grants169
Members
-
Joined
-
Last visited
Everything posted by grants169
-
I took @JorgeB advice and disabled the NFS service completely and haven't had the problem since (knock on wood). I was unaware that the service had to be disabled and simply not using it wasn't good enough. Settings -> NFS -> Enable NFS -> No. I do find it interesting that the server went for 2 years without the problem happening, but as soon as I re-installed a video card the problem started happening again (with NFS enabled, but not used).
-
I don't use NFS. At all. None of my shares are NFS exported. And as I stated, one of the times it happened I was on the shell using the 'mv' command.
-
I'm screaming into the abyss here probably, but here we go again with this problem. I've gone for about 2 years without this problem and all of the sudden BAM, I'm plagued again. It has happened to me twice in the few days, about 3 days apart from each other. First time, I was on the shell moving files from a disk to cache and within a half second of typing this command: #mv /mnt/disk5/some/files/* /mnt/cache/some/directory --transport endpoint not connected. The second time, I was using lidarr and within lidarr I changed the parent directory of music files: /mnt/user/media/music/artist to /mnt/user/media/other-music-dir/artist (where, "media" is the share name. moved within the share itself) --transport endpoint not connected. ^^^ I don't know if related of not, but I noticed the problem when I was in nemo (linux mint file manager), and nemo was fixed on the directory I moved FROM and it flipped out with a bunch of errors about not being able to reach the server. At first I thought it was simply because I moved that directory within lidarr so of course it couldn't reach it, but then soon noticed it was more severe than that. Both times the server was not doing anything out of the ordinary. The only (major) recent change the server has had is the addition of an nvidia RTX video card. Come to think of it, that's the only time I've had this problem is with a video card installed... HMM, I doubt it's related, but as long as we're throwing darts..... I was problem-free the past 2 years with no video card installed.
-
Thank You. I'm not understanding this setting. Setting to 60% freed space to 78%, I don't understand that math, but the trick for me is to set to 0% to finally move all files older than 10 days.
-
Mover was working fine until last update (3/30) and I don't understand what's making it not work. It's set to move files that are older than 10 days old when capacity used is over 70% of cache. I SUSPECT it's because it says "keep on primary" in the Mover Action log, but I don't know why it is doing that when I haven't changed anything to make that happen, nor do I see a setting that's making that happen. These files are more than 10 days old, cache usage is over 70%, it looks like all the criteria has been met, but files are not being moved to secondary. Any advice would be appreciated. excerpt from Mover tuning log: 18:00:06.803 Moving threshold: 70% (1.3TiB) ; Freeing threshold: 70% (1.3TiB) 18:00:06.804 Mover action: cache->user0 (cache:yes). Pool is above moving threshold percentage: 81% >= 70%. 18:00:06.805 => Will smart move old files from cache to user0. Nothing will be moved from user0 to cache 18:00:06.806 Adding Age 18:00:06.807 Age (modification time) 10 18:00:06.873 Updated Filtered filelist: /tmp/ca.mover.tuning/Filtered_files_2025-04-02T180001.list for media excerpt from Mover Action log: cache|media|yes|1742426843|6731|495037683165|1350342017024|1|12922|keep on primary|/mnt/cache|none|media/media/movies/my_file.mov excerpt from Filtered Files log: cache|user0|media|yes|1742426843|1350342017024|6731|0|1|12922|/mnt/cache/media/media/movies/my_file.mov Summary log: PRIMARYSTORAGENAME|FILES_FROM_PRIMARY|SIZE_FROM_PRIMARY|FILES_FROM_SECONDARY|SIZE_FROM_SECONDARY TOTAL|0|0|0|0|0|0 ca.mover.tuning.cfg: testmode="no" logging="yes" movenow="yes" version="2025.03.30" moverDisabled="no" validateFilenames="yes" debuglogging="no" notify="no" advancedSettings="yes" parity="yes" moverNice="0" moverIO="-c 2 -n 0" force="no" beforeScript="" afterScript="" movingThreshold="70" freeingThreshold="70" age="yes" daysold="10" advancedFilters="yes" ctime="no" atime="no" sizef="no" sparsnessf="no" filelistf="no" filetypesf="no" ignoreHidden="no" omovercfg="yes" enableTurbo="no" cleanFolders="yes" cleanDatasets="no" synchronizeCache="no" advancedOptions="yes" rebalanceShares="no" resynchronizeCache="no" omoverthresh="90" fillupThreshold="0" loggingFolder="/tmp" logfilesDaysold="1" listfilesDaysold="1"
-
List of events that creates network failure/lockout: 1. Bind network card to VFIO at boot for VM 2. Later decide to use the NIC as UNRAID's main network interface after using in VM 3. Unbind the NIC from VFIO, configure UNRAID to use NIC in Network Settings. No problems, yet. This is where problems start: 4. Forget to edit the VM and neglect to uncheck pass thru option on VM template 5. Start the VM Results: 6. UNRAID unassigned network settings in a failed attempt at using network card for the VM and became totally unreachable from network, requiring reboot at console. Someone with greater experience might be able to run some commands at console instead of reboot, but those people probably wouldn't put themselves in this position 🤣 Clearly I'm a bonehead for forgetting to edit VM before starting, but it would be nice if UNRAID either didn't allow the VM to start or be proactive in unchecking pass thru options for something that couldn't be passed thru. Can be replicated by following steps above.
