




jortan
Members
-
Joined
-
Last visited
Everything posted by jortan
-
You may want to look at ZFS + snapshots using sanoid + syncoid if you want to replicate those snapshots to another machine. It's a lot more manual work to configure and maintain, but a good learning experience if you're up for it. It seems native ZFS support will be coming to Unraid eventually. It's great for running dockers/vms, though with ZFS you don't have the ability to cache writes to the array within Unraid like you can with the built-in "pool" functionality (my guess is this will be possible when Unraid supports ZFS natively) There's a number of Youtube guides for implementing ZFS in Unraid also.
-
From what I understand it has long been the case that some people report issues with docker on ZFS and some people have none. This might be due to ZFS only having problems with specific containers? I've had issues with dockers using "sendfile" syscall on ZFS previously: But it seems likely this is fixed now: https://github.com/openzfs/zfs/issues/11151 Could this have caused some of the other docker + ZFS issues seen in the past? I've had issues with docker + ZFS previously (both using docker.img and using a direct file path on ZFS). I've never used ZFS zvols. I don't have the bandwidth right now to try migrating this back to ZFS. I will try to revisit this when 6.10 is released.
-
Typically this is ~/.vimrc (aka /root/.vimrc) but this path isn't located on persistent storage so it won't survive reboots. Run this once but also add it to /boot/config/go echo "set tabstop=4" >> ~/.vimrc
-
zfs import is what you wanted here, not zfs create I suggest before you do anything else, you zfs export the pool (or just disconnect the drive) prevent any further writing and consider your options (but I'm not sure if there are any)
-
More deduped data also means more compute resources to compare each write to hashes of all the existing data (to see if it can be deduplicated) I don't know for sure, but I suspect not - in the same way that adding a normal vdev does not cause ZFS to redistribute your data or metadata. It should by design, but it also might just break (situation may have improved in the last 11 months?)
-
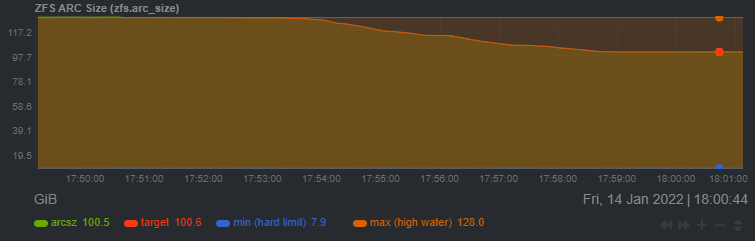
To clarify earlier comments about ZFS memory usage - the ARC doesn't show how much memory ZFS needs to function, the ARC will dynamically consume memory that the system doesn't otherwise need. This is why you can't assume how much memory ZFS "needs" for dedupe/DDT based on ARC size before/after turning on dedupe. It is expected that the ARC would be the same size in both scenarios. To demonstrate that the ARC is dynamic and doesn't actually show how much memory ZFS "needs", you can artificially reduce the amount of memory available to ZFS by consuming memory in a ram disk mount -t tmpfs -o size=96G tmpfs /mnt/ram/ As you copy files to the ram disk, and as available memory approaches 0%, the ZFS ARC will release memory back to the system, dynamically reducing its size: \ ZFS will continue functioning without issue (but with less data cached) until the DDT starts getting pushed out of the ARC because it no longers fits. This can happen if you: - keep adding data (DDT size increases), and/or - reduce the amount of memory available to ZFS At this point, performance of the ZFS filesystem will reduce, likely by orders of magnitude.
-
Neither me nor the documentation I'm referencing are saying dedupe performance with a special vdev is bad (at least not over dedupe performance without a special vdev) Without the special vdev your normal pool devices will very busy writing your data, but also all the hashes/references for the deduplication table (DDT). For spinning rust disks, this is a lot of additional random I/O and hurts performance significantly. Unless designed very poorly, the special vdev will increase performance because it spreads the DDT writes to separate, fast storage devices. The DDT is not a cache, and neither is the special vdev --- https://www.truenas.com/docs/references/zfsdeduplication/#deduplication-on-zfs The DDT needs to be stored within your pool (in vdev or special vdev) and constantly updated for every block of data that you write to the pool. Every write involves more writes to the DDT (either new hashes or references to existing hashes) When ZFS writes new entries to DDT (or needs to read them from the pool/special vdev) it's cached in memory (ARC) and will push out other information that would otherwise be stored in the ARC. If your DDT becomes large enough to exceed the amount of memory that ZFS is allocating for ARC, that's where you will run in to significant performance issues. That's not counting the fact that there is other data that ZFS wants to keep in the ARC (regularly accessed data and ZFS metadata) for performance reasons. Keeping the hashes/references to what has already been written in memory is fundamental to how de-duplicating file systems work. However, those hashes/references are fundamental structures of the file system, which is why they can't only exist in memory and must also be written to the filesystem.
