aglyons
Members
-
Joined
-
Last visited
Everything posted by aglyons
-
I was running some Docker updates and got a docker.img usage warning. I started to look and see if I had something set to store logs in the wrong spot and noticed the path for error logs. /tmp/Nginx-Proxy-Manager-Official/var/log I can't find out where that path is on the server. It's not in any share, it's not on the thumb drive and it's not in the cache. Where are these log files being stored and is there any management that needs to be done to keep them in check?
-
Went down a long rabbit hole and came to this conclusion (at the end of the thread). It appears that the GUI on my system is reporting that all drives are currently running a SMART test. I have confirmed via CLI that no tests are actually running. I've updated my hardware profile and that was submitted 02-12-23. Yes, I am running a PERC310 in HBA mode. I've confirmed the PERC310 does support SMART status and testing. SMART tests do work properly and report back correctly. It's just the GUI reporting weirdness. Attached is the log package. knoxx-diagnostics-20230212-1818.zip
-
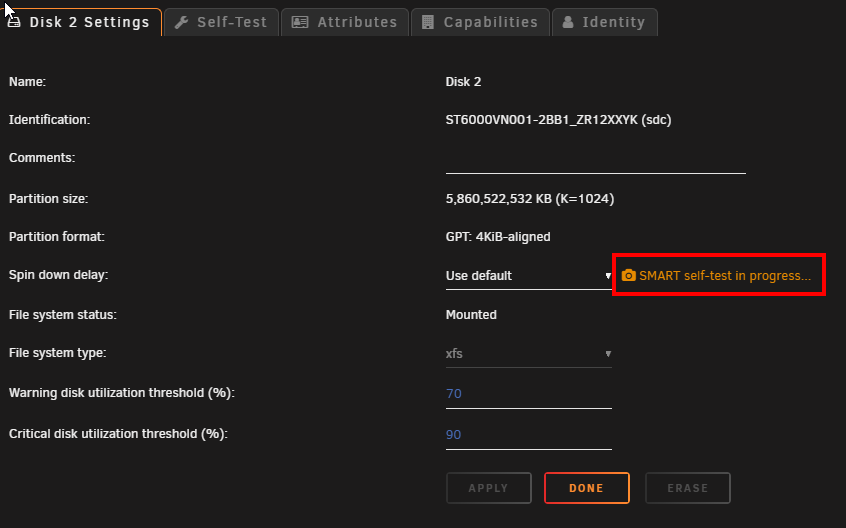
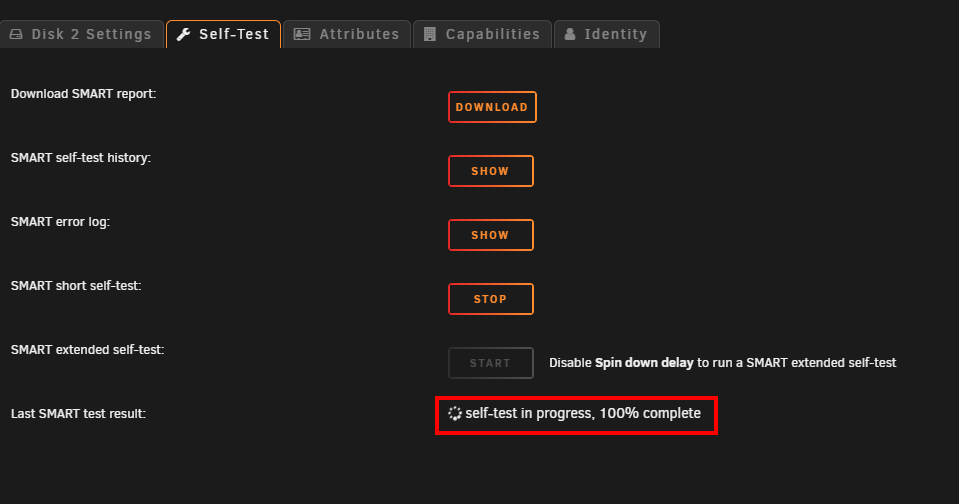
OK, so this long rabbit hole brought me to this conclusion. There was nothing wrong with SMART testing to begin with. There is however, I think a bug in the Unraid UI. Switching the default SMART controller type back to auto, results in manually triggering tests to run, report the progress % and complete successfully without error. BUT, The UI for each drives disk settings will report there is a test running, and, the self-test page will also show "self-test in progress, 100% complete". THis is shown even though there are no self-tests actually running. I've confirmed with smartctl that no tests are currently running on /dev/sdc yet the GUI is showing a test in progress. root@KNOXX:~# smartctl -a /dev/sdc smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.19.17-Unraid] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Seagate IronWolf Device Model: ST6000VN001-2BB186 Serial Number: ZR12XXYK LU WWN Device Id: 5 000c50 0e39de1db Firmware Version: SC60 User Capacity: 6,001,175,126,016 bytes [6.00 TB] Sector Sizes: 512 bytes logical, 4096 bytes physical Rotation Rate: 5425 rpm Form Factor: 3.5 inches Device is: In smartctl database 7.3/5417 ATA Version is: ACS-3 T13/2161-D revision 5 SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s) Local Time is: Sun Feb 12 16:41:53 2023 EST SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART Status not supported: Incomplete response, ATA output registers missing SMART overall-health self-assessment test result: PASSED Warning: This result is based on an Attribute check. General SMART Values: Offline data collection status: (0x00) Offline data collection activity was never started. Auto Offline Data Collection: Disabled. Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: ( 0) seconds. Offline data collection capabilities: (0x73) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. No Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: ( 1) minutes. Extended self-test routine recommended polling time: ( 729) minutes. Conveyance self-test routine recommended polling time: ( 2) minutes. SCT capabilities: (0x70bd) SCT Status supported. SCT Error Recovery Control supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 081 064 006 Pre-fail Always - 134257168 3 Spin_Up_Time 0x0003 093 091 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 124 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 081 060 045 Pre-fail Always - 125890195 9 Power_On_Hours 0x0032 092 092 000 Old_age Always - 7136 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 55 183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 067 047 040 Old_age Always - 33 (Min/Max 31/36) 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 284 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 855 194 Temperature_Celsius 0x0022 033 053 000 Old_age Always - 33 (0 21 0 0 0) 195 Hardware_ECC_Recovered 0x001a 081 064 000 Old_age Always - 134257168 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 6333h+41m+47.380s 241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 54866540544 242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 264620654405 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed without error 00% 7136 - # 2 Short offline Completed without error 00% 7136 - # 3 Short offline Completed without error 00% 7135 - # 4 Short offline Completed without error 00% 5617 - SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay. The particular line to refer to for a currently running test is; Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run. If the test WAS currently running that would have a value showing the current progress like this. Self-test execution status: ( 249) Self-test routine in progress... 90% of test remaining.
-
So interesting how others have said this is sporadic and they can't figure out what is going on. Once I've *kind of* figured out my SMART scanning issue, that message went away. I am wondering if smartctl is doing a long scan of drives (which can take upwards of 12 hours) is the cause of the services message?
-
I think this IS actually resolved. Manually triggering a shot self-test does return a message in red saying "Errors occurred - Check SMART report" but checking the SMART report shows no problem. And, if you refresh the screen the message changes to green and says "Completed". The interesting thing is this error message only pops up for 3.5inch spinning drives that are part of the Unraid array. I don't see the same error message on SSD drives that are part of the cache pool.
