iripmotoles
Members
-
Joined
-
Last visited
Everything posted by iripmotoles
-
Excellent. Thank you so much for your help!
-
On the emulated drive now I don't have the Lost+Found folder. I will check again after rebuild.
-
Ok, thank you. I cancelled, then checked and repaired the drive with the following output: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata sb_ifree 350, counted 348 sb_fdblocks 1172213351, counted 1189241404 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 inode 4455004287 - bad extent starting block number 4503567550636411, offset 0 correcting nextents for inode 4455004287 bad data fork in inode 4455004287 cleared inode 4455004287 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 5 - agno = 2 - agno = 3 - agno = 4 - agno = 1 - agno = 6 - agno = 8 - agno = 9 - agno = 7 entry "DeloreanASAnnotationToolbarView.nib" at block 0 offset 560 in directory inode 4455004273 references free inode 4455004287 clearing inode number in entry at offset 560... Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... bad hash table for directory inode 4455004273 (no data entry): rebuilding rebuilding directory inode 4455004273 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (14:2462824) is ahead of log (1:2). Format log to cycle 17. done Then I stopped the array and started it normally, now it has started a new Data-Rebuild. My shares are back but of course have an exclamation mark for being unprotected. I will report back the results. If everything is back to normal after the rebuild, I will install the newly ordered drive as dual parity.
-
Thank you for your reply. Does it make sense to cancel the Data-Rebuild in order to attempt check/repair or is it better to let the rebuild run through?
-
Hi All, the other day I upgraded my seemingly fully functioning server from 6.12.6 to 6.12.8. After the upgrade certain dockers wouldn't start anymore and the attempt gave me an "execution error". I didn't realize or suspect a potential issue with my array. I urgently needed to access my paperless docker and in a knee-jerk reaction I downgraded to 6.12.6 and then upgraded to 6.12.8 again. Edit: I forgot and now remembered: After the first upgrade, the Server became unreachable and I forced a reboot. Later I had the time to investigate a bit further and finally found my main Disk 1 being unmountable. I stopped the array and today started looking into the issue. First I downloaded diagnostics, see attached (edit: attachment removed after problem was solved). Then I followed this advice, stopped the array, unassigned the drive and started again. I didn't notice an emulated drive, most of my shares were gone and the docker issue persisted. I then stopped the array, assigned the drive again and started the array. A data-rebuild started that I paused and that's where I'm standing now. I have ordered a new drive that will arrive tomorrow. Any help would be highly appreciated.
-
Wieso?
-
Ok, thank you! Once the initial backup is completed I will compare the directories with krusader synchronize and see what happened. Edit: You were right, the destination size is almost half of the original directory. Maybe you could put a short warning in your opening post. Sooner or later there will be somebody out there that set this up the way I intended and thinks that it works. Looking further opened a whole new can of worms. I suspect using another backup solution such as CCC instead of time machine would end with the same issue. I will keep looking for another solution for simple synchronizing, maybe something like unison.
-
I want to use the script to rsync time machine backups which in itself have hard links. Therefore I believe I need the -H flag to preserve the hard links in order to not break the time machine functionality. @mgutt Can I just change your script to -avH without messing with its functionality?
-
Kommt aufs Case an. Die von dir ausgesuchte ist Full Profile. Je nach Case kann es sein, dass du Low Profile brauchst. Da ist dann einfach das Slot-Blech kürzer.
-
Laut unraid wiki geht das:
-
Nee, Unraid läuft vom USB-Stick. Wenn du deine SATA SSDs als Cache nimmst, brauchst du keine NVME.
-
Wieso Selbstbau? Die Kiste muss man doch nur auspacken, Platten reinstecken und installieren. socke braucht anscheinend kein Array in so astronomischen Größen, wie man es hier im Forum oft liest. Für den normalen Hausgebrauch reicht doch bei den heutigen Festplattengrößen eine Platte plus Parität ewig. Falls die wider Erwarten irgendwann doch mal voll wird, kann er eine weitere Platte hinzufügen die dann wieder ewig reicht. Klar ist es irgendwie cool, einen Speicher mit dreistelligen TB zu haben. Braucht aber eben nicht jeder.
