




live4soccer7
Members
-
Joined
-
Last visited
Everything posted by live4soccer7
-
Still no filling up of the docker.img. I'm thinking /tmp may have resolved the issue. I'll let it go for the next week before marking this as resolved. This has been bugging the heck out of me for a long time. It may be a little premature, but thank you everyone for helping me save my sanity.
-
Still no filling up of the docker.img. I'm thinking /tmp may have resolved the issue. I'll let it go for the next week before marking this as resolved. This has been bugging the heck out of me for a long time. It may be a little premature, but thank you everyone for helping me save my sanity.
-
Still nothing. Fingers crossed. There are several hundred jpegs in the tmp folder that was created, as suggested by @Gragorg
-
No issues today. I still believe it is every few days roughly. I'll post back up tomorrow morning.
-
Thanks, I'm giving it a shot. I haven't be up at 2AM when it happens so checking the docker size to actually see the culprit hasn't been much of an option. Now that I'm documenting it a little here if it continues to happen on a set schedule then I'll stay up or wake up a 2AM and check dockers sizes to see which one it is. It will at least give me more direction.
-
It happened last night. IMO, it has to be a local process to fill up 20GB that fast. My internet connection is not that fast for any kind of downloading. I added a transcode path to the /mnt/cache/transcode_plex and then set the transcode within the actual plex docker to /transcode Doing that, it can't be plex transcoding or processing. Is there an obscure log I can check to see what is doing all the writing at this time? I mean, it fills 20G roughly in 8 minutes and then clears itself.
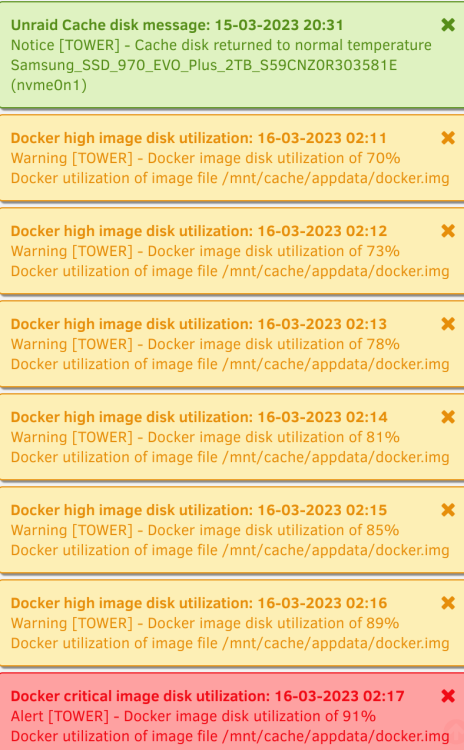

-
Would it do transcoding while "processing the library" on a scheduled task? I would assume to just transcode to a location on the cache disk would be best or should I try to push that to ram? Whatever it is, it is consuming at least 20GB during this time, for whatever reason
-
That could be the case and something I will look at, but it wouldn't explain why the docker image fills up around 2AM every few days. Plex is being watched here throughout the day and we are sleeping at 2AM. That coinciding with the "scheduled task" within plex itself.
-
Not a problem. Here we are: I think that covers what is relevant. There are a few more ports below the last screen shot, but I can't see how it would be a part of the issue.

