




coreylane
Members
-
Joined
-
Last visited
Everything posted by coreylane
-
@kesx I don't see VictoriaLogs as a supported source or sink in the documentation https://vector.dev/components/ What does your configuration look like? What errors are you getting, etc? Thanks
-
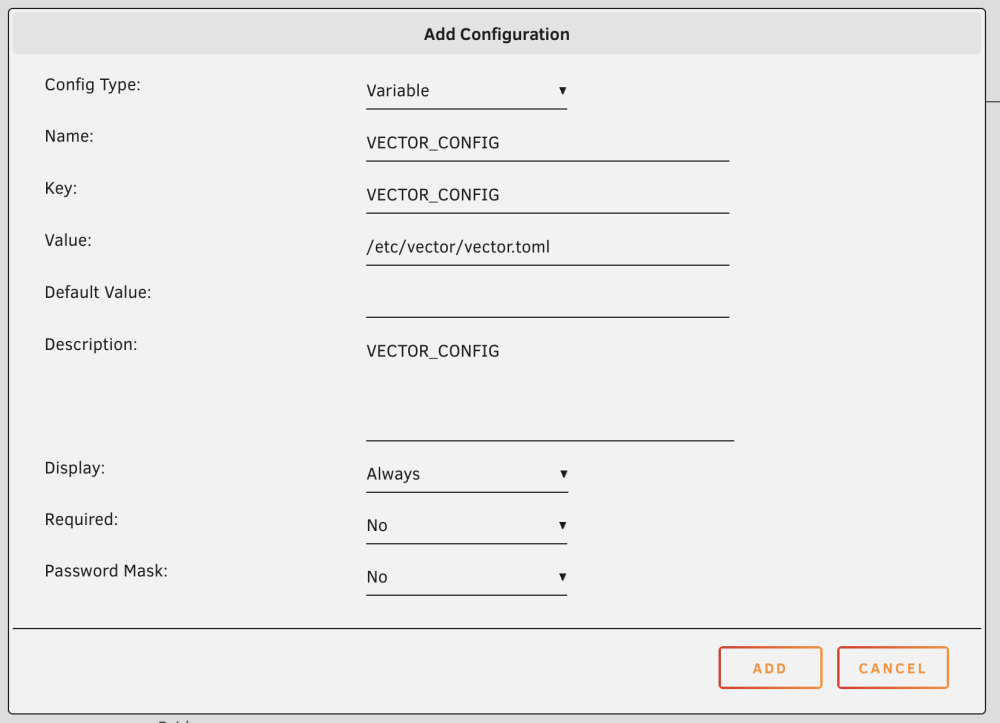
Hi Steve, you can fix this by adding a new environment variable to the docker container configuration in Unraid. Please see screenshots below Type: Variable Key: VECTOR_CONFIG Value: /etc/vector/vector.toml

-
Thank you for reporting this. I'm having the same issue. This behavior was changed in Vector 0.34. I will work on a fix to the unraid template now. https://vector.dev/highlights/2023-11-07-0-34-0-upgrade-guide/#default-config-location-change
-
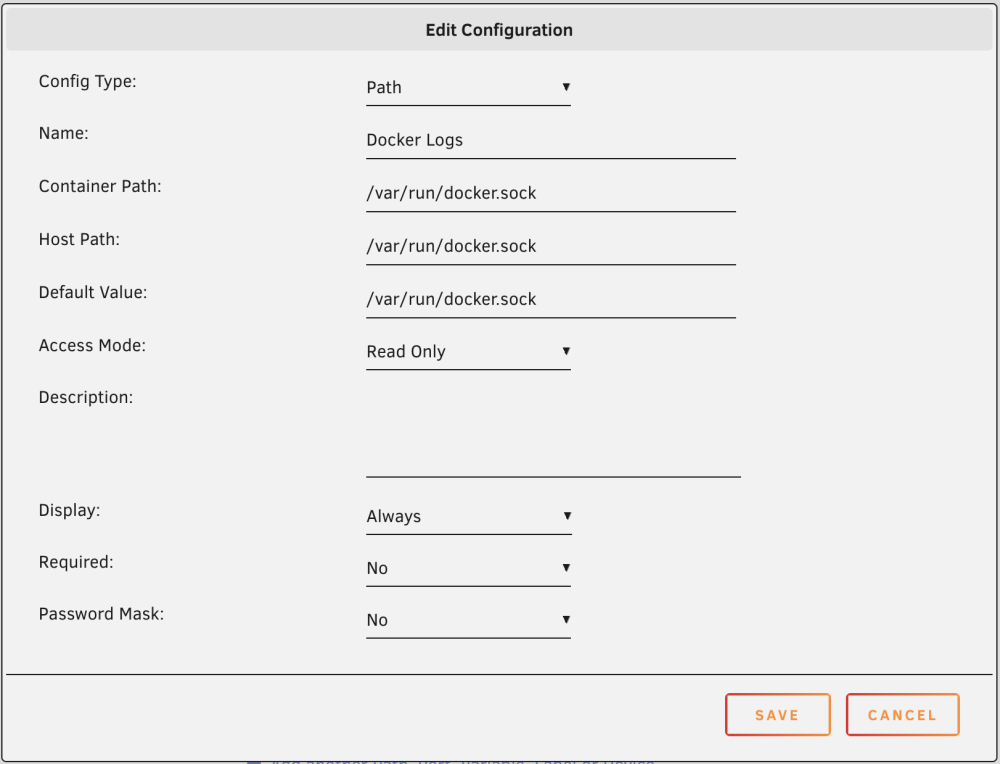
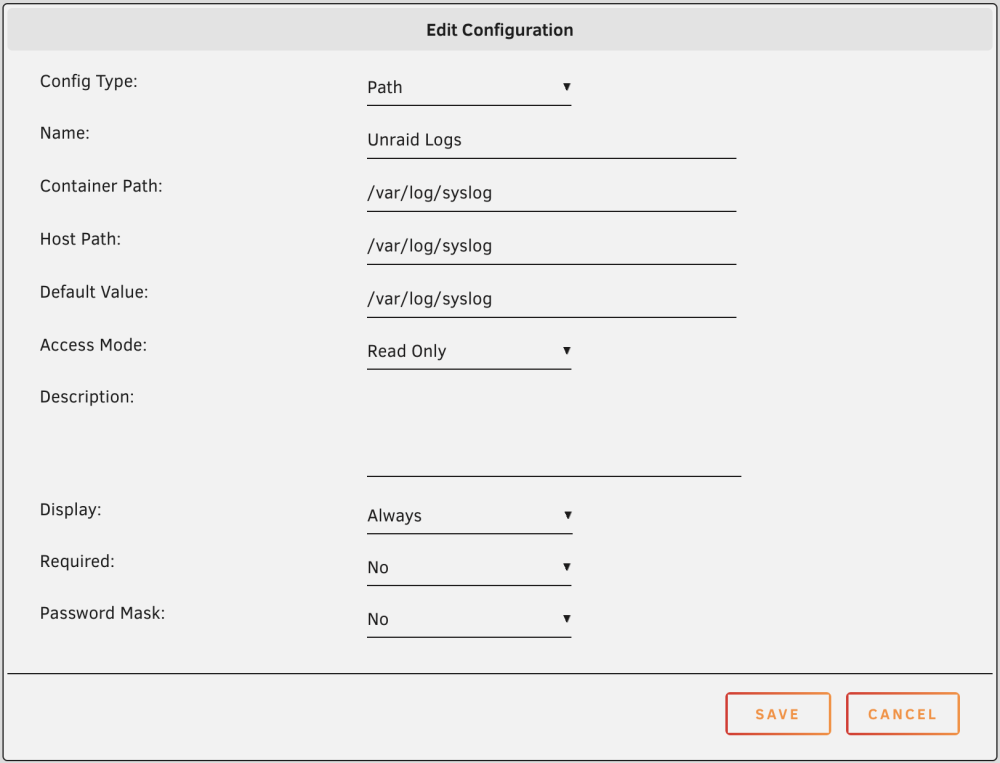
Overview: Support for vector CA available in the coreylane repo. Application: Vector - GitHub Project Docker Hub: https://hub.docker.com/r/timberio/vector/ Template GitHub: https://github.com/coreylane/unraid-ca-templates How do I ingest/collect Unraid logs using Vector? Vector can be used with logs of any kind, but my original intention was to use Vector for ingestion of Unraid logs. Please see the below configuration guides for instructions on ingesting Unraid logs with Vector. Unraid Docker Logs To ingest Unraid's docker logs using Vector, the container needs read-only access to the unix socket Docker listens on. The default in Unraid is /var/run/docker.sock Add the below path configuration to the Vector container: Unraid syslog To ingest Unraid's system logs using Vector, the container needs read-only access to the syslog file. The default in Unraid is /var/log/syslog Add the below path configuration to the Vector container: Vector configuration When the container paths are setup, the final step is to provide a vector.toml configuration defining the desired log sources and destinations (sinks) where the logs should be shipped. Below