neuer_unraider
Members
-
Joined
-
Last visited
Everything posted by neuer_unraider
-
Hey, I've got a rare opportunity to host my Unraid at a friends datacenter space for basically only electricity cost, which would be a superb deal for me and finally solves the issue with having an offsite backup. I only ever used Unraid on my old desktop case/PC and it worked flawlessly since then. However, to take this opportunity, I'd have to move my Unraid to a Dell PowerEdge R730xd case provided by him. I am exactly 0 experienced in this area and from having a quick look at the tech spec, this thing doesn't offer a USB slot. Does this mean that I can't take this opportunity with Unraid? Or are there workarounds available (i. e. adding a PCIe-card which provides a USB slot or something) or being able to boot Unraid from a small SSD? The tech spec is here: https://i.dell.com/sites/doccontent/shared-content/data-sheets/en/Documents/Dell-PowerEdge-R730-and-R730xd-Technical-Guide-v1-7.pdf Thank you!
-
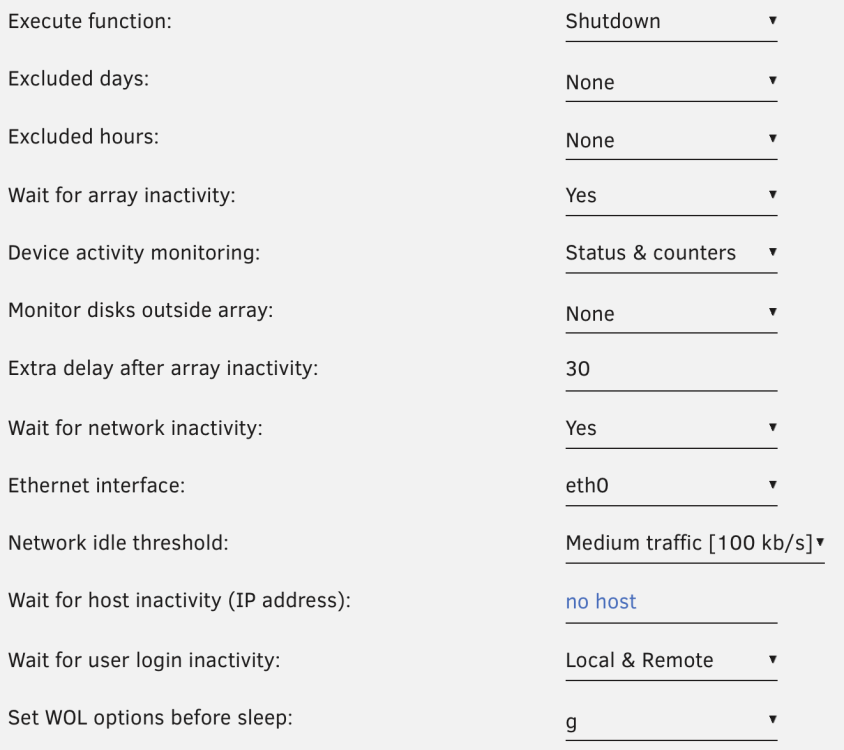
Hey, I am having problems with this plugin. I am using my NAS for Jellyfin mostly. I set "extra delay after array activity" to 30mins. Yet, whenever I am using Jellyfin on my Fire TV Stick, and pause the media for only 1 minute, UNRAID shuts down because of this plugin. It seems the extra delay is not recognized correctly. I also tried using "Yes, exclude Cache" for "wait for array inactivity", but it doesn't change anything. What am I doing wrong? Thanks!
-
I have some questions: Is /root/keyfile stored in RAM only (i. e. not written to disk)? Does UNRAID constantly scan for this file in the background? i. e. I boot the server and only 8 minutes later I am placing the keyfile there. Will it automatically decrypt/start the array then? Is there a HTTP-API available that I can call with the encryption key to start the array? Does this also somehow work with a passphrase only? Aka me sending the passphrase on-the-fly and not having a keyfile at all?
-
Thanks, it makes total sense. It's USB2 after all. I decided to not try it out, because the booting anyway needs to put the firmware into the RAM, so there is nothing saved skipping firmware checksum.
-
Hello, is there a solution to this available now? I want to sleep or shutdown my UNRAID instance using Shortcuts in iOS. For that I can either use a CURL command or a SSH command. Thanks!
-
Hi, I want to optimize the boot time of my UNRAID. I want to skip any bz* files/firmware verification. I know it's a risk to my data integrity, but I am willing to take that risk. This is by far the biggest chunk of startup time. How can I achieve that? Thanks!
