

FreeMan
-
Posts
1520 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by FreeMan
-
-
I ran out of cache disk space - my fault! I'm clearing unnecessary files and fixing configs so it doesn't happen again.
However, various dockers won't respond, and attempting to restart them gives an Error 403. I'm now at 63% cache space utilization, so there shouldn't be any issues there.
nas-diagnostics-20210917-0712.zip
Is this simply a case of reboot the server or are there other trouble shooting tips I should try first?
-
Well, my problem is fixed!
We just had the AC replaced and while they were doing it, I had them install a new vent in my office right in front of my server. With a steady dose of cooled air blowing up its skirt, the server temps stayed sane and I had 2 drives occasionally hit 40°C, but nothing higher during a parity check.
Of course, I'll have to get a cover for heating season because I don't want to cook the server, but it'll run nice and frosty now during the summer.
-
 1
1
-
-
13 minutes ago, itimpi said:
Did you try copying the files or moving them?
I moved them as I've been doing for ages. I've gone back and forth between using cache and not, but don't recall having run into this before.
Based on your question, I copied them from the array to the cache-based temp directory, deleted them from the array, copied them back from cache to the array and deleted them from Cache. Now there are no file on cache.
Thanks!
10 minutes ago, trurl said:#2 in this post I often refer to:
Thanks. I have been very much aware of the "don't cross the streams" admonition for years. Since I'm using Krusader and both directory windows work from "/media" I assumed (with all inherent danger, obviously) that it would work properly since it's always worked that way in the past.
I guess I know better now, and will be sure to "copy/delete" instead of "move" from here on out.
-
I received a warning from Fix Common Problems that I have files on my cache drive for a share that's set to not use cache.
Here's the config for the "Sport" share:
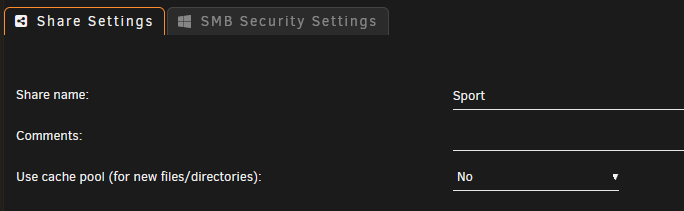
Browsing the cache pool shows that recent files are there for the Sport share:
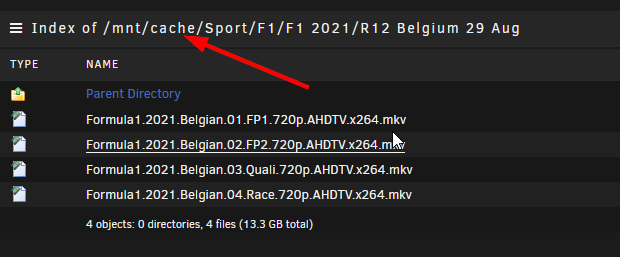
I copied the files from a temp directory (on Cache) to the Sport share using Krusader. Here's the path as reported by Krusader:
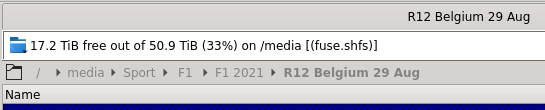
And here is the mapping for /media from the Krusader config:
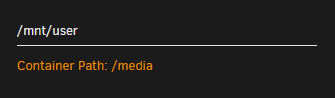
Why is Krusader writing these files to the cache pool instead of waking up the drive (if necessary) and writing them directly to the array?
nas-diagnostics-20210830-1450.zip
-
Just for fun, today, the Cache Utilized Percentage is almost right, but the actual amount used is off.
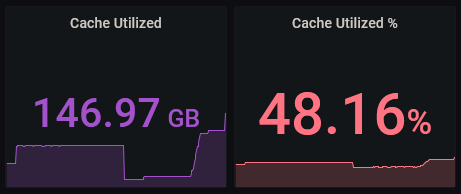

175GB out of 360 is 48.61%. 147GB out of 360 is 40.83%. So either the math is wrong or it's not finding all 360GB of available cache space.
-
On 7/3/2021 at 11:38 AM, falconexe said:
Check Your timeframe in the upper right. Set it to the last hour and see if it changes. When is your mover running?
Note: If you are using cache pools, then you’ll need to explicitly modify the query to account for all cache drives in the pool that makes up that instance of “Cache”.
Also, to remove the second image on your post, you need to delete the second (or all) of the attachments in the post of that image. If not, it will stick the dupe on the end… Once they are all deleted, save your post. They should now be gone. Edit it again, upload the single photo, stick it where you want it, then save.
This had, initially, fixed the display issue. However, it's back.
