




live4soccer7
Members
-
Joined
-
Last visited
Everything posted by live4soccer7
-
Thank you very much. That did the trick!
-
I recently had to transfer files off of an old time machine backup directly in order to recover some media. In order to access these on the mac machine that I access this information I needed to change the permissions of the files. I then transferred them from the MAC to my unraid share. I can see 2-3 levels deep in the folder structure and then nothing else shows up when I try to drill down deeper with a file explorer (windows and linux have been tried). If I go to MC or use the unraid webgui file explorer then I can see everything as you would expect. I changed the file permissions and ownership once the files were in unraid to nobody users 666. I'm sure I'm missing something simple. Here is a directory and file that are not viewable on an OS GUI file explorer (NFS/SMB). drw-rw-rw- 1 nobody users 90112 Oct 18 2018 20170915-180740/ -rw-rw-rw- 1 nobody users 311759 Sep 13 2017 IMG_1682.JPG
-
That option makes sense. I'll take a look next time I reboot the system. I just know I've messed around in the bios and never been able to get it to boot with unraid without manually selecting the option highlighted in the screenshot. You can see the machine/server try a bunch of options as it will quickly cycle through the boot sequence from the bios and then will hang, making a forced power down the only way to recover. My main concern is I can't have the machine boot back up after a power outage due to this. I do have a large UPS, but that will only keep me going for so long during an extended outage and I may not be around to manually boot the server up and select the right boot option.
-
The only one I am actually aware of is the 850 1TB and that is a drive added in unassigned drives that is dedicated to a VM.
-
It would be before unraid is booted/recognized. This is simply a question out of ignorance on the topic. This would be a similar screen of a boot menu.
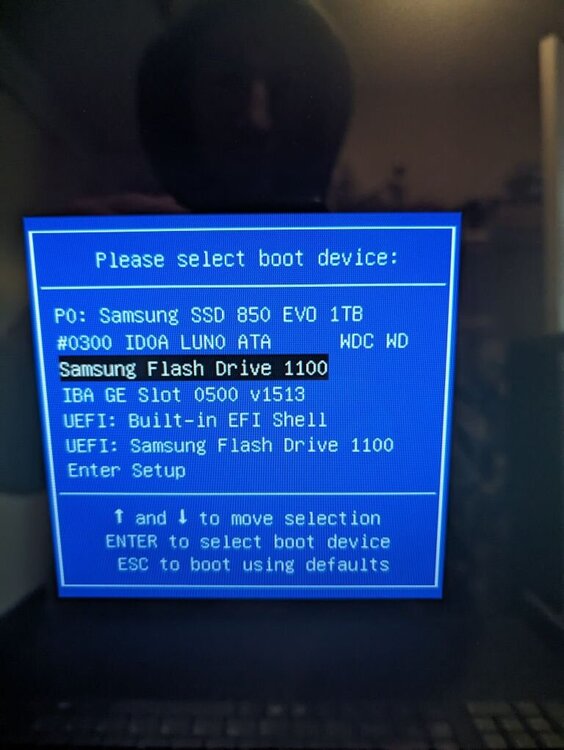
-
Many many updates ago there was a bug, I believe, that duplicated boot options. Now when I reboot the system there are multiple of the same option and the system will hang on reboot unless I smash the boot menu button and select the proper option. I have tried going into the bios and disabling/reordering the media options, but I'm not able to find a way to actually remove boot options from the menu. I'm on a supermicro system. I've never had to mess with this before and I didn't see anything clear on how to do this when searching around online. Any pointers/tips?
-
I also have permission issues as well. For example on the matrix docker, the permission user/groups is changed and code-server is unable to view/edit these files. Is there a way around this or to add additional users/groups?
-
Thank you very much.
-
This was asked in 2019, but I didn't see a response. Can anyone answer these questions? They do seem quite important in regards to behavior. "I have a question about a setting: In the "Docker Auto Update Settings" settings tab, there is the setting "Time to wait for docker graceful stop before killing". What unit of time does this use? Seconds or minutes? What command is used for a graceful stop versus killing? Does it kill docker or only containers currently running? Thank you!"