-
By default openzfs on Linux will "consume" up to half of system memory for the ARC, subject to other memory requirements of the system. This memory is allocated to the ARC regardless of whether dedupe is enabled or not and the amount allocated can't be used to measure how much memory is being used by dedupe. The special vdev provides faster read/write access for permanent storage of the metadata and DDT, but the DDT still needs to fit in ARC memory to avoid significant performance issues. https://www.truenas.com/docs/references/zfsdeduplication/ The amount of memory required to keep DDT cached in ARC ... https://www.truenas.com/docs/references/zfsdeduplication/ zdb doesn't function by default in Unraid due to lack of persistant storage location for its database. You can enable zdb database in memory using these commands: Further recommendations for estimating DDT size in a ZFS pool (and subsequently, the memory required for performant dedupe in ZFS): https://serverfault.com/questions/533877/how-large-is-my-zfs-dedupe-table-at-the-moment Hope this helps.
-
I think he's talking about this suggestion: The Unassigned Disks has facility to mount remote shares in the GUI. These get mounted to /mnt/remotes. You could then assign these folders to dockers on the primary Unraid server. This is theoretically possible, but there will likely be some issues around timing for auto-mount as the nested Unraid won't be available when the primary Unraid array starts. And I think where you fix these remote mounts after the docker has started, you will need to restart the docker in order for it to see the files? Not sure but I recall something like this from my testing. Using multiple cache pools on a single Unraid server would be the simpler option for now. Or, live with a single array for now. This will be much easier to transfer to multiple arrays when this feature is added as your data will just be on standard XFS formatted disks, and you can (carefully) assign these to a different array later without needing to transfer data.
-
I'm not trying to win an argument. If I post something that's wrong, I appreciate it when someone takes the time to correct me (and will edit the original post containing the incorrect information). The information you have posted isn't a difference of opinion, it's just incorrect as per openzfs documentation. If you don't want to learn and don't want to edit your posts then I guess we're done here. For someone who complains about ZFS misinformation on the internet, I find this bizarre. Have a great day? https://openzfs.readthedocs.io/en/latest/performance-tuning.html
-
Your evidence is based on not really understanding how ZFS allocates memory. If you keep adding deduped data or applications with memory requirements, at some point your system will suffer significant performance issues or might stop working completely. It might be next week or it might be never - you don't know when because you haven't considered/measured it. This isn't evidence or a difference of opinion, it's just factually incorrect. If you don't want to learn, that's fine, I'm trying to correct misinformation for the benefit of others who might try to learn about ZFS here. ZFS Dedupe does have additional memory requirements, regardless of the addition of a special vdev. It's crucial that you have enough memory for the DDT. Implementing ZFS dedupe without measuring/considering memory requirements is inviting a disaster scenario. You may not care if your ZFS pool/Unraid server could potentially fall off a performance cliff or stop working at all. For people who would consider that a minor disaster: https://www.truenas.com/docs/references/zfsdeduplication/
-
Operating system volumes for virtual machines is a use-case where dedupe is going to be very useful. Glad it's working for you. I don't mean to be rude, but the assertions in your post are bording on misinformation and could lead people to get themselves in to very difficult situations: I strongly recommend you review how ZFS/ARC allocates memory dynamically as you have reached the wrong conclusion from your observations. ZFS ARC is utilising available unused memory in both situations - this is why you aren't seeing any noticeable change. When other applications or the operating system demand more memory, ZFS will dynamically reduce the size of the ARC. Without dedupe, the ARC is caching ZFS metadata and data inside your pools. When you have dedupe enabled it additionally needs to cache the DDT. The DDT is going to occupy some of that space in the ARC that would otherwise be used to cache data/metadata. If the size of the DDT exceeds the memory that ARC is able to allocate, you will suddenly run in to serious performance issues. Yes, the special VDEV absolutely holds the DDT and helps with performance for dedupe pools. However, this is no substitute for carefully considering the memory requirements for the DDT when enabling dedupe with ZFS. It's critically important that the DDT also fits in memory. Think for a moment about how ZFS dedupe works. Every block written is hashed and that hash placed in the DDT - or a reference to an existing hash. The DDT is written to the special vdev, but also dynamically cached in memory by the ZFS ARC. Every subsequent write to that dataset needs to hashed and compared against all the hashes in the DDT. All of them. For every block you write. Each write can't occur until it's been compared to all the hashes in the DDT. If those hashes aren't already cached in the ARC, it needs to read them from the special vdev. That takes far, far more time than if the hash was already in memory. If reading parts of the DDT from the special vdev pushes another part of the DDT out of the ARC (because you don't have enough memory), then very suddenly your performance is going to tank abysmally. Every single block written is going to need hundreds or thousands of reads to your special vdev to complete. Every. Single. Write. The reason your ZFS dedupe is working great, is not (only) because of the special vdev, it's because you (currently) have sufficient memory for the DDT to be permanently cached in the ARC. That could change and very suddenly if you write more data to your dedupe datasets and/or other applications demand memory and ZFS reduces the ARC size. This is not about corporate vs. homelab performance, this is about ZFS dedupe working brilliantly, until it very suddenly works terribly (or stops working at all) because the DDT no longer fits in memory. To say that ZFS dedupe doesn't have additional memory requirements anymore because of special vdevs is simply not true. No, they will become slower when they fill up, but will always get thrashed relatively speaking - because writes to a dedupe dataset in the pool requires a multiple of writes to the DDT: https://www.truenas.com/docs/references/zfsdeduplication/
