ars92
Members
-
Joined
-
Last visited
Everything posted by ars92
-
Hopefully kernel 6.18 really does have support for SR IOV XE drivers, when using ADL.
-
Seems like the Xe driver being part of the kernel is now planned for kernel 6.13 which may release around February 2025. And not sure when will unRAID support 6.13 as its now bound by the supported kernels by ZFS. https://github.com/intel/linux-intel-lts/issues/33 Hopefully we will have native Xe SR IOV support in unRAID for 14th gen Intel by mid next year, but a lot of things needs to fall in place for that to happen
-
Just to confirm, SR IOV doesn't make it possible to use the iGPU with Docker containers (example Plex for HW transcoding) and also multiple VMs passthrough, at the same time correct? We have to choose either one?
-
Thanks Kieran, it works perfectly 😊 Hope you had a good vacation!
-
There is a new version of yt dlp, how do we update it within pinchflat?
-
Hi there, would like to check how is the stability of your system now, with unraid 6.12.6 which should fully support ryzen 7000? Was thinking of getting threadripper 7960x to replace my 1920x but I think I'm gonna need to go with just the normal ryzen considering the limited Mobo and general availability of parts for threadripper this time around.
-
Thanks JorgeB as always. Will keep an eye on the disk in case anything funky happens in the future.
-
Thanks @JorgeB, attached the specific disk SMART report. I ran a short self-test (which showed as pass) right before downloading the report. WDC_WD80EFAX-68KNBN0_VDH6GBBK-20231119-1818.txt
-
So I was using my NAS and doing some file ops on Windows when trying to delete a specific folder caused a lockup on any transfer. Restarted laptop trying the same thing, but this time even the server stopped responding on webGUI. After a hard reset, starting the array didn't work as it was stuck on mounting disk3 Restarted server in maintenance mode and followed another unraid forum post recommending to run xfs_repair, and below is what I got after running a -vL through the webGUI check (had to use -L as it forced me to empty the log, and I went ahead as it was recommended on the other post too) After the below I started array, everything is fine, but I now have a lost+found folder (sized 13.69MB) with files I cant recognize. Should I be worried that the disk may be failing? But a FS repair worked so I only had an FS issue rather than a failing disk right? Should I do/check anything else? xfs_repair_disk3.txt
-
awesome stuff @VRx! I'm just wondering, since I need to use RPZ (Response Policy Zone) to rewrite certain URLs to a different IPs, do I need to do this manually (create the rpz file and add it to named.conf)? As I dont see such a function through webmin.
-
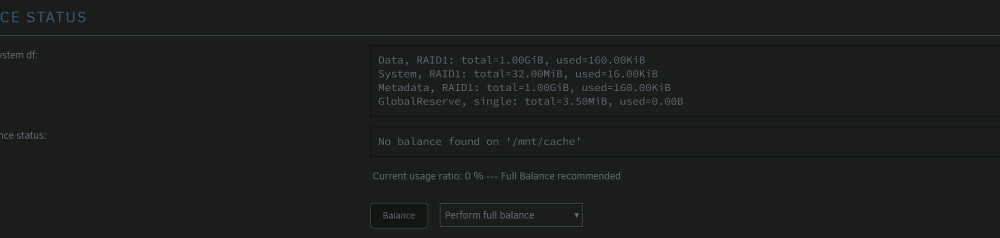
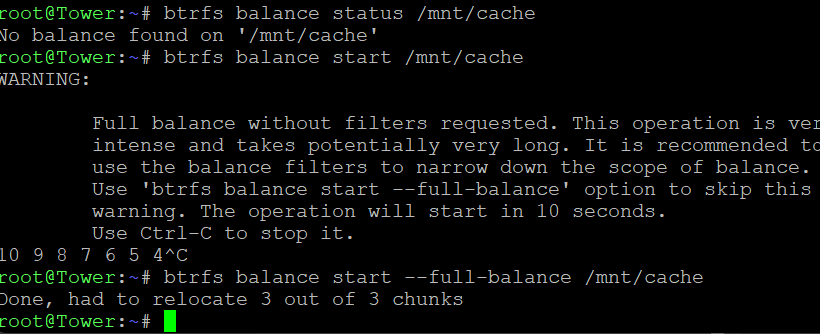
Thanks JorgeB for the prompt reply. Sure enough, today the SSD has turned read only, at least I'm not able to start any of my VMs anymore. Managed to copy files out two days back from the VMs (since some of the Vdisks weren't able to be copied out in its entirety) and the app data backup was already there due to CA Backup (thanks Squid for this!!) Planning to get a pair of Crucial P5 Plus, since my two Evo Plus' 5 year warranty ended two months ago in June....lol SN700 seems fun but way too expensive in my country for some reason..... ========================================================================================================================= So I've gotten the replacement SSD, got the disk replaced without doing any reassigning etc. since the old drives have nothing useful anymore. Everything looks good, docker service is back up, but this is worrying me a bit. I have setup scrub and balance to run monthly now, just in case it helps in the future (I will setup the script suggested by JorgeB soon) but when I run "perform full balance" the page refreshes almost immediately (maybe due to nothing in the disks) but the recommendation doesn't go off. I then tried running the below CLI command and I get the below, but the GUI still shows the same message. Should I just ignore this?