is a very simple example Vector configuration that ingests docker logs and unraid syslogs and sends them to the cloud based log service Logtail. Example /mnt/user/appdata/vector.toml [sources.docker_logs] type = "docker_logs" [sources.unraid_logs] type = "file" include = ["/var/log/syslog"] [sinks.logtail_http] type = "http" method = "post" uri = "https://in.logtail.com/" encoding.codec = "json" auth.strategy = "bearer" auth.token = "XXXXXXXXXXXXXXXXXXXXXX" inputs = ["docker_logs", "unraid_logs"] New Relic Configuration The below vector.toml snippit will ship your logs to new relic [sinks.new_relic] type = "new_relic" inputs = ["docker_logs", "unraid_logs"] account_id = "123456" api = "logs" license_key = "XXXXXXXXXXXXX"
-
Are your Crucial SSDs still working ok after the firmware update?
-
Great idea about using two different make/model drives for RAID1 cache pool. And you are probably right about me catastrophizing, we need more data points. Crucial release notes are very opaque and do not provide any transparency or details around what the actual "edge case" is so customers have no idea if they are potentially affected. Their firmware update process is also a complete joke, and their support all around seems lacking. 🤷♂️
-
Read the errors in the logs I posted, this isn't simply an annoying SMART attribute discrepancy, the BTRFS filesystem will become completely read-only, the drive will (temporarily) stop being detected in BIOS, and you will potentially lose data. The firmware release notes from Crucial admit this problem exists. They claim it doesn't affect Windows, which is why I specifically mention "Unraid system" in my original post.
-
Posting this here in case anyone else runs into these issues, hopefully it will save some time. TLDR: Avoid using Crucial SSDs in your Unraid system. If you are using them, backup all the data immediately, consider replacing them, or at the very least check your firmware version and update to the latest (M3CR046) ASAP. I had a cache pool