




enJOyIT
Members
-
Joined
-
Last visited
Everything posted by enJOyIT
-
I wish there was a statement about a native backup solution. Anyway great!
-
reboot fixed it
-
I will post back after parity rebuilt.
-
Ok, here we are :-)
-
Hi, I am using luks encryption but now I have a weird error: There are 4 disks which have this icon. The data on these disks is still available and even writeable. What does this icon mean? Thank you!

-
Welcome :)
-
Thank you @Rysz ! It's working for me aswell.
-
ah, ok. thank you!
-
runs on the standard 3493 port Maybe the plugin uses the wrong authentification mechanism? The windows NUT tool runs fine and can connect.
-
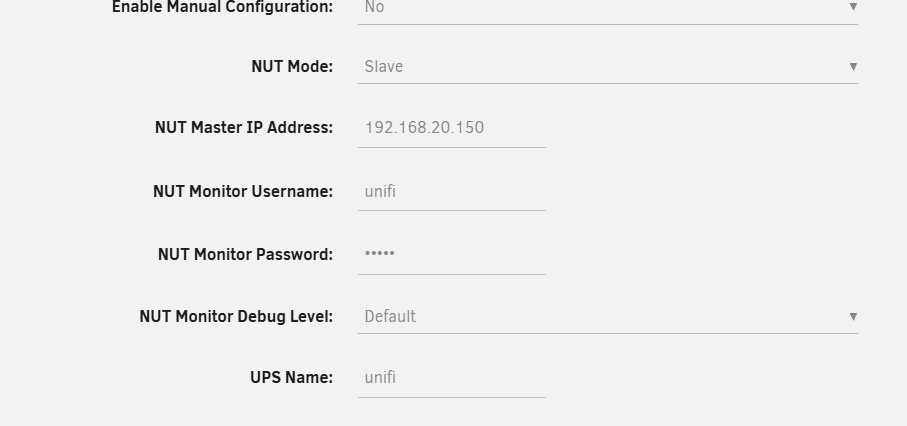
Connecting to my new Unifi UPS doesn't work: Oct 31 12:17:42 unraid upsmon[407139]: Poll UPS [[email protected]] failed - Unknown error Oct 31 12:17:42 unraid upsmon[407139]: Communications with UPS [email protected] lostNUT Server is working, tested it with https://github.com/nutdotnet/WinNUT-Client/releases/tag/v2.2.8719 my settings: Any ideas?
-
I don't know what happend, but when I hit the "Yes" button to update a docker app, nothing happens: The cancel button is working. Searching for new updates is working, hitting the "update all" button at the bottom of the docker apps... doesn't work either. Tried with google chrome and microsoft edge. Any ideas except of restarting the whole machine? Thanks!
-
Habe hier zwei von diesen Sticks... Die scheinen die Fertigung umgestellt zu haben... beide haben keine gültige GUID mehr...
-
I'll setup an unraid server for a friend. Is it possible to buy the starter license with my information and give this license to my friend/ activate it with his email? Can he then renew his license after 12 month or do I have to do this? Thanks!
-
Sind auch keine 36 Euro, sondern eher 16 Euro im Jahr Mehrkosten 🤑
-
Happy Birthday! And hopefully even more 19 years to come!
