




HumanTechDesign
Members
-
Joined
-
Last visited
Everything posted by HumanTechDesign
-
Thank you so much for taking over so quickly, @EDACerton ! Great work, and I really hope that this remains supported. Highly helpful plugin. When using it, I noticed something odd: the initial post from @dlandon states, that the plugin also tracks read activity. I have an (so far unknown) process that only reads (not modifies or writes) to my ZFS pool. I noticed that the plugin does not record that read activity. I then saw that the actual inotifywait doesn't track the access event: https://github.com/dkaser/unraid-fileactivity/blob/cf66db6b95cdf47781bce75da8ae0d811850e71d/src/usr/local/emhttp/plugins/file.activity/scripts/inotify.file.activity#L73 Based on the manual for inotifywait this is probably what I need (https://linux.die.net/man/1/inotifywait): access A watched file or a file within a watched directory was read from. Would it be possible to add the access event to the call? Possibly with a toggle switch so that people who are looking for write activity don't have to go through all of the read activity? Possibly I am also hit by this issue: Thank you so much!
-
Just to spell it out for the next time: the GUI way would have been to leave it with 2 slots, unassign the first (smaller) drive (with a red cross in front as a missing drive), and then start the array (confirming that there is a missing pool device?). This would have automatically detached the smaller device and also reduced the GUI slot numbers, correct? EDIT: Just checked the release notes for 7.1.0-beta3 So I guess, the GUI way is not yet fully ready. Generally, it would be really nice, to perform such an operation (including resilver etc.) via choosing the new (larger) drive in the existing single drive slot for the pool. Unraid could then perform the temporary mirror creation, resilvering and detach of the smaller drive internally (with a progress notification). This way, Unraid would always know that it should treat this pool as a single drive vdev.
-
As I needed my server to run today, I actually continued using the CLI way: 1. Add the larger device as a mirror for the existing pool via a new slot in the GUI 2. Start array 3. Finish resilver 4. Stop the array 5. Import the pool via CLI zpool import <poolname> 6. Remove the smaller mirror device via zpool detach <poolname> <drivename> 7. Remove the pool via the pool details (clicking on the blue poolname on the left) 8. Add a new pool with the same name, 1 slot and FS set to auto (showing a blue icon) 9. Start the array This worked without problems. However, I would still be interested in the GUI way. I could also not find any documentation on how this should be accomplished correctly via GUI.
-
Sorry for taking over this thread, but I am exactly in the same position for the exchange: I have resilvered, and I would now like to remove the smaller mirrored device. However, I don't know how I should accomplish the following via the GUI: I am on 7.0.1. (so long after the beta), but the GUI does not let me change the slot numbers, so how should I remove the smaller one? I probably could solve it via the CLI path, but I specifically want to understand what the GUI way would have been. Or was the possibility for GUI removal removed after the beta? EDIT: Maybe this is actually the correct way to do this? So, is it correct that the pool shows two red crosses?


-
Yes, this is clear. My assumption in this case was that by blacklisting the driver, the video output is not correctly redirected to the Remove KVM. I will try an upgrade to 7.0.1 today and we will see what happens.
-
Thanks for the report! I upgraded to 7.0.0 last week or so, and it actually did change the behavior in the Remote KVM (the picture was not frozen to the blue bootloader), but it still didn't show the full boot process (it remained black with a new aspect ratio). Also, I had to still use the dummy plug so that the iGPU showed up in Unraid. I might have made some BIOS changes in the meantime. So maybe, I misconfigured something there. Nevertheless, I also have the feeling that the issue seems to be improving with the new kernel. Could you please list all the configuration settings that are relevant in this regard: Final Jumper setting? BIOS setting? Use of a dummy plug? Use of the SR-IOV plugin? You can fully utilize the iGPU in docker containers for transcoding (did you verify this?) AND have full Remote KVM capabilities? At an off-chance, that this is related: Did you blacklist the `cdc_ether` driver as suggested here (also specifically for this board): I did so before upgrading, and I am wondering if that is related to my issues. Thanks and regards!