using 2x Crucial MX500 1TB SSDs. They worked fine for about a year, but this past week I suddenly started getting all kinds of BTRFS errors and other storage related write errors messages in the syslog. Examples below. The only thing that ended up resolving this and stabilizing my cache pool was updating the SSDs firmware to the latest version available, M3CR046 at the time of this post. This update is not available for direct download through the Crucial support site, you must use crucial storage executive software which only runs on Windows. Also the firmware update only works if you are actively writing to the disk (lol)... so this required mounting BTRFS in Windows using WinBtrfs, and writing to the filesystem while you execute the firmware update in the crucial software. I will never buy Crucial SSDs again, and am looking to replace these with a more reliable brand. Feb 7 01:20:52 darktower kernel: I/O error, dev loop2, sector 887200 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Feb 7 01:21:10 darktower kernel: BTRFS error (device loop2: state EA): bdev /dev/loop2 errs: wr 13, rd 1644, flush 0, corrupt 0, gen 0 Feb 7 01:21:10 darktower kernel: BTRFS warning (device sdc1: state EA): direct IO failed ino 109014 rw 0,0 sector 0x578abf30 len 0 err no 10 Feb 7 01:21:10 darktower kernel: BTRFS warning (device sdc1: state EA): direct IO failed ino 109014 rw 0,0 sector 0x578abf38 len 0 err no 10 Feb 7 04:40:04 darktower root: Fix Common Problems: Error: Unable to write to Docker Image Feb 7 08:39:38 darktower kernel: I/O error, dev sdc, sector 212606944 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Feb 7 08:39:38 darktower kernel: I/O error, dev loop3, sector 78080 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0
-
Have you investigated these messages? shfs: share cache full
-
I created a gh issue regarding the missing libffy dependency https://github.com/UnRAIDES/unRAID-NerdTools/issues/37
-
What is the process to convert btrfs cache array disks to xfs?