-
Hi, I tried a completely different container (the original one from plex) with completely fresh install and added a new media folder. Even I tried to delete the codec folder. The browser client plays the file via direct play/stream. I only wanted to check if transcoding is working, so I changed the resolution. Thank you anyway for your advices! 🙂
-
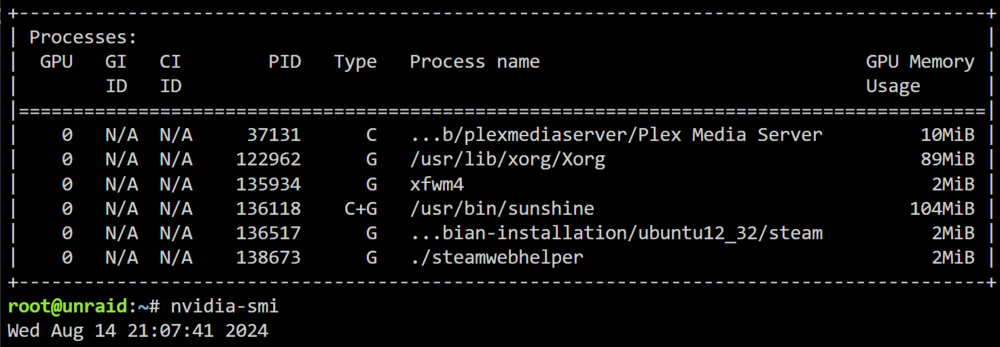
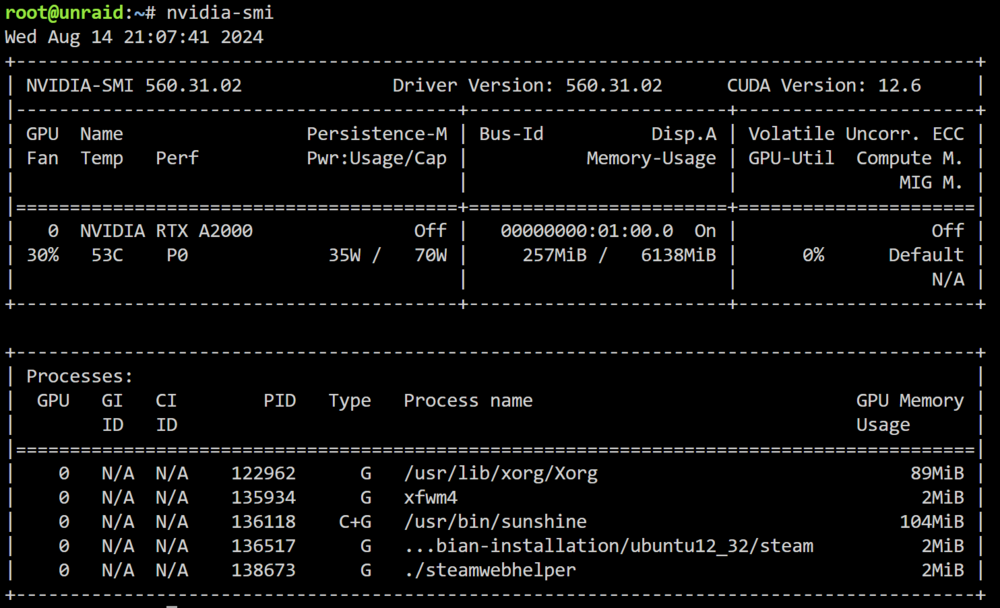
Hi, I have a weird issue which I can't explain and it's driving me crazy. I ran binhex-plexpass for years. Today I made a restart of my unraid machine and now my plex container doesn't do transcoding anymore. It's showing a process for a second in nvidia-smi: but then it disappears and it doesn't transcode via GPU. I tried several plex containers and every single container shows the same behaviour. The video stucks and it doesn't going on anymore. It seems to me, that it plays the little temp file which he transcoded and the file ends it stops. But he doesn't going on to transcode. I tried another path for transcoding... but the same issue. I tried emby which transcodes fine.... So what the heck is going on here?! Edit: Tried now on my android phone... transcoding works. So the transcoding playing in browser doesn't work... Edit2: Tried the browser on my android phone, same issue. This is crazy
-
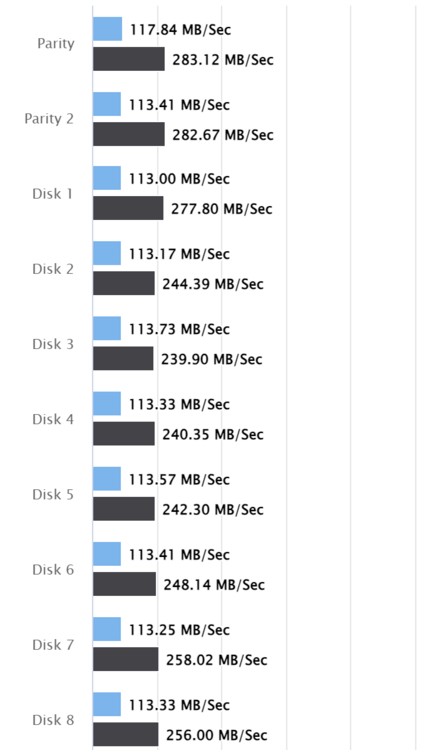
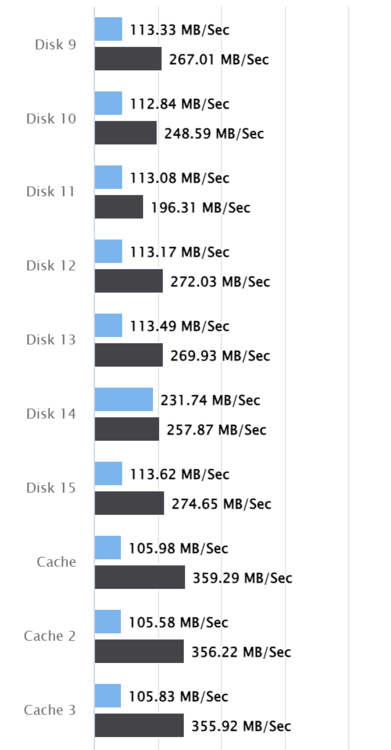
What could be the reason that the single drive speed is at about 115 MB/s but when it runs all drives at the same drive, each drives max out at about 250 MB/s? It doesn't make any sense to me. I alreads reran the test and restarted the docker. There is only one drive which does >200 MB/s at single drive speed. Controller: Fusion-MPT 24GSAS/PCIe SAS40xx/41xx Broadcom / LSI RAID bus controller Type: Add-on Card in PCIe Slot SLOT4 PCIe 5.0 X8 (x8 PCI Express 5 x8) Current & Maximum Link Speed: 16GT/s width x8 (15.75 GB/s max throughput) Port 1: sdaa 14TB Seagate ST14000NM001G Rev SN04 (Disk 6) Port 2: sdab 14TB Seagate ST14000NM002G Rev 0 (Disk 14) Port 3: sdc 1TB NVMe WDS100T3X0C-00SJ Rev 0 (docker) Port 4: sdd 1TB