




warp760
Members
-
Joined
-
Last visited
Everything posted by warp760
-
ja genau... mist, gestern erst auf die 6.11.2 gegangen 😞
-
Hab gerade das gleiche Problem. Es lief über mehrere Stunden ein Disc-clear durch. Jetzt steht da "unmountable disc" Drück ich auf formatieren, steht da ein paar Sekunden lang "formatieren gestartet" und dann passiert nix. Die betreffende Disc fährt nicht mal hoch... Wie ist hier vorzugehen?
-
Sollte kein Problem sein. Mache ich aber nicht. Bei Hetzner hab ich noch zusätzlich 10 Snapshots. Das reicht mir
-
Mach ich auch so, nur ich lass die Qnap die Daten "holen" Qnap fährt hoch > holt sich alle neuen Daten > komprimiert und verschlüsselt das Ganze > schickt den verschlüsselten Klumpen zu Hetzner nach Finnland > fährt wieder runter. Unraid macht bei mir garnichts. Qnap hat nur Leserechte auf unraid
-
Er meint das endlich mal jemand den Container anpasst dass das in Zukunft nicht mehr passieren kann. Der Maintainer ist ja offenbar nicht mehr "vorhanden"
-
Raspberrymatic an sich läuft wunderbar. Nur halt nicht mit der ETH Platine. Läuft bei mir deswegen immer noch auf nem Raspi. VM ist mir zu energiehungrig.
-
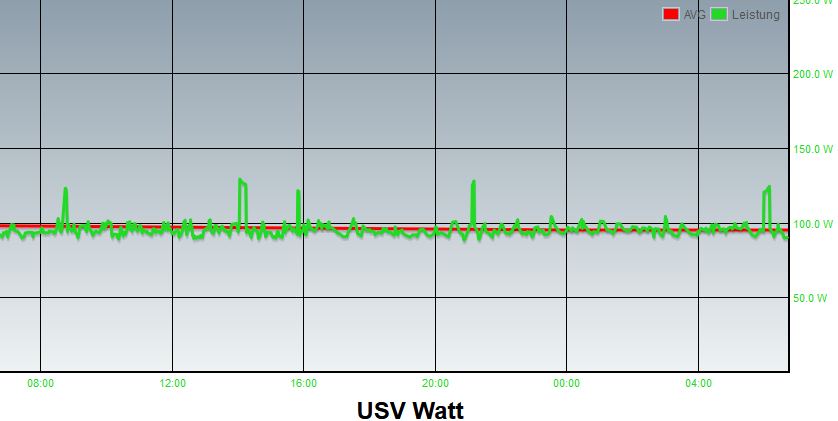
Ich hab die leider auch...
-
Interessiert Parity wenn in Cache geschrieben wird? Warum?
-
Hä? Und das ist für dich ein Backup?
-
Sicherst du auf ein Qnap? Wenn ja, regel doch alles von dort aus (nur mit Leserechten) Läuft bei mir einwandfrei
-
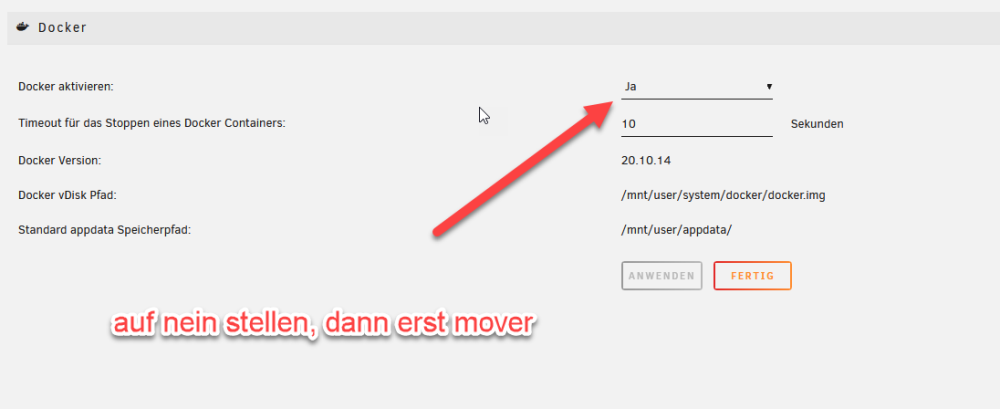
Schalt mal den mover noch aus
-
Dockerdienst davor gestoppt?
-
Ja klar... aber nur weil du es vorher falsch gemacht hast
-
Das war falsch! Du musst nicht die Docker stoppen, sondern den kompletten Dockerdienst Aber bei dir jetzt eh schon zu spät
-
Qnap hat auch extrem kurze Server. Die laufen ja auch mit unraid. Hardwarespecks kenn ich aber nicht. Ich selbst habe das Silverstone RM21 und bin damit sehr zufrieden. Ist 480mm tief. Mein Schrank hat 700mm Tiefe. https://www.galaxus.de/de/s1/product/silverstone-rm21-308-rack-montage-2u-micro-atx-satasas-hot-swap-ohne-netztei-server-barebone-14330780?supplier=2705624
-
CCU2 habe ich schon lange nicht mehr 🙂 Mit der geht doch glaub nicht mal IPwired oder?
-
Hi Leute, ich hänge auch gerade n bisschen fest 😞 Will folgenden Docker installieren: https://hub.docker.com/r/ledidobe/grott Muss ich Zuweisungen usw gleich beim Starte mit angeben? Bei mir lädt der nicht mal was runter, sondern wirft sofort n Fehler? Hau ich allerdings docker run -d -p 5279:5279 --restart on-failure -e gmqttip="192.168.0.206" ledidobe/grott in die Konsole, dann lädt er alles runter und ich hab dann auch n Container (da kann ich dann aber nichts mehr einstellen) und mein kleiner i3 wird 60° heiß... Also irgendwas rotiert da 😞 <wie geh ich denn da richtig vor?
-
Nur die Dokumente die neu dazu kommen. Alte werden nicht einfach "umsortiert"
-
Selbstverständlich... Die Anleitung ist ja eindeutig. Aber viel Erfolg 🙂 VM kommt mir nicht in die Tüte (Stromverbrauch) Denk ich lass das aufm Raspy. Im Schrank hängt der jetzt auch an der USV und hab nun n zweiten gerichtet damit ich bei Defekt schnell wechseln kann. Die ETH hängt mit POE am Switch.
-
Ne, Raspberrymatic läuft bei mir immer noch auf m Raspy mit abgesetzter ETH Platine. So ist der Raspy nicht mehr an einen Ort mit gutem Empfang gebunden und konnte in 19" Schrank einziehen. Drum hab ich auch kein USB. Denk der Serverschrank wird bei den wenigsten "mitten im Haus" stehen 🙂 Wie ich das bisher gelesen habe, muss direkt auf unraid (also nicht im Container) einige Treiber nachgeladen werden und davor scheue ich mich noch. Bringt mir nix, wenn raspberrymatic läuft und der Rest dafür instabil wird. Die IP ist natürlich eingetragen. Die ETH läuft ja jetzt auch schon Ansonsten läuft der Raspberrymatic Container problemlos. Einfach Backup rein und ab dafür. Hab halt nur zu nix Empfang. Wenn unraid bei dir im "Wohnraum" steht, dann kannst es ja mit USB probieren. Mit Ethernet ist man halt viel viel flexibler.
-
Falls das falsch rüber kam: ich hab nen extra redis Docker
-
Das frage ich mich auch... mir ist vor Kurzem aufgefallen, dass mehrere Dokumente fehlen. Die waren natürlich auch schon durch den Schredder gewandert. Durch ne blöde Einstellung beim Backup, das Dateien auch auf m Ziel gelöscht werden, waren die fehlenden Dokumente im Backup natürlich auch nicht mehr. Bin gerade dabei meine wöchentlichen Snapshots aus Finnland runterzuladen um zu schauen wann genau das passiert ist. Inzwischen sind aber "plötzlich" wieder 8 neue Dokumente in paperless aufgetaucht. Unter anderem das eine Dokument wo ich gesucht hatte. Weiß ja nicht genau welche fehlen. In dem Zeitraum waren ja mehrere Updates von redis. Ich vermute hier einen Zusammenhang. Das waren jetzt nur paar alte Rechnungen, wobei ich ja nicht wirklich weiß was noch fehlt. Alles in allem ist bzgl paperless meine Stimmung SEHR getrübt 😞
-
Ich hab mit 6.9.3 angefangen und da war das auch schon auf 0 Bin da als Newbie natürlich auch gleich reingelaufen. Super nervig... verstehe nicht, warum da 0 drin steht.
-
Und vielleicht auch größere Intervalle. Hab aktuell 4x im Jahr eingestellt.
-
Servus @cz13 danke... aber das hatte ich mir auch schon durchgelesen. Bin aber leider nicht wirklich schlau draus geworden. Wie lest ihr denn eure Temperaturen von extern aus zum mitloggen oder ähnlichem?