-
I got iGPU enabled, for intel/vaapi. Personally I don't have much need for it, as I write only alarms via camera passthrough; encoding just puts more load on the server. But if someone has a need for it, below may help you enable it. Note when the docker image is updated your changes will be overwritten and you'll have to do this again so you may consider disabling auto updates for Zoneminder if you're going to use this. This assumes you have all the i915 gpu bits in place on your host server (check with lsmod | grep i915 or confirm /dev/dri/renderD128 is there) First, edit Docker->Zoneminder to add a device with value /dev/dri Then open console for Zoneminder and run these commands (this is what worked for me and your mileage may vary): apt install -y vainfo apt install -y intel-media-va-driver-non-free groupadd -g 110 render usermod -a -G video www-data usermod -a -G render www-data check to see if it works with: vainfo Then configure your cameras in Zoneminder under Source: DecoderHWAccelName : vaapi DecoderHWAccelDevice : /dev/dri/renderD128 Then under Storage: Video Writer: Encode and pick your flavor of vaapi encoding.
-
Consider this thread:
-
Looks like it's going to continue to happen until libfuse is fixed, but won't be fixed as the project does not currently have any active, regular contributors.. Limetech has an closed issue at github https://github.com/libfuse/libfuse/issues/589 my "fix" for it was to stop using NFS. That's the only time I had an issue with it outside of a once messed up appdata folder, minus one singular time I encountered it with SMB as others also have reported. Use SMB instead. If you absolutely need to use NFS then access the disk directly instead of via fuse. Enable disk shares and exclusive shares in settings-->global share settings.
-
Was getting sick of seeing a CPU spike to +60% on lsof. I edited /usr/local/emhttp/plugins/dynamix/nchan/update_1 and commented out the following lines # exec("LANG='en_US.UTF8' lsof -Owl /mnt/disk[0-9]* 2>/dev/null|awk '/^shfs/ && \$0!~/\.AppleD(B|ouble)/ && \$5==\"REG\"'|awk -F/ '{print \$4}'",$lsof); # $counts = array_count_values($lsof); $count = []; # foreach ($names as $name) $count[] = $counts[$name] ?? 0; # $count = implode("\0",$count); $count = "0"; Rather than killing the entire script. This way it still works with percentages and fan speeds on the dashboard, but doesn't spike CPU when looking for share streams. 5 minute load average dropped from about 1.3 to 0.9 and 15 minute average from about 1.8 to 1.2, so this definitely makes a difference.
-
I found another thread discussing this bug:
-
Assuming you're on linux, this is what I use in my /etc/fstab for samba, maybe it'll help you out... //[unraid server IP]/media /mnt/media cifs cred=/etc/cred.cifs,uid=[your local username],gid=[your local group],perm,iocharset=utf8 0 0 make a file /etc/cred.cifs, chown it root:root and chmod it 600 and put in it: username=[unraid username] password=[unraid password] and of course create the directory /mnt/media or where ever you want to mount the share. mount it with sudo mount -a -t cifs I know there are a few tweaks you can do to that, but I keep it simple and it works flawlessly for me.....
-
My "solution" was to quit NFS and use SMB solely. Haven't had a problem since. It's pretty scary when it happens because literally all your data just POOF vanishes and I don't like it one bit. I haven't figured out the cause or a real solution.