NVMe WD_BLACK SN770 1 Rev 0 (docker2) Port 5: sde 14TB Seagate ST14000NM001G Rev SN04 (Disk 1) Port 6: sdf 10TB Seagate ST10000VN0004 Rev SC61 (Disk 2) Port 7: sdg 10TB Seagate ST10000VN0004 Rev SC61 (Disk 3) Port 8: sdh 10TB Seagate ST10000VN0004 Rev SC61 (Disk 4) Port 9: sdj 10TB Seagate ST10000VN0004 Rev SC61 (Disk 5) Port 10: sdk 12TB Seagate ST12000NM001G Rev SN04 (Disk 13) Port 11: sdl 14TB Western Digital WUH721414ALE6L4 Rev LDGNW07G (Disk 7) Port 12: sdm 14TB Seagate ST14000NM001G Rev SN04 (Disk 8) Port 13: sdn 14TB Western Digital WUH721414ALE6L4 Rev LDGNW240 (Disk 9) Port 14: sdo 12TB Seagate ST12000NM0008 Rev SN04 (Disk 10) Port 15: sdq 12TB Western Digital WD120EFAX Rev 81.00A81 (Disk 11) Port 16: sdr 18TB Seagate ST18000NM000J Rev SN02 Port 17: sds 18TB Seagate ST18000NM000J Rev SN04 Port 18: sdt 18TB Seagate ST18000NM000J Rev SN01 (Disk 12) Port 19: sdu 18TB Seagate ST18000NM000J Rev SN01 (Disk 15) Port 20: sdv 18TB Seagate ST18000NM000J Rev SN02 (Parity) Port 21: sdw 18TB Seagate ST18000NM000J Rev SN02 (Parity 2) Port 22: sdx 1TB Western Digital WDS100T1R0A Rev 411010WR (Cache 3) Port 23: sdy 1TB Western Digital WDS100T1R0A Rev 411000WR (Cache) Port 24: sdz 1TB Western Digital WDS100T1R0A Rev 411000WR (Cache 2) What's wrong here? Running unraid 7.0 beta2 hdparm looks "OK"? root@unraid:/mnt/disk3# hdparm -tT /dev/sdv /dev/sdv: Timing cached reads: 41692 MB in 1.99 seconds = 20945.44 MB/sec Timing buffered disk reads: 580 MB in 3.00 seconds = 193.13 MB/sec root@unraid:/mnt/disk3# hdparm -tT /dev/sdw /dev/sdw: Timing cached reads: 41634 MB in 1.99 seconds = 20917.79 MB/sec Timing buffered disk reads: 562 MB in 3.00 seconds = 187.14 MB/sec root@unraid:/mnt/disk3# hdparm -tT /dev/sdx /dev/sdx: Timing cached reads: 40174 MB in 1.99 seconds = 20182.08 MB/sec Timing buffered disk reads: 604 MB in 3.00 seconds = 201.29 MB/sec root@unraid:/mnt/disk3# hdparm -tT /dev/sdc /dev/sdc: Timing cached reads: 39974 MB in 1.99 seconds = 20080.78 MB/sec Timing buffered disk reads: 3626 MB in 3.00 seconds = 1208.21 MB/sec root@unraid:/mnt/disk3#

-
Regarding this thread: An option to disable CPU pinning would be nice.
