



bfeist
Members
-
Joined
-
Last visited
Everything posted by bfeist
-
Thanks for this. I'll keep a manual driver update in mind when I tackle this again. In the meantime I reverted to 6.9.4 and everything is stable again. I'll have another look in a few months.
-
Hoping to get some help on this ongoing saga. I've been running 6.12.4 with the RTK 8156 plugin for a long while (a year?) at full 2.5Gbps. Got to this point after an 18 month fight with the drivers and am very thankful for this plugin. I remember at the time that I couldn't upgrade past 6.12.4 or the network driver would break so I just left things there. I should define "thing would break" - The USB RTK 8156 nic would run at full speed for quite some time (anywhere from 30 minutes to a few hours) before suddenly dropping completely offline. My server is headless so getting back online requires a hard reset of my system at which point it comes back online for 30 minutes to a few hours before dying again. Tailing syslog shows no notifications leading up to the NIC dropping offline. 6.12.4 plus the driver plugin fixed this. Fast forward to yesterday when I forgot the above and happily upgraded unraid to 6.12.13. As the upgrade progressed, I saw a notification in the web UI that said that the RTK plugin was being updated as part of the OS upgrade. I'm now back to square one, suffering with the NIC dropping offline after some period. To add to this, I no longer get 2.5Gbps even though unraid reports a link at 2500Mbps. I get around 830Mbps using iperf3. Do I try to revert to 6.12.4? I don't know how I could figure out what version of the plugin I used to have that was working. Any advice would be greatly appreciated.
-
bump. any thoughts?
-
Sure thing. Here it is. my-OwnCloudOCIS.xml
-
I'm trying to setup OwnCloud OCIS which doesn't have a community application template. I've created everything in the unraid docker config and have successfully started the service. However, every time I stop the container it becomes orphaned, has to be deleted and then recreated via "add container" (which picks up my saved config to create a new container). How do I get unraid to stop orphaning the image? Thanks!
-
Thanks, that did it
-
-
Hi all, I've been getting a new error starting with 6.12.1, I believe. I'm on 6.12.2 now and it continues. The log fills with the following errors: Jul 3 00:44:51 Tower kernel: radeon 0000:00:01.0: GPU lockup (current fence id 0x000000000001e95b last fence id 0x000000000001e95c on ring 6) Jul 3 00:44:51 Tower kernel: radeon 0000:00:01.0: ring 6 stalled for more than 365322385msec Jul 3 00:44:51 Tower kernel: radeon 0000:00:01.0: GPU lockup (current fence id 0x000000000001e95b last fence id 0x000000000001e95c on ring 6) Jul 3 00:44:52 Tower kernel: radeon 0000:00:01.0: ring 6 stalled for more than 365322889msec Jul 3 00:44:52 Tower kernel: radeon 0000:00:01.0: GPU lockup (current fence id 0x000000000001e95b last fence id 0x000000000001e95c on ring 6) Jul 3 00:44:52 Tower kernel: radeon 0000:00:01.0: ring 6 stalled for more than 365323393msec I'm running an old AMD `AMD A10-7850K Radeon R7, 12 Compute Cores 4C+8G @ 3700 MHz` CPU. It has a GPU onboard that I'm not using for anything and I don't have a GPU card in the server. Any help you could provide would be greatly appreciated. Diagnostics attached. tower-diagnostics-20230704-2324.zip
-
Thanks very much. That did the trick! Ben
-
I see two (see below) I performed the following as you instructed: Made a dummy change to eth0 - I changed the default gateway, applied changes then changed the value back, applied changes Rebooted. Default route missing again, no route to internet. Screenshot below. Diagnostics after reboot attached. Last year I did make an attempt to add a usb-based NIC but it's no longer connected. This might be the root of the problem. Thanks again. tower-diagnostics-20230628-1211.zip
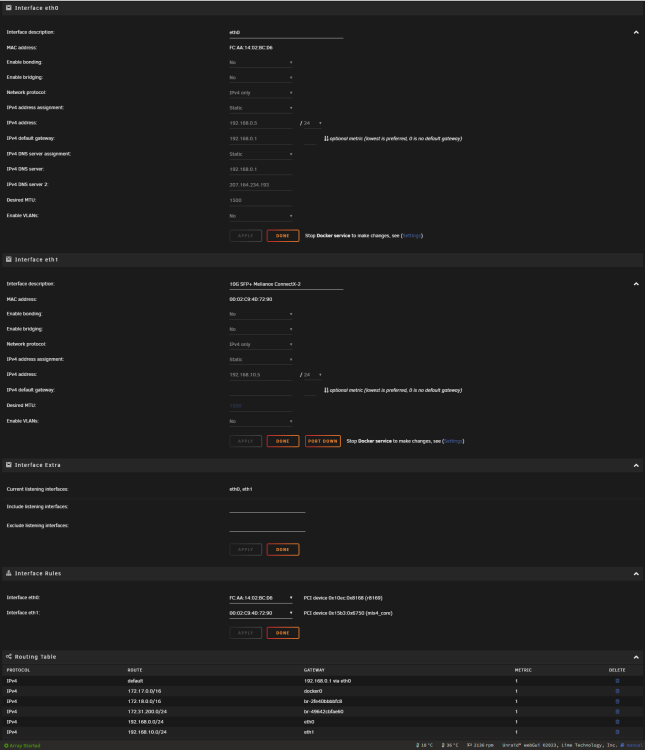
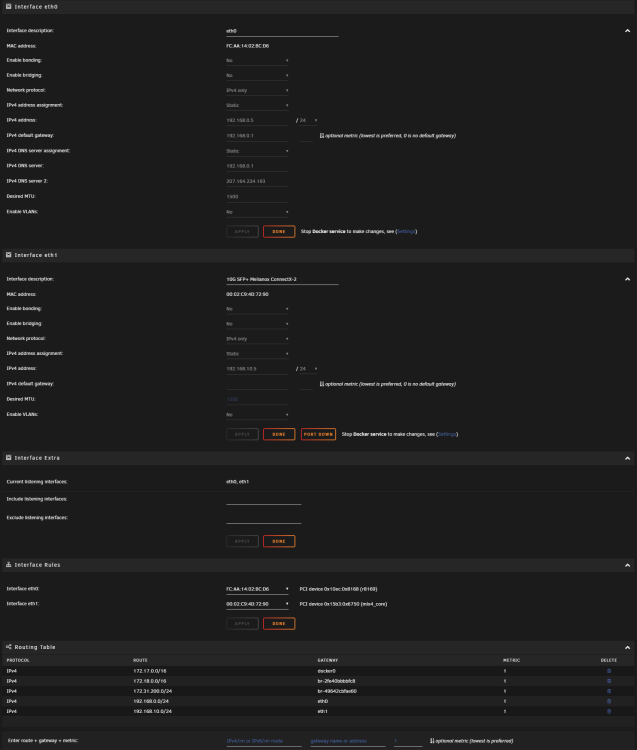
-
Default gateway was already set on `eth0`. Diagnostics attached. I appreciate the help. tower-diagnostics-20230628-1002.zip
