

FreeMan
-
Posts
1520 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by FreeMan
-
-
On 2/3/2022 at 12:44 PM, ashman70 said:
If I wanted to reduce the number of drives in my array by one disk, say a 3TB drive.
Would I do the following:
- Use the unbalance plug in to scatter the contents of the drive to all other drives.
- Confirm there is no data on the drive when completed
- Stop the array
- Remove the disk from the configuration
- Go to tools/new config and do a new config preserving drive assignments
- Save and rebuild parity based on the new config?
This does seem to be the proper steps. I'd suggest searching the main support forum as I know this has been asked dozens of times at least.
On 2/3/2022 at 12:44 PM, ashman70 said:After running the Unbalance plugin I am getting a report that says 11 files or folders don't have the correct permissions and to run the Safe dock permissions, which I ran and then I reran the Unbalance plugin dry run and I am still getting the error.
You may want to raise a separate question about that one. Also, make sure nothing else is writing to disk as that may effect DSP's ability to change permissions.
-
On 2/5/2022 at 10:07 PM, rallos_hoo said:
I am confused, what's wrong with my Unbalance????
Cause my cache device is nvme SSD

Mine are standard SATA SSDs - maybe that's the difference. AIUI, there are some issues with NVME devices here and there, but I don't know all the details. Maybe do some searches throughout the forum to see what you can turn up. Make sure you know which version of UNRAID they refer to because I know support has been improving.
-
1 hour ago, kim_sv said:
No, I don't think it does see any more than the "original" cache. Can you show a screenshot?
My pool drives:
Unbalance, in SCATTER mode, showing the option to move data to both pools:

Unbalance in GATHER mode showing the option to move data to either pool:

The most annoying part, to me, was that they are selected by default in SCATTER mode and I had to constantly remember to deselect them as I was moving data off of my failing drive. It would be great if there were some settings that would cause Unbalance to ignore drives when selecting the default set of destinations. More than once, I accidentally moved data to both pools, then had to go clean it up again.
Are you sure you're on the latest version? I don't have a clue when the plugin was last updated, but I've got CA doing automatic updates, so reasonably certain that I'm on whatever the latest may be.
-
On 1/29/2022 at 9:47 PM, rallos_hoo said:
hello,
Due to unraid 6.9 now support multiple cache pools, may this plugin add the feature moving files between cache pools?
From what I've seen it certainly does. When I selected files on a disk I was clearing, it defaulted to selecting all other disks as destinations. I had to specifically remove my two pools in order to get it to not put data there.
I'm reasonably certain that if you select data that's on one of your pools, you could select the other pool as the destination.
-
21 minutes ago, Squid said:
It is a new check (although one which should have been introduced at the start of 6.9)
Well, that does explain why it's never triggered before...
-
Unfortunately, I looked at some of the duplicated directories and there are some files, at least, that do exist on both pools.
Thanks for the tip about stopping the docker service first, I would have probably forgotten to do that and caused myself all kinds of grief.
-
When Fix Common Problems ran last night, it flagged this error:
QuoteShare appdata set to use pool apps, but files / folders exist on the cache pool
No changes have been made to my server, though I have been migrating data off of a drive that seems to be slowly dying.
There are absolutely appdata files on my cache drive, and by all appearances, they've been there since last October
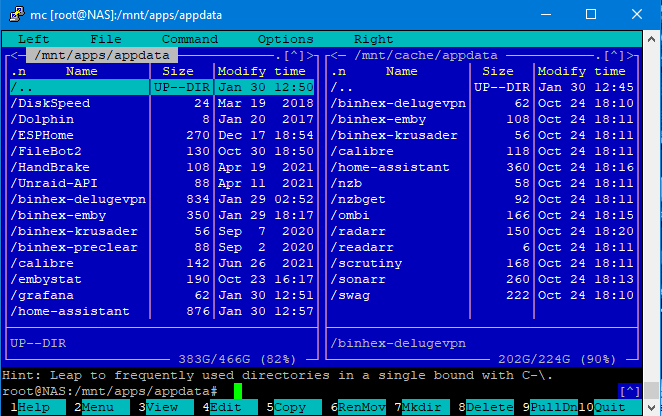
Also, you can see that some directories are duplicated across the two different locations.
1. If these directories on cache were created in October, why are they just now getting flagged as an error? Is this a new check?
2. Is there any option beyond going through each directory and file, comparing to see which version is the newest and manually merging them back into /mnt/apps from /mnt/cache?
-
After using Scatter to move data off of a failing drive, I'm looking to use Gather to pull things back together a bit. It seems that there's an issue in how it decides which disks it can move data to.
I've got a TV show with data on disk3 & disk7. On disk3, there is 2.43GB of files. On disk7, there are two images totaling less than 400KB.
When selecting a Target, I'm shown disk7 first, with 2.43GB to move everything there. I'm not shown disk3 as a destination option at all. My disk3 currently has 537MB of space, so I can see where 2.43GB > 537MB and it doesn't offer that as a location, but the vast majority of data already resides on disk3, and really, only about 400KB of data needs to be moved there.
I see that at a simple level, not presenting disk3 as a destination makes sense, but there is plenty of space for the data that isn't already on disk3.
Is this a known issue?
-
On 11/10/2021 at 3:36 AM, bonienl said:
Unraid version 6.10 has WireGuard support natively built-in, the plugin is no longer required.
For confirmation, does this mean we should uninstall the plugin if we're running 6.10?
If so, does Fix Common Problems flag that?
I'm currently on 6.9.2, so I'm oblivious to any changes that may be coming. Sorry, don't keep up with the coming change log as maybe I should.
-
If one was a hard link to the other, deleting one would not delete the other.
-
My appdata share was set to Cache: Prefer (allowing overflow to hit the array should that ever become necessary - it wasn't at only about 60-70% full). I set it to Cache: Yes then ran the mover, which should have caused the mover to migrate everything to the array.
I've finished manually copying all the files that were left on /mnt/cache/appdata/* to /mnt/disk2/appdata/* (disk2 is where the mover decided to put everything).
Subsequently, I've shut down the server, replaced the failing SSD and now after powering up and setting the share back to Prefer, am in the process of running the mover to get everything back onto my SSDs.
Once the move is complete (and I'm 100% certain to check for any remaining appdata root-level directories on the array and clean them up if necessary), I'll restart the docker service & fire up all my dockers.
I've been using CA backup for my cache backup for a number of years now, even though the cache is on a 3-disk array. (I know 3 is a not ideal number, but it's what I've got, so I'm running with it).
-
Even worse, as I'm moving through the Krusader detritus left over, I'm finding that some files do not exist in the destination directory. I guess it's a good thing I'm double checking.
I've got 3 other docker config directories to work through before I can shut everything down.
-
2 hours ago, Frank1940 said:
I would assume that a modified file being rewritten to the array would force a write directly to the array which would overwrite the existing file.
That seems like a reasonable assumption. However... These are all files from docker configs. I stopped all dockers and disabled the docker service prior to starting the mover.
If you look at the first post, there are svg files that are icons in use by Krusader that didn't get moved. Unless there's an update to Krusader itself, I doubt these get updated often. Actually, the file date on the cache drive versions are all 7 Sep 2020.
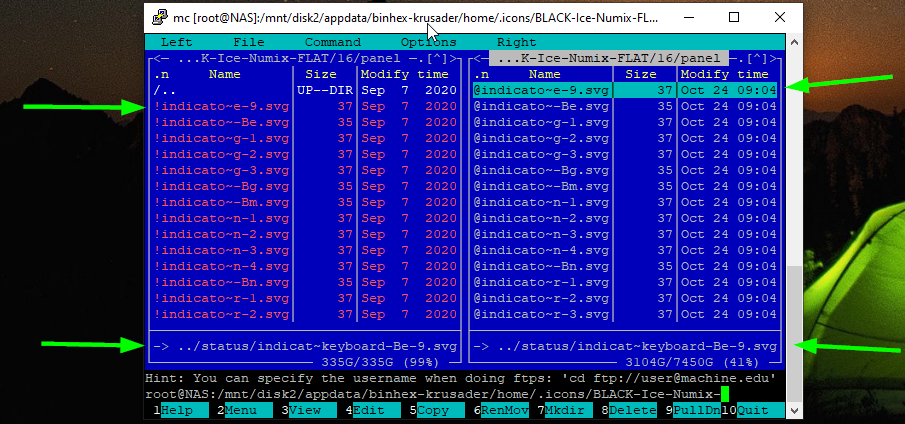
As you can see in this screen shot of MC, I've got essentially the same file selected in both panes (cache on the left, disk2 on the right). the names are the same as are the file sizes. The dates are different because the one on the right was just written. What I don't understand is that the cache version starts with "!" while the array version starts with "@", yet MC tells me that the file already exists
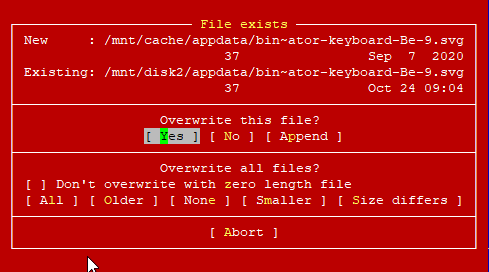
At this point, it seems my only option is to continue to confirm by hand that they've all been copied, which I will do. Then continue with my SSD replacement process and hope that I don't run into this issue when I move everything back to the cache.
-
Weird error message logged.One possibility that I know of is that Mover will refuse to 'move' a file to the array if the file already exists on the array.
I've used MC to try to move from cache to disk x where the mover put app data. So far, you are correct - all the files that remain also exist on the array.
Weird that it seemed to have moved them the first time it ran but didn't delete from cache.
I guess that I'll finish trying to move them and delete anything that already exists, just to be sure.
Sent from my moto g(7) using Tapatalk
-
Does that also explain the files that the mover failed to copy
Sent from my moto g(7) using Tapatalk -
120GB is A LOT of file system overhead!
Sent from my moto g(7) using Tapatalk-
 1
1
-
-
Additionally, can anyone explain this math:

how does 360 GB minus 224 MB leave only 238 GB free?
-
In an attempt to clear my cache pool so I can replace a failing drive, I've set the use cache setting for all the previously "cache only" shares to be "yes", and I've run the mover. When it finished, it left 224MB of data on the cache pool.
After turning on mover logging, my log is full of messages like this:
QuoteOct 23 18:09:50 NAS move: move: file /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/fileopen.svg
Oct 23 18:09:50 NAS move: move_object: /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/fileopen.svg No such file or directory
Oct 23 18:09:50 NAS root: Specified filename /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/folder_new.svg does not exist.
Oct 23 18:09:50 NAS move: move: file /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/folder_new.svg
Oct 23 18:09:50 NAS move: move_object: /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/folder_new.svg No such file or directory
Oct 23 18:09:50 NAS root: Specified filename /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/gtk-info.svg does not exist.
Oct 23 18:09:50 NAS move: move: file /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/gtk-info.svg
Oct 23 18:09:50 NAS move: move_object: /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/gtk-info.svg No such file or directory
Oct 23 18:09:50 NAS root: Specified filename /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/gtk-open.svg does not exist.
Oct 23 18:09:50 NAS move: move: file /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/gtk-open.svg
Oct 23 18:09:50 NAS move: move_object: /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/gtk-open.svg No such file or directory
Oct 23 18:09:50 NAS root: Specified filename /mnt/cache/appdata/binhex-preclear/home/.icons/BLACK-Ice-Numix-FLAT/24/actions/gtk-yes.svg does not exist.The only thing that appears to be left are a few docker's config data in the appdata directory on my cache. UNRAID somehow is seeing them, but then, when it attempts to move them, it can't find them.
Why would this be? Could it be that these files are in the failing areas of the SSD that I'm trying to replace and may be lost forever? If that's the issue, would reinstalling these 4 dockers after I've replaced the cache drive and moved everything else back likely resolve the issue?
nas-diagnostics-20211023-1829.zip
-
2 minutes ago, itimpi said:
In step 2 you need to actual stop the docker and VM services as otherwise they will keep file open that mover is then unable to move.
Ah, gotcha, the service itself, not just the dockers.
Thank you!
And this is why I double check... Happily, UNRAID and my hardware are stable enough that I don't often deal with these things...
-
@JorgeB now that I've got my replacement SSD, just to confirm:
1. Set all shares using this cache pool to "yes" (from "Prefer" or "Only")
2. Stop all dockers (appdata is the main thing on the cache and I don't want dockers trying to write there while the rest of this happens)
3. Run the mover to get everything off the cache
4. Physically swap out the drive
5. Rebuild the cache pool (since a drive will have been removed, it won't recognize it properly and will want to do that, right?)
6. Set all shares using the pool back to cache: "Prefer" or "Only", as they were originally
7. Run the mover to get everything back to the pool
7. Restart dockers.
-
Happy Halloween to me then. I guess I get to go shopping.That's not cable related, a SMART attribute is failing now, so yes, it should be replaced.
Now I need to figure out when I bought that drive and see if there's any warranty left on it.
Thanks
Sent from my moto g(7) using Tapatalk
-
I have 4 of these messages being reported on my UNRAID Dashboard this morning:

I presume that this means the SSD is failing and needs to be replaced immediately, or is it possible that it's just a cable gone bad?
nas-diagnostics-20211022-0649.zip
-
Sorry if this has been addressed - I was lazy and didn't read all 18 pages...
Is anyone aware of this issue https://github.com/Koenkk/zigbee2mqtt/issues/8663 that is apparently a driver bug and requires a kernel update to fix?
It seems to cause various ZigBee related issues, though not specifically related to MQTT...
-
8 hours ago, sheldz8 said:
Reboot first and see if that fixes it
Well, that does seem to have done the trick.
7 hours ago, ChatNoir said:Your docker image is corrupted, probably because the pool got full.
You should delete the image and reinstall your dockers from previous apps.
This, fortunately, seems to have been unnecessary. I know it's not a big deal to delete the img and start over, but why mess if I don't have to...
6 hours ago, JorgeB said:There are multiple ATA errors for cache2, and it's logged as a device problem, so you should keep an eye on that:
Joy... I've got another disk throwing some CRC errors, too. Don't really want to have to replace 2 drives at the same time.
The spinning disk started throwing errors after I physically moved the server just a bit while it was running. It could be as simple as a able is a smidge loose. That's what I'm counting on, anyway.
") Unfortunately, my plan for an easy to access setup isn't as easy as I thought it would be, so it's a bit of a pain to get to the server now.
Unfortunately, my plan for an easy to access setup isn't as easy as I thought it would be, so it's a bit of a pain to get to the server now.  I do need to shut it down and double check all the cables. I just need to muster the oomph to do it.
I do need to shut it down and double check all the cables. I just need to muster the oomph to do it.









[Support] binhex - Preclear
in Docker Containers
Posted
Duuude... This disk is awesome!!!!
🤣