-
Thanks. As I said, I also experienced this issue before, I was just wondering if this might also be related to this high CPU usage and in particular a specific CPU model (which apparently is not the case, as you are on 11th Gen). I was also suspecting this for a while now, but finding this current issue regarding the high CPU usage also seemed to correlate in my case. I just wanted to investigate in this direction. But yeah, I also assume a RAM issue. What I find surprising in my case though: I already limited multiple high RAM users (ZFS, dockers VMs), so my installed 64GB in the dashboard usually report ~80-85% usage. I also already did the `touch /boot/config/fastusr` fix suggested in the changelog. So I probably have to limit (especially ZFS) even more, but we will see. Thanks!
-
I can report that I experience this as well. For me, this seems to be somewhat related to running TubeArchivist container - but it is definitely not the only culprit. This might be a coincidence, but what CPU is everyone running here? I am also on the 12600K like @Boy Kai - but on a different MB brand. I am on 7.0.0 but I experienced the same issue with 6.12.x Your logs are also probably filled with Feb 24 23:52:00 Tower php-fpm[15343]: [WARNING] [pool www] child 1375992 exited on signal 9 (SIGKILL) after 20.070926 seconds from start
-
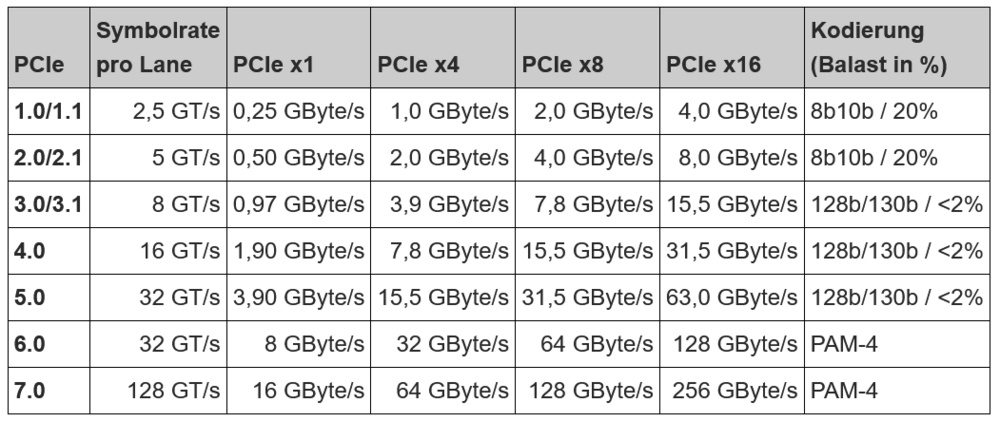
Hallo in die Runde - danke für die Einblicke! Da ich auch am Überlegen bin, diesen Rechner zu kaufen, hätte ich folgende Verständnisfrage (die vielleicht @SebastianSchmidt oder @motorsense sogar aktiv testen könnten): Bei den Bildern sieht man ja einen x4 Riser. Laut Recherchen im Internet sollte die DUAL(!) X520 auf PCIe 2.0 laufen. Quasi alle PCIe Extension-Karten, die man hierzu kaufen kann sind mit x8 angebunden. Wenn man jetzt mit der Tabelle unten 2.0 x4 umrechnet, kommt man doch (nach meiner Rechnung) nur auf 2,0 GByte x 8 = 16 Gbit (statt 20, wie ich sie bei einer Dual-NIC-Karte bräuchte). Übersehe ich etwas oder könnte ich (gerade bei einem Router-Betrieb) die beiden 10G NICs nicht gleichzeitig voll auslasten? Klar, Router bringt immer Overhead, aber irgendwie scheint da doch im Design was komisch zu sein. Wenn möglich, wäre ich über einen Testlauf mit gleichzeitig beiden NICs dankbar!
-
You mean the current stable 6.12.10? Yes, this is still affected. I would assume that everyone in this thread waits for the next RC or stable with a major kernel bump and see if that changes something.
