




jortan
Members
-
Joined
-
Last visited
Everything posted by jortan
-
Reboot and the unRAID ZFS plugin should use the package you just downloaded. There's still some underlying issue to be solved though, or you will continue to have problems. It's possible this is due to the system time on your unRAID server being incorrect. What's the output of: date edit: If date is correct, what's the output of this: openssl s_client -showcerts -servername github.com -connect github.com:443
-
If still not working, does your unRAID machine have internet access? Try these to test ping 8.8.8.8 net lookup github.com
-
On "plugins" tab, is "ZFS for unRAID 6" up to date? What's the output of this command? ls -alh /boot/config/plugins/unRAID6-ZFS/packages and this: cat /var/log/syslog | grep 'plugin:' Is your internet gateway running on unRAID? I have run in to issues where the required package can't be downloaded on boot (and hasn't been previously cached) You could try downloading the package manually and rebooting? cd /boot/config/plugins/unRAID6-ZFS/packages wget 'https://github.com/Steini1984/unRAID6-ZFS/raw/bce53432ab6891f33cd2fd16a4621b66a0c9c2dd/packages/zfs-2.0.0-unRAID-6.9.1.x86_64.tgz'
-
That would seem to be the case. 6.8.1 is well over a year old now and was only current for a couple of weeks before being replaced by 6.8.2. Anything stopping you from upgrading? Might be worth upgrading to 6.8.3 if you don't want to move to 6.9? 6.8.3 was a main branch release for a long time while 6.9 was being worked on so should be well supported by plugins.
-
Does borgbackup need updating? I'm getting this on 6.9.0 and 6.9.1: Traceback (most recent call last): File "/usr/bin/borg", line 33, in <module> sys.exit(load_entry_point('borgbackup==1.1.15', 'console_scripts', 'borg')()) File "/usr/bin/borg", line 22, in importlib_load_entry_point for entry_point in distribution(dist_name).entry_points File "/usr/lib/python3.9/importlib/metadata.py", line 524, in distribution return Distribution.from_name(distribution_name) File "/usr/lib/python3.9/importlib/metadata.py", line 187, in from_name raise PackageNotFoundError(name) importlib.metadata.PackageNotFoundError: borgbackup edit: It seems I can just run the binary borg-linux64 from here. Anyone know if I'm likely to run in to issues using this?
-
I tried this not long ago and had issues installing a specific docker josh5/lancache-bundle This was separate to the issues this docker has with storing its proxied data on ZFS, though possibly caused by the same problem (lack of sendfile syscall on ZFS)
-
Don't hold your breath. https://pca.st/wcs7v9ww skip to 19:10
-
They are definitely not spurious. But the disk will have already remapped any problem sectors to working parts of the drive. "reported uncorrect" is a serious error though, and I suspect it means you may potentially already have corrupted data. That's independent of anything resetting counters to zero. Not entirely equivalent. A zfs scrub does not check the health of the entire disk, but it will check the integrity all of the data. I recommend adding this to "user scripts" and running it once per month or so: #!/bin/bash zpool scrub yourpoolname Then run this to get the status/results of the scrub: zpool status ZFS is far better than other high-availability implementations (like RAID, or unRAID arrays) in regards to data integrity. If your disks disagree about what the correct data is, ZFS is able to use checksums to determine which data is correct and which drive is "telling lies" edit: Even better, you could have read errors/corruption on both drives in a ZFS mirror and still keep your array functional by replacing with working disks (without removing the existing ones) - as long as ZFS can read each record on one disk or the other. With RAID, a failing disk is going to be kicked out of the array entirely and if your other disk in the mirror is failing, you're going to have a bad time. In the case of unRAID array, every time you recheck your parity you are potentially overwriting the parity drives with incorrect information if any one of your drives are damaged. This is a good ZFS primer that covers this and more:
-
Are you trying to create a RAIDZ1? I'd recommend lower case to make your life easier. There were some spaces where there shouldn't be and you forgot to include the name of the pool (in addition to the mount point). I think this is what you want? zpool create -o ashift=12 -m /mnt/4tbpool 4tbpool raidz /dev/sdg /dev/sdt /dev/sdu /dev/sdv zfs set atime=off 4tbpool zfs set xattr=sa 4tbpool edit: raidz not raidz1
-
-
Unless I'm misunderstanding something, I have a disk with Reported Uncorrect sectors in my main unRAID array and unRAID does not appear to reset these during parity checks? This information can be useful to determine whether this was a one-off event or whether the disk is continuing to degrade. 9 Power_On_Hours -O--CK 056 056 000 - 38599 Error 144 [3] occurred at disk power-on lifetime: 20538 hours (855 days + 18 hours) In my case, for bulk storage of data I don't care too much about, this is fine.