-
Gitlab is s a complex and busy app for sure, mine is constantly writing logs as well. How long has your Gitlab instance been running, a week? Check out how much space the log files are using in /mnt/cache/appdata/gitlab-ce/log - Are they being rotated?
-
I ran "xfs_repair -v" on md1 (and all other array disks) but these messages are still appearing in the logs. Is this the right command? "fsck.xfs" command just redirects me to manpage for "xfs_repair" root@darktower:~# grep EXPERIMENTAL /var/log/syslog Dec 14 16:22:28 darktower kernel: XFS (md1): EXPERIMENTAL online shrink feature in use. Use at your own risk! root@darktower:~# grep fail /var/log/syslog Dec 14 16:22:28 darktower root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device Dec 14 16:22:29 darktower root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device Dec 14 16:22:29 darktower root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device Dec 14 16:22:29 darktower root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device
-
I recently got a small 10" display to directly attach to my Unraid server, for use in the rare case something goes wrong and I need to actually log in locally, and want to just keep 'bashtop' running on it as a dashboard. I'm having issues with Unraid OS and HDMI with this new display. The BIOS logo and boot messages perfectly fine, but once the systems boots into Unraid OS, the HDMI signal dies and the display goes to sleep. Where are display settings configured in Unraid? Maybe an unsupported resolution is set wrong in a file somewhere? Any tips or suggestions appreciated. Thanks! Using a VGA cable seems to work, but not ideal for me.
-
Is this normal behavior? Diagnostics attached.... root@darktower:~# grep XFS_IOC_FSGROWFSDATA /var/log/syslog Dec 14 01:11:32 darktower root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device Dec 14 01:11:33 darktower root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device Dec 14 01:11:33 darktower root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device Dec 14 01:11:34 darktower root: xfs_growfs: XFS_IOC_FSGROWFSDATA xfsctl failed: No space left on device darktower-diagnostics-20211214-0142.zip
-
It would be nice if this plugin could add/remove entries to .ssh/authorized_keys
-
Great thread! Successfully flashed a Supermicro AOC-S3008L-L8e with Broadcom/LSI SAS 9300-8i / SAS3008 firmware v. 16.00.10.00 and BIOS v. 08.37.00.00
-
I was using a Cloud Key Gen2 to manage my network devices, it has now totally died and won't even power on after 2.5 years of use. Instead of buying another I'd like to use the unifi-controller container in Unraid. What is the best way to adopt my devices with this new controller, do I really have to factory reset them and lose all my configuration? Thanks!
-
I recently swapped out old Marvell 88SE9215 SATA controllers and replaced with Supermicro AOC-S3008L-L8E SAS3 (based on Broadcom/LSI SAS 9300-8i / SAS 3008). I'm seeing much better IO performance overall with the new controller and everything is working, but I have noticed one change in behavior since swapping. I can't seem to get the write cache setting to persist reboots on disks connected to the new controller. I use the hdparm command to make the change successfully, but after a reboot it just goes back to being disabled. Dec 10 20:16:10 darktower root: Fix Common Problems: Warning: Write Cache is disabled on disk1 Dec 10 20:16:10 darktower root: Fix Common Problems: Warning: Write Cache is disabled on disk2 Dec 10 20:16:10 darktower root: Fix Common Problems: Warning: Write Cache is disabled on disk3 Dec 10 20:16:10 darktower root: Fix Common Problems: Warning: Write Cache is disabled on disk4 Dec 10 20:16:10 darktower root: Fix Common Problems: Warning: Write Cache is disabled on disk5 Dec 10 20:16:10 darktower root: Fix Common Problems: Warning: Write Cache is disabled on cache2 Should I add the hdparm commands as a startup script? Seems a bit hacky... Do I need to upgrade my controller firmware? I haven't bothered since everything has been working fine. root@darktower:~# hdparm -W 1 /dev/sdb /dev/sdb: setting drive write-caching to 1 (on) write-caching = 1 (on) Thanks!
