




unraidyn
Members
-
Joined
-
Last visited
Everything posted by unraidyn
-
Super, thanks!
-
I've just submitted a PR
-
Found the problem, it is indeed recursion: https://github.com/SimonFair/tasmotapm-unraid/commit/42d19aa714319843114c626059dd9c5fae094a90#diff-ffc2f4755a67ff8df0cc721d1c185eee2502fd60ec1193caf6b36ecb34f1b9dbR106 The setInterval call needs to be at the page level as its a repeat call not a delayed call, as at the moment its nested within the tasmotapm_status() method, meaning each time its calling itself N+1 times. The fix should be to move the setInterval call outside of the method. You can replace the page load call to start itself with the setInterval code. I can submit a PR if you'd like.
-
Doing some debugging, it appears to be an N+1 problem. For some reason, the network calls to `/plugins/tasmotapm/status.php` are being stacked upon each setInterval call. When each interval passes, by default every 1000ms, N+1 calls occur. Thats how it spirals so quickly.
-
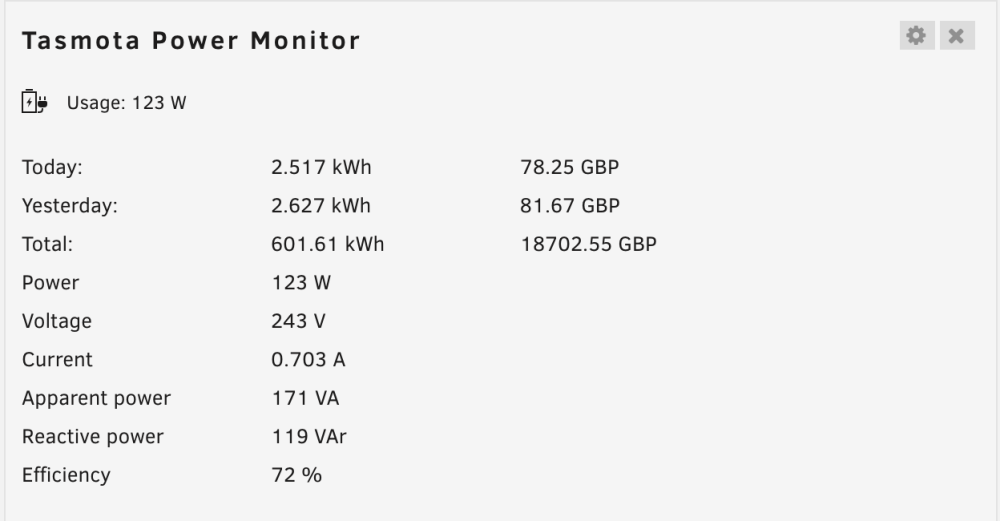
You amazing person you! Just updated to 6.12, relitively smooth but had a panic with "Unmountable: Unsupported or no file system" after enabling the "Permit exclusive shares:" option. Luckily a reboot fixed it, panic over for now. Now to take a look at this! Appears to be working - however, there appears to be a pretty nasty bug. After a few seconds (iterations), the values stop updating at the set interval (tried at the default 1000ms, 2000ms, etc) and instead start racing along faster and faster until either the tab or browser crashes. It also caused the plug to overload and reset as well, presumably due to the amount of requests being performed overloading its little webserver. There is a video of it malfunctioning attached. bug.mov This is with the default polling rate of 1000ms, in FireFox 114.0.1. Now that to me smells like instance stacking or something recursive calling successive setIntervals, causing it to scale exponentially. I'll start to debug, remembering to refresh regularly haha
-
Currently waiting on a time frame to update my box, will report back with findings, will probs be an hour or so.
-
You're a legend 🥳 You beat me to it, was just looking at your repos git history (mainly the NUT one) to see what updates were required to migrate from 6.12 and how that would translate to this project. My first time looking at Unraid plugins, but I'm a senior dev by trade so was giving it a go, looking through dev threads and 6.12 update changes to try and reverse what needs updating. Looks like the dev wants a new owner for the projects: Would you mind doing what you did for the NUT and IPMI projects and taking ownership? The plugin also requires posting onto CA as its currently unlisted. I can take what you've done and publish a fork, with some guidance as this is the first Unraid plugin I'm looking at (especially CA publishing), but you seem to know what you are doing 😉
-
Super, thanks!