These were from yesterday:
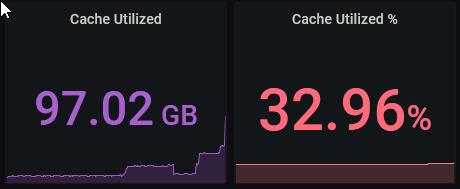
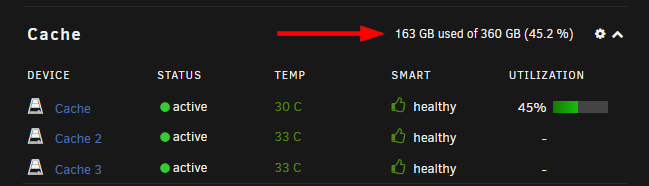
And this is from this morning:
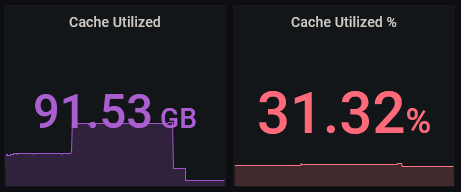

No amount of adjusting the time frame will cause the Grafana reported utilization to get back in sync with the WebGUI.
To address the other issues noted in your original response:
* The mover is running at 01:10. It is currently 06:56, it's long since completed its task, the first shots were from sometime after noon yesterday
* As noted previously, the query is pulling `"path" = '/mnt/cache'`. If you have a specific recommendation on how to modify it to pull in the 3 individual drives that make up the cache pool, I'll be happy to make that mod to see if it makes a difference.
I suppose this isn't critical, as UUD is a nice addition, and I'm relying on the WebGUI being accurate as the last word, however, it's mildly annoying. I'm willing to test out suggestions, but I'm not going to be heavily digging into finding a solution myself.
I'd like to say that this is a recent change (though I don't believe I've changed anything in either my UNRAID or Grafana setups that would have caused this), but it may well have been off from day one and I just never noticed. Out of curiosity, I just loaded UUD v1.5 and it is reporting the same incorrect number that v1.6 is, so this is probably nothing new.
-
On 6/7/2021 at 2:08 PM, shiftylilbastrd said:
So I just got the notification that my pull request was committed. Now if we can get the plugin updated to pull the latest version(2.1.3) this should be functional again.
If the plugin was ever updated (I'm guessing not since the newest version I see is 2.0.0 and my plugin is dated 2018.02.11), your changes don't seem to have worked for me. I have auto updates turned on, but don't recall having seen the change come through (doesn't mean it didn't, just that I don't recall). My speed tests have been reliably failing before & since your post.
 I appreciate your efforts and hope that it does get updated!
On 4/20/2021 at 11:21 PM, truckerCLOCK said:
I appreciate your efforts and hope that it does get updated!
On 4/20/2021 at 11:21 PM, truckerCLOCK said:If you go to setting and go to v0.3.4. It works fine for me.
The V0.3.4 change appears to be working for me as well. A manual test functions, now to wait for my regularly scheduled test to ensure all is good. Thank you for this work-around!
-
Have you notified whoever asked you to post diagnostics that they are up here? Maybe describe the issues you're having in more detail and someone else may be able to take a look.
Most modern CPUs will throttle back if they get too hot, and will probably shut the computer down if temps continue to go up. You'd probably need to look at the docs for your mother board to determine if it has that feature and where in the BIOS settings it may be.
The Parity Check Tuning plugin can be set to pause a parity check or disk rebuild if disk temps get too hot, but it won't shut down the whole server.
-
5 hours ago, Lolight said:
Is this one?
https://www.backblaze.com/blog/hard-drive-temperature-does-it-matter/
Their conclusion is surprisingly nonsensical (read the comments under the report).
That is one. I wasn't aware of any, but figured they'd have a report somewhere. It is decidedly inconclusive. The first thing I noted was their extremely cool temps - the min temps any of my drives report in SMART history is about 30°C (86°F). Right now my "server room" is about 25°C (77F) and I've got drives spinning between 36-44°C. My SSDs are always reporting either 30 or 33C (1 @ 30, 2 @33). They never change (makes me a bit suspicious, but they're cool enough I'm not concerned).
In general, it seems that occasionally hitting 50°C isn't quite the "instant death" I was initially fearing, but it is best if they don't get that toasty.
-
2 hours ago, falconexe said:
Check Your timeframe in the upper right. Set it to the last hour and see if it changes. When is your mover running?
Note: If you are using cache pools, then you’ll need to explicitly modify the query to account for all cache drives in the pool that makes up that instance of “Cache”.
Also, to remove the second image on your post, you need to delete the second (or all) of the attachments in the post of that image. If not, it will stick the dupe on the end… Once they are all deleted, save your post. They should now be gone. Edit it again, upload the single photo, stick it where you want it, then save.