-
This has happened to me 4 times in the past year, and 2 times it happened last night around 3AM so I wasn't exactly on top of my game, but I did remember to get diagnostics both times. I was watching plex struggle with a music folder of bad .wav files, and determined the rip was bad so I went to delete the folder via NFS and Linux Mint 21 reported "Can not delete folder, not empty." I went to look at the folder and all the contents were deleted, it was empty so I deleted the folder that's when it was reported "input/output error." Then Unraid loses all of it's shares and docker throws a fit. Under the "shares" tab, there are no shares. I tried stopping the array and restarting it, but still no shares. I was required to reboot the server to get everything back, thankfully. After reboot, I started a parity check and decided to try to delete a totally different folder (one that wasn't possibly in use by plex). Same result happened, all shares disappeared and I had to reboot again. Same error, "folder not empty, can't delete." Try to delete the (actually empty) folder and "input/output error" and all shares go down. I had completed a parity check just a few days prior, so I'm pretty certain there are no issues there. Also the parity check I've been running now for the past 8 hours since this happened is reporting no errors. Out of curiosity, is there a command I can run to get shares back instead of rebooting? 1st time: Mar 7 02:27:39 Delmar kernel: ------------[ cut here ]------------ Mar 7 02:27:39 Delmar kernel: nfsd: non-standard errno: -107 Mar 7 02:27:39 Delmar kernel: WARNING: CPU: 0 PID: 7623 at fs/nfsd/nfsproc.c:889 nfserrno+0x45/0x51 [nfsd] Mar 7 02:27:39 Delmar kernel: Modules linked in: ext4 mbcache jbd2 ccp rpcsec_gss_krb5 macvlan xt_nat veth nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo xt_addrtype br_netfilter xt_CHECKSUM xt_MASQUERADE xt_conntrack ipt_REJECT nf_reject_ipv4 xt_tcpudp ip6table_mangle ip6table_nat iptable_mangle iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 vhost_net tun vhost vhost_iotlb tap xfs nfsd auth_rpcgss oid_registry lockd grace sunrpc md_mod ip6table_filter ip6_tables iptable_filter ip_tables x_tables bridge stp llc bonding tls i915 iosf_mbi drm_buddy x86_pkg_temp_thermal intel_powerclamp coretemp i2c_algo_bit mpt3sas gigabyte_wmi raid_class wmi_bmof kvm_intel nvme i2c_i801 intel_wmi_thunderbolt kvm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel aesni_intel crypto_simd cryptd rapl intel_cstate intel_uncore nvme_core i2c_smbus scsi_transport_sas ttm drm_display_helper r8169 realtek drm_kms_helper ahci libahci drm input_leds led_class intel_gtt agpgart i2c_core syscopyarea Mar 7 02:27:39 Delmar kernel: sysfillrect sysimgblt intel_pch_thermal fb_sys_fops fan thermal wmi tpm_crb tpm_tis video tpm_tis_core backlight tpm acpi_pad button unix Mar 7 02:27:39 Delmar kernel: CPU: 0 PID: 7623 Comm: nfsd Not tainted 5.19.17-Unraid #2 Mar 7 02:27:39 Delmar kernel: Hardware name: Gigabyte Technology Co., Ltd. Z390 UD/Z390 UD, BIOS F10 11/05/2021 Mar 7 02:27:39 Delmar kernel: RIP: 0010:nfserrno+0x45/0x51 [nfsd] Mar 7 02:27:39 Delmar kernel: Code: c3 cc cc cc cc 48 ff c0 48 83 f8 26 75 e0 80 3d bb 47 05 00 00 75 15 48 c7 c7 17 54 6a a0 c6 05 