-
I have some OLD containers/apps installed from linuxserver and it seems their repository link changed sometime over the years. It does seem they may be forwarding the old link to the new one. OLD: linuxserver/mariadb NEWER: lscr.io/linuxserver/mariadb can I just replace the old with the new without issue?
-
Matrix Server. What is the best way to go about being able to edit the config files? I know it is a permissions issue since 991 is applied, but I'm unable to edit the files unless I'm signed into console as root and nano into the file. I can't edit them or copy them to my local pc or view them in something like codeserver. Thank you for any tips on this.
-
ahhhh..... Thank you very much. One less thing I need to look at during the "house cleaning" process.
-
@JonathanM I'm not sure I understand. Is that a question?
-
Thank you. Moving them now. Quick question if you see this. For whatever reason under /mnt I have /user and /user0. Any ideas on why/how this would be? Or is this associated with actual users created in unraid and just named arbitrarily in the FS? I'm trying to FINALLY do some house cleaning. ha
-
I have several 3 and 4 TB disks and I want to consolidate them to some 10TB disks I have that are already a part of the array. Is it best to move the contents of a 3TB disk (disk 2, for example) to a 10TB drive (disk 10) through the file manager or just use MC? They are all a part of the array. Moving from disk to disk, specifically and nothing to do with shares. I have probably 6 disks that I want to do like this. I'm just removing some old ones that have been in there for AGES, freeing up space, and reducing power consumption.
-
When I reboot again, I'll let you know. Thank you.
-
I did a fresh install on a new usb and simply copied over the config from the zip. The result was still the above.
-
Here is my result
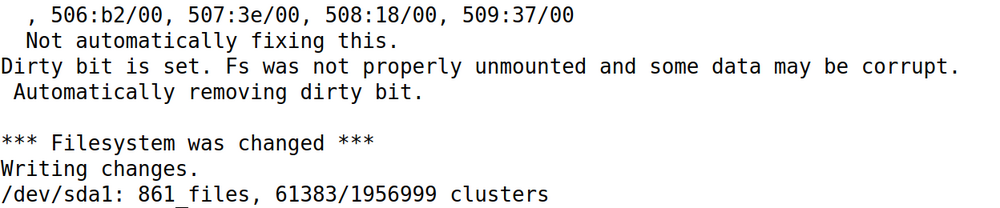
-
This doesn't really have to do with why the system went down, but perhaps a side effect of it going down uncleanly. lsscsi to get list of devices Confirm your device and run the following in your unraid terminal fsck -y /dev/sda1 I got this from reddit:
-
Here are some more shots.
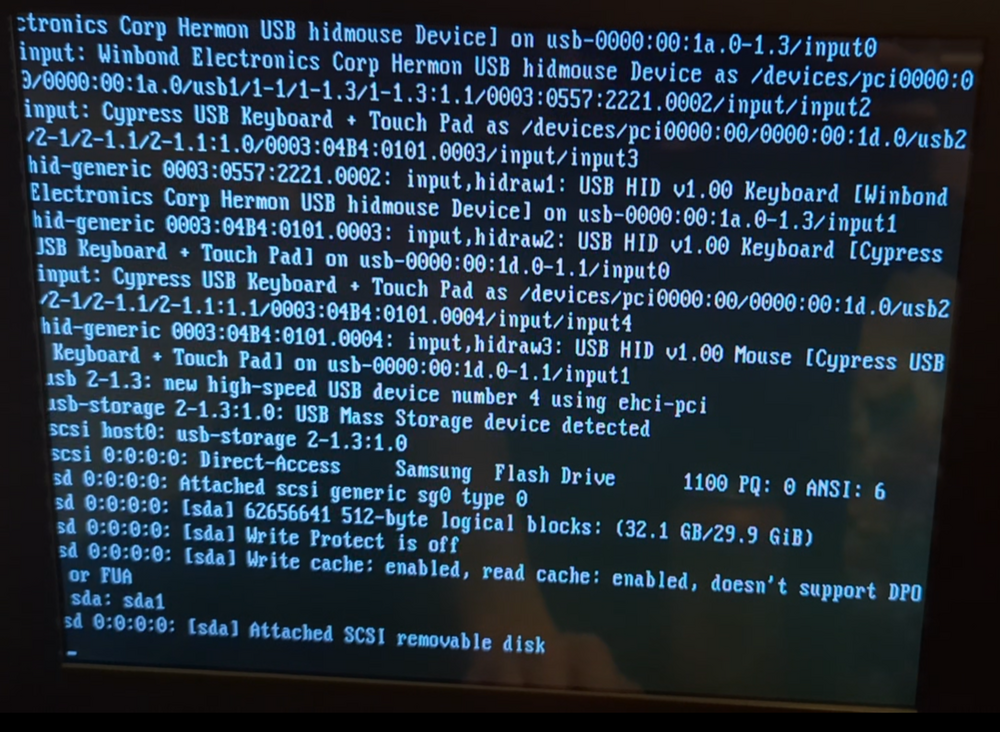
-
Well..... I highly doubt it is the USB unless a file in the config folder is corrupt. I did a fresh install on a new usb drive that was confirmed genuine by the manufacturer and the error on boot is the same. I then tried booting from a different USB slot with the original usb drive and the error persists. This is either something in the config folder that's messed up somehow. I am sorting through the video of the boot to see if I can find what's right above this. It paused here for a few seconds and I had time to snap a quick photo. Any ideas at all? The first photo is the very last frame before the "errors" in the second photo fly by.