-
Super, I've just come across this issue too, and I think I'll have to wait for that update to resolve my issue. In my use case, the local TLD is correct, as is the hostname, but as I'm using a different port to access Unraid (as port 80/443 is being used by the reverse proxy itself) Unraid throws the following error: In which I understand why its doing that, but obviously I can never resolve that issue without having some manual control over the allowed origins list, or supporting reverse proxies. Which I take it will be resolved in that future update regarding custom allowed origins?
-
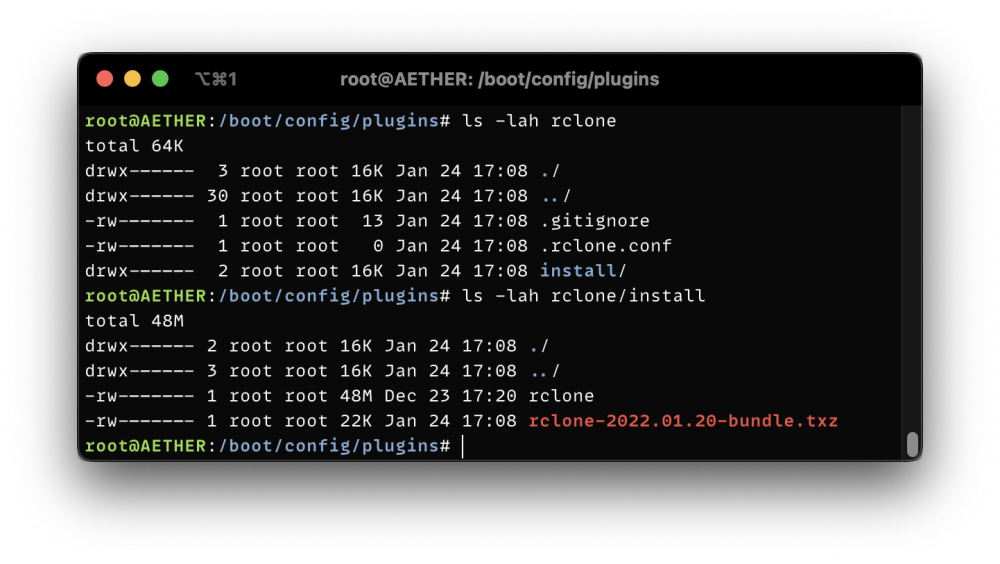
If you want to know something really weird, if I modify the plugin to delete the plugin directory as the first action in the installation script: if [ -d /boot/config/plugins/rclone ]; then rm -rf /boot/config/plugins/rclone fi; It works fine. There is something about that specific '/boot/config/plugins/rclone/install/rclone' file that my install really doesn't like.
-
Ah right okay, I could swap to a different flash drive, but its behaving absolutely fine otherwise. What's super weird is no other plugins have this issue, this is the only plugin. And what makes it weirder, it also doesn't occur if the rclone plugin doesn't already exist on the drive. It downloads and installs just fine. Is there any file system integrity test or something I can perform on the USB drive? Running an 'fsck' said the drive was normal and healthy.