-
Probably a good idea for the docker image ("Docker vDisk location:" in Docker Settings). I just have this running on a single XFS partition at the moment, it's not that much of a pain to recover from if it dies. For the "appdata" docker files, ZFS works great. Out of the ~30 or so dockers I run, the only issue I've had was with lancache-bundle, workaround for that is here
-
There has been a misunderstanding historically whenever ZFS support was raised as a feature request. ie. it was always talked down because people assumed that that there was a desire to replace the unRAID array with ZFS. Some may wish to do that, but as you say, it's best suited to replacing the "pool" function, not the array. Support for multiple pools was probably a pre-requisite for ZFS support. What's next? Maybe to get ZFS pools supported in Unassigned Devices or a new plugin? Ultimately that work could potentially be pulled in to unRAID proper for ZFS support, as we've seen with other plugins.
-
I just moved a ZFS pool from one unRAID server to another and I'm fairly sure the ZFS plugin mounted the pool for me automatically. I may have issued a "zfs mount -a" command, can't remember, but it was no more complicated than that.
-
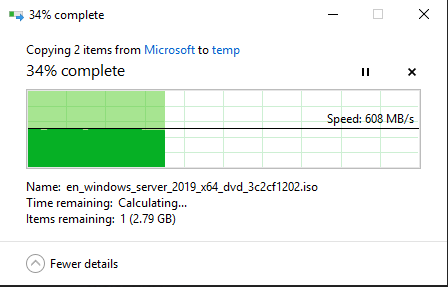
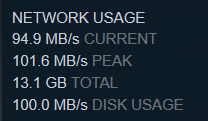
From doing some quick reading there may be some benefit to that, but would probably require far more customisation of unRAID internals than is the case for VMs. On that note, moving a Windows VM from virtio-net to SR-IOV, my SMB read speeds across network have gone from ~70MB/sec to ~600MB/sec. Wow!
-
You can run the iperf3 server as normal, and on the client run something like this: iperf -P 8 -c ip.address.of.server That launches 8 parallel streams, and seems to run multithreaded.
-
Will not work at all on P20 firmware. fstrim on P16 only works if SSD supports deterministic read zero after trim (for samsung 8xx, this is from 860 onwards). Described well in this post: https://forums.unraid.net/topic/84156-lsi-9211-8i-and-trim-support/?do=findComment&comment=779516
-
I've been running P16 on multiple controllers for ~6 months, including my main array and two ZFS pools (SSD and SAS disk). ZFS pools have checksums for all data, the pools are scrubbed regularly. No issues encountered.
-
Unfortunately it looks like SR-IOV/RDMA can't be used together on ConnectX-2/3 adapters, so I'll probably be using them on the Windows client side, but not for unRAID/SR-IOV/RDMA. edit: This is a lot more complicated than I thought.... https://www.starwindsoftware.com/blog/smb-direct-the-state-of-rdma-for-use-with-smb-3-traffic-part-i
-
Happy to follow your lead and contribute where I can. I haven't worked with SR-IOV previously. I have an 82599eb card on the way for my main system so I'm mostly interested in eeking out the best performance I can from that. But I'll continue to have a test server with MLNX ConnectX-2 adapter - I'm happy to continue doing testing/benchmarking/assisting where I can. edit: Feel free to incorporate anything from my post. I'm not sure about the best way to organise this. It certainly makes sense to have a single document that outlines all the different options / possible methods for each step - but it can be a little difficult to follow. It would probably be easier for readers if we had a set of end-to-end instructions for each kernel driver (I'm assuming the variations in requirements are common to the kernel driver being used?) That was my thought in making the Mellanox post (and repeating a lot of your work)
-
It can be done, but not if you use DHCP for your WAN interface. If you have a static WAN IP, you can assign RFC1918 addresses to both WAN interfaces and use your actual WAN IP as the CARP interface address. Not much of a guide, but some discussion on this here: https://www.reddit.com/r/PFSENSE/comments/cvmefu/pfsense_carp_with_one_wan_ip/ If haven't used pfsense CARP for many years, had a lot of issues getting it working. I think it's improved since then though.