-
Wenn du Abstriche in der Ausstattung machen willst: Fujitsu D3644-B, nur ein M.2 slot und ein NIC onboard, zwei SATA ports weniger. Wenn du Abstriche beim Stromverbrauch und beim Kaufpreis machen willst: Supermicro, zB. X11SCH-LN4F. Tolle Ausstattung aber kostet derzeit so ab 300€. Ich habe letzten Monat ein C246M-WU4 bei mindfactory gekauft aber leider hat der Chipsatz gesponnen. Wollte dann nicht ewig auf Ersatz oder Reparatur warten und habe mir den Preis erstatten lassen. Hab dann eins bei Amazon erwischt. Kein Warehouse Deal, direkt von Amazon. Die haben mir aber ein Board mit verbogenen Pins am Sockel geschickt, großzügig mit Leitpaste vollgeschmiert. Also Vorsicht mit Amazon. Haben sie mir aber ersetzt durch eins, was gut aussieht und bisher gut funktioniert.
-
Erstens hat er nach einem gen 10 plus gefragt und zweitens braucht er keinen zusätzlichen SATA Controller. Falls eine iGPU gewünscht ist, würde ich den T40 nochmal ins Spiel bringen. Da die drei 3,5" Bays hier ausreichend sind, ist der doch für den Preis ein tolles Gesamtpaket. Cache je nach Anspruch per SATA oder PCIe-NVME Adapter. Laut elefacts braucht der 15,1 W + Festplatten im Leerlauf mit Unraid.
-
Here you go.

-
Nein, zwingend ist das nicht. Du kannst die VM's auf deinen Cache-Pool legen. Lies mal hier.
-
Naja, alles ist da nun auch nicht proprietär. Vor allem Mainboard und Netzteil. Sollte da mal etwas nach Ablauf der Garantie den Geist aufgeben und Ersatz wirklich so teuer sein, hat man immer noch die Option, die restlichen Komponenten in ein anderes Case umzuziehen. Ich hab für meine Eltern als NAS den Microserver in kleinster Ausstattung mit Pentium Gold gekauft. Ich finde den für den Preis von aktuell 440€ mit der Ausstattung schon super. Dazu einen SFF Adapter für eine SATA-SSD. So klein wird man einen Eigenbau nicht hinbekommen und so günstig wahrscheinlich auch nicht. NVME fehlt leider, würde zwar per PCIe-Adapter passen aber die Stelle liegt überhaupt nicht im Luftstrom, das wird wahrscheinlich zu warm. Alternative wäre vielleicht ein Dell T40. Ist etwas größer (gar nicht mal so viel) aber dafür gibt es da sogar für unter 500€ einen Xeon und eine 1TB HDD dazu. Das ist preislich zur Zeit eigentlich kaum schlagbar. Der hat allerdings nur drei 3,5" bays. M.2 slot ist zwar vorhanden aber wohl deaktiviert. Dafür kann man den PCIe-Slot vielleicht besser belüften. Ob man den SATA vom optischen Laufwerk für eine HDD oder SSD nutzen kann, wäre noch interessant. In so einen 19" Verteilerschrank würde vermutlich auch der Dell passen. Wenn der Schrank nicht direkt unter der Decke hängen muss, könnte man den Server auch oben drauf stellen oder legen. Dann kommt auch kühlere Luft dran. Ansonsten ein einzelnes Regalbrett unter bzw. neben den Schrank hängen und den Server darauf.
-
Brilliant, thank you! Very helpful. I will contact the vendor.
-
Yes, those would be the next logical steps for fault isolation. However, I don’t have either laying around and I will certainly not buy another board to find out what’s wrong with the one I‘ve bought only a few weeks ago. It sounded like @UhClem actually found something useful in my syslog and I‘d much rather make a well founded warranty claim on my existing purchase. Edit: For what it's worth, as you guys predicted the preclear + post-read on the microserver came out with zero new errors on the new disks. Maybe this thread should be moved to General Support?
-
Thanks for the feedback guys, very interesting. The board came with the latest BIOS version. Do you mean flaky chipset as in a bad unit or as in a bad model / series? Return the board for direct replacement or change to another product? Can you please elaborate a bit on the details in the syslog for my warranty claim?
-
They are going through without any errors so far, clearing completed and half of post-read. Afterwards I will try them again in my server with yet another set of SATA cables and on different ports of the board. Any BIOS settings I could check out, bearing in mind that everything works great with the WD drives?
-
Got it, thank you. Will try them in the microserver.
-
So then what can be gained exactly by trying the disks in another system? If I understand you correctly I have already narrowed it down to an incompatibility between the Toshiba MG and the C246 chipset? Any thoughts on the nvme error at the time of the crc error?
-
After first noticing the issues, I hooked up the Toshiba drives to the cables (and respectively ports on MoBo) that were working fine with the WD drives. So I can pretty much rule out SATA ports and cables. I have a new HP microserver gen10+ sitting here and was planning on putting the 4TB drives in there for my parents NAS needs as well as cross offsite backup. I could put the Toshiba drives in and try to preclear them there. Is it worth waiting for the preclear results before pulling the drives from my server?