-
Mine is doing the exact same thing, works on any other machine, but repeatedly on Unraid just keeps cycling USB: Jan 25 12:43:55 AETHER kernel: usb 5-1: USB disconnect, device number 16 Jan 25 12:43:59 AETHER kernel: usb 5-1: new low-speed USB device number 17 using xhci_hcd Jan 25 12:44:00 AETHER kernel: hid-generic 0003:06DA:FFFF.0011: hiddev96,hidraw2: USB HID v1.00 Device [PPC Offline UPS] on usb-0000:2c:00.3-1/input0 Jan 25 12:44:14 AETHER kernel: usb 5-1: USB disconnect, device number 17 Jan 25 12:44:18 AETHER kernel: usb 5-1: new low-speed USB device number 18 using xhci_hcd Jan 25 12:44:18 AETHER kernel: hid-generic 0003:06DA:FFFF.0012: hiddev96,hidraw2: USB HID v1.00 Device [PPC Offline UPS] on usb-0000:2c:00.3-1/input0 Jan 25 12:44:32 AETHER kernel: usb 5-1: USB disconnect, device number 18 Jan 25 12:44:36 AETHER kernel: usb 5-1: new low-speed USB device number 19 using xhci_hcd Jan 25 12:44:36 AETHER kernel: hid-generic 0003:06DA:FFFF.0013: hiddev96,hidraw2: USB HID v1.00 Device [PPC Offline UPS] on usb-0000:2c:00.3-1/input0 Jan 25 12:44:50 AETHER kernel: usb 5-1: USB disconnect, device number 19 Jan 25 12:43:37 AETHER kernel: usb 5-1: USB disconnect, device number 15 Jan 25 12:43:41 AETHER kernel: usb 5-1: new low-speed USB device number 16 using xhci_hcd Jan 25 12:43:41 AETHER kernel: hid-generic 0003:06DA:FFFF.0010: hiddev96,hidraw2: USB HID v1.00 Device [PPC Offline UPS] on usb-0000:2c:00.3-1/input0 Jan 25 12:43:55 AETHER kernel: usb 5-1: USB disconnect, device number 16 Jan 25 12:43:59 AETHER kernel: usb 5-1: new low-speed USB device number 17 using xhci_hcd Jan 25 12:44:00 AETHER kernel: hid-generic 0003:06DA:FFFF.0011: hiddev96,hidraw2: USB HID v1.00 Device [PPC Offline UPS] on usb-0000:2c:00.3-1/input0 Jan 25 12:44:14 AETHER kernel: usb 5-1: USB disconnect, device number 17 Jan 25 12:44:18 AETHER kernel: usb 5-1: new low-speed USB device number 18 using xhci_hcd Jan 25 12:44:18 AETHER kernel: hid-generic 0003:06DA:FFFF.0012: hiddev96,hidraw2: USB HID v1.00 Device [PPC Offline UPS] on usb-0000:2c:00.3-1/input0 Jan 25 12:44:32 AETHER kernel: usb 5-1: USB disconnect, device number 