-
I'd strongly recommend slice size of 8MB configured in lancache-bundle and ZFS recordsize of 1MB zfs set recordsize=1M tank/lancache-dataset ZFS recordsize only applies to new files, and I'm not sure exactly what happens to existing lancache cached files when you change the slice size. Probably best to nuke and start again. I just had to reinstall all my dockers and unfortunately I'm unable to install now: Command: root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='lancache-bundle' --net='bridge' -e TZ="Australia/Adelaide" -e HOST_OS="Unraid" -e 'LANCACHE_IP'='192.168.0.252' -e 'DNS_BIND_IP'='192.168.0.252' -e 'CACHE_MEM_SIZE'='500m' -e 'CACHE_DISK_SIZE'='2000g' -e 'CACHE_MAX_AGE'='7300d' -e 'UPSTREAM_DNS'='1.1.1.1' -e 'USE_GENERIC_CACHE'='true' -e 'DISABLE_ARENANET'='' -e 'DISABLE_BLIZZARD'='' -e 'DISABLE_CITYOFHEROES'='' -e 'DISABLE_DAYBREAK'='' -e 'DISABLE_EPICGAMES'='' -e 'DISABLE_FRONTIER'='' -e 'DISABLE_HIREZ'='' -e 'DISABLE_NEVERWINTER'='' -e 'DISABLE_NEXUSMODS'='' -e 'DISABLE_NINTENDO'='' -e 'DISABLE_ORIGIN'='' -e 'DISABLE_RENEGADEX'='' -e 'DISABLE_RIOT'='' -e 'DISABLE_ROCKSTAR'='' -e 'DISABLE_SONY'='' -e 'DISABLE_STEAM'='' -e 'DISABLE_TESO'='' -e 'DISABLE_TWITCH'='' -e 'DISABLE_UPLAY'='' -e 'DISABLE_WARFRAME'='' -e 'DISABLE_WARGAMING'='' -e 'DISABLE_WSUS'='' -e 'DISABLE_XBOXLIVE'='' -p '53:53/udp' -p '80:80/tcp' -p '443:443/tcp' -v '/mnt/poolname/lancache':'/data/cache':'rw' -v '/mnt/poolname/appdata/lancache-bundle/log/named':'/var/log/named':'rw' -v '/mnt/poolname/appdata/lancache-bundle/log/nginx':'/var/log/nginx':'rw' 'josh5/lancache-bundle:latest' docker: Error response from daemon: failed to copy files: copy file range failed: invalid argument. See 'docker run --help'. The command failed. I did just switch to unRAID docker service using "directory" instead of "docker.img", not sure if that's related, but this is the only docker I've been able to reinstall. edit: Never mind, it's another ZFS issue - back to XFS docker image.

-
In case you're not aware: https://docs.netgate.com/pfsense/en/latest/recipes/high-availability.html
-
ps: There may be a nicer way of doing this, but I added some notes re: permanent MAC address assignment to my post above
-
Plenty of posts around from people attempting to passthrough entire network adapters - though usually out of a desire to virtualise pfsense, which I would always advise against (talk about complicating your network!) My use-case is wanting to get the best possible 10Gb SMB performance out of a Windows KVM guest (on ZFS storage) This may be a fools errand but I'm sure I will learn some things along the way. But yes, GPU SR-IOV is the killer use-case for all this. It's so frustrating that this feature is still missing, even on professional (workstation) cards. Perfect, thank you. /boot/config/go # Relaunch vfio-pci script to bind virtual function adapters that didn't exist at boot time /usr/local/sbin/vfio-pci >>/var/log/vfio-pci