-
Nobody here said dedup wasn't worth using outright, I said that in my experience running steam folders over network isn't worth it. If the desired outcome is to tinker and experiment and learn, then I'm all for that. If the desired outcome is the right tool for the right job, then for the benefit of other people who might be reading this and think this is a good idea for performance reasons - it probably isn't (in my opinion). A cheap SSD (on the gaming machine itself) will almost certainly perform better. Network speed / ZFS performance are factors but not the only ones - consider all the context switching between drivers and network stacks for every single read and write to storage. A normal gaming computer application requests read/write data -> storage driver -> disk performs read or write -> storage driver -> application A gaming computer with iscsi storage application requests read/write data -> storage driver (iscsi initator) -> network driver (client) -> transmit request over network -> network driver (server) -> storage driver (iscsi target) -> disk performs read or write -> storage driver (iscsi target) -> network driver (server) -> transmit request over network -> network driver (client) -> storage driver (iscsi initiator) This context switching is not without cost. It's the reason SATA is going away and SSD storage is being placed directly on the PCIE bus now - the fewer protocols/driver stacks that storage needs to go through, the better. If you think a bit more about how dedupe works, it absolutely must use more memory. Every time you're issuing a write to dedupe pool, ZFS needs to hash the data you're asking to write and compare it against hashes of data already stored (the DDT table). If those hashes don't fit in ARC memory, ZFS would need to read the missing hashes from the vdev or the pool every time you issue a write command. Yikes. If you throw a bunch of data at ZFS dedupe and haven't planned your memory/metadata requirements, you could find your dedupe storage grinding to a halt. The special vdev just provides a low-latency place for reading/writing metadata/DDT table because they will be constantly thrashed by reads/writes: https://www.truenas.com/docs/references/zfsdeduplication/ So as I stated in previous post, this will add even more context switching/latency than running iscsi alone.
-
Impressive numbers - just keep in mind that these may not reflect real-world performance due to a number of factors (not least of which your reads are likely coming straight from ZFS ARC memory, not from actual ZFS storage) >>and play with IT stuff Have fun then, sorry I don't have any answers re: ZFS de-dupe in Unraid.
-
Your mileage may vary, but I have played around with network steam folders in the past and found it wasn't worth the effort. Adding network i/o to storage is always going to impact negatively on performance, and adding ZFS dedupe is going to make this even worse. Another approach you may want to consider is lancache: https://forums.unraid.net/topic/79858-support-josh5-docker-templates/ This will cache all steam downloads from computers on your network - so you can delete games from your computers knowing you can reinstall them again later at LAN speed if required. ps: lancache docker does require a workaround when using ZFS as your cache repository: https://forums.unraid.net/topic/79858-support-josh5-docker-templates/page/9/?tab=comments#comment-938921
-
Do you have the "Community Applications" plugin installed? This adds the "Apps" tab to unRAID. If you're already searching in "Apps" and still can't find it, what version of unRAID are you running? I'm still on 6.10.0-rc1, not sure if it's published for rc2 yet?
-
Not aware of Recycle Bin functionality, but you can have ZFS publish snapshots to the Shadowcopy / Previous Versions tab in Windows, so you can view older versions of your shares from Windows: Scroll to "ZFS Snapshots – Shadow copies!!! Part 1, the underlying config" here: https://forum.level1techs.com/t/zfs-on-unraid-lets-do-it-bonus-shadowcopy-setup-guide-project/148764 edit: You can enable Recycle Bin as well: https://forum.level1techs.com/t/zfs-on-unraid-lets-do-it-bonus-shadowcopy-setup-guide-project/148764/238
-
Could be bad cable? More likely, you might need to disable NCQ in Unraid Settings | Disk: @MikkoRantalainen Apparently some users have the issue only with queued TRIM, some need to disable NCQ entirely. It depends if you have "SEND FPDMA QUEUED" (queued TRIM only) or "WRITE FPDMA QUEUED" (NCQ in general). bugzilla.kernel.org/show_bug.cgi?id=203475#c15 Me personally, I get the latter, and the only fix is to disable NCQ entirely via kernel command line. (Samsung 860 EVO + AMD FX 970 chipset) – NateDev Jun 12 at 3:10 https://unix.stackexchange.com/questions/623238/root-causes-for-failed-command-write-fpdma-queued Keep in mind that LSI Controllers don't support TRIM, so you're going to have performance issues with your SSDs as time passes. Use onboard SATA ports if possible. I have my LSI firmware on P16 as that's the latest version is the latest that works with TRIM. edit: UDMA CRC Errors These are most commonly cable issues I think?