-
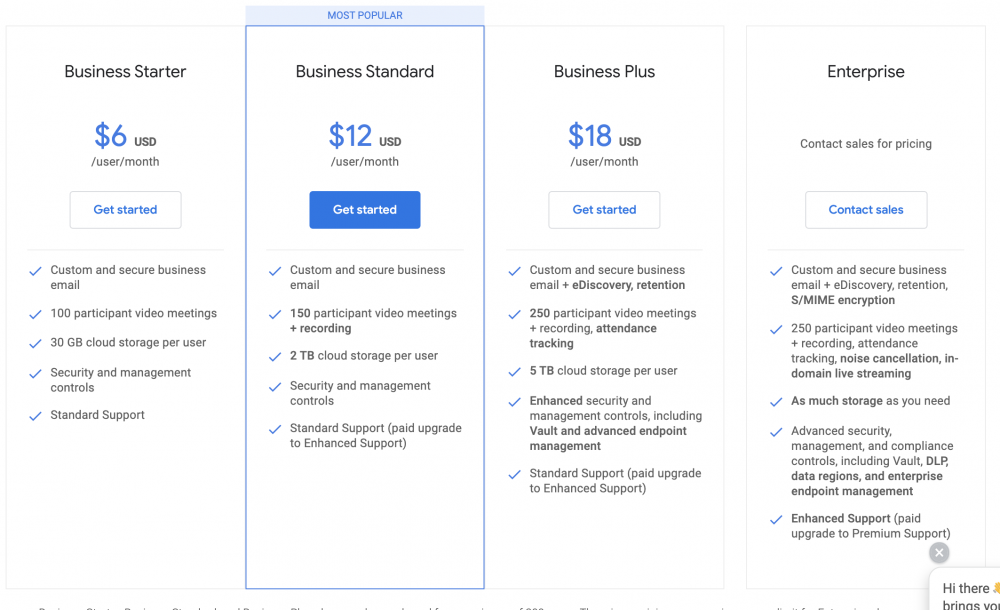
What is the best cloud storage for a 10 TB library? It looks like Google has stopped the unlimited plans, now I'd have to get an "Enterprise" plan for 10TB
-
I'm having the same permissions issue deploying this container with unraid version 6.10.0-rc2 The only solution I've found so far is changing /mnt/user/appdata/clamav to 777 2021-12-02T22:10:35+00:00 ClamAV process starting Updating ClamAV scan DB ERROR: Can't create freshclam.dat in /var/lib/clamav ERROR: Failed to save freshclam.dat! WARNING: Failed to create a new freshclam.dat! ERROR: initialize: libfreshclam init failed. ERROR: Initialization error! Hint: The database directory must be writable for UID 100 or GID 101 An error occurred (freshclam returned with exit code '2') Mappings: /var/lib/clamav <-> /mnt/user/appdata/clamav /scan <-> /mnt/user USER_ID & GROUP_ID are set to 99/100 root@darktower:~# stat /mnt/user/appdata/clamav File: /mnt/user/appdata/clamav Size: 0 Blocks: 0 IO Block: 4096 directory Device: 0,51 Inode: 13792273858936362 Links: 1 Access: (0755/drwxr-xr-x) Uid: ( 99/ nobody) Gid: ( 100/ users) Access: 2021-12-02 16:10:03.832225925 -0600 Modify: 2021-12-02 16:10:03.832225925 -0600 Change: 2021-12-02 16:10:03.832225925 -0600
-
Great plugin, I'd like to suggest a critical performance related config check that could potentially save other users a lot of time and frustration. The script should check to see if docker.img is stored on the array (spinning hdd) instead of the cache (ssd). I suffered several days of painfully slow Docker performance until realizing it was due to docker.img being on a spinning disk, even though I had configured the "system" share to prefer the cache. Mover skipped the file since Docker daemon was running at the time. I had to shutdown docker service and manually invoke mover, now my docker performance is lightning fast as expected! Nov 29 03:27:31 darktower move: skip: /mnt/disk1/system/docker/docker.img Nov 29 03:40:01 darktower move: skip: /mnt/disk1/system/docker/docker.img Thanks!
-
I get a file not found error in the nginx log whenever the stats page is loaded unraid 6.10.0-rc2 / Plugin version 2020.06.21 Nov 28 04:35:59 danktower nginx: 2021/11/28 04:35:59 [error] 10665#10665: *8533 open() "/usr/local/emhttp/plugins/dynamix.system.stats/images/sys.png" failed (2: No such file or directory) while sending to client, client: 192.168.1.69, server: , request: "GET /plugins/dynamix.system.stats/images/sys.png HTTP/1.1", host: "192.168.1.100", referrer: "http://192.168.1.100/Stats"