-
Thanks for the suggestion. I have been using the plugin for quite a long time now (already under 6.11.x) and I specifically requested the lazy load option as a feature because of this exact USB HDD. After you implemented it, I never had problems again up until this current version. I am not sure if the added "type" detection is the culprit. I will see if I can manually downgrade again and see if the problem appeared due to other changes to Unraid (which I am not aware of at the moment). What I don't understand: when this long loading time happens, the ZFS Master area on the Main tab just stays blank (not even showing the "Last refresh at XXX" notification at the top. I can't even trigger a rescan via the button as usual (nothing happens). Once the ZFS master list is populated (and the snapshots are loaded via lazy load), the system returns to normal. I have a feeling that this only happens once after a fresh install or reboot. Is there any kind of caching involved (apart from the time in the refresh delay)?
-
Hi there, since the latest upgrade I have the following issue: I have a zpool (backuppool) on an external USB HDD. Since the update, the refresh of the dataset list on the main tab does not work anymore. Also (and this is the bigger issue), there is a constant read load of around ~400K/s for the USB HDD. Based on iotop, this seems to be based on the following command - originating from the plugin: 15728 be/4 root 393.29 K/s 0.00 B/s ?unavailable? zfs program -jn -m 20971520 backuppool /usr/local/emhttp/plugins/zfs.master/scripts/zfs_pool_get_datasets_snapshots.lua backuppool I checked your commit history on github and this seems to have been modified based on the new zvol functionality. Is anyone else seeing this issue? EDIT: I reinstalled the plugin and now the dataset list is back. However, the snapshot lazy load takes extremely long now (a few minutes instead of a few seconds before the update). Is there something that can be done?
-
Updated to 6.12.10 from last night and the problem remains. However, I would have also been surprised because 6.12.10 specifically rolled back the kernel to 6.1.79 (which is lower than the kernel from 6.12.9 but still higher than the kernels after Unraid 6.12.4). I will wait for the next major kernel jump (AFAIK should happen with the upcoming next major Unraid release). If that does not change the situation, I will specifically file bug report. Hopefully, Limetech can figure it out.
-
If this is related to the mATX version of the board, we are discussing this problem in this thread:
-
Danke für den Hinweis! Sorry für den missverständlichen Ablauf. Hätte einen Edit zu dem Post davor machen sollen: Der war der Übeltäter. ADSB-Tracking ist jetzt wieder umgezogen auf einen Raspberry Pi. Bei C6 ist es am Ende nicht geblieben, weil ich dann wie gesagt die M.2 Slots wieder belegt habe. Meine Beobachtungen sehen daher jetzt ungefähr so aus: Mit fr24feed-piaware docker (und anderen containern): nur C2 und im Spindown auf minimum 33W Ohne fr24feed-piaware docker (und anderen containern) und dem PCH M.2 Slot belegt: C6 und im Spindown minimum 22W Ohne fr24feed-piaware docker (und anderen containern) und mit beiden M.2 Slots belegt: C3 und im Spindown minimum 25W Der Hauptgewinn in der real world Umsetzung ist der konsequente Umzug von "heißen" Daten (Nextcloud etc.) vom großen Pool auf den Toshibas und Exos auf die M.2. Ich habe mich früher immer vom Spindown ferngehalten, weil ich 1. bei früheren Synologys die Erfahrung hatte, dass die wegen jedem Mini-Datenpaket im Netzwerk aufgewacht (oder gar nicht schlafen gegangen) sind und 2. ich immer noch nicht ganz sicher bin, ob häufiges Aufwecken jetzt nicht doch schlecht für die drives ist. Ich war quasi schon immer mit meiner Unraid Box auf ZFS, sodass ich niemals das Erlebnis von "nur eine Platte läuft an" hatte, sondern wenn schon immer gleich der ganze zpool lief. Nach dem Umzug auf die M.2s schläft der große pool jetzt auch tagsüber 80% der Zeit. Ich werde mal schauen, ob ich in Zukunft noch einmal Arbeit reinstecke und noch weiter nach Potenzial suche, aber zum aktuellen Zeitpunkt bin ich eigentlich okay damit, würde ich sagen. Warum ich selbst unter den besten Bedingungen nicht über C6 hinauskomme (selbst wenn bis heute nichts in den PCIe-Slots steckt und alle angeschlossenen Geräte grundsätzlich ASPM, DIPM etc. mitbringen), kann ich nicht genau sagen, aber für mich wäre das erstmal okay, wie es jetzt ist. Ich danke euch aber für eure Hilfestellungen und den guten Austausch! Und ein riesen Lob und Danke an @mgutt - ohne Dich und Deine Hilfestellungen hätte ich vorher nicht mal gewusst, wo ich anfangen müsste zu suchen!