-
S3 Sleep: is it possible to configure the plugin so that none of my disks in my array starts spinning? I don't need any of the disks after a wakeup and it's wasting energy every time I wake the server up. Thanks!
-
Das hat mich auf eine super Idee gebracht, ich mache nun was ähnliches: - Mit dem Sleep S3 Plugin von Dynamix den Tower automatisch einschlafen lassen, sobald das Array aus ist - Auf einem Raspi einen Reverse Proxy hosten, der bei einem Request einen Wake on LAN-Befehl sendet (werde ich noch einbauen) - Per iOS Shortcuts einen Wake on LAN-Befehl senden - Per Homebridge ein Apple Home Accessoir faken, sodass ich das per Siri sprachsteuern kann, welches ebenfalls ein Wake on LAN-Befehl sendet Aus dem Sleep aufwachen geht innerhalb von wenigen Sekunden und im Sleep zieht der Tower nur 3 Watt. So ist das halb-automatisiert und gut genug für den Anfang. Zusätzlich habe ich noch meine CPU undervolted und 2 von 4 RAM-Riegeln entfernt (die ich eh nicht brauche). Und powertop läuft nun auch nach dem Boot. Ich komme somit nun im Array-aus-Rest-an-Idle auf 32 Watt. Danke für Eure Ideen!
-
@doron can you add a flag to not replace the keyfile but rather add another one? I'd like to use a keyfile during normal operation but I am paranoid and would like to have an additional ultra-secure passphrase as a backup that I will remember that I definitely don't want to enter in because it takes a long time manually doing so.
-
Ich möchte gerne meine unRAID-Installation etwas umbauen und das Teil nur noch als Datengrab nutzen. Grund sind die horrenden Strompreise und eigentlich brauche ich das NAS nur 10min pro Tag, um da Backups draufzuspielen. Vielleicht mal für 1,5h, um einen Film über Jellyfin anzugucken. Mir kam also die Idee, das NAS quasi immer aus zu haben und nur entweder zu bestimmten Backup-Zeiten zu starten oder on-demand automatisch, wenn jemand über Jellyfin darauf zugreifen möchte (ich dachte da an Wake on LAN oder ähnliches). Hat damit jemand Erfahrung bzw. ist das umsetzbar, ohne dass ich manuell booten muss? Die Lösung zur automatischen Passphrase-Eingabe beim Boot habe ich schon gefunden. Mir geht es eher um die Praktikabilität der Idee. Meine Hardware ist nämlich uralt (2013, Intel i5 3570K / AsRock Extreme 4) und dementsprechend zieht das NAS auch viel Strom. Die paar kleinen Docker-Services hätte ich dann auf einen Raspi 4 gepackt, welches dann per SMB/NFS auf das Datengrab zugreift. Am unRAID hängen 2x NVMe als Cache sowie 4 HDDs. Danke für Eure Erfahrungen!
-
Thank you, that made it!
-
@Kilrah I am not hijacking anything, it's even officially documented here: https://wiki.unraid.net/Manual/Security#Custom_Certificates
-
This is the path it shows in the settings UI. I just replace that file with my custom certificate (it has nothing todo with Unraid.net or whatever server they offer), but nothing happens. Unraid only picks it up when I press "Provision". So I assume that I need to press that button. If there's a better way, please tell me

-
Hey, I'm providing a custom SSL certificate to Unraid and update it with a shellscript. Still, I need to click the "Provision" button under "Settings -> Management Access" manually: How can I invoke the functionality of that button from my shellscript that's running on the server?

