




TDD
Members
-
Joined
-
Last visited
Everything posted by TDD
-
Linux guy here. Use the Ubuntu ones. If they don't work for unknown reasons, I have an archive of the older tool set. Kev.
-
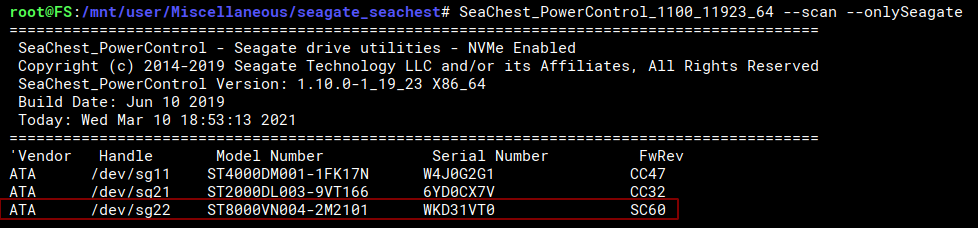
Thank you for the work bringing this together. There is an easy way to just target the disks you want to modify. SeaChest_PowerControl_1100_11923_64 -s --onlySeagate I believe most tools actually allow this -s switch. See screenshot. This allows you to skip the 'map' part and make this easier :-)! Kev.
-
Try the EPC disable/low current disable per my posts. They are reversible if nothing better happens after reboot. I've had no issue since. Kev.
-
You won't notice much of a difference, if any, toasting EPC and spin. Try just the EPC if you are inclined. Drives will still spin down. It's not like your power bill will double. All we are doing here is making the drives way less aggressive with their sleep modes so the controller doesn't freak out. I'd rather this fix than the alternative of drives dropping. I believe it to be an issue in any recent merge into the combined mpt3sas driver and kernel. It was all fine under 4.19. Disable and await any non-firmware fixes later. You can then re-enable the aggressive power saving if you wish. I have had zero issue since this fix across all my controllers that are LSI based. Kev.
-
Well - tested it myself by initiating a manual backup. It does not purge old backups until the running one is complete - as expected and safe. Is it a big ask to have an option where the backups are purged according to the plan prior to the backup? TY. Kev.
-
Wonderful plugin. TY! Question - with any backup about to proceed, are any out of date .tar backups deleted prior to the commencement of the new backup? I ask as my (small!) 1TB drive that holds the current .tar would not hold another in progress and would of course run out of disk space and error out. TY! Kev.
-
Hi All. I also upgraded without incident. Looks superb...thank you to all the team! I do want to pass along a GUI issue. I don't obviously see now what dockers are due for an update in the dashboard? I seem to recall they had an indicator stating as much. A right click on one due for an update does show the option, so this is just a cosmetic fix. TY. Kev.
-
Hi all! I have been busy moving things around in my array as I leave ReiserFS for XFS. No problems. I have noticed that I still have a mix of 4k-aligned and unaligned MBRs. My solo 4TB is 4k; the others (a mix of 2, 1, and 0.75TB drives) are showing a mix of 4k aligned and not. I perhaps erroneously assumed that the reformat to XFS would by default 4k align things but it appears not. Questions are... 1) Any benefit to having them 4k or not? Peformance? I am more than sure my older 2TBs and before are non-AF drives. 2) To make them all 4k, I must emtpy them, preclear them, format again as XFS and it will force 4k? Is there a tool to run that shows conclusively which drives are AF and which are not? Thx! Kev.