18 And it will just keep going until I unplug it... SOLVED: Manually selected the "Usbhid-ups" driver in NUT and NUT grabbed the device before it had chance to disconnect again. Appears its something to do with the device firmware having a really short timeout if the device isn't captured by the appropriate driver in time. See: - https://serverfault.com/questions/994338/how-can-i-fix-my-ups-repeatedly-disconnecting-and-reconnecting - https://www.linuxquestions.org/questions/slackware-14/usb-device-keeps-connecting-and-disconnecting-slackware-14-specific-4175471128/
-
Nope, it appears its still broken. Not sure what to do, but this is currently making the server unbootable in its fresh-installed state.
-
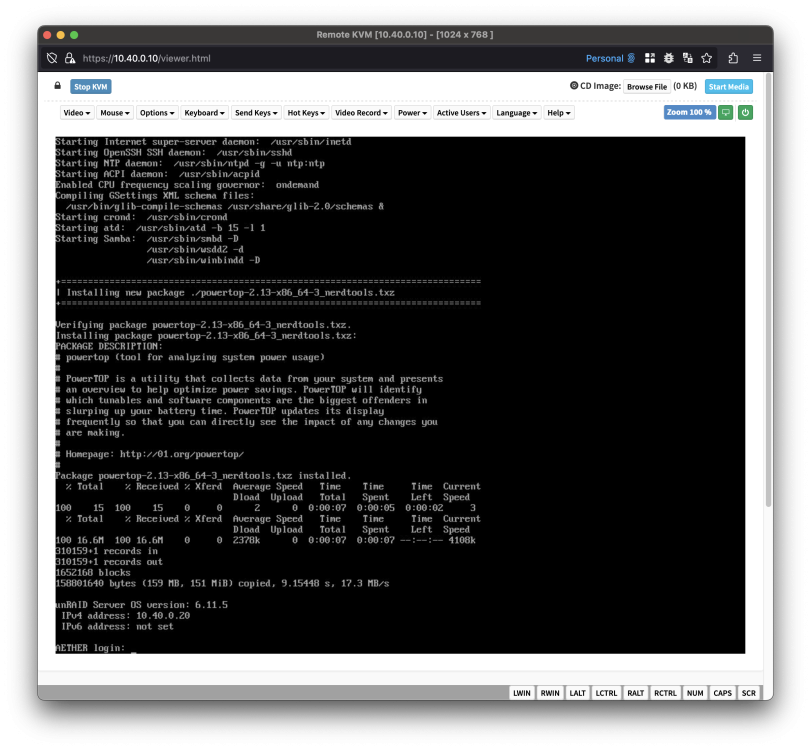
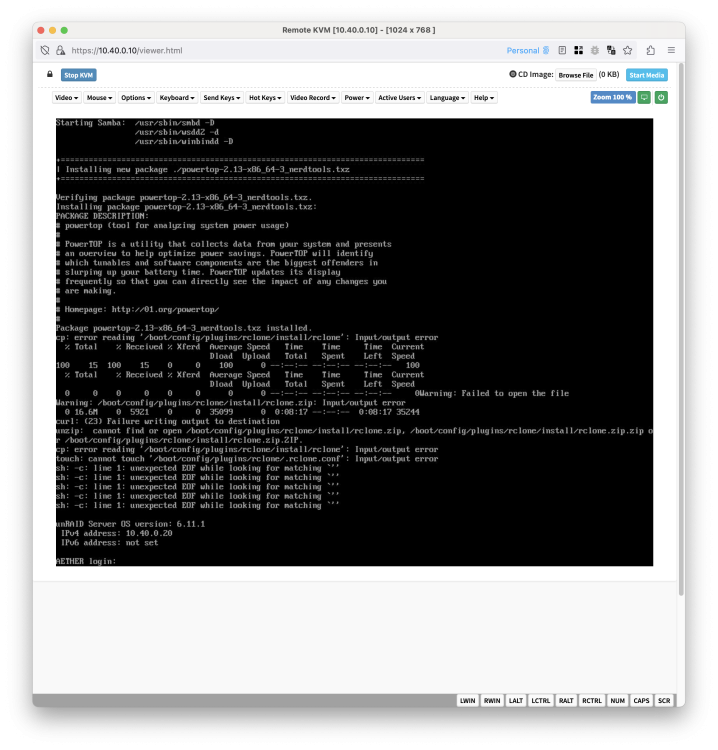
I'm having an issue that is breaking Unraid boot, for some reason it fails each boot. In order to fix it, I have to put the USB drive into my main machine and delete/move the rclone directory to allow it to rebuild from scratch on boot; mv /boot/config/plugins/rclone /boot/config/plugins/rclone.old (or something to the same effect) Unraid 6.11.5 and 6.11.1. I've just re-installed the plugin and will report if that has fixed it as I have a reboot tomorrow to install a new USB PCI-e card. This screenshot is the broken boot: This screenshot is after moving/deleting the `/boot/config/plugins/rclone` directory: Permissions of `/boot/config/plugins/rclone`:
-
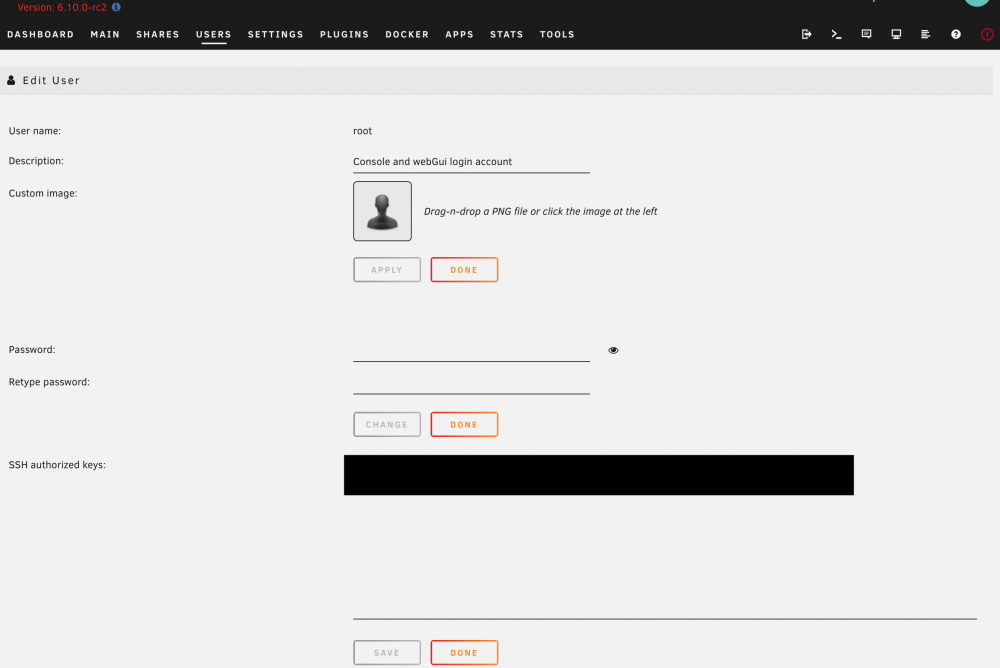
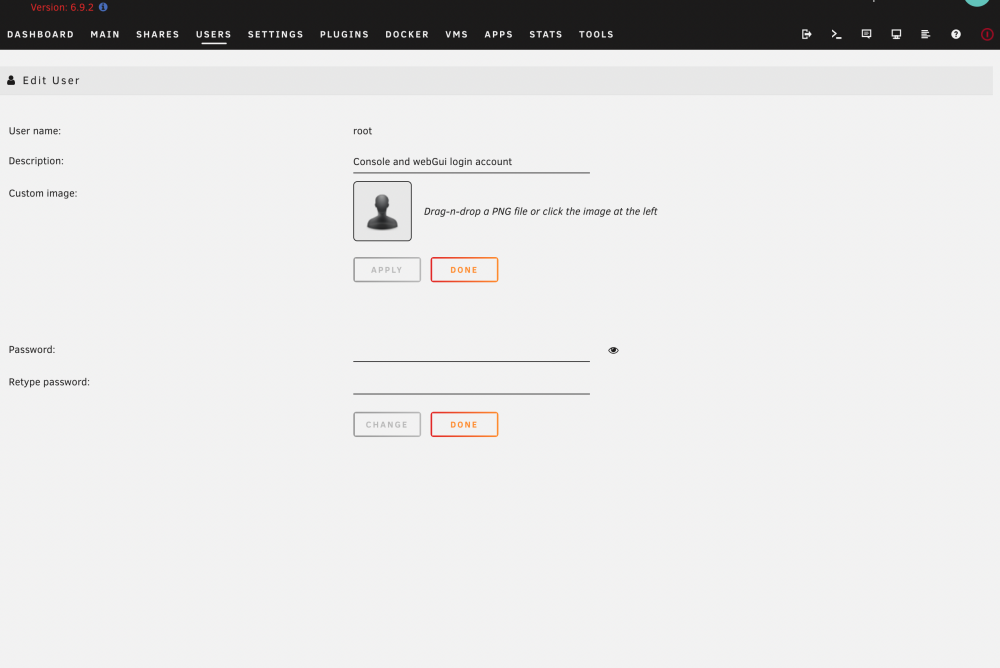
Doesn't appear to work on Unraid 6.9.2, as I can't get the WebGUI to load the 'SSH authorized keys' box on the 'Edit User' page. Both of my other 6.10.0-rc2 boxes however loads this fine. Logs are empty and so is the console, there doesn't appear to be any errors, it just doesn't load the WebGUI on 6.9.2. See attached both screenshots. Should also mention I've done multiple re-installs, which has no effect. 6.10.0-rc2: 6.9.2:
-