-
Hey, some days ago I encountered weird system behaviour and could grab this out of `dmesg` before the system went unrensponsive. The call trace looks like it has something to do with swap. But after reseraching this for a while it seems that Unraid doesn't use a swap partition or swap file by default. Since I never configured a swap on Unraid as well, I am very confused about this panic and don't know if it even has to do with the swap that I know from classic Linux. No data seems to be lost on my disks or the boot stick. Parity check was successful. I'm using btrfs with 2 NVMes in a cache, 1 parity HDD and 3 additional HDDs. Is this some sort of case where cosmic radiation caused a bit flip (I'm not using ECC RAM) and I shouldn't worry about this or might there be a deeper root cause which I should investigate? [1320874.636401] BUG: unable to handle page fault for address: fffff8efcea4a488 [1320874.636416] #PF: supervisor read access in kernel mode [1320874.636421] #PF: error_code(0x0000) - not-present page [1320874.636426] PGD 0 P4D 0 [1320874.636432] Oops: 0000 [#1] SMP PTI [1320874.636438] CPU: 1 PID: 38 Comm: khugepaged Tainted: G W 5.14.15-Unraid #1 [1320874.636445] Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./Z77 Extreme4, BIOS P2.90 07/11/2013 [1320874.636451] RIP: 0010:_compound_head+0x0/0x11 [1320874.636462] Code: 89 e1 48 c7 c6 75 a2 eb 81 48 89 c2 e8 77 5e f6 ff 48 8d bb c8 10 00 00 5b 5d 41 5c 41 5d e9 f8 d3 f5 ff 5b 5d 41 5c 41 5d c3 <48> 8b 57 08 48 89 f8 f6 c2 01 74 04 48 8d 42 ff c3 e8 ea ff ff ff [1320874.636472] RSP: 0018:ffffc90000173c78 EFLAGS: 00010246 [1320874.636477] RAX: ffffea0000000000 RBX: 00001507b9600000 RCX: 0000000000000000 [1320874.636483] RDX: 0000003bbf3a9292 RSI: ffff888107553ae0 RDI: fffff8efcea4a480 [1320874.636488] RBP: ffffea00041d54e8 R08: ffff88815cb0fe58 R09: 0000000000000000 [1320874.636492] R10: ffff88840f6a8288 R11: 0000000000000286 R12: fffff8efcea4a480 [1320874.636497] R13: 0000000000000000 R14: ffff888194e10cc0 R15: 7c00003bbf3a9292 [1320874.636503] FS: 0000000000000000(0000) GS:ffff88840f680000(0000) knlGS:0000000000000000 [1320874.636508] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [1320874.636513] CR2: fffff8efcea4a488 CR3: 000000000200a006 CR4: 00000000001706e0 [1320874.636519] Call Trace: [1320874.636525] pfn_swap_entry_to_page+0x27/0x3c [1320874.636533] __migration_entry_wait+0x48/0x82 [1320874.636540] do_swap_page+0x57/0x539 [1320874.636548] __collapse_huge_page_swapin+0xc2/0x16b [1320874.636557] khugepaged+0xb0a/0x17c8 [1320874.636565] ? collapse_pte_mapped_thp+0x284/0x284 [1320874.636571] kthread+0xde/0xe3 [1320874.636577] ? set_kthread_struct+0x32/0x32 [1320874.636583] ret_from_fork+0x22/0x30 [1320874.636592] Modules linked in: vhost_net tun vhost vhost_iotlb tap kvm_intel kvm md_mod nf_tables xt_connmark xt_comment iptable_raw wireguard curve25519_x86_64 libcurve25519_generic libchacha20poly1305 chacha_x86_64 poly1305_x86_64 ip6_udp_tunnel udp_tunnel libblake2s blake2s_x86_64 libblake2s_generic libchacha xt_mark veth xt_CHECKSUM ipt_REJECT nf_reject_ipv4 xt_nat xt_tcpudp ip6table_mangle ip6table_nat iptable_mangle macvlan xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xt_addrtype iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 br_netfilter xfs dm_crypt dm_mod dax ip6table_filter ip6_tables iptable_filter ip_tables x_tables bonding i915 x86_pkg_temp_thermal intel_powerclamp coretemp iosf_mbi crct10dif_pclmul i2c_algo_bit crc32_pclmul ttm crc32c_intel ghash_clmulni_intel mxm_wmi drm_kms_helper aesni_intel crypto_simd cryptd rapl drm intel_cstate intel_uncore intel_gtt agpgart i2c_i801 ahci tg3 i2c_smbus libahci nvme i2c_core syscopyarea nvme_core [1320874.636690] sysfillrect sysimgblt fb_sys_fops wmi video backlight button [last unloaded: md_mod] [1320874.636735] CR2: fffff8efcea4a488 [1320874.636741] ---[ end trace 8ce14d1014ae0131 ]--- [1320874.636745] RIP: 0010:_compound_head+0x0/0x11 [1320874.636751] Code: 89 e1 48 c7 c6 75 a2 eb 81 48 89 c2 e8 77 5e f6 ff 48 8d bb c8 10 00 00 5b 5d 41 5c 41 5d e9 f8 d3 f5 ff 5b 5d 41 5c 41 5d c3 <48> 8b 57 08 48 89 f8 f6 c2 01 74 04 48 8d 42 ff c3 e8 ea ff ff ff [1320874.636761] RSP: 0018:ffffc90000173c78 EFLAGS: 00010246 [1320874.636766] RAX: ffffea0000000000 RBX: 00001507b9600000 RCX: 0000000000000000 [1320874.636771] RDX: 0000003bbf3a9292 RSI: ffff888107553ae0 RDI: fffff8efcea4a480 [1320874.636775] RBP: ffffea00041d54e8 R08: ffff88815cb0fe58 R09: 0000000000000000 [1320874.636780] R10: ffff88840f6a8288 R11: 0000000000000286 R12: fffff8efcea4a480 [1320874.636785] R13: 0000000000000000 R14: ffff888194e10cc0 R15: 7c00003bbf3a9292 [1320874.636790] FS: 0000000000000000(0000) GS:ffff88840f680000(0000) knlGS:0000000000000000 [1320874.636795] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [1320874.636800] CR2: fffff8efcea4a488 CR3: 000000000200a006 CR4: 00000000001706e0