-
What are the other devices in your build? ASPM support etc.? I am on the same board (long time no see) and without an M.2 in the CPU slot (top right) I can reach C6, when there is an M.2 installed in the top right slot (CPU), I can reach C3. I have documented some of my findings in the German forum (maybe Google translate can help):
-
Muss mich hier nochmal kurz dranhängen - läuft bei euch das WoL plugin unter 6.12.8? Ich habe WoL vorher nicht benutzt und wollte es jetzt einsetzen. Kann das Plugin auch problemlos installieren, allerdings funktioniert es nicht: der Libvirt wake on lan service in den VM settings steht dauerhaft auf stopped (auch nach Neuinstallation des Plugins, ein-/ausschalten etc.). Im Syslog ist der Wechsel auch zu sehen mit Mar 17 19:51:39 Tower ool www[9805]: /usr/local/emhttp/plugins/libvirtwol/scripts/wol_stop Mar 17 19:51:44 Tower ool www[7324]: /usr/local/emhttp/plugins/libvirtwol/scripts/wol_start Der Libvirt Virtual BMC direkt drunter in den Settings steht dauerhaft auf Running. Für mich sieht es aktuell auch so aus, dass das Plugin ja nicht mehr wirklich gepflegt wird, aber so wie das hier klingt, sollte es ja weiterhin funktionieren? Dachte, vielleicht liegt es an der Unraid Version.
-
Interesting. Maybe it has something to do with the fact that on the ATX version of the board, the IPMI is handled via the external card instead of a BMC that is directly soldered to the board. Nevertheless, your setup contradicts my assumption in the first post. It would be interesting to hear about other boards with soldered BMCs (such as Supermicro etc.).
-
But based on that comment, it seems like your iGPU is not used at all in this configuration. Do you see the iGPU in the system devices in that constellation? I believe the problem arises if only the BMC VGA device and the iGPU is available. Then (based on the above commit) the iGPU (or the BMC) gets blocked out. I would imagine that the dGPU is not even part of this chain and therefore gets treated differently. Therefore it would be interesting if you still have the BMC (KVM via Web) AND the iGPU available if you take out your dGPU (with Unraid after 6.12.4). Sorry if I sound so unconvinced. I am just really trying to understand if that Linux Kernel or Unraid or the BIOS/board is the issue.
-
Meaning the dummy plug or the dGPU? It's interesting to hear this report. Do you still have everything available (on 6.12.8) when the dGPU is removed?
-
Thank you for your report. If I remember correctly, you had to dummy plug the dGPU to get everything working correctly together - right? Did/could you try without the dGPU put into the server? I could imagine that a dGPU changes the behavior in this instance.