-
And I spoke too soon. Triggering a manual short test produced an error message; [GLTSD (Global Logging Target Save Disable) set. Enable Save with '-S on'] There's a bunch of hits online about this actually being a bug in the smartctl app. There was this one post on (https://bugzilla.redhat.com/show_bug.cgi?id=1907729) at the very end mentioning blacklisting the individual USB disk -it was a post about external drives and smart failing. The search continues
-
OK, fixed it. Dell PERC310 running in HBA mode. You have to set the SMART controller type to SCSI mode. Once I did that I could see the "Last Smart test results:" spinning and return "Completed" I checked the report download and was presented SMART stats. smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.19.17-Unraid] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org User Capacity: 6,001,175,126,016 bytes [6.00 TB] Logical block size: 512 bytes Physical block size: 4096 bytes Lowest aligned LBA: 8 Rotation Rate: 5425 rpm Form Factor: 3.5 inches Logical Unit id: 0x5000c500e39dc12a Serial number: ZR12XYE5 Device type: disk Transport protocol: SAS (SPL-4) Local Time is: Sun Feb 12 15:40:56 2023 EST SMART support is: Available - device has SMART capability. SMART support is: Enabled Temperature Warning: Disabled or Not Supported Read Cache is: Enabled Writeback Cache is: Enabled === START OF READ SMART DATA SECTION === SMART Health Status: OK Current Drive Temperature: 27 C Drive Trip Temperature: 0 C Error Counter logging not supported [GLTSD (Global Logging Target Save Disable) set. Enable Save with '-S on'] SMART Self-test log Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ] Description number (hours) # 1 Background short Completed - 70 - [- - -] Long (extended) Self-test duration: 43980 seconds [12.2 hours] Device does not support Background scan results logging
-
Querying smartctl from the CLI shows me that it seems to identify the SCSI devices AND it also is identifying the megaraid separately. root@KNOXX:~# smartctl --scan /dev/sdb -d scsi # /dev/sdb, SCSI device /dev/sdc -d scsi # /dev/sdc, SCSI device /dev/sdd -d scsi # /dev/sdd, SCSI device /dev/sde -d scsi # /dev/sde, SCSI device /dev/sdf -d scsi # /dev/sdf, SCSI device /dev/sdg -d scsi # /dev/sdg, SCSI device /dev/sdh -d scsi # /dev/sdh, SCSI device /dev/sdi -d scsi # /dev/sdi, SCSI device /dev/sdj -d scsi # /dev/sdj, SCSI device /dev/sdk -d scsi # /dev/sdk, SCSI device /dev/sdl -d scsi # /dev/sdl, SCSI device /dev/sdm -d scsi # /dev/sdm, SCSI device /dev/bus/1 -d megaraid,0 # /dev/bus/1 [megaraid_disk_00], SCSI device /dev/bus/1 -d megaraid,1 # /dev/bus/1 [megaraid_disk_01], SCSI device /dev/bus/1 -d megaraid,2 # /dev/bus/1 [megaraid_disk_02], SCSI device /dev/bus/1 -d megaraid,3 # /dev/bus/1 [megaraid_disk_03], SCSI device /dev/bus/1 -d megaraid,4 # /dev/bus/1 [megaraid_disk_04], SCSI device /dev/bus/1 -d megaraid,5 # /dev/bus/1 [megaraid_disk_05], SCSI device /dev/bus/1 -d megaraid,6 # /dev/bus/1 [megaraid_disk_06], SCSI device /dev/bus/1 -d megaraid,7 # /dev/bus/1 [megaraid_disk_07], SCSI device /dev/bus/1 -d megaraid,10 # /dev/bus/1 [megaraid_disk_10], SCSI device /dev/bus/1 -d megaraid,11 # /dev/bus/1 [megaraid_disk_11], SCSI device /dev/bus/1 -d megaraid,12 # /dev/bus/1 [megaraid_disk_12], SCSI device /dev/bus/1 -d megaraid,13 # /dev/bus/1 [megaraid_disk_13], SCSI device Querying one of the SCSI devices SDC directly shows that it sees the drive, identifies it just fine and can see that the device is SMART compatible and enabled. root@KNOXX:~# smartctl -i /dev/sdc smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.19.17-Unraid] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Seagate IronWolf Device Model: ST6000VN001-2BB186 Serial Number: ZR12XXYK LU WWN Device Id: 5 000c50 0e39de1db Firmware Version: SC60 User Capacity: 6,001,175,126,016 bytes [6.00 TB] Sector Sizes: 512 bytes logical, 4096 bytes physical Rotation Rate: 5425 rpm Form Factor: 3.5 inches Device is: In smartctl database 7.3/5417 ATA Version is: ACS-3 T13/2161-D revision 5 SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s) Local Time is: Sun Feb 12 15:35:54 2023 EST SMART support is: Available - device has SMART capability. SMART support is: Enabled
-
https://www.reddit.com/r/Tailscale/comments/qmfcaw/smb_issues_via_tailscale/
-
So the next question is, why is Unraid using the Megaraid driver for the controller that is running in HBA mode? @limetech If you have a moment can you help me clear this up?