-
Dear, I have issues with the network connectivity of Docker containers after "they haven't been used" for a while. Short example: having Jellyfin or Nginx or whatever service with a HTTP server works and is reachable/usable perfectly fine while it is "hot", i. e. I'm currently actively using it. After a while of not "using" the container, I fail to reach the container for the first couple of seconds. I couldn't figure out after which amount of time it starts to fail. Small flow chart: First connection to Jellyfin via Firefox/Edge/Chrome fails, the server "just doesn't respond" I press F5, it keeps failing After some seconds and pressing F5 again, it starts responding The same behaviour also happens when a container on Unraid tries to reach another container after a while. Example with Nginx as a reverse proxy: First connection to some Nginx virtual host via Firefox/Edge/Chrome fails, the server "just doesn't respond" I press F5, it keeps failing After some seconds and pressing F5 again, Nginx starts responding but with 500 Service unavailable because... ...it's now starting to write "Upstream unavailable" messages to its log files because it can't reach the upstream docker container waiting for some seconds I press F5 again and it finally can reach the upstream docker container It's really annoying behaviour. This issue is present for all containers I have so I don't think it's an issue exclusive to one specific service. Maybe some important facts (don't know if they help trying to pinpoint that issue): Using br0 custom network with fixed IPs for nearly all containers Having "Host access to custom networks" set to enabled in Docker settings Using IPv4 only Using macvlan Unraid 6.10-rc2 The Unraid WebUI itself works all the time without this issue, even after not using it for a long time I would describe this as: "when trying to connect to the server from a 'cold' state, the first couple of seconds the container is not reachable because it's waking up" (or something like that). The problem is that I'm not really experienced with Docker and networks so I don't really know where I can start looking at. None of the "default" log files containts a message about connections problems or so. Do you have ideas what the issue might be or what I can do to debug it?
-
As the title says. It works when enabling it while the system is running but is broken after a reboot of Unraid. Multiple people are having this problem: For me this is a crucial bug as I need this thing working and I can't trust my server being in a working state after a reboot. Thanks!
-
How is this "solved" if it works when I enable this feature manually after startup? It only doesn't work after a reboot when this option was enabled already because for whatever reason. It's a feature implemented by Limetech for a reason and it works only in half of the cases. How can this be submitted as a bug? Running 9.10rc2
-
@Dyon Hey, it seems this container should be updated to work properly with IPv6 and WireGuard. The following error shows up currently when using a IPv6-enabled VPN configuration: RTNETLINK answers: Permission denied RTNETLINK answers: Permission denied You can see the fix here: https://bodhilinux.boards.net/thread/450/wireguard-rtnetlink-answers-permission-denied Can you fix this in your container?
-
Problem gefunden. Mein VPN-Provider packt per Default einen "Killswitch" in die VPN-Konfiguration von WireGuard. Sobald ich den entferne, geht es. PostUp = iptables -I OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT && ip6tables -I OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT PreDown = iptables -D OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT && ip6tables -D OUTPUT ! -o %i -m mark ! --mark $(wg show %i fwmark) -m addrtype ! --dst-type LOCAL -j REJECT Danke an alle!
-
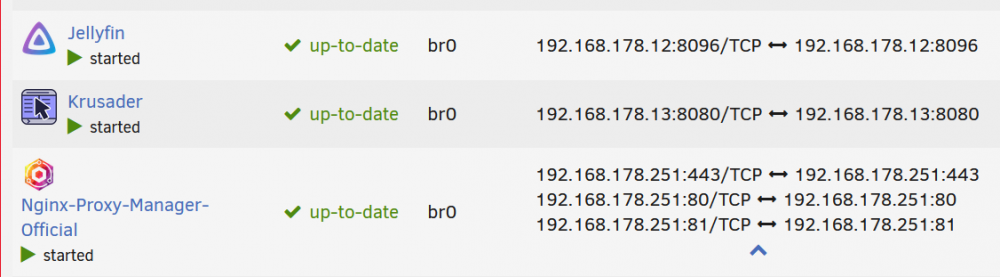
Ist abgearbeitet. Es failed beim erreichen des Containers (habe mal zum Testen die IP 192.168.178.16 an nzbgetvpn statisch vergeben in br0). NPM sowohl nzbgetvpn laufen beide in br0. Spezifischer: dieser Command failed: curl -sSL -D - http://192.168.178.16:6789 -o /dev/null Ich kann auch diese IP nicht aus meinem Browser erreichen. Das geht nur, sobald ich den Container auf bridge ändere. Wenn ich die IP in NPM nutze statt des hostnames, kriege ich auch einen 504er statt 502, was Sinn machen. Vorher (mit Hostname): Nachher (mit statischer IP): Da es mit allen anderen Containern mit NPM im br0 Netzwerk klappt, gehe ich von einem Fail im nzbgetvpn-Container an sich aus.