-
Thanks JorgeB for the prompt reply. Sure enough, today the SSD has turned read only, at least I'm not able to start any of my VMs anymore. Managed to copy files out two days back from the VMs (since some of the Vdisks weren't able to be copied out in its entirety) and the app data backup was already there due to CA Backup (thanks Squid for this!!) Planning to get a pair of Crucial P5 Plus, since my two Evo Plus' 5 year warranty ended two months ago in June....lol SN700 seems fun but way too expensive in my country for some reason.....
-
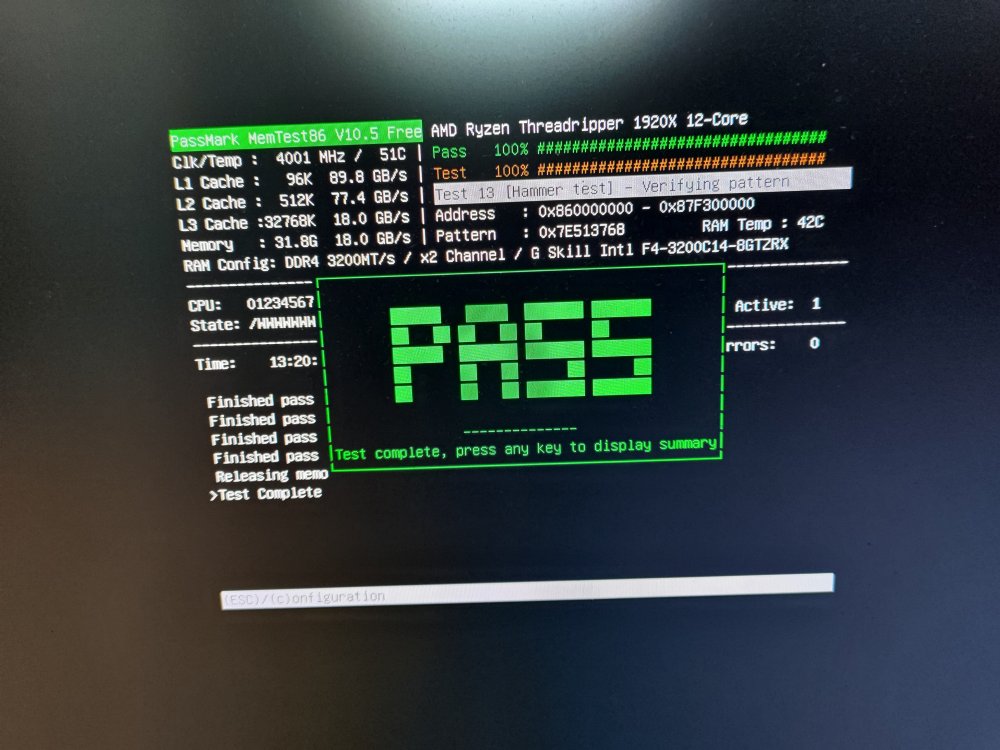
hey all, First time having a potential hardware issue, so I apologize if I missed certain prerequisite details. My server has been running just fine for a long time, even replaced a disk a few days back by upgrading parity and using the parity disk as a disk drive. Everything has been great even after that. But last night, docker started acting weird and I noticed errors in my cache pool when I downloaded the SMART report. i ran a memtest which went on for 13 hours for 4 pass, and it passed so I guess the 4 RAM sticks are fine. The vdisks aren't able to copy into my array after a certain point so I guess they are corrupted. Good thing my appdata backs up every month using CA Backup. I just want to try to understand if my M.2 drives are going bad and I should purchase some new ones, or should i try my luck by reformatting and using them back again. Attached diagnostic after running scrub (which couldnt correct any of the errors) and also a command which JorgeB recommends to run (shows a whole lot of errors!) Also attached SMART report from both cache disks. I cant do any cable checks since they are M.2 connected directly to the motherboard. I have a third drive used as an unassigned disk, which seems to be fine for now (ADATA drive bought a few years after these two) from scrub page UUID: d7811189-42b8-4d37-a4d0-dae7ee9e73f6 Scrub started: Tue Aug 15 21:03:35 2023 Status: aborted Duration: 0:09:38 Total to scrub: 478.01GiB Rate: 833.38MiB/s Error summary: read=135 Corrected: 0 Uncorrectable: 135 Unverified: 0a root@Tower:~# btrfs dev stats /mnt/cache [/dev/nvme0n1p1].write_io_errs 0 [/dev/nvme0n1p1].read_io_errs 130 [/dev/nvme0n1p1].flush_io_errs 0 [/dev/nvme0n1p1].corruption_errs 2 [/dev/nvme0n1p1].generation_errs 0 [/dev/nvme2n1p1].write_io_errs 354329 [/dev/nvme2n1p1].read_io_errs 339856 [/dev/nvme2n1p1].flush_io_errs 1334 [/dev/nvme2n1p1].corruption_errs 2806 [/dev/nvme2n1p1].generation_errs 0 root@Tower:~# tower-diagnostics-20230815-2115.zip tower-smart-20230815-2130.zip tower-smart-20230815-2131.zip