-
For some reason, each time I upgrade to a new version of unraid, I can't route to outside the network. I discovered it's because the default route is missing. In the file attached, you can see the line I have to add manually in order to restore outbound network access. Any thoughts as to how I can fix this? Thanks!
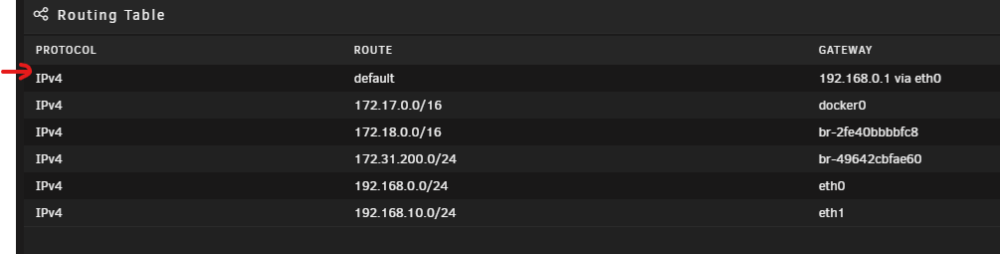
-
Update on this for the general information of anyone reading this thread: It turned out that one of my drives which wasn't showing as failing at all was getting itself into a very very slow (bytes per second) state when writing files to it. This would appear whenever my mover script decided to write to that drive. No SMART errors appeared and unraid didn't handle the situation at all, everything just slowed to a crawl. I could eventually stop the array and reboot. This would put everything back to normal for possibly weeks--until the mover decided to write to that one drive again. I finally decided to just replace it to see what happens. Since replacing it I have done several data operations across the whole array (upgraded my dual parity drives to 18TB drives) with no issues. No clue what's wrong with that one drive. I ran a preclear on it just for fun and it worked with no problems and threw no errors and reported no reallocated sectors. No idea why any of this happened but hey.
-
Thanks very much! I’ll try flipping one the other way around. I actually don’t know which way is “up” anyway. It’s also useful to know that it might be a connection issue between the drive and the cage.
-
@magictoaster76Did your other cages have the same problem? I'd like to try to get to the bottom of this. I'm interested to hear any thought you might have.
-
Amazon.ca here as well. All 6 of mine have this problem but they are all in my server at this point, so there's no returning them. If you do manage to fix one, please let me know how you did it. I'll pull my server apart and will do the same. This is a pretty crazy problem to be having consistently across many devices. When this first happened, I contacted Icy Dock and got a formulaic answer about sending the faulty items to them for inspection. Not interested in doing that.
-
Sadly, no. Interesting to hear that you have the same problem. Did you buy yours off Amazon? Maybe that seller is selling a whole pile of defective units.
-
That's what I was worried about. This is very unusual. I just did a parity verification a week or so ago and it ran at full speed with no errors.
-
How did you determine which drive was the problem, or are you talking about the drive that was being rebuilt?
-
I'm experiencing this right now, attempting to rebuild to an older drive that I successfully precleared. @jedimstr, are you saying that the drive being rebuilt to might be bad and is causing this?
-
Also, I found a bug in "Ultimate UNRAID Dashboard - Version 1.6 - 2021-03-20 (falconexe).json". Line 6016 is currently: "datasource": "Varken", But it should be: "datasource": "$Datasource_Varken",
-
No prob. Attached. telegraf.conf
-
Thanks for this great tool! I just spent hours working through setting it up. With fresh eyes on the install process I would like to suggest to @falconexeputting version numbers for each docker on the first post (as of today): docker - influxdb:1.8.4-alpine (I see there's an image of this in the first post, but I didn't realize this was a version restriction) docker telegraf - telegraf:1.19.2-alpine Also, including a default telegraf.conf that matches `telegraf:1.19.2-alpine` and the panels in UUD 1.6 would be great. I guess now I need a faster motherboard/CPU too because this dashboard uses ~20% of my resources lol.
-
Sorry for the delayed reply. Temps are great. Below is an image I just took of current temps, and this is after I added a dust cover across the front of the cases.

-
Nope. Icy Dock support has no idea what's going on. It's possible the amazon seller who sold me the drive cages was shipping faulty cages.




