




aglyons
Members
-
Joined
-
Last visited
Everything posted by aglyons
-
Was the reason for moving to the XE due to performance? I just pulled my older Nvidia card and put in an A380, and my first test was a major disappointment. One 4KHDR>1080 stream, and the GPU was hitting 94% usage. No better than the Nvidia card I had just pulled. Does the XE driver fix this? Also, is the ":plexpass" tag for lscr.io images?
-
My intention was not specifically JUST Unraid, but also the containers and VM's running on the system. I ran into an issue with Penpot using compose, where the exporter container was crashing and restarting so quickly that the UR UI couldn't report the restart loop. Only looking at the log files informed me of what it was doing. If this internal AI had been watching the logs, it could have informed me much earlier. As it stands right now, unless you are watching logs on a regular basis, which I suspect the majority of UR users are not, there could be issues happening in the background, causing other issues that are hard to trace for the average user.
-
I came across an AI log file scanner that would diagnose issues and humanize responses by explaining what is going wrong. It also provided steps to resolve the problem. I commented on the GitHub project, suggesting that a local AI agent could monitor Unraid/Docker/VM logs in real time and alert the sysop to any issues it finds, along with relevant solutions. Think "Fix Common Problems" on steroids. I did not receive a response from the maintainer. GitHubGitHub - YEDASAVG/Stratum: AI-powered Log Intelligence Sy...AI-powered Log Intelligence System - Semantic search, anomaly detection, and root cause analysis for logs using RAG techniques. Built with Rust, Axum, NATS, ClickHouse, and Qdrant. - YEDASAVG/Stratum
-
Currently, on the Docker page, whenever a container starts, stops, updates, etc., the entire page refreshes to display the container's current state. Using the compose plugin, containers are orphaned when the stack is updated. Clearing out orphaned containers can only be done one by one and requires a full page refresh for each. This takes more time and places more demand on system resources. An ASYNC refresh of changed content would dramatically speed up the process and enhance user experience. Any area of the UI could employ the same ASYNC refresh backend, further enhancing the user experience and system responsiveness.
-
I suggest allowing only approved individuals access to download the diagnostic files that community members upload. I understand that the data is sanitized and redacted. However, whenever I upload a diagnostic file, my UniFi IPS goes off the charts with blocking requests to my server. I get that this is a community and everyone is here to help each other out. But there is no way to be entirely sure that everyone here is being honourable and decent. I can only speak as to my experience and what I see happening. Perhaps only allow those with a certain number of verified answers to other posts? Forum admins? Forum moderators? Could there be further obfuscation of the data contained in the diagnostic files, such as any domain names or internal/external IP addresses? My network was relatively quiet regarding penetration attempts, but I recently posted a thread and attached my diagnostic file. Ever since then, I have been logging over 100 attempts a day to various ports and to my NPM container. And I'm a home user, not a big corporation. Thank god I went with the Unifi gateway to help block all this. Not cool. A.
-
I'll run the iperf. Just so I am clear, if an array folder has a cache-first config, when writing to the array, the files will initially be copied onto the cache pool, and then the mover 'moves' the files to the array. If this is not the 'understood' function, do I have to specifically state the files are landing on a cache pool, regardless of the fact that the mover will relocate the files? I chose to be specific about the config in the event that a pool array behaves differently than a shared folder cache config. Yes, they both land on a pool device, but in the latter, the mover is involved, which may introduce other parameters.
-
I did state that the files are being transferred to an SSD ZFS mirror cache drive. 2025-07-21_10-02-35.mkv 2025-07-21_10-02-04.mkv
-
I've posted about disk throughput before, and I have seen a number of other posts about it as well. So, I'm back with another question, hoping to either come to an understanding of why it works this way or potentially expose an underlying issue. I have two Samsung 870 EVO drives in a ZFS mirror as a cache drive for a shared folder. Everything written to the share goes to the cache (obviously). My network backbone is 10G, although the UR server utilizes the MB's built-in 2.5G NIC. I was transferring a folder with a series of +12GB files over to the array, and the network transfer rate was about 30-40MB/s. Which is a far cry from 10G speeds. That's when I took a look at the UR dashboard to see transfer rates and disk throughput. The network throughput was showing approximately 600 Mb/s, and disk throughput was fluctuating between 0 and 170 MB/s. There was never a constant write speed to the cache drive for the shared folder. The mover is not running, and no other transfers were running in the background. If there are any tests I can run, please let me know. Diag attached. Thx, A.
-
I think what you're really looking for is not really multiple arrays, but a cache pool for the existing array. None of the arrays (other than a ZFS AFAIK) have any striping, so you wouldn't see any real performance benefits with an array of NVME drives. I think you might even see a performance degradation (compared to single mounted NVME) as the array functions require all disk activity when writing to a disk in order to calculate the parity bits. That is the reason Unraid arrays don't have spectacular throughput performance and the addition of cache pools to speed up writing and reading (in certain configs).
-
I don't think disabling IPV6 or anything else does it. I suspect that once UR is up, making any change in the config resets the networking, and the SHIM gets created as it should. I myself had the default bridge disabled, and when I re-enabled bridging on the ETH0, everything started working. But I have seen many other people saying they enabled this or disabled that, and it started working again. I really think the problem is rooted in the boot-up process and the creation of the network at boot-up. Perhaps the SHIM creation process is run before another function that is required for the SHIM, in which case, the SHIM creation would fail. But once the system is up, changes to the networking runs the SHIM process again, and because all the other functions are already in place, the SHIM is created correctly. Again, this is all theory. I don't possess the required Linux acumen to diagnose this fully.
-
Thanks @bmartino1 and @ChrisCross Regarding the IP address to assign, is that for the host network or the VLAN? If it's the host network, is that not going to add another IP to the host machine on the same host network? I already have Unifi complaining on the regular about two devices having the same IP; now it appears that we are adding a third IP for one box!? @limetech This is an example of the community trying to help solve these issues, but there is a lack of clarity and an introduction of third-party code to solve a bug that could cause complications should the following release address this issue from another direction. If there is an official patch that works, either broadcast that out in an email to paid users or release the 7.1.3 release with this in place.
-
Is this script universal, or does it need customizing to work? My box has both bridging and bonding disabled, VLANs, and custom bridges in place. Also, my IP base is different from the script. I couldn't see any specific walkthrough of customizing the script to suit a system's config, and I would like to avoid killing my network connectivity completely. Any chance of getting a walkthrough on what needs to be customized?
-
And a fourth. https://forums.unraid.net/topic/189927-solved-710-host-access-to-custom-networks-no-longer-works/ The posted 'solution' does not read as a real solution but rather a temporary patch. It is a series of steps that must be performed after each system reboot, so the 'fix' is not persistent.
-
I just ran into this issue and have found two others that I suspect are the same issue. https://forums.unraid.net/topic/190305-712-docker-vlan-host-comms-broken/
-
I suspect that we are seeing the same issue. So far, I have found one other besides myself and this post. https://forums.unraid.net/topic/190305-712-docker-vlan-host-comms-broken/ In my case, nothing was changed in the networking or Docker config prior to or following the 7.1.1 or 7.1.2 updates, and it has been working with the same configuration since 6.12.
-
I have since found two other cases of this issue popping up. https://forums.unraid.net/topic/190244-712-docker-containers-cant-access-pihole-also-in-docker https://forums.unraid.net/topic/190273-712-docker-no-shim-network/
-
So this is the same situation I am seeing. I also just came across another similar post that is showing the same problem. IMO, this is a new issue since 7.1.x was released. That post does talk about the SHIM network and some scripts that need to run to solve the problem. But I have to question why this is an issue now when it wasn't before. If this is a known issue and there is a known workaround, why wasn't that workaround built into the release?
-
You're running pihole in a container in HOST mode or you created a custom network for PiHole? MACVLAN or IPVLAN?
-
Can you describe your network config? I just posted an issue with containers on a VLAN not being able to communicate with the host. Curious if this is the same problem.
-
I have a VLAN set via MACVLAN that, under v7.0, worked just fine. After upgrading to 7.1.1 and now 7.1.2, the containers on that VLAN and the host are broken in both directions: Host to Container and Container to Host. I made no other changes to the network config before or after the 7.1.1 or .2 updates. I have 'host access to custom networks' enabled. knoxx-diagnostics-20250517-1748.zip
-
Hey @VladoPortos, just thought I would bring up an oncoming headache. URv7.1 is baking in the oven with RC1 released. v7.1 includes CSS changes as they are working on reworking responsiveness. While I am looking forward to the fixes you are planning, I would hate to see you put a ton of work into FV2 only to have to do it all over again when URv7.1 gets released. While many here might not be too happy about it, with the limited time you have for this, it may be prudent to focus on your changes to be compatible with the 7.1 release instead of 7.0.1, as its lifetime is ticking down.
-
Do you not have the ability to edit the folder on the docker page and then toggle the switch on the containers you want to add to that folder?
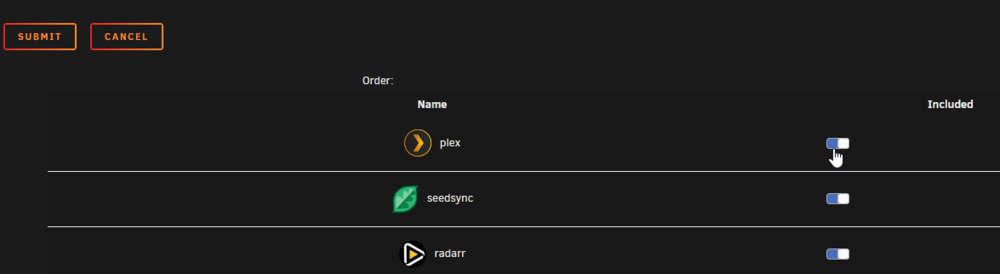
-
Yes it is, I don't think it's supposed to affect any page other than "/docker". I mentioned at the end of the post that I noticed it added a header "Dashboard Folders" which is not present when pulling up the main page on a PC. That leads me to think the CSS is not specific enough, locking it to only the /docker URL but also the mediaquery has issues with breakpoints.
-
I've discovered that there are other CSS issues with the current release. When opening the UR UI on my Samsung tablet, nothing shows in the page regarding inner content. Desktop PC and mobile are ok; the in-between media query sizes are somehow messing up. *** I just noticed that the main dashboard is showing "Dashboard Folders" for some reason.
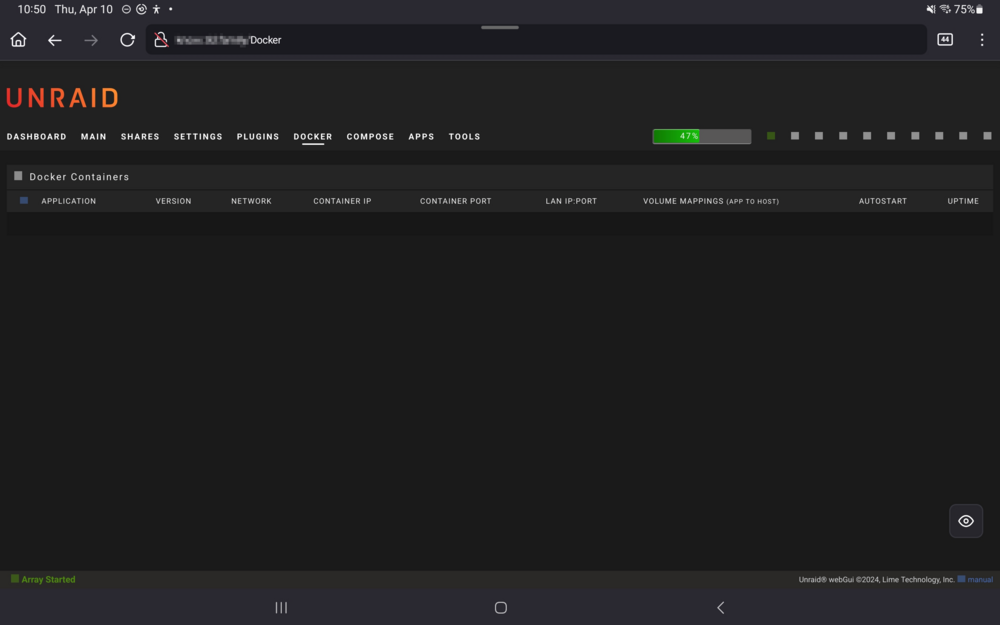
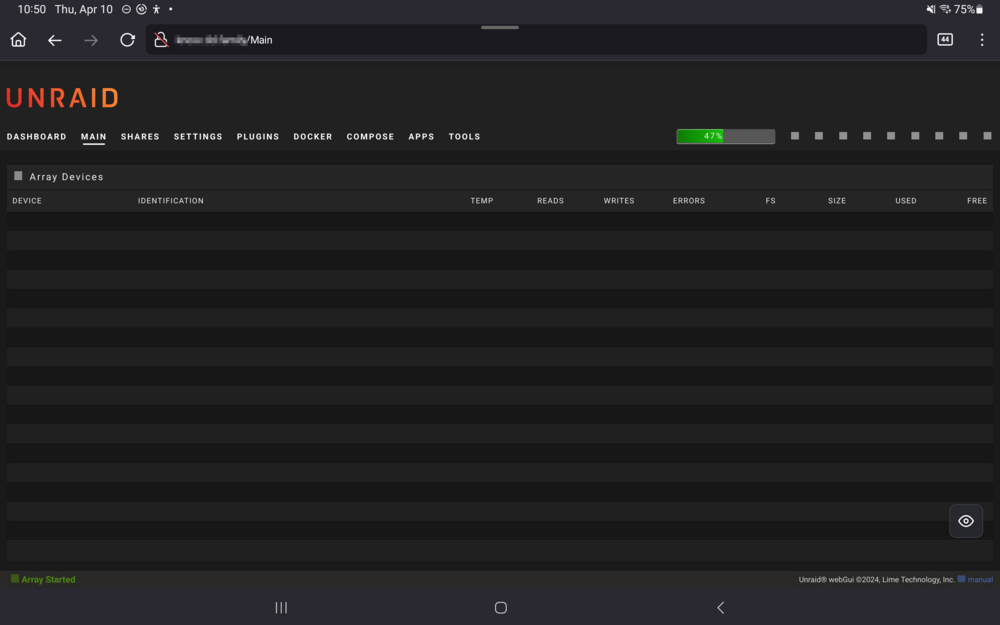
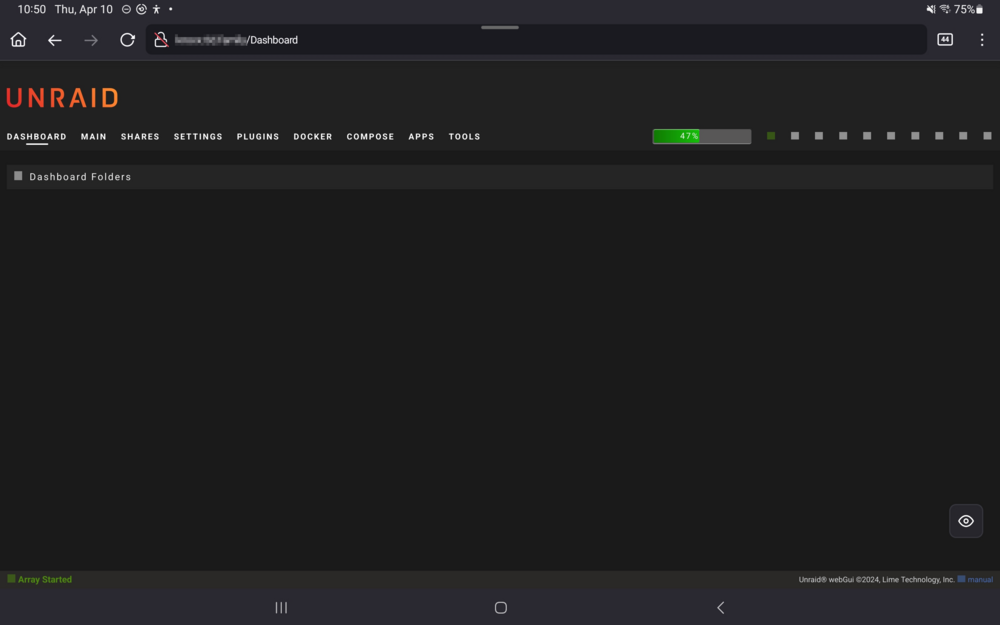
-
So I gave up on troubleshooting the default bridge and created a new bridge network parented to eth0. All containers moved to that new bridge are working as expected.