Interesting, I set the time frame to 1 hour and it sync'd the numbers. I set it back to 24 hr and it remained correct.
I'm not sure where in the query I would need to make modifications, since it's selecting on "path" = '/mnt/cache'. I do have all 3 drives in the pool specified in the Cache Drive(s) drop down at the top of the page.
And I don't care about the multiple images enough to be bothered, but thanks for the tip!
")
-
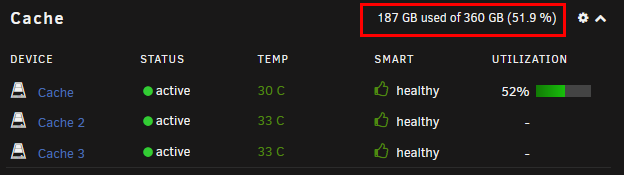
I've just noticed an interesting inconsistency.
As reported by the WebGUI:

As reported by UUD:
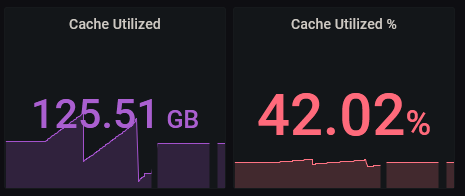
I know that the UUD is only refreshing every 30 seconds, but trust me, my system is NOT capable of writing 62GB to the cache drives in 30 seconds.
Forgive this second image. I've tried deleting it twice, but it persists...
-
After a brief DuckDuckGo search...
Here's an undated PDF from Icy Dock with scary warnings about how heat kills drives. Of course, they want to sell you their docks to keep your drives cool, so one should take it with a grain of salt.
Here's a 2020 page from ACKP claiming that "prolonged operation at temperatures under 20°C (68°F) or above 50°C (122°F)" will shorten a drive's lifespan. Of course, they want to sell you cooling solutions for your NOC, so there's a grain of salt with this one, too.
Both of those actually reference the same white paper from National Instruments, so there is at least some credibility (or, at least, consistency) to them. The NI paper states:
QuoteThe condition that has the biggest impact on the life of a hard drive is temperature. Heat decreases the life of the hard drive head. A 5 °C increase in temperature could reduce the life of a hard drive by up to two years. Heat also reduces the fly height of the hard drive head, which can cause the head to make contact with and damage the media. If your system will be operated in an environment with a minimum ambient temperature less than 5 °C and/or a maximum ambient temperature greater than 50 °C, you must select a hard drive with an extended operating temperature range. These hard drives include components designed for reliability in low and high temperature extremes. (Emphasis added)
Of course, NI wants to sell you their hardware for running tests on your equipment, and they want to sell you the "extended life" option if your conditions are outside those ranges, so again, a grain of salt.
Finally, I found a Tom's Hardware story from 2007 reporting on a Google Labs research paper (404, I couldn't find it at the Wayback Machine, maybe it's me). Tom's summary indicates that heat is a factor, but not the only or even biggest factor in drive death. According to their summary, Google didn't (yet) have any particular parameters that were credible in predicting drive death. It does, however, mention that drives operating in cooler temperatures did seem to die more frequently than drives operating hotter and that only at "very high" temps did the trend reverse.
Tom's quotes may very well be the source of a lot of the conventional wisdom at this board:
- Once a drive is past the infant mortality stage (about 6 months of high activity), death rate drops until about 5 years have passed
- Age alone isn't necessarily a factor, after 3 years, death rate stabilizes at about 8%
- Drives with SMART scan errors show a 10x likelihood of dying of those that don't have scan errors
- While 85% of drives with one reallocation error survive more than 8 months after the error, the overall death rate is 3-6x higher after the first allocation error than those without errors
- 56% of all their drive failures had no SMART warnings at all.
All in all, it sounds like drive temp isn't the worst thing. All the things I found (again, just a quick scan) said that up to 50°C operating temp is OK. Of course, cooler is going to be better, but you don't want the drive reaching for a sweatshirt, either.
I still haven't found anything from BackBlaze, and they seem to be the preferred go-to for drive life metrics. Wonder if they do have anything on causes of failure, or just statistics...
-
This is more on line with what I believed and understood, but I've certainly got no proof one way or the other.50's is too hot.
40's is tolerable.
30's is desirable.
The higher the HDD's operating temps, the lower its lifespan.
The case's airflow volume, static pressure and the air's temperature are crucial parts here.
But even with an optimum airflow it might not be possible to keep the densely packed drives in the 30's (under load) if your ambient temps don't stay well below of 25 degrees.
Thank you for your input.
I wonder if anybody has done /can find some research on what effect temp really has on drive lifespan. Sounds like something BackBlaze might have. I may see if they've got something.