-
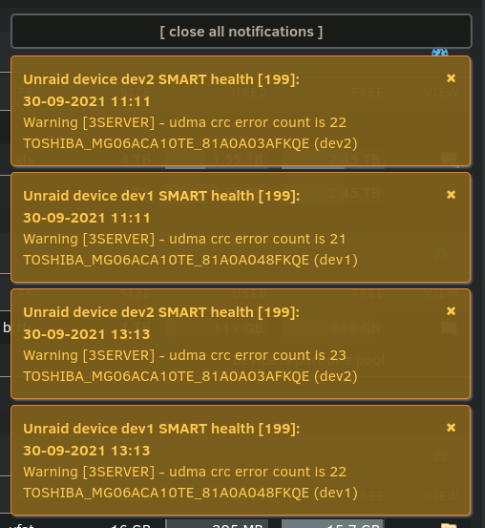
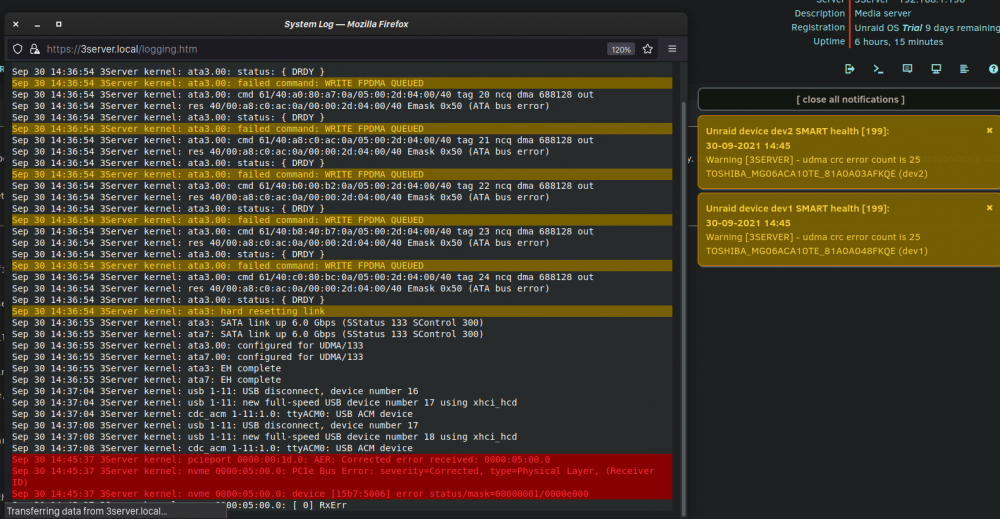
tl;dr: Replaced the mainboard, issue fixed. Thanks a lot for the help! Hi guys, I have a recently built a server with the following config: Gigabyte C246M-WU4 Xeon E-2176G 1x Kingston Server Premier DIMM 32GB ECC 2x WD Black 1TB NVMe Cache 2x WD Red 4TB WD40EFAX be quiet! Pure Power 11 FM 550W Everything running very nicely and happily. Two days ago I installed additionally two Toshiba Enterprise 10GB MG06ACA10TE. All disks connected directly to the MoBo, all on one of the modular power cables of the PSU. Then started preclearing both new disks. Yesterday I woke up to find several error notifications. Unraid dev1 SMART health [199]: Warning - udma crc error count is... I aborted the preclear, shut down the system and swapped the sata cables from the WD to the Toshiba drives and installed new cables on the WD disks. Then I started a new preclear on both Toshiba but the errors kept coming up. Shut down the system again and installed another modular power cable so only two disks per outlet on the PSU. This time resumed the previous preclear. The errors keep coming. First I thought that maybe the parcel with the two disks was mishandled during transport. But at some point I noticed something strange: The errors are almost always happening on both disks at the same exact minute. Not sure at when I got the one error mismatch. At some point I lost patience and put one of the new disks into the array as second parity but immediately realized my stupidity and took it out again. System log is pretty colorful but I can't make much sense of it. I saved diagnostics before each shutdown except the very first one for the disk install. This screenshot is from today. Can't find anything in the syslog for these times: Preclear is still running, currently 90% zeroing. I will post results once finished. Any help would be highly appreciated. Edit: Just found a correlation between SMART notification and syslog: Sep 30 14:45:37 3Server kernel: pcieport 0000:00:1d.0: AER: Corrected error received: 0000:05:00.0 Sep 30 14:45:37 3Server kernel: nvme 0000:05:00.0: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Sep 30 14:45:37 3Server kernel: nvme 0000:05:00.0: device [15b7:5006] error status/mask=00000001/0000e000