-
I have had this issue where my docker image fills up every few night and then it stops doing whatever is happening and it reverts back to the size before these excessive writes. I strongly believe it is plex based off the library actions that happen every few days. It always happens at the same time around 2AM (plex, as shown below.....). I have roughly 20gb extra in my docker image. Any ideas or tests? I've looked at quite a few things over the last year or so and I just can't quite pin it down other than I have a very strong suspicion it is plex. I have tried looking at logs and I wasn't able to find anything indicative of this issue, but I may have been looking at the incorrect logs. I am sorry to start another docker image filling up thread. I really have put in a lot of effort trying to resolve this. There is nothing out of the ordinary in the sizes, IMO. Name Container Writable Log --------------------------------------------------------------------- deepstack 4.28 GB 483 kB 1.19 MB anaconda3 3.98 GB 340 kB 52.2 kB office-document-server-ee 3.35 GB 345 MB 3.60 MB GitLab-CE 2.46 GB 0 B 21.1 MB MakeMKV-RDP 2.45 GB 22.8 MB 188 kB digikam 1.77 GB 625 MB 140 kB Collabora 1.54 GB 36.4 kB 199 kB deepstack-ui 1.40 GB 289 kB 1.93 kB binhex-readarr 1.29 GB 135 MB 8.28 MB Krusader 1.26 GB 32.5 MB 96.8 kB HandBrake 1.15 GB 99.0 MB 172 kB binhex-delugevpn 1.14 GB 3.14 MB 37.5 kB double-take 995 MB 55 B 2.99 kB Nginx-Proxy-Manager-Official 905 MB 13.9 kB 7.88 kB macinabox 899 MB 3.43 MB 39.7 kB Rocket.Chat 875 MB 0 B 47.2 kB openhab 847 MB 149 MB 3.72 kB chia 745 MB 1.62 MB 5.13 kB Sonarr 738 MB 97.5 MB 855 kB luckyBackup 719 MB 2.04 MB 8.92 kB plex 713 MB 64.1 MB 1.13 MB MongoDB 698 MB 20 B 6.65 MB binhex-syncthing 693 MB 1.81 MB 17.0 kB code-server 630 MB 316 kB 25.8 kB Ghostfolio 565 MB 1.34 kB 64.1 kB NodeRed 535 MB 0 B 13.2 MB matrix 484 MB 29.7 kB 102 kB nextcloud 444 MB 35.0 kB 36.0 kB lidarr 406 MB 140 MB 9.23 MB postgresql14 376 MB 63 B 1.54 MB Influxdb 308 MB 2.83 kB 1.57 GB mariadb 293 MB 16.5 kB 55.6 kB FileZilla 215 MB 0 B 21.1 MB Grafana 206 MB 0 B 767 MB Beets 200 MB 0 B 21.1 MB bitwardenrs 193 MB 0 B 3.73 MB Headphones 192 MB 22.1 MB 5.48 MB radarr 190 MB 19.5 kB 263 kB flame 179 MB 0 B 3.31 kB sabnzbd 177 MB 20.3 kB 4.58 MB redis 164 MB 68.4 MB 20.2 MB heimdall 127 MB 41.7 MB 4.89 kB netbootxyz 84.7 MB 11.1 kB 6.35 kB element-web 69.2 MB 769 B 8.70 MB Authelia 50.0 MB 190 B 7.37 kB Cloudflare-DDNS 36.3 MB 5.81 kB 3.16 MB synapse-admin 29.3 MB 1.09 kB 54.4 kB MQTT 25.7 MB 0 B 1.24 MB --------------------------------------------------------------------- Total size 41.1 GB 1.86 GB 2.50 GB
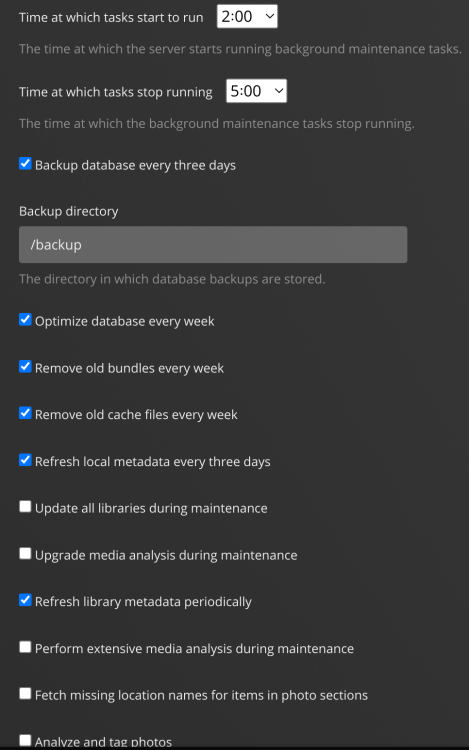
-
Anyone have permission issues with imports? I was able to import my library just fine, but when it downloads something in sab it is unable to move it from the download folder to the "music library" folder. Lidarr can see but not access downloaded track /downloads/music_files_from_sab.flac. Likely permissions error. I have changed the files and folders in that downloads directory to 755 and also tried 777, however the result is the same. I have no issues with sonarr, radarr, etc.... so I'm a bit baffled on this. I have tried looking at logs and every setting I can think of, however nothing has resulted in any success. It's almost as if the user/group is not correct with lidarr. It is set to the default for the docker. The recent downloads (since installing lidarr) are nobody users dwrxwrxwrx This is the same as the existing library that it imported from the array. checking lidarr's config folder in cache/appdata/lidarr the files in the config are all given nobody users I'm baffled edit: resolved. It was the destination path that was having permission issues due to permissions from older version of unraid way back. Changed permissions and user:groups recursively on the destination and it resolved it.