-
I have all my dockers running on custom bridge with dedicated IP. I've tried adding the IP assigned to machinaris docker in the worker_address variable, but I still can't get machinaris running again. I'm using a basic full node setup, chia only. debug.log webui.log Anything I can do to get this running on a custom bridge network again?


-
It's not the only option though, that's what pools are for? There's a case to be made that unRAID should not require an array to be present if you don't need one. That one I agree with, though there is clearly a lot of code currently hanging off whether the array is up or down (ie. you can't run docker/vm services without the array running). It will probably happen one day, but that's a massive change for unRAID. I'm a huge advocate of ZFS and very appreciative of @steini84 / @ich777's work on this, but unRAID's array is still arguably the better option for large libraries of non-critical media where write performance isn't that important - ie. media libraries/copies of your blurays, etc. With an unRAID array, if you have a 12 disk array and you lose 2 disks - you only lose the data on those 2 disks. With the same RAID5-style BTRFS/ZFS pool and a single parity disk, if you lose 2 disks, you've lost the entire pool. There's also the flexibility where (as long as your unRAID array parity disk is equal in size to your largest disk), you can add individual disks of any size and fully utilise their capacity. To each their own, but my 2c is that these features will continue to provide value long after ZFS support for pools in unRAID becomes mainstream.
-
Yes, and that's the secret sauce of unRAID - the ability to add redundancy to an array of dissimilar disks via block level RAID5 equivalent parity (even when those disks contain different file systems) and combine these in to a single virtual filesystem. But it's for this reason that It simply makes no sense to have ZFS pools inside unRAID's array because they're trying to do similar things things in completely different, mutually exclusive ways. In the same way it makes no sense to have a RAID5/10 BTRFS pool inside the unRAID array and why this functionality is already provided in the form of pools separate from the array. Agreed, if anything just don't upgrade your ZFS pools with any new feature flags introduced from now if you don't need them, just in case.
-
It's mentioned that ZFS will be an option for storage pools, not the array: ZFS File System Ever since the release of Unraid 6, we have supported the use of btrfs for the cache pool, enabling users to create fault-tolerant cache storage that could be expanded as easily as the Unraid array itself (one disk at a time). Adding ZFS support to Unraid would provide users with another option for pooled storage, and one for which RAID 5/6 support is considered incredibly stable (btrfs today is most reliable when configured in RAID 1 or RAID 10). ZFS also has many similar features like snapshot support that make it ideal for inclusion.
-
Is this confirmed anywhere? Seems more likely to me it will be offered as an alternative pool file system, not an array replacement?
-
This is normal but ZFS will release this memory if needed by any other processes running on the system. You can test this, create a ram disk of whatever size is appropriate and copy some files files to it: mount -t tmpfs -o size=64G tmpfs /mnt/ram/ Outside of edge cases where other processes benefit from large amount of caching, it's generally best to leave ZFS to do its own memory management. If you want to set a 24GB ARC maximum, add this to /boot/config/go echo 25769803776 >> /sys/module/zfs/parameters/zfs_arc_max Yes, but if you're optimising for performance on spinning rust, you should probably use mirrors. Optane covers a lot of products. As far as I'm aware, they all just show up as nvme devices and work fine for ZFS. Where they don't work outside of modern Intel systems is when you want to use them in conjunction with Intel's software for tierered storage. I use an Optane P4800X in an (old, unsupported) Intel system for ZFS SLOG/L2ARC on unRAID.
-
Nice job, looks great! Live read/writes stats for pools? ie. 'zpool iostat 3' ? Perhaps make the pool "green ball" turn another colour if a pool hasn't been scrubbed in >35 days (presumably it turns red if degraded?) Maybe a similar traffic light indicator for datasets that don't have a recent snapshot? This might really help someone who has added a dataset but forgotten to configure snapshots for it. Maybe make the datasets clickable - like the devices in a normal array? You could then display various properties of the datasets (zfs get all pool/dataset - though maybe not all of these) as well as snapshots. Some of the more useful properties for a dataset: used available referenced compression compressratio as well as snapshots