-
I played a bit around with VM and GPU passthrough. When I try to switch back to virtuaI get this error: I had choosen AMD Raphael before and when I start the VM the whole host GUI was unresponsive so I had to do a hard reboot, because "reboot" via cmd didn't work as well (stucks at unmounting drives). I think that should never happen... My VM-xml: <?xml version='1.0' encoding='UTF-8'?> <domain type='kvm'> <name>Video</name> <uuid>44a7927b-8d15-b11c-7957-0b95882dfc5c</uuid> <metadata> <vmtemplate xmlns="unraid" name="Windows 11" icon="windows11.png" os="windowstpm" webui="" storage="default"/> </metadata> <memory unit='KiB'>8388608</memory> <currentMemory unit='KiB'>8388608</currentMemory> <memoryBacking> <nosharepages/> </memoryBacking> <vcpu placement='static'>5</vcpu> <cputune> <vcpupin vcpu='0' cpuset='0'/> <vcpupin vcpu='1' cpuset='12'/> <vcpupin vcpu='2' cpuset='28'/> <vcpupin vcpu='3' cpuset='14'/> <vcpupin vcpu='4' cpuset='30'/> </cputune> <os> <type arch='x86_64' machine='pc-i440fx-8.2'>hvm</type> <loader readonly='yes' type='pflash'>/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi-tpm.fd</loader> <nvram>/etc/libvirt/qemu/nvram/44a7927b-8d15-b11c-7957-0b95882dfc5c_VARS-pure-efi-tpm.fd</nvram> </os> <features> <acpi/> <apic/> <hyperv mode='custom'> <relaxed state='on'/> <vapic state='on'/> <spinlocks state='on' retries='8191'/> <vpindex state='on'/> <synic state='on'/> <stimer state='on'/> <vendor_id state='on' value='none'/> </hyperv> </features> <cpu mode='host-passthrough' check='none' migratable='on'> <topology sockets='1' dies='1' clusters='1' cores='5' threads='1'/> <cache mode='passthrough'/> <feature policy='require' name='topoext'/> </cpu> <clock offset='localtime'> <timer name='hpet' present='no'/> <timer name='hypervclock' present='yes'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/vm/domains/win-video/vdisk1.img'/> <target dev='hdc' bus='virtio'/> <serial>vdisk1</serial> <boot order='1'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x18' function='0x0'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/mnt/user/isos/virtio-win-0.1.248-1.iso'/> <target dev='hdb' bus='sata'/> <readonly/> <address type='drive' controller='0' bus='0' target='0' unit='1'/> </disk> <controller type='pci' index='0' model='pci-root'/> <controller type='pci' index='1' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='1'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/> </controller> <controller type='pci' index='2' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </controller> <controller type='pci' index='3' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='3'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/> </controller> <controller type='pci' index='4' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/> </controller> <controller type='pci' index='5' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='5'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/> </controller> <controller type='pci' index='6' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='6'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x08' function='0x0'/> </controller> <controller type='pci' index='7' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='7'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x09' function='0x0'/> </controller> <controller type='pci' index='8' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='8'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x0a' function='0x0'/> </controller> <controller type='pci' index='9' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='9'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x0b' function='0x0'/> </controller> <controller type='pci' index='10' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='10'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x0c' function='0x0'/> </controller> <controller type='pci' index='11' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='11'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x0d' function='0x0'/> </controller> <controller type='pci' index='12' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='12'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x0e' function='0x0'/> </controller> <controller type='pci' index='13' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='13'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x0f' function='0x0'/> </controller> <controller type='pci' index='14' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='14'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x10' function='0x0'/> </controller> <controller type='pci' index='15' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='15'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x11' function='0x0'/> </controller> <controller type='pci' index='16' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='16'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x12' function='0x0'/> </controller> <controller type='pci' index='17' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='17'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x13' function='0x0'/> </controller> <controller type='pci' index='18' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='18'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x14' function='0x0'/> </controller> <controller type='pci' index='19' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='19'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x15' function='0x0'/> </controller> <controller type='pci' index='20' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='20'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x16' function='0x0'/> </controller> <controller type='pci' index='21' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='21'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x17' function='0x0'/> </controller> <controller type='pci' index='22' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='22'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x18' function='0x0'/> </controller> <controller type='pci' index='23' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='23'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x19' function='0x0'/> </controller> <controller type='pci' index='24' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='24'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1a' function='0x0'/> </controller> <controller type='pci' index='25' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='25'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1b' function='0x0'/> </controller> <controller type='pci' index='26' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='26'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1c' function='0x0'/> </controller> <controller type='pci' index='27' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='27'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1d' function='0x0'/> </controller> <controller