Sorry to resurrect an old thread... but to anyone coming across this problem in future, here is an easy solve applying a little beginner linux knowledge; # Take a backup of $PATH to restore later # Note: This will only keep the variable alive for the current session! $ PATH_TEMP=$PATH # ... just to make sure the $PATH_TEMP variable has been stored $ echo $PATH_TEMP .:/usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin # Print the current $PATH so we can extract all paths except the current directory, so we can override it $ echo $PATH .:/usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin #-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ # Copy everything BUT the first current directory marker (.) and break character (:) # Next, export the modified $PATH to override it for the current session using the string you copied above $ export PATH=/usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin # ... just to make sure the $PATH variable change has been stored $ echo $PATH /usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin # --- # ... now you can run the find command! # --- # To restore the session $PATH either close your current terminal session and start a new one, or to manually restore # the current session, lets load $PATH back from the $PATH_TEMP variable set earlier $ export PATH=$PATH_TEMP # ... verify everything is back to normal. Looking good! $ echo $PATH .:/usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin
-
Oh my gosh, that was it! THANK YOU!!! Now just to figure out why its responding to LAN clients and not WLAN... despite being pingable (@ :53) and accessible to WLAN clients. EDIT: DNSMASQ_LISTENING doesn't work across subnets when set to 'local', it has to be 'all'
-
I thought that too, but it does. The device is accessible and listening on 10.0.0.201 with that DNS server being reported via UniFi DHCP so all clients are pointing at it. Tail'ing the PiHole log in realtime on the container `pihole -t`, I can see local client lookups are going through fine: # ----- # Local machine @ 10.0.0.23 01:42:36 in ~ ➜ nslookup google.com Server: 10.0.0.201 Address: 10.0.0.201#53 Non-authoritative answer: Name: google.com Address: 142.250.180.14 01:42:41 in ~ ➜ nslookup internal.othyn.com Server: 10.0.0.201 Address: 