-
"IT mode stands for "initiator target". It presents each drive individually to the host." https://dannyda.com/2021/09/22/what-are-it-mode-hba-mode-raid-mode-in-sas-controllers/
-
So can you help me understand the difference between HBA (which is non-raid passthrough) and IT mode (which is non-raid passthrough)? Sorry, I'm getting frustrated as my system is running with data on it. If I have to do something dramatic to correct the situation, It's not going to be a fun time.
-
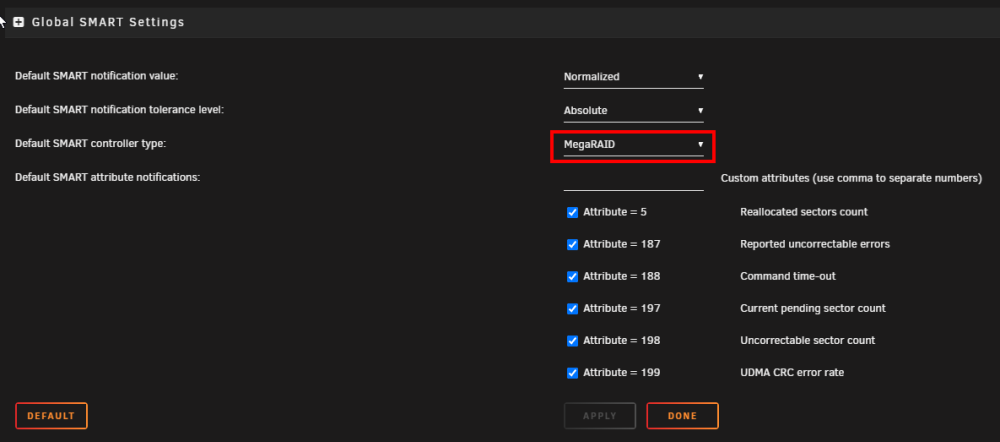
I changed the default Smart Controller Type in disk settings to Megaraid since that is the driver that is being used according to the hardware report. The continuous SMART test seems to have gone away, but, I have now noticed that each individual drives SMART config has some extra fields. It appears as though the Device Name is populated automatically and correctly. But Disk Index does not have a value. I've searched online and through the docs and can't find anything that refers to the Disk Index and where/how I would get that.

-
Poking around I found the hardware profile tool which I had never run before. According the output, from what I can understand, the card has already been flashed to the LSI firmware. <node id="raid" claimed="true" class="storage" handle="PCI:0000:05:00.0" modalias="pci:v00001000d00000073sv00001028sd00001F78bc01sc04i00"> <description>RAID bus controller</description> <product>MegaRAID SAS 2008 [Falcon]</product> <vendor>Broadcom / LSI</vendor> <physid>0</physid> <subproduct>Dell</subproduct> <subvendor>Dell</subvendor> <businfo>pci@0000:05:00.0</businfo> <logicalname>scsi1</logicalname> <version>03</version> <width units="bits">64</width> <clock units="Hz">33000000</clock> <configuration> <setting id="driver" value="megaraid_sas" /> <setting id="latency" value="0" /> </configuration>
-
This wasn't happening when I first got the server set up. This is new. I also have the "Starting Services..." notice at the bottom of the UI which was mentioned in another thread. I'm wondering if they are related somehow. I have a Dell PERC 310 running in HBA mode and from what I understand about Dell's HBA and LSI's IT mode, are the same thing. I've done some more research and according the Dell specs, the Perc310 does support S.M.A.R.T. management, at least it does in RAID mode according to the spec sheet - https://i.dell.com/sites/doccontent/shared-content/data-sheets/Documents/dell-perc-h310-spec-sheet.pdf. I'm looking for clarification in HBA mode but if it's supported in RAID I think it's safe to say it would be.
-
I just noticed this myself, also, I posted another thread about Smart testing running 24/7 and showing 100% all the time. Survives reboots and is affecting all drives including cache and parity. I wonder if this is any way related? Logs are posted there too.
-
I've just noticed that the SMART self test seems to be running constantly and it's stuck at 100% on all drives. I've rebooted the server and still the self test starts up again, and again, at 100%, for all drives in the array including cache and parity drives. knoxx-diagnostics-20230211-1550.zip
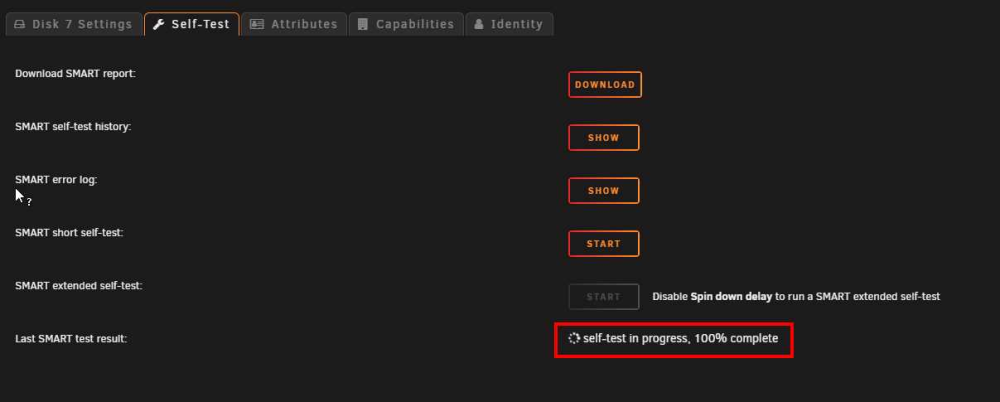
-
Hey guys, Recently was adding some Docker containers and found the Docker Allocations display to be hard to find the info that I needed. I would love it if we could either sort that table ourselves, or, if the table was grouped by network and then sorted by IP and/or, Ports assigned. Currently it's sorted alphabetically by container name so assigned IP's and ports are all over the place. It's hard to find what you need. Before After
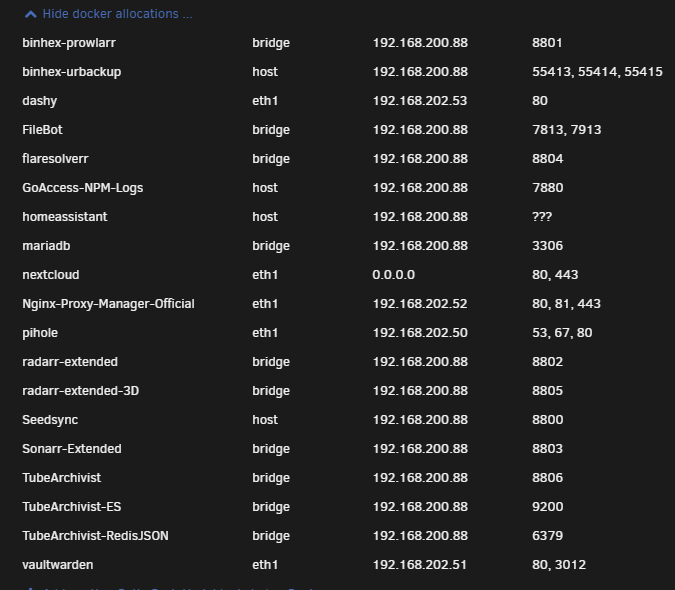
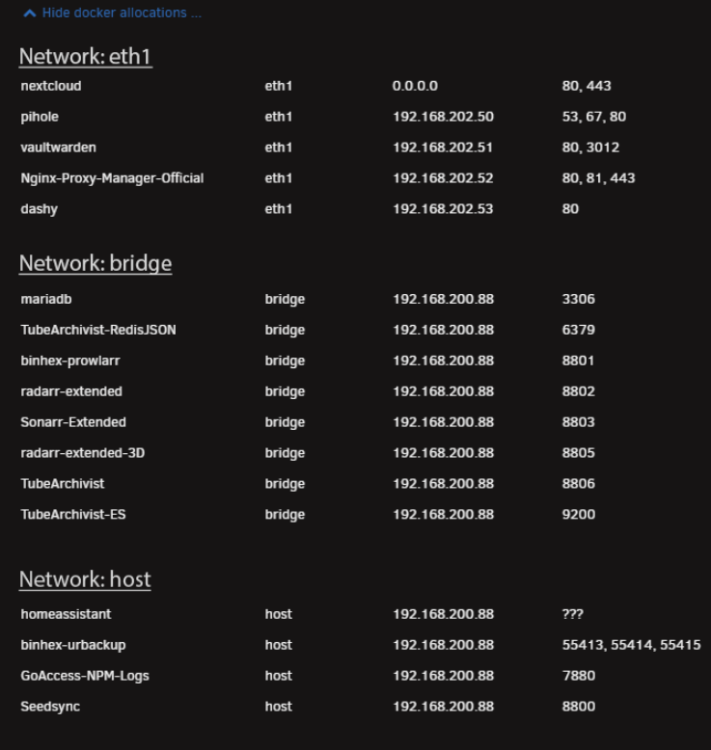
-
Hey all, just getting started. Managed to get everything working but I had a thought and noticed something that made me go hmmmmm. First, I see a few people talking about already having ES and REDIS already installed on their system, and because of that are having a hard time getting TA to talk to it. While I didn't have either installed prior, I had some challenges trying to figure out what needed to go where and what needed to be set to what. I was curious, would it not be a good idea to create a docker image that includes the three components (TA, ES & REDIS) already installed in the one app? I get it that would be duplicating services in a way. But a dedicated ES and REDIS for TA might simplify setup and cut down on people running into problems. Just a thought. The hmmmm I was referring to is if you select the "more info" link on the Unraid container for TubeArchivist-RedisJSON. It brings you to the DockerHub page (https://hub.docker.com/r/redislabs/rejson/). That page states that "This docker image has been deprecated, please download the redis-stack docker." Does this pose any concerns going forward?
-
HOLY CRAP! Thanks so much for this! I doubt I would have had the time to figure out this entire config script. This should be included as an example in the official docs as I think this covers what pretty much everyone would want. 1080p is pretty much as high as I think anyone would want to go being that you're storing it locally. 4k videos can chew up space pretty quick.
-
Hey all, pulling my hair out, and I don't have any left lol! I've read the docs forward and backward and can't figure out the correct formatting. Wondering if anyone can share a download format that would limit to 1080 and embed the thumbnail and subtitles. Given a codec choice I'd say 264 and container, mkv. If this is at all possible that is. I've tried this bestvideo[height<=1080] --remux-video mkv but I still get errors [2023-02-08 17:18:53,258: INFO/MainProcess] Task home.tasks.download_single[c4dbe92f-6c7a-4ba1-b2d5-3609fc5c1187] received [2023-02-08 17:18:53,260: WARNING/ForkPoolWorker-16] Added to queue with priority: {'youtube_id': 'nMmvuNHHxnM', 'vid_type': 'videos'} [2023-02-08 17:18:53,312: WARNING/ForkPoolWorker-16] Downloading type: VideoTypeEnum.VIDEOS [2023-02-08 17:18:54,061: WARNING/ForkPoolWorker-16] ERROR: [youtube] nMmvuNHHxnM: Requested format is not available. Use --list-formats for a list of available formats [2023-02-08 17:18:54,061: WARNING/ForkPoolWorker-16] nMmvuNHHxnM: failed to download. [2023-02-08 17:18:54,151: INFO/ForkPoolWorker-16] Task home.tasks.download_single[c4dbe92f-6c7a-4ba1-b2d5-3609fc5c1187] succeeded in 0.8925375429680571s: None {"error":{"root_cause":[{"type":"resource_not_found_exception","reason":"snapshot lifecycle policy or policies [ta_daily] not found, no policies are configured"}],"type":"resource_not_found_exception","reason":"snapshot lifecycle policy or policies [ta_daily] not found, no policies are configured"},"status":404}
-
I'll try to recreate this when a new update comes out for a container. Will post logs and screenshots if it does it again.
-
@Squid Not sure if the future UR update is going to handle this but there seems to be another issue where the "Update All" button will update containers that the UI says are up to date. I think the plugin patch solves the UI display but not the underlying update functionality.
-
I put it to notify just to make sure that it was actually running. I'll be changing it back to errors only now. Just thought I would mention what I saw happening.
-
Double Notifications I can't say how long this has been going on for as I just noticed it. I'm seeing double notifications of appdata backup, and, from different 'senders'. It always starts with "Community Applications" but shows finished from "CA Backup". Same start and end times. Nothing showing wrong in the log at all.