-
@Beardmann Do you know if the second IOM module can be pulled while the unit is powered up and being utilized?
-
Thanks! I did end up getting a DS4486 (I think that's the model number for the 48 disk shelf). It's been awesome and I would agree with you. Mine has 4 power supplies and I think 2 IOM. IOM6 is plenty fast for my needs.
-
I've noticed that my cache drives will get quite warm and there are lot of writes at this time. It's no from mover or large known file transfers. I'm not quite sure how to pin down what may be causing this. It happens at what feels like random times in the day. Sometimes at night, sometimes during the day or evening, etc... It happened yesterday and nothing was downloading large files unless something is happening in the background. Any tips/tricks on trying to find what is actually writing to the cache?
-
Hi all. I have a question for those that either know or have experience with this. I don't really care about the noise that these units output since they are in a "server closet". I already have the front fan shroud installed with the 3x140mm fans. Those running at 100% helped drop the hdd temps about 5-6C with a room ambient temperature of about 80-85F. My question is if I were to replace the fan wall in the middle with 3x120MM Notctua 3k rpm fans, would this help increase airflow or is it more or less just to help quiet the unit?
-
@afsilver I am getting a similar issue as well. I had a recovery and everything is back online except mariadb. Did you ever find a resolution? I'm no noobie, but I haven't been able to resolve this one yet and it would be great to get my dbs back online. This worked for me: http://raafat.tawasol.net/mysql-crashes-io-error/#:~:text=This means that you have,least the last one is
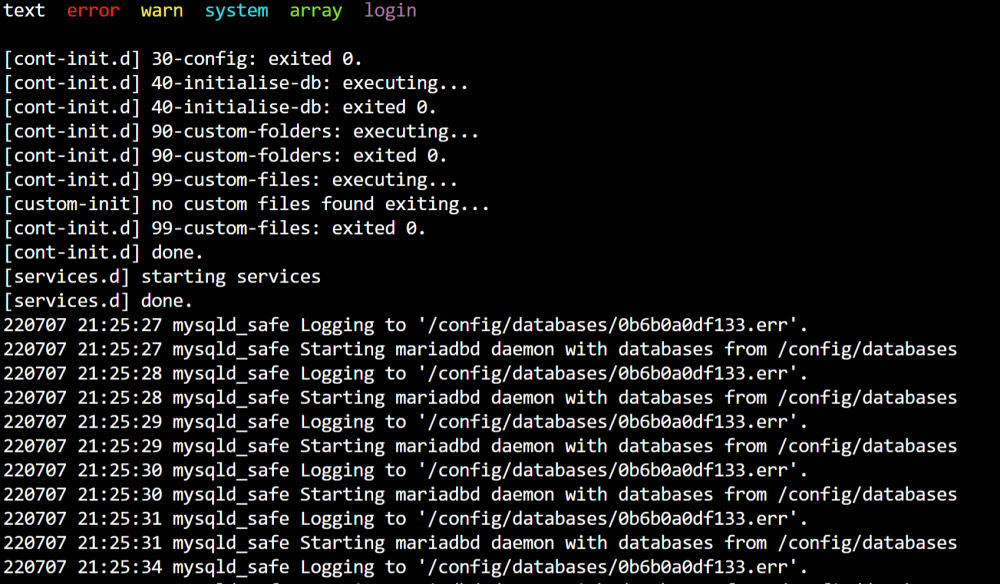
-
I do have a lost and found share. What is one to do with all that? lol
-
Where can I check that?