type='pci' index='28' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='28'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1e' function='0x0'/> </controller> <controller type='pci' index='29' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='29'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1f' function='0x0'/> </controller> <controller type='pci' index='30' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='30'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x01' function='0x0'/> </controller> <controller type='pci' index='31' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='31'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x02' function='0x0'/> </controller> <controller type='pci' index='32' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='32'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x03' function='0x0'/> </controller> <controller type='pci' index='33' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='33'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x04' function='0x0'/> </controller> <controller type='pci' index='34' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='34'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x05' function='0x0'/> </controller> <controller type='pci' index='35' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='35'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x06' function='0x0'/> </controller> <controller type='pci' index='36' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='36'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x07' function='0x0'/> </controller> <controller type='pci' index='37' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='37'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x08' function='0x0'/> </controller> <controller type='pci' index='38' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='38'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x09' function='0x0'/> </controller> <controller type='pci' index='39' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='39'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x0a' function='0x0'/> </controller> <controller type='pci' index='40' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='40'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x0b' function='0x0'/> </controller> <controller type='pci' index='41' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='41'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x0c' function='0x0'/> </controller> <controller type='pci' index='42' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='42'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x0d' function='0x0'/> </controller> <controller type='pci' index='43' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='43'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x0e' function='0x0'/> </controller> <controller type='pci' index='44' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='44'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x0f' function='0x0'/> </controller> <controller type='pci' index='45' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='45'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x10' function='0x0'/> </controller> <controller type='pci' index='46' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='46'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x11' function='0x0'/> </controller> <controller type='pci' index='47' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='47'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x12' function='0x0'/> </controller> <controller type='pci' index='48' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='48'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x13' function='0x0'/> </controller> <controller type='pci' index='49' model='pci-bridge'> <model name='pci-bridge'/> <target chassisNr='49'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x14' function='0x0'/> </controller> <controller type='sata' index='0'> <address type='pci' domain='0x0000' bus='0x01' slot='0x16' function='0x0'/> </controller> <controller type='virtio-serial' index='0'> <address type='pci' domain='0x0000' bus='0x01' slot='0x17' function='0x0'/> </controller> <controller type='usb' index='0' model='ich9-ehci1'> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x7'/> </controller> <controller type='usb' index='0' model='ich9-uhci1'> <master startport='0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0' multifunction='on'/> </controller> <controller type='usb' index='0' model='ich9-uhci2'> <master startport='2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x1'/> </controller> <controller type='usb' index='0' model='ich9-uhci3'> <master startport='4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x2'/> </controller> <interface type='direct' trustGuestRxFilters='yes'> <mac address='ce:7e:9d:f7:87:35'/> <source dev='vhost0' mode='bridge'/> <model type='virtio-net'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x15' function='0x0'/> </interface> <serial type='pty'> <target type='isa-serial' port='0'> <model name='isa-serial'/> </target> </serial> <console type='pty'> <target type='serial' port='0'/> </console> <channel type='unix'> <target type='virtio' name='org.qemu.guest_agent.0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='mouse' bus='ps2'/> <input type='keyboard' bus='ps2'/> <tpm model='tpm-tis'> <backend type='emulator' version='2.0' persistent_state='yes'/> </tpm> <audio id='1' type='none'/> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x01' slot='0x19' function='0x0'/> </hostdev> <memballoon model='none'/> </devices> </domain>
-
Will this be available in the GUI in future releases? Because, like the OP, I don't want to do CPU micromanagement and just want to say this VM 2 CPUs, that VM 4 CPUs, etc...
-
Is there a possibility to change the boot order within the started VM? From proxmox I know I can interrupt this and change to a mapped device like it's done on a bare metal PC. Hitting ESC/F10/F2 etc...
-
Yeah I know UrBackup and other solutions, but I don't want any "bloatware" in my guest machines to do a backup. Nor I want to run a VM which runs a backup solution and I am in trouble when my VM-system is broken or has other problems. My last statement for this topic... A simple built-in backup solution is a must have for an hypervisor. I'm just asking limetech to look at the solution in Proxmox (not the Proxmox Backup Server! I mean the built-in solution of the hypervisor). It is a really simple approach and in my opinion that shouldn't be a big task to do it in a simlar way.
-
Are you backup the .img files with veeam?! And where is veeam running? In an VM? What is when your host has a problem running that VM? How do you restore backups?
-
Sorry for the emotional post. But naming proxmox as "worst server-based applications" was triggering me.