ab 47 05 00 01 e8 42 57 1a e1 <0f> 0b b8 00 00 00 05 c3 cc cc cc cc 48 83 ec 18 31 c9 ba ff 07 00 Mar 7 02:27:39 Delmar kernel: RSP: 0018:ffffc90000767d78 EFLAGS: 00010286 Mar 7 02:27:39 Delmar kernel: RAX: 0000000000000000 RBX: ffff8881589d0030 RCX: 0000000000000027 Mar 7 02:27:39 Delmar kernel: RDX: 0000000000000001 RSI: ffffffff820d7be1 RDI: 00000000ffffffff Mar 7 02:27:39 Delmar kernel: RBP: ffff888158308000 R08: 0000000000000000 R09: ffffffff82244bd0 Mar 7 02:27:39 Delmar kernel: R10: 00007fffffffffff R11: ffffffff82882d66 R12: ffff888179c090c0 Mar 7 02:27:39 Delmar kernel: R13: ffff8887bfbd2600 R14: 000000000000000b R15: 0000000000000000 Mar 7 02:27:39 Delmar kernel: FS: 0000000000000000(0000) GS:ffff88907e200000(0000) knlGS:0000000000000000 Mar 7 02:27:39 Delmar kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Mar 7 02:27:39 Delmar kernel: CR2: 0000000000000010 CR3: 000000018ab02004 CR4: 00000000003726f0 Mar 7 02:27:39 Delmar kernel: DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 Mar 7 02:27:39 Delmar kernel: DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 Mar 7 02:27:39 Delmar kernel: Call Trace: Mar 7 02:27:39 Delmar kernel: <TASK> Mar 7 02:27:39 Delmar kernel: fh_verify+0x4e7/0x58d [nfsd] Mar 7 02:27:39 Delmar kernel: nfsd_lookup+0x3f/0xdb [nfsd] Mar 7 02:27:39 Delmar kernel: nfsd4_proc_compound+0x434/0x56c [nfsd] Mar 7 02:27:39 Delmar kernel: nfsd_dispatch+0x1a6/0x262 [nfsd] Mar 7 02:27:39 Delmar kernel: svc_process+0x3ee/0x5d6 [sunrpc] Mar 7 02:27:39 Delmar kernel: ? nfsd_svc+0x2b6/0x2b6 [nfsd] Mar 7 02:27:39 Delmar kernel: ? nfsd_shutdown_threads+0x5b/0x5b [nfsd] Mar 7 02:27:39 Delmar kernel: nfsd+0xd5/0x155 [nfsd] Mar 7 02:27:39 Delmar kernel: kthread+0xe4/0xef Mar 7 02:27:39 Delmar kernel: ? kthread_complete_and_exit+0x1b/0x1b Mar 7 02:27:39 Delmar kernel: ret_from_fork+0x1f/0x30 Mar 7 02:27:39 Delmar kernel: </TASK> Mar 7 02:27:39 Delmar kernel: ---[ end trace 0000000000000000 ]--- Second time: Mar 7 03:07:06 Delmar kernel: ------------[ cut here ]------------ Mar 7 03:07:06 Delmar kernel: nfsd: non-standard errno: -103 Mar 7 03:07:06 Delmar kernel: WARNING: CPU: 0 PID: 7829 at fs/nfsd/nfsproc.c:889 nfserrno+0x45/0x51 [nfsd] Mar 7 03:07:06 Delmar kernel: Modules linked in: macvlan xt_nat veth nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo xt_addrtype br_netfilter xt_CHECKSUM xt_MASQUERADE xt_conntrack ipt_REJECT nf_reject_ipv4 xt_tcpudp ip6table_mangle ip6table_nat iptable_mangle iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 vhost_net tun vhost vhost_iotlb tap xfs nfsd auth_rpcgss oid_registry lockd grace sunrpc md_mod ip6table_filter ip6_tables iptable_filter ip_tables x_tables bridge stp llc bonding tls i915 gigabyte_wmi x86_pkg_temp_thermal intel_powerclamp wmi_bmof intel_wmi_thunderbolt coretemp mpt3sas iosf_mbi drm_buddy kvm_intel i2c_algo_bit ttm drm_display_helper i2c_i801 nvme raid_class kvm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel aesni_intel crypto_simd cryptd rapl intel_cstate intel_uncore nvme_core i2c_smbus scsi_transport_sas drm_kms_helper r8169 realtek ahci libahci drm intel_gtt agpgart input_leds led_class i2c_core intel_pch_thermal syscopyarea sysfillrect sysimgblt Mar 7 03:07:06 Delmar kernel: fb_sys_fops fan