because it looks nice, takes up less space than a big cooler, and theoretically is reported quite efficient. Upon further research I found a number of comparison/tests by Linus Tech Tips on youtube that regularly showed a good air cooler more effective at cooling than water coolers (and some smaller water coolers better than larger). While your milage may vary, it helped me stick with my air-cooled Noctua solution. The other reason I was pushing towards air-cooled is pretty simple. If one of more of my fans fail, I still have a big heatsink to help dissipate heat. In a water cooled environment, if my water cooling fails, well it fails good! There is no failure mode in water cooling I could think of that wasn't likely to result in some fairly catastrophic failure leaving my CPU with zero cooling support. I've never run water cooling personally but after asking and reading around, I never would unless a) I had to due to space constraints for a suitable air-cooler, and b) it was only going to be on while I was there so I could power down instantly in case of issues. My server is designed to run 24/7 however, so and air-cool is running excellently for me even under higher loads (and also quieter than the fans on a radiator would be which was another driver).
-
If I understand correctly you have a bunch of files that are downloaded inside a docker container to a location that is not mapped back to your underlying drives? There's a few ways to do it (I'm not familiar with Syncthing to know if it can do it inherently), but the most reliable I could point you to would be docker cp command if you are able to use the command line. Just make sure that you are using a destination on your Unraid server that is suitable to put the files. You can use `docker ps` to confirm the name of the docker container you are targeting. Then use the docker cp command something like (change the specifics to suit your situation): docker cp <container_name>:/home/unknown/deviceblabla /mnt/user/folder/you/want/files/in/ Let me know how you get on!
-
48GB. Runs a bunch of dockers, and 1 windows VM very happily.
-
Hey @Fuggin. Giving zero consideration as to why you're not seeing it (as in I don't know enough about it to try debug that) but on mine I also have a Preclear section under the Tools menu, and it shows me log access etc. also so depending on how your Preclear is installed you may have something under there. I happen to be doing a couple of disks myself so screenshots attached to help.

-
A few updates I thought I'd catch up on while I have a rainy weekend in lockdown and my new drives are pre-clearing. Who would have thought, 30TB of storage would not be enough... When I consolidated the data I had I had already cracked 20TB, and the other 10TB filled up awfully fast just by getting some updated content made FAR too easy with Overseer, Radarr/Sonarr, etc. Also I decided to play a little with lightning, and upped the RAM. So I've added: 2x 10TB WD Red Pro Drives (to make a total of 6 drives = 50TB storage). Corsair Vengeance RGB Pro 32GB (2 x 16GB) DDR4-3200 CL16 (for a total of 48GB) Corsair Midnight Commander Pro to run my fans Corsair iCUE LS100 Smart Lighting Strip Starter Kit for some in-case lighting I still plan to add: 3-4x Corsair iCUE SP140 RGB ELITE Performance 140mm - These will replace the 2 front of case stock fans, add an additional front of case fan (I want 3 to help cool my HDD's which are all front of case). Debating one as the exhaust fan also but considering static pressure, airflow volume, and impact on my CPU cooling fans also. Research in progress, feel free to give any thoughts you have. Also considering changing the case top to the vented version and adding some exhaust fans at the top. These fans also supposedly have a slightly lower noise level than the stock ones (the stock ones are pretty quiet and perfectly fine, it's mainly a drive to add some LED fans) 2x Fractal Design Drive trays - I have the 2 new drives mounted in the lower cage, but I'd like to bring them up so they are better in the airflow of the fans. Not a biggie, just a matter of stock/supply timeframes these days. My experience of the Midnight Commander Pro so far I thought I'd immortalise some thought/experience here. I've been running it for only about a week and a half now but it's been interesting. Prior to the Pro, I had my fans running off the in-case Nexus+ 2 fan controller. Combine this with the Dynamix Auto Fan Control plugin and I'd managed to get things running marvellously including fan speed display, all nice, quiet and functional. For the record, if that's what you plan to run i think you'll be perfectly happy by the way, I'm certainly not trying to suggest it's not a good solution. I chose to get the Pro hoping to get better control of the fans individually to manage airflow better; the Nexus+ 2 just "does it's thing" based upon effectively a single fan input from the motherboard (in my case the CPU fan header) so if one fan is going up, they all are. That worked fine but I'm a control freak some times so thought the Pro along with its 4 temperature probes would be good to try out. I manage the Pro through my Windows VM