-
Wäre auch zu einfach gewesen: hab mir spontan zwei Verbatim Vi3000 geholt. Stecken jetzt in den beiden M.2 Slots. Leider kam es, wie ich befürchtet habe: nur noch C3 und wieder hoch auf ~64W bei angelaufenen Platten (Spin-Down noch nicht getestet). An sich scheinen die eigentlich alles zu unterstützen, was man sich wünschen könnte (ASPM L1, ASPT etc.). Soweit ich weiß ist allerdings der eine M.2-Slot direkt an die CPU angebunden und könnte da deshalb einen niedrigeren State verhindern. Muss mal schauen, ob ich das noch mit anderen SSDs in der Belegung testen kann. Frage in die Runde: wie habe ich den folgenden Output zu den L1 Substates zu deuten? root@tower:~# lspci -vv | grep 'L1SubCap' L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ root@tower:~# lspci -vv | grep 'L1SubCtl1' L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- Wenn ich das richtig verstehe, würden prinzipiell ALLE PCI links und devices L1.1 und L1.2 sprechen, aber keiner tut es - stimmt das? L1 scheinen sie nämlich (weiterhin) alle zu sprechen/aktiviert zu haben: 00:06.0 PCI bridge: Intel Corporation 12th Gen Core Processor PCI Express x4 Controller #0 (rev 02) (prog-if 00 [Normal decode]) LnkCap: Port #5, Speed 16GT/s, Width x4, ASPM L1, Exit Latency L1 <16us LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 00:1a.0 PCI bridge: Intel Corporation Alder Lake-S PCH PCI Express Root Port #25 (rev 11) (prog-if 00 [Normal decode]) LnkCap: Port #25, Speed 16GT/s, Width x4, ASPM L0s L1, Exit Latency L0s <1us, L1 <4us LnkCtl: ASPM L0s L1 Enabled; RCB 64 bytes, Disabled- CommClk- 00:1b.0 PCI bridge: Intel Corporation Device 7ac0 (rev 11) (prog-if 00 [Normal decode]) LnkCap: Port #17, Speed 8GT/s, Width x1, ASPM L0s L1, Exit Latency L0s <1us, L1 <4us LnkCtl: ASPM L0s L1 Enabled; RCB 64 bytes, Disabled- CommClk- 00:1b.4 PCI bridge: Intel Corporation Alder Lake-S PCH PCI Express Root Port #???? (rev 11) (prog-if 00 [Normal decode]) LnkCap: Port #21, Speed 16GT/s, Width x4, ASPM L1, Exit Latency L1 <64us LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 00:1c.0 PCI bridge: Intel Corporation Alder Lake-S PCH PCI Express Root Port #1 (rev 11) (prog-if 00 [Normal decode]) LnkCap: Port #1, Speed 8GT/s, Width x1, ASPM L1, Exit Latency L1 <64us LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 00:1c.3 PCI bridge: Intel Corporation Device 7abb (rev 11) (prog-if 00 [Normal decode]) LnkCap: Port #4, Speed 8GT/s, Width x1, ASPM L1, Exit Latency L1 <64us LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 00:1d.0 PCI bridge: Intel Corporation Alder Lake-S PCH PCI Express Root Port #9 (rev 11) (prog-if 00 [Normal decode]) LnkCap: Port #9, Speed 8GT/s, Width x4, ASPM L0s L1, Exit Latency L0s <1us, L1 <4us LnkCtl: ASPM L0s L1 Enabled; RCB 64 bytes, Disabled- CommClk- 01:00.0 Non-Volatile memory controller: MAXIO Technology (Hangzhou) Ltd. NVMe SSD Controller MAP1202 (DRAM-less) (rev 01) (prog-if 02 [NVM Express]) LnkCap: Port #0, Speed 8GT/s, Width x4, ASPM L1, Exit Latency L1 <64us LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 04:00.0 Non-Volatile memory controller: MAXIO Technology (Hangzhou) Ltd. NVMe SSD Controller MAP1202 (DRAM-less) (rev 01) (prog-if 02 [NVM Express]) LnkCap: Port #0, Speed 8GT/s, Width x4, ASPM L1, Exit Latency L1 <64us LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 05:00.0 Ethernet controller: Intel Corporation Ethernet Controller I226-LM (rev 06) LnkCap: Port #0, Speed 5GT/s, Width x1, ASPM L1, Exit Latency L1 <4us LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 06:00.0 PCI bridge: ASPEED Technology, Inc. AST1150 PCI-to-PCI Bridge (rev 06) (prog-if 00 [Normal decode]) LnkCap: Port #0, Speed 5GT/s, Width x1, ASPM L0s L1, Exit Latency L0s <512ns, L1 <32us LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+
-
I might have tracked down the issue in the Linux kernel. I am trying to gather more input on this issue in this thread: This should also be relevant to @mrhanderson.