-
Container is showing as "not available" for me while other dockers are fine. Anyone else with the same issue?


-
I do not know if this would help you guys who are trying to use Nvidia GPU on an OS newer than High Sierra, but the below worked for me for each and every release (up to Monterey) the moment I made the change. Before that I always get a black screen, which blocked me from even trying to install OCLP to get graphic acceleration working with my 1070TI <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x0b' slot='0x00' function='0x0'/> </source> <rom file='/mnt/user/Downloads/Softwares/Galax1070ti.rom'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> The bolded underlined area was always 0x00 for me all the while, but I noticed that it was 0x03 on my High Sierra by default but 0x00 on anything newer, the moment I changed it, lo and behold, I got the nice, pixelated UI you get when drivers aren't installed OCLP works perfectly after that. The below was needed too, of course: How to Enable NVIDIA WebDrivers on macOS Big Sur and Monterey
-
For me the longer boot started at 6.8.3 and wasn't there in 6.7.0 and below. But it's not that big of a deal as its perhaps 10 seconds or so more.
-
Thanking the existence of this docker. Was about to get down and dirty on either trying to enable secured connection to Emby and Jellyfin which has been unsecured and accessible through WAN for a long time (crazy, I know!), saw it was kinda complicated, went and looked into reverse proxy as I am a network engineer by day, so I deal with this on a daily basis but with enterprise solutions. Nginx and others still seemed pretty involved and then this popped up through CA Settled both services through separate DDNS entries which sync to the CNAME of my router DNS so manual update of IP isn't needed, may still need to refresh my hostname every 30 days though due to it being a free account. This barely took a few minutes to set up, thanks again!!!
-
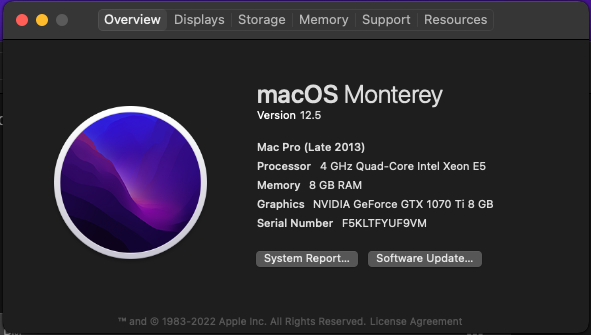
Love how well this has been working for the past couple of months. Thanks SpaceInvaderOne for creating an easy way for Unraid users to enjoy Mac OS!
-
It should work great according to this site - Intel GPUs | GPU Buyers Guide (dortania.github.io) Your issue sees to be something outside of the MAC OS/bootloader though. Try to make it work with Windows first and then see if you need to change anything to make it work.
-
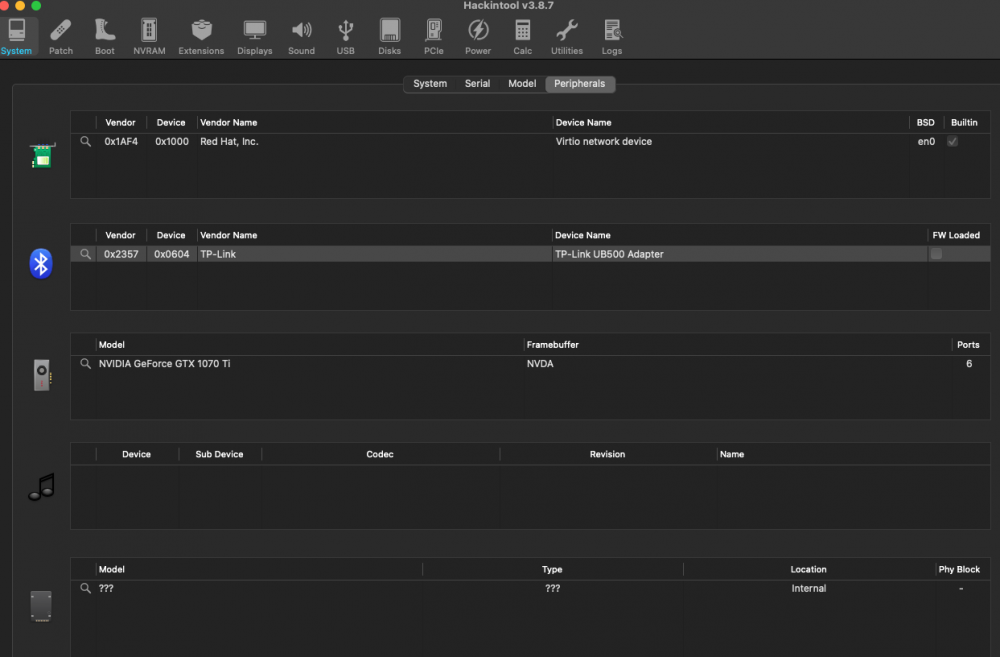
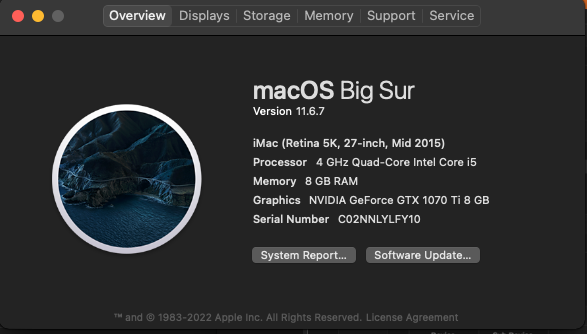
Happy to report that my GTX 1070 TI is working pretty well on Big Sur using OCLP. Will soon try Monterey to see if the same can be achieved. Mainly used elitemacx86 instructions, but also had to edit certain PCI slot values in the XML generated by Unraid/Macinabox or else I was constantly stuck on the UEFI screen. Basically made it the same as what I have working in High Sierra and it came right up. Love how my monitor USB hub works on my USB controller which is passed through to the VM, while the same doesn't work on High Sierra (it disables itself right after choosing my boot drive which signals something in OC not supporting it I guess, but not a big deal as I think I'm gonna get rid of High Sierra soon since Big Sur is working great!) Im trying to get Bluetooth to work though, and I can see the hardware in Hackintool but not in System Report. Still trying to figure out how can I get this to work, but something tells me its not gonna work since I don't see Broadcomm under Vendor Name here.... any thoughts?
-
Ah knew it, thanks for confirming that! Will try getting an img through my other Mac OS VM and retry
-
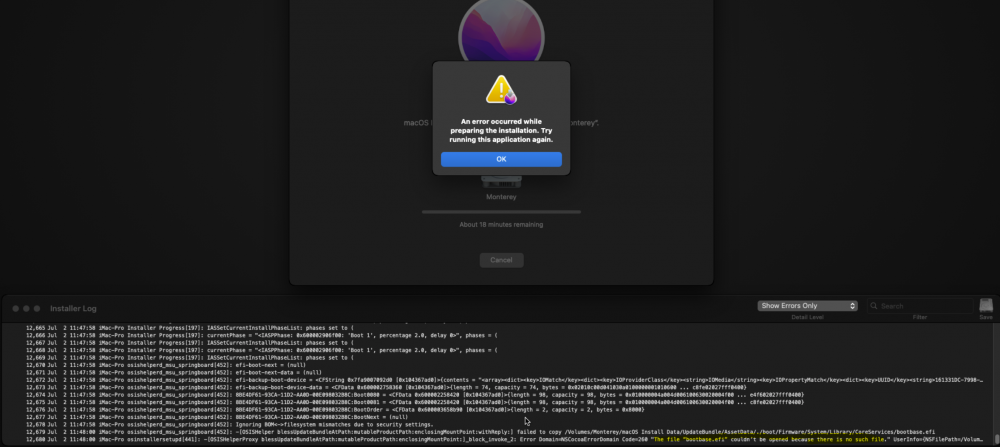
Hi all, I have High Sierra working pretty well for me so I'm simply trying to run Monterey now to see how it goes. I have another instance of Macinabox running (had to manually change the appdata location and also the userscript syntax to reference the new directory for this to work correctly) The installer runs pretty well until its around 24GB in size installed, and then I get below error. It seems like the bootbase.efi file is missing in the installer itself? Could it be an AMD issue as I'm using a 1st Gen Threadripper This is the img installer size, seems kinda small at 3GB but I've tried redownloading a couple of times.

-
This helped me, thanks!
-
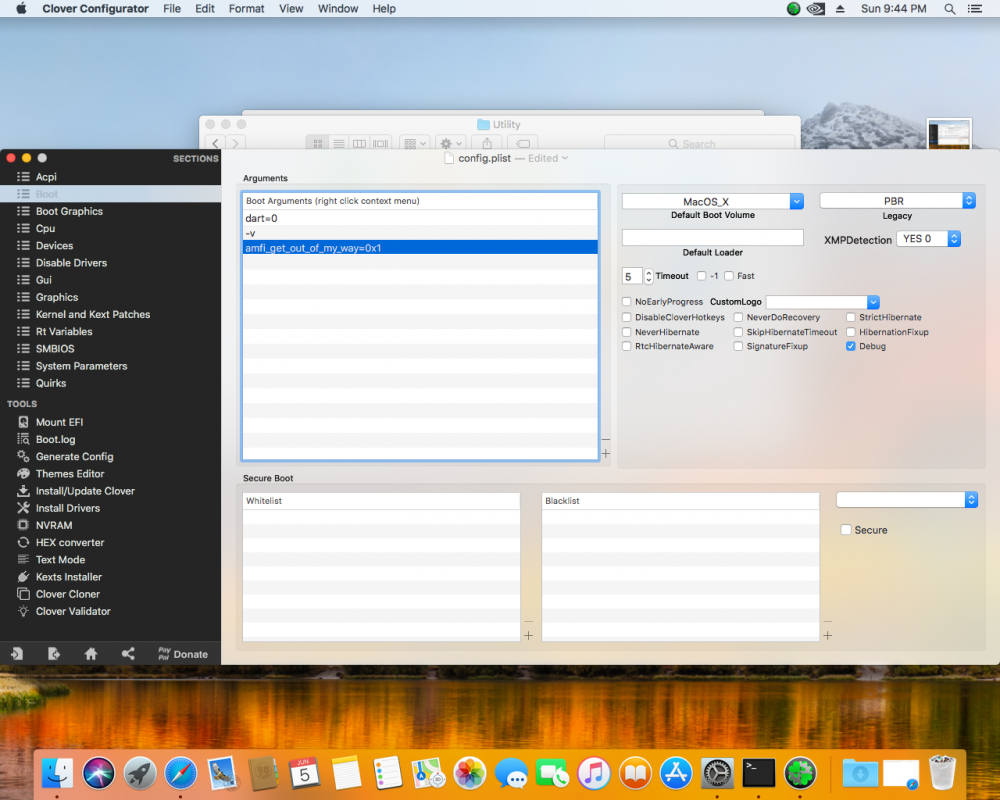
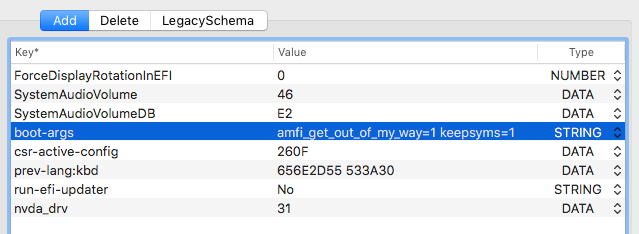
EDIT: Issue solved by using latest modified Nvidia Web drivers obtained through Tonymacx86 forum This is how my boot-args looks like, so I added the amfi line to the existing boot-args, and there is a space in between. Apart from that I can see that I already have Lilu and WhateverGreen kext included in the kext folder of Opencore so I didn't do any changes there. I also have the nvda_drv 31 input too, but it doesn't help. I did also try to repackage the installer using a cert stripper python script. This does help to run the driver installer but no difference after a restart.
-
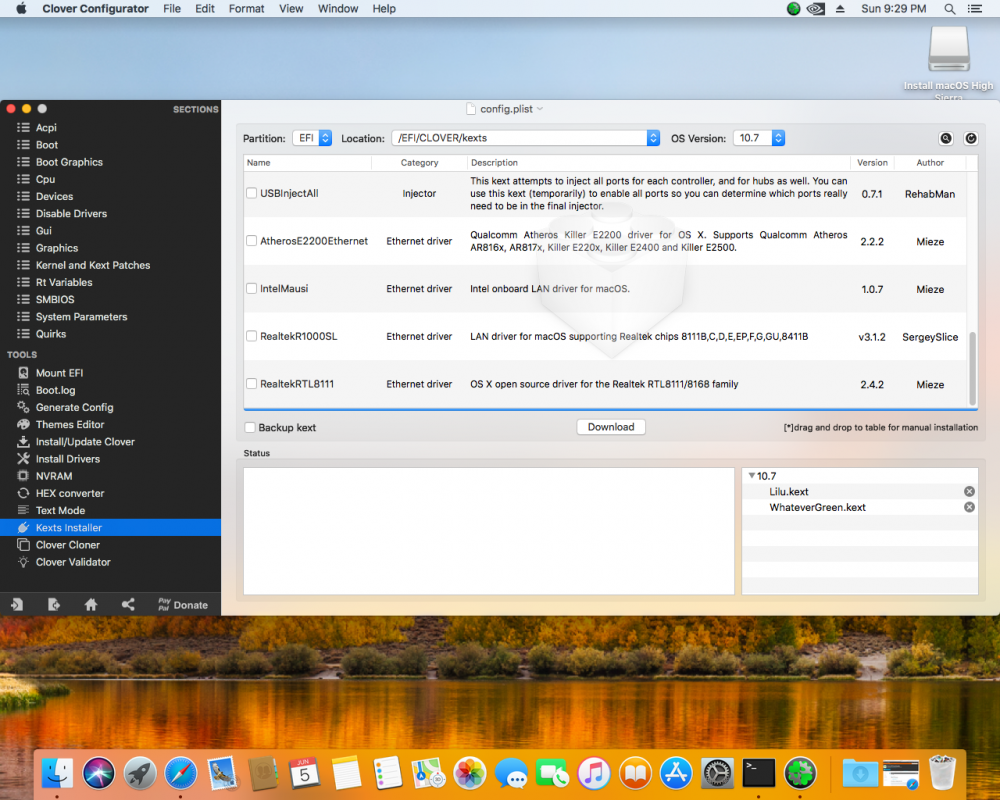
EDIT: Issue solved by using latest modified Nvidia Web drivers obtained through Tonymacx86 forum This is really good. I've got High Sierra working again after last having a working version in unraid 6.8 with Clover. Unfortunately Nvidia drivers had its certificate revoked as of 1st June, so any users using Maxwell with High Sierra are also affected. There is a solution as below taken from the Tonymacx86 forum but anyone here who has been working with Hackintosh and Unraid for a long time, can sort of look through this and also provide the Opencore configurator options for it? I can see some of the steps are written in a way that some one who has been working with this a long time will be able to figure out but alas I'm not one of them https://www.tonymacx86.com/threads/the-apps-authorization-has-been-revoked-high-sierra-nvidia-graphics-certificates-expired.320609/page-3#post-2324531 Update High Sierra till lates 17G14042 Cleanup NVIDIA Web driver (WEB-Drive-Toolkit From Github) Make this in terminal console: sudo chmod -R 755 /Library/Extensions/NVDAStartupWeb.kext sudo chown -R root:wheel /Library/Extensions/NVDAStartupWeb.kext sudo touch /System/Library/Extensions/ && sudo kextcache -u / sudo touch /Library/Extensions && sudo kextcache -u / Add boot arguments in clover configurator as in attached screenshot Add kext as in attached screenshot Reboot (If you have black screen add temporary boot argument nv_disable=1) Install official driver 387.10.10.10.40.140