-
Thank you everyone so much! That worked like a charm. I got lucky. That saved a bit of time in reworking my dockers/setup etc... from my previous backup. I was able to assign it to the cache, put it in maintenance mode, run the fs_check/repair, and then start the array and it was all there as if nothing happened.
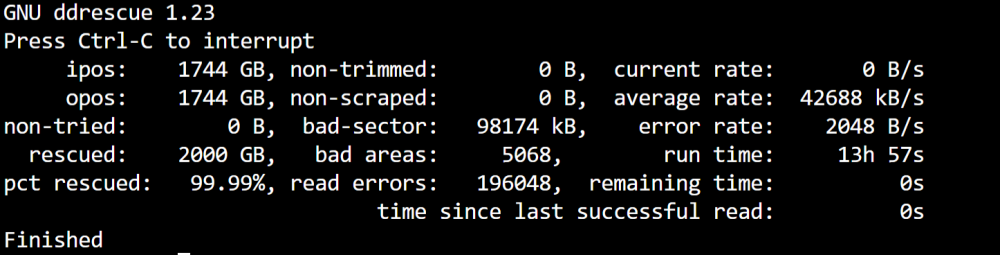
-
It looks promising. If I can get it mounted, I can live with .01% missing/corrupt
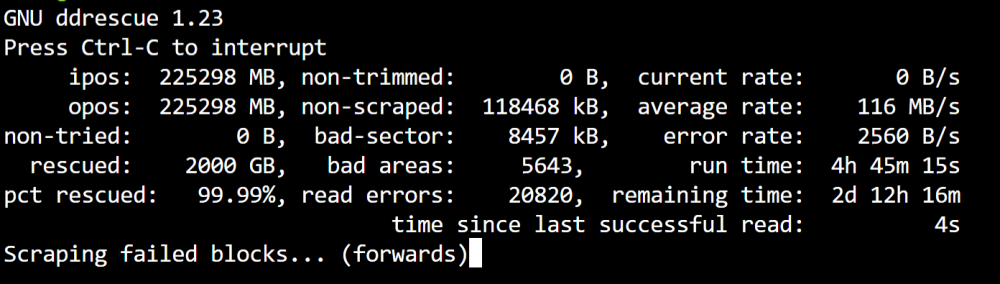
-
Thanks! Running ddrescue now. fingers crossed!
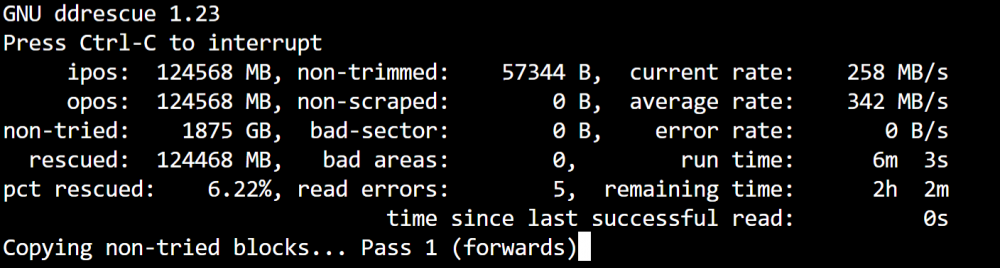
-
What would be the preferred program or method to clone it? I am handy and comfortable in terminal if it is possible clone/copy it to the array or I can move it to a windows machine and clone it to a mechanical drive there. Thanks.
-
I think we went through all of that earlier in this thread. It yielded no successful results in changing permissions.
-
This exact thing happened to me as well. The only way I could fix it was to delete the docker and all the files for it in appdata and install a completely fresh setup. Luckily, there wasn't much to config for it so it was easy. I haven't addressed the other docker that was having problems and now I can't remember and can't check because my cache drive just failed last night.
-
Ok. thank you for clarification. This drive will get RMA'd for sure. It is just over 1 yr old. If using a recovery tool like UFS, would this impair the ability to clone the drive? Just wondering which one I should attempt first.