-
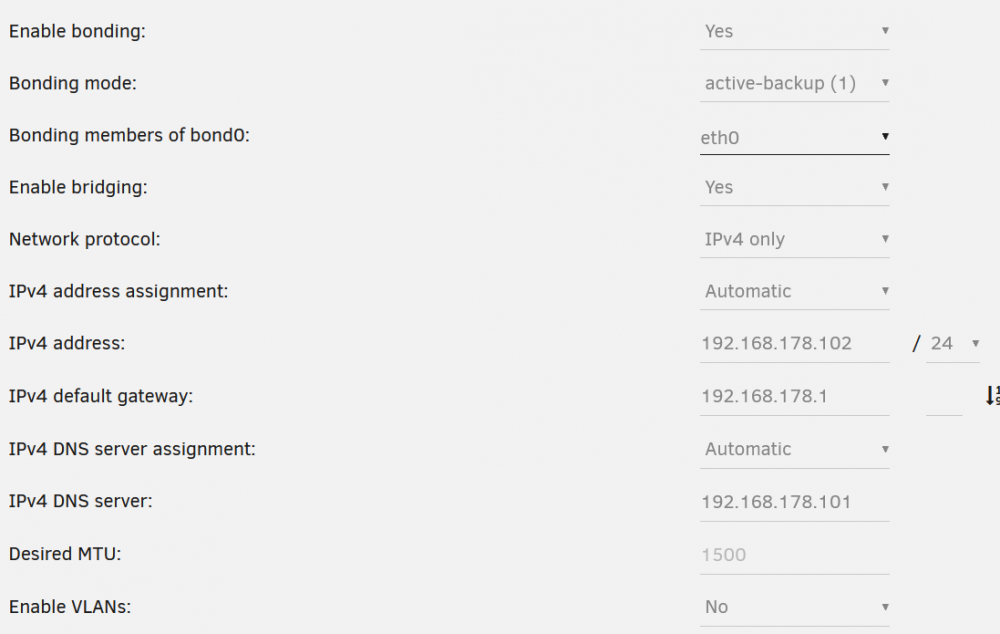
Ich habe versucht, möglichst alles im Standard zu belassen. Mein internes Netzwerk der Fritzbox läuft auf 192.168.178.0/24


-
Hey, das Webinterface von NZBGet läuft auch über HTTP. Nur eben auf einem anderen Port. In all meinen anderen Container funktioniert es. Nur in diesem eben nicht. Und ich vermute, dass es am VPN liegt.
-
Ich kann keinen meiner Container in br0 per IP von außen (außerhalb des Hosts) erreichen. Das Subnetz stimmt aber (192.168.178.0/24). Ich kann nur Container erreichen, die auf bridge eingestellt sind. Ich habe darauf geachtet, dass die zugewiesenen IPs in br0 noch nicht in meinem Netzwerk vergeben sind.
-
Ich nutze Jellyfin als App und möchte das Webinterface gerne hinter einem NGINX Proxy Manager nutzen. Dafür habe ich wie immer bei meinem Apps Jellyfin in das br0-Netzwerk hinzugefügt. Damit klappt auch das Reverse Proxy'ing des Webinterfaces gut. Problem ist, dass DLNA nun immer noch die "falsche" IP-Adresse propagiert: nämlich die aus dem br0-Netzwerk. Ich kann nun jedoch nicht mehr mit meinem Windows Explorer darauf zugreifen, da Jellyfin mit der br0-Adresse nicht zugreifbar ist. Was ist die Lösung, um das Problem zu lösen? Müsste ich irgendwie dem Host "erlauben", dass auf diese spezielle App aus auch vom bridge-Netzwerk von außen zugegriffen werden darf? Oder was wäre der beste Weg? PS: ich habe ein bisschen die Doku bemüht und versucht, die Netzwerksettings richtig einzustellen. Wie gesagt: für's Webinterface klappt das auch...