10.0.0.201#53 Name: internal.othyn.com Address: 10.0.0.200 # ----- # Pihole @ 10.0.0.201 $ pihole status [✗] DNS service is NOT listening $ pihole -t Jan 5 01:42:41: query[A] google.com from 10.0.0.23 Jan 5 01:42:41: forwarded google.com to 1.1.1.1 Jan 5 01:42:41: reply google.com is 142.250.180.14 Jan 5 01:42:43: query[A] incoming.telemetry.mozilla.org from 10.0.0.23 Jan 5 01:42:43: gravity blocked incoming.telemetry.mozilla.org is 0.0.0.0 Jan 5 01:42:50: query[A] pihole.internal.othyn.com from 10.0.0.23 Jan 5 01:42:50: /etc/pihole/custom.list pihole.internal.othyn.com is 10.0.0.200 Jan 5 01:42:54: query[A] pi.hole from 127.0.0.1 Jan 5 01:42:54: Pi-hole hostname pi.hole is 10.0.0.201 Jan 5 01:42:57: query[A] oxserv.internal.othyn.com from 10.0.0.23 Jan 5 01:42:57: /etc/pihole/custom.list oxserv.internal.othyn.com is 10.0.0.200 Jan 5 01:43:00: query[A] internal.othyn.com from 10.0.0.23 Jan 5 01:43:00: /etc/pihole/custom.list internal.othyn.com is 10.0.0.200 Jan 5 01:43:24: query[PTR] 23.0.0.10.in-addr.arpa from 10.0.0.23 Jan 5 01:43:24: config 10.0.0.23 is NXDOMAIN Jan 5 01:43:25: query[A] pi.hole from 127.0.0.1 Jan 5 01:43:25: Pi-hole hostname pi.hole is 10.0.0.201 So I have no idea WTF is going on as its responding to client requests with upstream DNS from CF.
-
I'm absolutely loosing my mind over deploying this... Running tag 2022.01 using the recommended setup. I have DNS resolving and 'working', but when I actually check the docker container by running `pihole status`, I just get `[✗] DNS service is NOT listening`, the webUI also reports "DNS service not running" constantly. I've spent the last few hours trawling through just about every GH issue on the topic and help page on here trying all sorts of solutions. I've nuked the container and appdata around 3 times now for fresh installs to try and fix things, nothing is working. I have the container running on br0 at an address of 10.0.0.201 which is static, which is also the value of ServerIP. PIHOLE_DNS_ is configured to 1.1.1.1;1.0.0.1 with DNSMASQ_LISTENING set to local. All other options are default. This is my diag report: diag.log