Sent from my moto g(7) using Tapatalk
-
Interesting, and thanks for the feedback @Hoopster. I just don't think I'd ever seen a drive hit above about 40-41°C before, even during a parity check.
I've got 5-in-3 cages, and this is the first time in quite a while that I've actually had 4 drives in any one cage. I've seen some comments about the IronWolf running hot, so maybe with it running hot and 4 drives (even though it was next to a drive that wasn't part of the array and spun down), the whole mess was just hotter than I'm used to.
I'd still welcome other's input, feedback, comments.
-
How hot is too hot for hard drives?
I just finished rebuilding a drive in my array, and the brand new Seagate Iron Wolf was consistently hitting 46°C. I was using Parity Check Tuning to pause the rebuild, so that's about as hot as it got, but it spent 3 days bouncing between about 42-46°.
I understand that different drives may have different operating conditions spec'd by the manufacturer (Seagate says up to 65° for the IronWolf), but what's a "reasonable" and "sensible" number? At what point should I worry about shutting things down to prevent drive damage?
-
Thanks.
Since it's not part of the array now, I either need to Preclear or rebuild parity. Since both this disk and parity are SMR (I know, what was I thinking), it's probably 6 of one, half dozen of the other in terms of time to live.
Sigh...
Sent from my moto g(7) using Tapatalk -
I ended up replacing the drive with the new Iron Wolf. With all the associated heat issues, it only took about forever to rebuild data onto the new drive.
I now have the Barracuda with reported uncorrect errors still in the server and listed as an Unassigned Device.
- Would it be reasonable to try to run a preclear on it and see if it survives?
- If so, would more than 1 preclear cycle be suggested?
- If it survives one or more preclears, would you feel confident putting data on it? (running single parity, would ensure it's excluded from shares that might have critical data)
If it does come out in the end that it seems reasonably "safe" to reuse it, I'd move data from my two smaller 4TB drives onto it, doing overnight writes when I wouldn't notice the slowdowns, and get the older 4TB drives out of the system.
-
As a general point of reference for any future issues you may come across, it's always helpful to go to the "Tools" menu, then click on "Diagnostics" and download the zip file. The page there tells you exactly what is being collected, but in general, it includes all the configuration info that the experts here would need to help diagnose setup issues like this.
Glad you got this resolved so quickly and welcome to the Unraid family!
-
2
-
-
In UNRAID, go to the "Tools" menu, then select "New Config".
That should wipe out all previous disk assignments and allow you to reassign drives. It should also tell the OS that these are not UNRAID prepared disks, so it should do a clear on them.
Of course, you can also do a preclear on the disks to ensure they get wiped, but when you start the system after doing a "New Config", that should do the trick.
-
1
-
-
5 hours ago, itimpi said:
If it is thought it would be of use I could enhance the Parity Check Tuning plugin to add such entries.
I think it would be useful if disk rebuilds were logged in the Parity Check history. I think it would be even better if they could be kept in a separate category, but that's probably not possible, so a simple entry there would be fantastic.
Also, bug report filed, so I'm marking this one "resolved", since it seems nothing else can be done from this end.
-
1
-
-
Fair enoughWe can't, it's a separate database, there's a copy option but never used it before and not sure how it works.
Sent from my moto g(7) using Tapatalk
-
Unless this can be moved to the bug thread, I'll post an issue later today.Did a quick test without the plugin installed, if a rebuild is running at the time scheduled for a parity check it will attempt to start one but since the rebuild is already running nothing happens, on the other hand if the rebuild is paused, I did it manually but it would be the same if paused by the plugin, then it re-starts the current rebuild from the beginning, so it's an Unraid bug, it's a minor one and one that won't affect many users but it might still be worth reporting.
Thanks for duplicating it.
Sent from my moto g(7) using Tapatalk
-
it adds nothing to the discussion, but it's quite sad:

(Wow, sorry that's so BIG!)
Those are the Pushover notices from when it reset. I was wrong in my initial report - the Parity Check is scheduled for 00:30, not 03:30 on the first of the month.
There is a minor issue of the extra "%" sign in there, but I think this is the first time I've ever noticed, so it's definitely a minor issue.
-
Thanks,@itimpi.
Not trying to pick on you with these PCT reports lately, I promise! I've discovered that I'm pretty good at finding bugs in other's code, not so good at finding them in my own.
Frankly, if it weren't for PCT automatically pausing the rebuild, I may well have cooked a drive by now, so I don't really mind all that much. I have no idea why it's running so hot after installing this one additional drive. Fixing that is my next highest priority.
Sent from my moto g(7) using Tapatalk














[Solved] Ran out of cache space, dockers crashed/won't respond.
in General Support
Posted
Additionally, some of the dockers have a Question mark symbol instead of their usual icon: