




thellamapaul
Members
-
Joined
-
Last visited
Everything posted by thellamapaul
-
Just to add data, my issue ended up being a bad overclock config that was causing the system to crash under high load.
-
While this is an operational workaround that I'm currently using and linked in my first post, it is not a solution. Implementing the fix seems like it would be a quick variable definition change, as long as the developers can agree on a new glyph to define.
-
Please update the model declaration in /etc/avahi/services/smb.service from Xserve, which is no longer included in Mac os (per this thead) and results in a blank paper icon in Finder. That same thread suggests using 'MacPro7,1@ECOLOR=226,226,224' instead, which I also like.
-
Yep totally works, not sure how I was missing it 😖. Thanks for all the hard work 🥳
-
Picking this back up, has anything changed in the last 5 years to support this? I'm looking through 82 pages of the Unbalanced thread and losing my mind
-
I have the smae issue of it spinning and not completing. My server was connected before and now also reports offline (I did not reflash anything). Connect reports it being version 6.12.3 and having cached values from 8/26/23, but apparently has a flash backup from 12/4/23, so it seems like it partially broke in an update but flash updates never stopped. I tried reinstalling the connect plugin but still have the same result.
-
I also have this issue, I also use an nVidia GPU for transcoding (750 Ti). Identified Plex as the issue after changing the time scheduled tasks start and the reboot time followed. Since I've been tracking it, it happened on 4/9, 4/14, 4/28, and 5/1, so pretty sporadic. I have Plex log to my Syslog and attached the logs around the most recent 3 incidents. According to the logs it looks like thumbnails, but there are plenty of times thumbnails are generated without the crash. I'm guessing it's something else that doesn't log. plex reboot logs.txt
-
Giving this a shot! Thanks!
-
Hi, been seeing this issue for a while. Major symptom is docker containers stop responding, then I check the Unraid web gui which usually loads slowly and shows load at 100%. Usually lasts a couple minutes. Did a bunch of tests trying to reproduce it and was able to do it a couple times but nothing concrete. Seems like something is getting triggered after so many new files are created and brings the server to a halt. Everything is being written to an SSD cache. Diagnostics and a screenshot of my file transfer test attached. cayenne-diagnostics-20230311-1543.zip
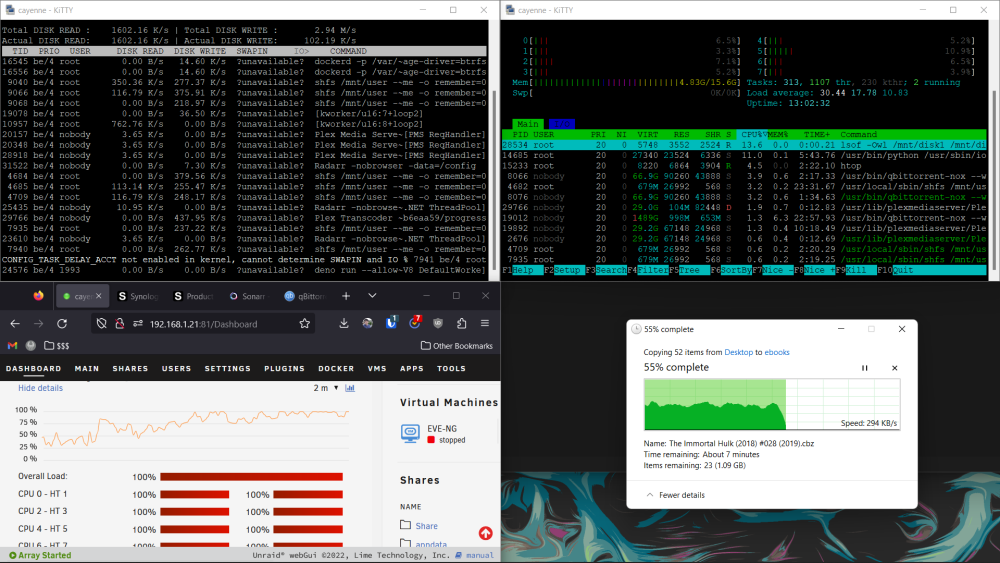
-
First time posting. Fix Common Problems reports Machine Check Events detected and recommends posting my diagnostics to get more info. I'm on 6.11.5 so I understand mcelog is already installed. I've attached my anonymized diagnostics. Been running Unraid for a couple months now. Just upgraded my mobo and cpu on 3/6 so wouldn't be surprised if that was related. Probably a separate issue, but I have been having performance issues where my docker containers are unresponsive randomly. I can usually lo into the Unraid GUI and see the overall load sitting at 100%. After a couple minutes the load will drop back down under 50% and everything will respond again. During this time I can ssh into the server as well and can't identify anything specific in htop or iotop. Usually iotop will be writing a bit but I have everything writing to a cache drive so not sure why I'm seeing such notable performance impact. Thanks in advance! cayenne-diagnostics-20230311-1100.zip