thermal wmi tpm_crb video tpm_tis backlight tpm_tis_core tpm acpi_pad button unix Mar 7 03:07:06 Delmar kernel: CPU: 0 PID: 7829 Comm: nfsd Not tainted 5.19.17-Unraid #2 Mar 7 03:07:06 Delmar kernel: Hardware name: Gigabyte Technology Co., Ltd. Z390 UD/Z390 UD, BIOS F10 11/05/2021 Mar 7 03:07:06 Delmar kernel: RIP: 0010:nfserrno+0x45/0x51 [nfsd] Mar 7 03:07:06 Delmar kernel: Code: c3 cc cc cc cc 48 ff c0 48 83 f8 26 75 e0 80 3d bb 47 05 00 00 75 15 48 c7 c7 17 d4 91 a0 c6 05 ab 47 05 00 01 e8 42 d7 f2 e0 <0f> 0b b8 00 00 00 05 c3 cc cc cc cc 48 83 ec 18 31 c9 ba ff 07 00 Mar 7 03:07:06 Delmar kernel: RSP: 0018:ffffc9000073fb58 EFLAGS: 00010282 Mar 7 03:07:06 Delmar kernel: RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000000000000027 Mar 7 03:07:06 Delmar kernel: RDX: 0000000000000001 RSI: ffffffff820d7be1 RDI: 00000000ffffffff Mar 7 03:07:06 Delmar kernel: RBP: ffffc9000073fdb0 R08: 0000000000000000 R09: ffffffff82244bd0 Mar 7 03:07:06 Delmar kernel: R10: 00007fffffffffff R11: ffffffff8287946e R12: 000000000000000c Mar 7 03:07:06 Delmar kernel: R13: 000000000010011a R14: ffff8881049111a0 R15: ffffffff82909480 Mar 7 03:07:06 Delmar kernel: FS: 0000000000000000(0000) GS:ffff88907e200000(0000) knlGS:0000000000000000 Mar 7 03:07:06 Delmar kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Mar 7 03:07:06 Delmar kernel: CR2: 000014b224d7d000 CR3: 00000004df3e8004 CR4: 00000000003726f0 Mar 7 03:07:06 Delmar kernel: DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 Mar 7 03:07:06 Delmar kernel: DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 Mar 7 03:07:06 Delmar kernel: Call Trace: Mar 7 03:07:06 Delmar kernel: <TASK> Mar 7 03:07:06 Delmar kernel: nfsd4_encode_fattr+0x1372/0x13d9 [nfsd] Mar 7 03:07:06 Delmar kernel: ? getboottime64+0x20/0x2e Mar 7 03:07:06 Delmar kernel: ? kvmalloc_node+0x44/0xbc Mar 7 03:07:06 Delmar kernel: ? __kmalloc_node+0x1b4/0x1df Mar 7 03:07:06 Delmar kernel: ? kvmalloc_node+0x44/0xbc Mar 7 03:07:06 Delmar kernel: ? override_creds+0x21/0x34 Mar 7 03:07:06 Delmar kernel: ? nfsd_setuser+0x185/0x1a5 [nfsd] Mar 7 03:07:06 Delmar kernel: ? nfsd_setuser_and_check_port+0x76/0xb4 [nfsd] ### [PREVIOUS LINE REPEATED 1 TIMES] ### Mar 7 03:07:06 Delmar kernel: nfsd4_encode_getattr+0x28/0x2e [nfsd] Mar 7 03:07:06 Delmar kernel: nfsd4_encode_operation+0xad/0x201 [nfsd] Mar 7 03:07:06 Delmar kernel: nfsd4_proc_compound+0x2a7/0x56c [nfsd] Mar 7 03:07:06 Delmar kernel: nfsd_dispatch+0x1a6/0x262 [nfsd] Mar 7 03:07:06 Delmar kernel: svc_process+0x3ee/0x5d6 [sunrpc] Mar 7 03:07:06 Delmar kernel: ? nfsd_svc+0x2b6/0x2b6 [nfsd] Mar 7 03:07:06 Delmar kernel: ? nfsd_shutdown_threads+0x5b/0x5b [nfsd] Mar 7 03:07:06 Delmar kernel: nfsd+0xd5/0x155 [nfsd] Mar 7 03:07:06 Delmar kernel: kthread+0xe4/0xef Mar 7 03:07:06 Delmar kernel: ? kthread_complete_and_exit+0x1b/0x1b Mar 7 03:07:06 Delmar kernel: ret_from_fork+0x1f/0x30 Mar 7 03:07:06 Delmar kernel: </TASK> Mar 7 03:07:06 Delmar kernel: ---[ end trace 0000000000000000 ]--- delmar-diag-second-crash.zip delmar-diag.zip
-
Same problem with my 870s. It was required to write the ISO to a USB stick (using mkusb, rufus, etc) or burn it to a CD and boot directly from it. Worked fine then, updating firmware from SVT01B6Q to SVT02B6Q.