as it runs through Corsair's iCue software. That works fine too, however iCue seems to not see the actual CPU temp. It see's my GPU temp, and the Pro's temp probes fine however. No problem, I have one of my temp probes buried into the fins of my CPU cooler so I get to know if the temp is going up or down at least, even if not the actual CPU temp. Overall I can control the fans, set their performance profile/curve, and apply different profiles per fan, but even on quiet I feel it's all running a little louder than when I had it running from my Nexus, and monitoring the temps that Unraid see's I'm not sure it is actually keeping things cooler than the Nexus was. This is all totally subjective, I did not make detailed measurements before to compare temp (although I could possibly get it out of Grafana stats if I cared enough), and the noise... well as I say it's just subjective. In theory the Pro could shut down a fan if the temp was cool enough but I haven't seen that happen even when everything is sitting down in the low 20degrees celsius so I'm not sure what temp would be required for that. What I'm running these days I have Overseer feeding Radarr and Sonarr, which in turn feed qBittorrent and sabnzbd (which uses jackett). All these feed my Plex content. So I can automatically request something on Overseer and it magically pops up in my Plex some time later. This took a little planning to get all the drive mappings etc. setup right, but now it works pretty damn well and is pretty much how I made my last 10TB magically disappear! I've also got nextcloud+mariadb+redis going. It "works" but it's no dropbox at the end of the day. My intention was to replace my dropbox, I'm debating if I keep going with nextcloud, try something else, or just keep paying dropbox because nextcloud just isn't as smooth and reliable as dropbox by a long shot. On the monitoring side I have telegraf+influxdb+grafana. These work pretty well, I'm yet to spend the time to get Ultimate Unraid Dashboard up and running to expand what grafana is monitoring. I've also got Zabbix on my "to-do list", I used to have it on one of the servers I shutdown and I'd like to get my backed-up config running with the docker version on Unraid. Other than that: Trillium which I played with but have not really gotten into to replace several other notes apps I use Swag and Heimdall, working on trying to expose certain services off my network and make it easier for me to access all the things from ideally a nice shiny browser homescreen. I'd say this is still WIP in heimdall works pretty nicely overall especially compared to a number of similar things I've tried. Ideally, I'd have a portal page that utilised plex accounts for login and added an authorisation layer, but dreams are free, and I'm not yet motivated to go write one. Specifically I'd like to let key friends access overseer to make requests. Wireguard provides nice reliable access for my laptop and another remote computer back to my server. I've considered this as an option for friends, but I still want more control than a "server or not server" and expecting them to run specific software is not the best user experience especially as many of them are not as geeky as I am. Pi Hole is now running my network DNS. I'm not doing much filtering with it, my router does parental control filtering on the kids devices, but it is interesting to see the stats. The one thing I haven't messed to far with is the default upstreams for it are Cloudflare and something else (I can't remember) but I like them to be my ISP DNS as there is a measurable performance increase by querying the closer servers. I can update it at runtime but if it restarts it resets, so I need to go look at the appdata config - I just haven't looked that far yet. Binhex's Preclear is of course a stock standard these days. I only run the docker container when I need to use preclear however so most to the time it's taking up a little space but zero resources. Honourable mentions to Gaps, dupeGuru, Code-Server, P3R-OpenRGB that I still have installed but either run rarely, or have given up on. Happy to share experiences with them if anyone is curious. Wow, that was more than I expected, and probably bloody hard to read so if you got here, well done and thanks for taking an interest. The only other things I wanted to mention was that the old GPU I'm still using has actually been working really well for my GPU passthrough Windows VM and is running StarCraft II perfectly well. I'd still like to update some day, but it's working well enough to make me go on a saving spree. Also, I have some annoying boot anomalies when I reboot sometimes having to go into bios and exit (without changing a thing) for it to boot through to Unraid sometimes; I don't think it's every time but I don't reboot enough for me to have spent more time debugging - may be related to if I had something plugged into the on-board graphics for it to boot, and I'll get a dummy HDMI load at some point to try anyway, but one day I'll likely have to work out more exactly what's going on so it's reboot-safe. Hope everyone is keeping well in the carnage that is life at present!