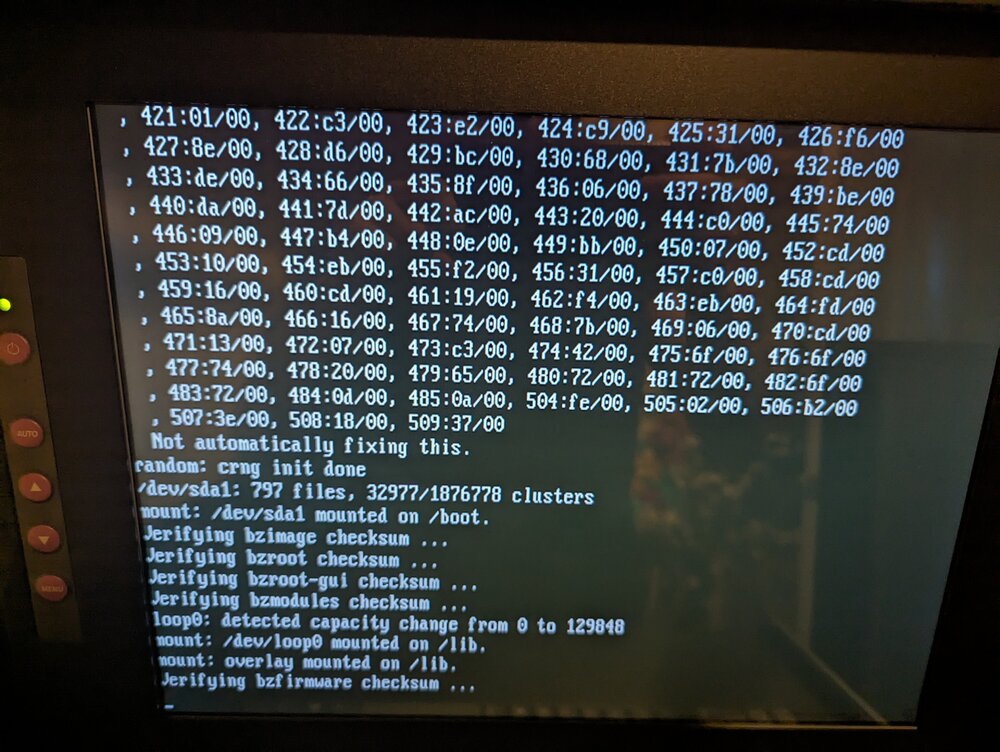
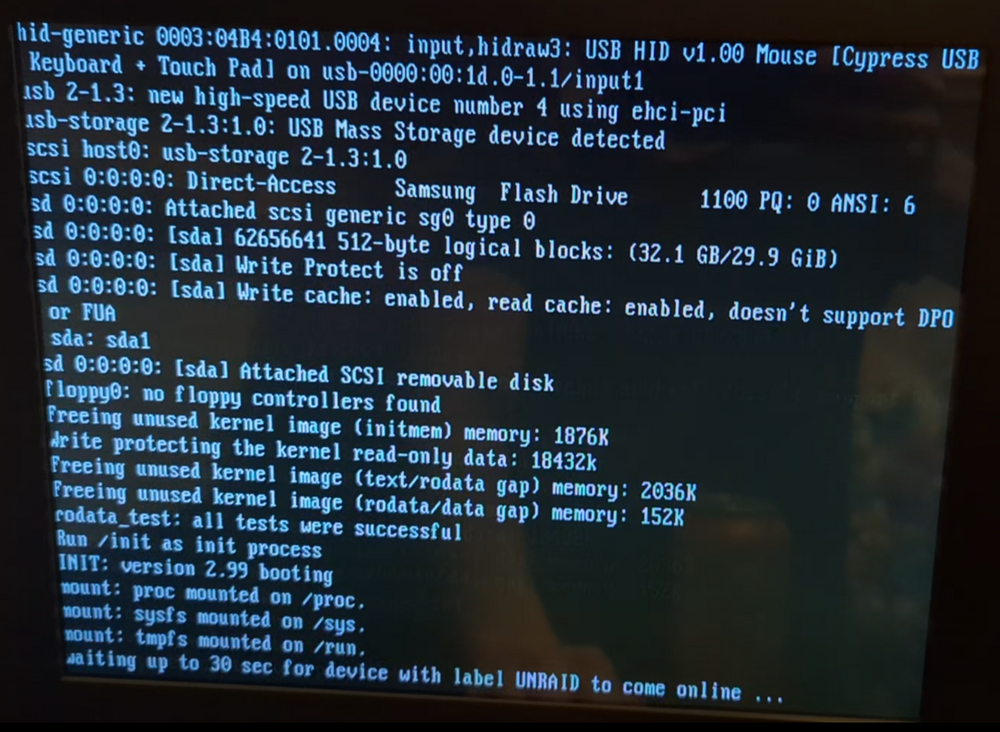
-
I ended up picking up an hpe enterprise and swissbit. I'll run a test on them to check things out. Swissbit will be the primary since the one I got is SLC as opposed to pSLC of the hpe enterprise. Regardless, this will end the usb issues for me and I can sleep at night. There are quite a few essential things running on the server.
-
Anyone tried one of these? It's USB 😂 I've been trying to find if it has a single GUID for the USB drive itself. edit: from what I can see from further research, this can not be used outside of ESXi https://www.ebay.com/itm/235089699698?epid=13034394641&itmmeta=01HXPRXH7Z76JV7PQ2AAV8BD9T&hash=item36bc702372:g:WgkAAOSw5Elj7Tqy&itmprp=enc%3AAQAJAAABEFSK1UgDTSmq%2F5aDQtQo68VrRDKaIDQv5RQzURJoI%2FSW8iV56SJUaG7LwwwlQUJnoVd7HOKMBFC220PXKf%2FOasZ9wZw6JudmyWQfB8j3ZOC0FTMmdgBE%2FOc%2FtNf8CRtyRlt65Pw7%2BBSwpJZuaf8BsFifwr1%2FK3Oz6CbDFpmO%2F4loxix1tA1xy%2Fie3ONIDOd2wjdSv0FQ832lBA%2FVgjQ%2FadHdJwaEoi%2FCG79lYLc8JpjWYwjuLCKEuZGvweefCHHOHjL0FlkxveVY6iHqoCYLdiZJXDJfW6wPZ2M5D6kUaMsErXYBMCSAgJzReu%2B0McyS66xNYJR%2F5kheeSg4FBfcorc0m%2BYn5COVsgZt1wfu%2BGyX|tkp%3ABFBMnpT22O1j
-
I just want to confirm, if that's ok. If I go ahead and create a new USB drive with a fresh image to make sure there aren't any bad bits (at least best chance). I would just copy over the config folder from my backup to the newly created flash drive, correct? I think this method may be better than creating the new usb drive fully from the backup.zip file.
-
I thought about this as well, but not sure there are any others internally on the server. I'll take a look. Are there any plans at all to be able to use something other than a USB drive? They are purely made like s*** these days. My last USB was still good after running unraid for 10yrs, but just become too small, 1GB, to upgrade.