-
Found the culprit. In case anyone else has the "Loading, please wait.." message after attempting to load a large dataset (camera with a lot of events), the fix is to log on to console and increase memory limit from 'memory_limit = 128M' to something like 512M in /etc/php/7.4/apache2/php.ini.

-
Perfect - Thank You!
-
Would it be possible to have a user variable that would load to RAM files OLDER than X days? I have cache drive setup to only move files if they are older than 20 days and if cache is more than 70% full. Doing this on a 1TB cache drive essentially re-creates the idea behind this script except pulling recent video files off nvme instead of RAM, eliminating spin ups for recent files already. Without an "older than" definition, the script is loading all the files off my nvme instead of HDD. Thanks for the consideration.
-
users and admin users for backuppc. I get that we can use variables NGINX_AUTHENTICATION_TYPE=BASIC NGINX_AUTHENTICATION_BASIC_USER1=backuppc NGINX_AUTHENTICATION_BASIC_PASS1=backuppc. What I want to do is use authentication for USERS as is documented in backuppc so they can access their backups (not as admin). It seems the CgiAdminUsers variable is defaulted to backuppc and we can't change that with an htpasswd file, which means we also can't add a standard user with htpasswd. Unless I'm missing something??
-
My setup is a 250 GB disk dedicated to ZM. I save events until the disk is 85% full and it purges the oldest. Been doing this for years, moving it from an old bare metal server to unraid. The disk holds roughly 300,000 events using 7 cameras. Basically overkill as I rarely go back in time the 4 months of events that it holds. But, my problem is I can't go back in time if I'm trying to query about 60,000 events from the console. From the console, clicking on "events" with a camera with 40k events, they pop up just fine. Other cameras with 60k events all I'm presented with is a message "Loading, please wait..." and nothing more happens; it's the same thing with all 3 cameras I have with greater than 60k events. Clicking on the total events, with 300k, it's obviously the same thing. My thinking it's some limitation with mysql, but there's nothing in error logs and I'm not sure what I can do to increase the number of events that can be queried. My old server was able to do it just fine with what was essentially a stock ZM install, using the same 250GB hard disk and I don't recall modifying mysql outside of what ZM requires... Any thoughts?
-
I don't know how I didn't notice this before, but coming from 6.9, I had CPU (HT) 7 isolated as the emulator pin for my VM. Unraid 6.11 doesn't seem to honor isolating a HT, only the core and corresponding HT. This is different behavior in 6.11 vs 6.9. After UNisolating CPU (HT) 7 and rebooting everything seems to work again as per balancing the load among CPUs assigned for unRAID.
-
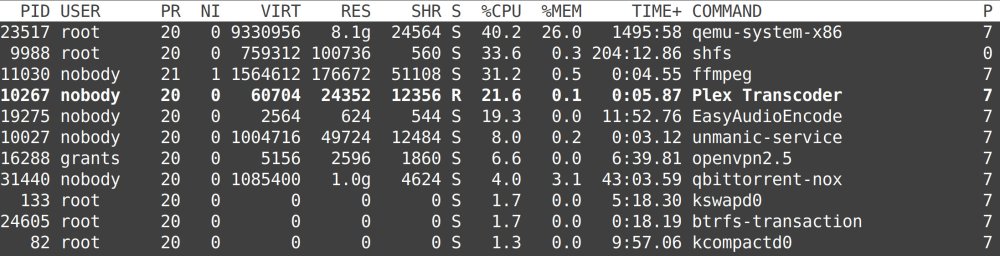
No, it's all the container (and other) processes that overwhelmingly favor CPU 7. In top, press "F" and select option "last used CPU." That lets me see what processes are using CPU 7. See the last column in the attached image..
-
Setup: I have 12 CPUs: 0-6, and 1-7 are used for unraid. CPUs 2-8, 3-9, 4-10, 5-11 are isolated for VM usage, on an intel 8700K When using unraid 6.9, the 4 CPUs for unraid would be balanced and all were used for docker tasks (without CPU pinning). Now with unraid 6.11, I have Plex, Unmanic, Zoneminder, Nextcloud, mariadb, plus more and they ALL use CPU 7. CPUs 0, 6, and 1 sit there and do nothing (other than underlying unraid tasks). I understand I can use CPU pinning, but why? Unraid 6.9 managed putting tasks on lesser used CPUs. But if I have to pin containers to certain CPUs, I can still be bottlenecked depending on which container needs more CPU. So, I'm confused as to why this is happening. Any advice or insight would be appreciated.