-
After some discussion in the ASUS W680 board specific thread, I want to find out if other boards have the same problem with the current Unraid version (or rather specific Linux kernel). What is the matter? If you have a IPMI/BMC that uses the ast driver in Unraid (the problem turned up with the ASPEED AST2600, but this could be universal to other BMCs as well) and want to use the iGPU from the CPU (e.g. for a VM or docker), you run into the following situation: - If no device (or dummy plug) is inserted, you can verify the complete boot process of Unraid via the hardware VGA or via the KVM screen in your IPMI GUI but lose the iGPU in Unraid (e.g., when you want to use the Intel SR-IOV plugin). For me, it even crashes the boot process - If a device (or dummy plug) is inserted, you still keep it in Unraid, but the VGA/KVM stops updating after the blue boot loader screen of Unraid. This seems to be an issue that has popped up (at least with the board from the thread) only AFTER Unraid 6.12.4 (so 6.12.5 and beyond). I have found this kernel commit which seems to be describing exactly this behavior and could correlate with the kernel updates in the relevant Unraid releases. To find out if this is a general issue or specific to this board, I would now like to find people with the following constellation: - Updated Unraid to a release >6.12.4 - Use of an ASPEED BMC (or other BMC using the ast driver) - Use of BMC VGA/KVM (with full output until the CLI login) AND a detected iGPU in Unraid (with or without dummy plug) For reference: My setup is a ASUS Pro WS W680M-ACE SE with a 12600K. Multi-Monitor (and iGPU) is activated in the BIOS - BIOS settings don't seem to matter. I am currently on Unraid 6.12.8 (Linux Kernel 6.1.74) and can use SR-IOV with a dummy plug but KVM drops out after the bootloader. Other users with the exact same board report that they have KVM + iGPU/SR-IOV. However, they are still on 6.12.4 (Linux Kernel 6.1.49). If you want to find out, if your BMC in Unraid is adressed with ast, you can run lspci -v Then look for your BMC. The last lines should tell you the required part. For me, the (relevant) output looks like this: 06:00.0 VGA compatible controller: ASPEED Technology, Inc. ASPEED Graphics Family (rev 52) (prog-if 00 [VGA controller]) Subsystem: ASPEED Technology, Inc. ASPEED Graphics Family Flags: medium devsel, IRQ 19, IOMMU group 18 Memory at 84000000 (32-bit, non-prefetchable) [size=64M] Memory at 88000000 (32-bit, non-prefetchable) [size=256K] I/O ports at 4000 [size=128] Capabilities: [40] Power Management version 3 Capabilities: [50] MSI: Enable- Count=1/4 Maskable- 64bit+ Kernel driver in use: ast Kernel modules: ast
-
I did some digging in the kernel commits (never done that before and I also don't have experience with the internals of Linux), but I found this: https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/?id=8d6ef26501b97243ee6c16b8187c5b38cb69b77d If I read this correctly our issue actually is a feature instead of a bug (if this actually IS the cause). As far as I can tell it correlates with the kernel timeline in the Unraid releases. I have seen that there has been further development on the module/driver afterward but it would be interesting to see if this has been fixed or if it will stay that way from now on. This would suck because it takes away a lot of functionality. I can see this comment which gives me at least some hope https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/drivers/gpu/drm/ast/ast_mode.c?id=8d6ef26501b97243ee6c16b8187c5b38cb69b77d#n1784 * FIXME: Remove this logic once user-space compositors can handle more * than one connector per CRTC. The BMC should always be connected. If I have the time, I will also boot up a live distro with a later kernel. However, as far as I can tell ALL boards with a BMC that is adressed with the ast driver (probably all ASPEED BMCs?) should run into this problem - not only this board. This should pop up in the whole server world? I have started a dedicated thread for that topic here:






