




hamish_18
Members
-
Joined
-
Last visited
Everything posted by hamish_18
-
Looked at the communication logs on my phone. looks like I am getting a database schema mismatch error repeatedly. Not sure why for my account and not others. But, looking in to that. Most likely has nothing to do with my password, or the need for a device password. If that troubleshooting doesn't yield any results, I'll circle back to trying the device password.
-
I will try it. But, none of my other users need to, and this would be the first time. So if there was a change, then is it in the release notes? Otherwise, this would be more of a troubleshooting step, and/or workaround. I'll report back the results of the test.
-
What? a device password? Why would I need to do that now. I have never needed to before?
-
Has anybody run in to an issue with 30.0.5 and I don't know what ios version of the app, but the ios app is asking me to log in everytime I load the app up. I do, successfully it seems, but every page is empty. even the more page, where I believe it would tell me what ios version of the app I have... I tried upgrading to 30.0.6, and that made no diff. I also have some strange errors in my logs now from the 10th of feb? {"reqId":"aLkXDMX6KqpCia4dn29T","level":3,"time":"2025-02-10T21:20:16+00:00","remoteAddr":"","user":"user","app":"webdav","method":"POST","url":"/remote.php/dav/bulk","message":"Unknown error while seeking content","userAgent":"Mozilla/5.0 (Windows) mirall/3.4.0stable-Win64 (build 20211129) (Nextcloud, windows-10.0.19045 ClientArchitecture: x86_64 OsArchitecture: x86_64)","version":"30.0.5.1","exception":{"Exception":"Sabre\\DAV\\Exception","Message":"Unknown error while seeking content","Code":500,"Trace":[{"file":"/config/www/nextcloud/apps/dav/lib/BulkUpload/MultipartRequestParser.php","line":117,"function":"isAt","class":"OCA\\DAV\\BulkUpload\\MultipartRequestParser","type":"->"},{"file":"/config/www/nextcloud/apps/dav/lib/BulkUpload/BulkUploadPlugin.php","line":54,"function":"isAtLastBoundary","class":"OCA\\DAV\\BulkUpload\\MultipartRequestParser","type":"->"},{"file":"/app/www/public/3rdparty/sabre/event/lib/WildcardEmitterTrait.php","line":89,"function":"httpPost","class":"OCA\\DAV\\BulkUpload\\BulkUploadPlugin","type":"->"},{"file":"/app/www/public/3rdparty/sabre/dav/lib/DAV/Server.php","line":472,"function":"emit","class":"Sabre\\DAV\\Server","type":"->"},{"file":"/config/www/nextcloud/apps/dav/lib/Connector/Sabre/Server.php","line":43,"function":"invokeMethod","class":"Sabre\\DAV\\Server","type":"->"},{"file":"/config/www/nextcloud/apps/dav/lib/Server.php","line":371,"function":"start","class":"OCA\\DAV\\Connector\\Sabre\\Server","type":"->"},{"file":"/config/www/nextcloud/apps/dav/appinfo/v2/remote.php","line":19,"function":"exec","class":"OCA\\DAV\\Server","type":"->"},{"file":"/app/www/public/remote.php","line":146,"args":["/config/www/nextcloud/apps/dav/appinfo/v2/remote.php"],"function":"require_once"}],"File":"/config/www/nextcloud/apps/dav/lib/BulkUpload/MultipartRequestParser.php","Line":99,"message":"Unknown error while seeking content","exception":[],"CustomMessage":"Unknown error while seeking content"},"id":"67afb7316cbe4"}

-
Ok. I just figured it out /sigh. I haven't touched these settings in years, but my firewall's smtp protection is causing it? This ticket can be closed. I added my unraid IP to skip the SMTP proxy from looking at data from it. That was a new one.
-
That is super strange! I never changed anything either, and then all of a sudden, I noticed in my logs that I was getting those errors when trying to send an email. What version of unraid are you guys running? I am on 6.12.6 Just to re-iterate, this is what I get in my logs when I try to send a test email now: Mar 22 07:39:31 haymak3runraid ool www[333]: /usr/local/emhttp/plugins/dynamix/scripts/notify 'smtp-init' Mar 22 07:39:33 haymak3runraid sSMTP[1959]: Creating SSL connection to host Mar 22 07:39:33 haymak3runraid sSMTP[1959]: SSL connection using ECDHE-RSA-AES256-GCM-SHA384 Mar 22 07:39:33 haymak3runraid sSMTP[1959]: Server didn't like our AUTH LOGIN (503 AUTH command used when not advertised) My settings are in fact just like Amane's. I just don't get how google doesn't like this anymore.
-
I can get the settings. It's the amount of data that I would get is the issue I believe. plex and other things routinely send me emails.
-
I have shitty comcast, and I don't think they allow this. I guess I can try again. But gmail is really my only option.
-
Google is being less than helping, but it appears that we may need oauth2 support now? Is this something that unraid is working on? I'd REALLY like to get notifications from my server again.
-
Starting two nights ago around 2am, I am no longer able to receive email from my unraid server. I get this error: Mar 12 07:39:16 haymak3runraid ool www[13892]: /usr/local/emhttp/plugins/dynamix/scripts/notify 'smtp-init' Mar 12 07:39:18 haymak3runraid sSMTP[14113]: Creating SSL connection to host Mar 12 07:39:18 haymak3runraid sSMTP[14113]: SSL connection using ECDHE-RSA-AES256-GCM-SHA384 Mar 12 07:39:18 haymak3runraid sSMTP[14113]: Server didn't like our AUTH LOGIN (503 AUTH command used when not advertised) Checking my settings, nothing has changed, and mirror's other's from here. I also changed my app password to see if maybe that expired somehow?(It shouldn't have).. But that made no difference. I can't find anything other than this: https://support.google.com/a/answer/81126?visit_id=638458505878602168-168114250&rd=1#zippy=%2Crequirements-for-all-senders do you all think this is related? What are we to do, to start receiving emails again from unraid. Most likely this is impacting other services too. I started a community thread over on google, but don't have my hopes up very high that this will help anything. But one person stated that unraid will need to use oauth now?
-
I can start a new thread, but starting last night at 2am, I am no longer able to receive email from my unraid server. I get this error: Mar 12 07:39:16 haymak3runraid ool www[13892]: /usr/local/emhttp/plugins/dynamix/scripts/notify 'smtp-init' Mar 12 07:39:18 haymak3runraid sSMTP[14113]: Creating SSL connection to host Mar 12 07:39:18 haymak3runraid sSMTP[14113]: SSL connection using ECDHE-RSA-AES256-GCM-SHA384 Mar 12 07:39:18 haymak3runraid sSMTP[14113]: Server didn't like our AUTH LOGIN (503 AUTH command used when not advertised) Checking my settings, nothing has changed, and mirror's other's from here. I also changed my app password to see if maybe that expired somehow?(It shouldn't have).. But that made no difference. I can't find anything other than this: https://support.google.com/a/answer/81126?visit_id=638458505878602168-168114250&rd=1#zippy=%2Crequirements-for-all-senders do you all think this is related? What are we to do, to start receiving emails again from unraid. Most likely this is impacting other services too.
-
Can confirm, this is working again Thanks!
-
I too am having the exact same error as the above post. Should we revert back to a previous version?
-
Greetings. I am trying to troubleshoot an issue, but the docker seems to be missing a required package and so I cannot run splunk diag. Here is the error: libgcc_s.so.1 must be installed for pthread_cancel to work It appears I have no means of getting/installing this from the console. Any assistance would be greatly appreciated. Thanks!
-
Running 6.12.6 I too just came across this from having my dockers not available this morning. Ran diagnostics before power cycling as I couldn't get docker to respond or the webgui. Found the same errors in my logs as the OP. Will add this to my config, but also curious why this type of issue would occur in the first place.
-
Same issue as you. I've tried all sorts of different machine versions, and nothing is working Any other ideas?
-
I've been wracking my brain on this, and have found a bunch of articles close to this, but nothing specific. My ubuntu vm is 20.04, and I have found that loading the e1000 for network model seems to get a good nic loaded. I don't know why after the unraid upgrade that this has occurred, nor have I found information YET on why the e1000 model works. I do have intel dual nics in my unraid server... I also found that the vmxnet model from vmware also seems to work. You can also check that the vm sees a nic by running lshw -C network For me the virtio model yielded the nic as UNCLAIMED.. For vmxnet and e1000, the nic was DISABLED. So I could manually start the nic then. I then edited /etc/network/interfaces and changed the NIC to the correct one from the lshw command. For me, mine changed from ens1p0 to ens1. Also, at least your vm booted. It took me forever to figure out why the virtual disk was no longer working, and so the vm wouldn't even boot. Hopefully this helps a bit?
-
Just checking in to see if anybody has checked the logs at all?
-
here ya go. unraid-diagnostics-20230302-1509.zip
-
yes. when I stop vm manager. I see the proper 1gig file. but if I restart the system and everything attempts to come up, the old 1 meg libvirt file is in use. until I stop vm manager, and restart it.
-
I can fix the issue if it occurs. Now that I know what to do. It's almost like I have 2 different libvirt files now. If I reboot, the old 1.8M one is being used. I stop vmmanager, and start it up again, and it is now using the correct one. from df -h: /dev/loop2 1.8M 1.8M 0 100% /etc/libvirt They are different.
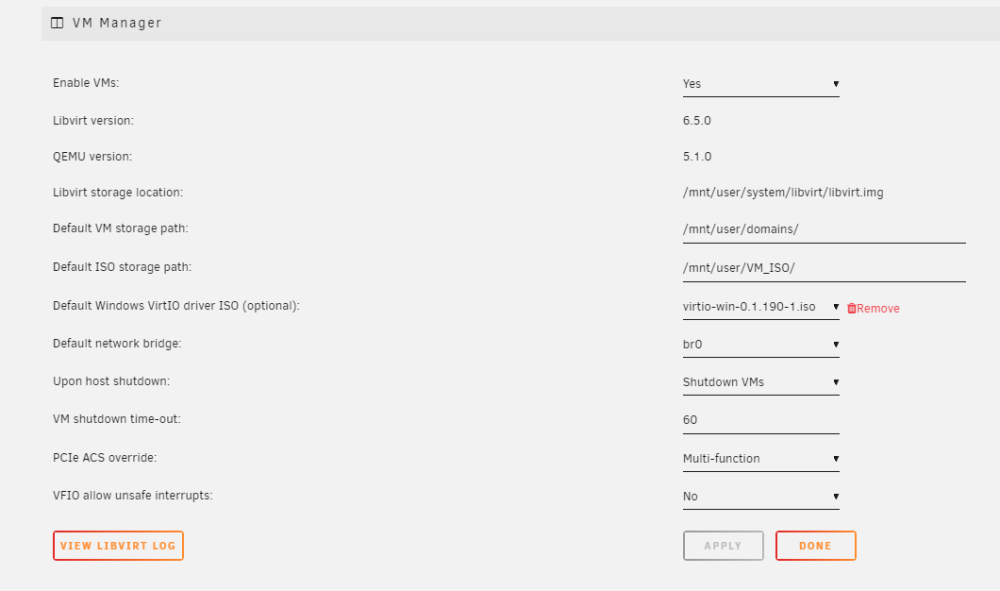
-
Something keeps changing it back. I change it to 1 gig, and to the appdata folder, and now when I look at df-h, it is back to 1.8M under /etc/libvirt.. Need to figure out where to fix this at.
-
Bumping this, as I just ran in to this issue again. Is there anything I can do here? Why is this only 1.8 Megs?
-
Well I still am not sure what happened, or if this has been a thing all along. I tried to delete and create a new libvirt.img file, and recreate the vm's. But after a reboot, the original is back and full. I then due to the error about files in the nvram folder, deleted them. which of course (now I know) those were not temporary. So recreate the vm's again, but with this weird (busted?) img file that is 1.8megs. It's 79% full, and I have 2 vm's left to re-create. Everything is up and running though.
-
Not sure if this is the right place to post this.. But I went to start a vm, and noticed that it was missing. I was doing some work on it, and had recently removed and recreated the template. I tried doing that again, and I got a no space left error. I checked a df-h, and I see that /dev/loop2 for /etc/libvirt is 100% full at 1.8megs?? in the libvirt log I see this: 2022-06-08 17:07:32.983+0000: 6964: error : virFileRewrite:537 : cannot write data to file '/etc/libvirt/qemu/Home_S1_PilotWin10.xml.new': No space left on device 2022-06-08 17:07:58.229+0000: 6963: error : virFileRewrite:537 : cannot write data to file '/etc/libvirt/qemu/Home_S1_PilotWin10.xml.new': No space left on device I don't have any errors in the system log about this. Why is that mount so small? And why would it be full? I haven't touched anything. The libvirt folder looks like this: /etc/libvirt# ls -l total 149 -rw-r--r-- 1 root root 450 Feb 23 2017 libvirt-admin.conf -rw-r--r-- 1 root root 518 Sep 27 2014 libvirt.conf -rw-r--r-- 1 root root 13800 Sep 27 2014 libvirtd.conf drwxr-xr-x 2 root root 1024 Feb 23 2017 nwfilter/ drwxr-xr-x 5 root root 1024 Jun 8 10:07 qemu/ -rw-r--r-- 1 root root 2169 Sep 27 2014 qemu-lockd.conf -rw-r--r-- 1 root root 18355 Sep 27 2014 qemu.conf drwx------ 2 root root 1024 Mar 5 2018 secrets/ drwxr-xr-x 3 root root 1024 Sep 27 2014 storage/ -rw-r--r-- 1 root root 1883 Feb 23 2017 virt-login-shell.conf -rw-r--r-- 1 root root 11687 Dec 11 2019 virtinterfaced.conf -rw-r--r-- 1 root root 2134 Sep 27 2014 virtlockd.conf -rw-r--r-- 1 root root 1997 Feb 23 2017 virtlogd.conf -rw-r--r-- 1 root root 11677 Dec 11 2019 virtnetworkd.conf -rw-r--r-- 1 root root 11677 Dec 11 2019 virtnodedevd.conf -rw-r--r-- 1 root root 11682 Dec 11 2019 virtnwfilterd.conf -rw-r--r-- 1 root root 16709 Dec 11 2019 virtproxyd.conf -rw-r--r-- 1 root root 11662 Dec 11 2019 virtqemud.conf -rw-r--r-- 1 root root 11672 Dec 11 2019 virtsecretd.conf -rw-r--r-- 1 root root 11677 Dec 11 2019 virtstoraged.conf what gives??

