




olympia
Members
-
Joined
-
Last visited
Everything posted by olympia
-
I am using v6.3.5 Sure yes, webgui is all fine. Sent from my E5823 using Tapatalk
-
Just installed and all, but dockers and VMs work. For those I get "No dockers are installed or they are currently unavailable". Would you have any hint where to look?
-
Is it possible to find/ view/ copy the results of the extended tests from the file system? I have a huge log with dupes and it is difficult to process it based on the "view results" window from the GUI. I presume these results should be saved somewhere? However, I cannot locate it.
-
I can't get around this issue. I really turned off everything I can. Limited the number of directories to cache (tried with using include and exlude as well), but this is just continue to occur. Joe L., do you have a clue how should I track down this issue?
-
So you don't think it's a problem due to running out of memory? I ran the command and it returns correctly the number of the top level directories (shares). Do you mean I should run it in the second when cache_dirs re-schedule itself? I don't know how could I do that timing wise. Cannot we print this to the log file?
-
Hi Joe L., I am trying to troubleshoot an issue what happens to one of my friend with unRAID and cache_dirs. Cache_dirs is restarting without any log entry every ~1.5-2 hours. My bet was going on that the process gets killed due to not enough memory, but this is occuring even if I exlude all the larger user shares with the '-e' option. Would you have a hint for me where to look at? I uploaded the system log (it is not visible from this log, but please note I tried to exclude a lot more shares as well, keeping only 2 very small in for caching). Thank you for your help in advance! syslog-2013-05-22.txt
-
Thanks Joe L., I finally sorted it was the good-old smarthistory which caused the weird behaviour with the spin downs.
-
Hello Joe L. I am trying to troubleshoot a spin down issue, detailed here: http://lime-technology.com/forum/index.php?topic=25250.msg222150#msg222150 I have 6GB memory. Would it be possible by any chance that cache_dirs go mad by the high memory issue on rc10 (I don't seem to have the slow down issue though) and could somehow cause such issue? It also occured once, that cache_dirs was - I beleive - crashing overnight, because it disappeard from the running processes when I checked in the morning without anything in the log.
-
Thank you for your time and efforts!
-
Hi Joe L., thank you for your response. I am also not doing any extraordinary hacking when I invoke the command, in fact I am also only doing a couple of excludes and nothing else. However I have 4GB RAM and a diverse dir/file structure. Cache_dirs is working perfectly, and the initial find stops after a while, and then there is no issue with shuting down the array. But this "after a while" for the initial scan takes about 5-15 minutes (never measured that) and at my friend who really has an insane structure it is more 15-25 minutes. This means if I want to stop the array for whatever reason in this initial scan, then I have to telnet in and kill the find command(s) in order to do that. So based on this experience that this period can be even 25 minutes, I thought it would come more handy if cache_dirs -q was doing that kill in its own.
-
Hi Joe L., Was it that dumb question that you don't have any feedback on it or you missed this one? Cheers!
-
Hi Joe L., not sure this has been already brought up by someone, but I think it hasn't. When you stop cache_dirs with 'cache_dirs -q' it is only terminating the cache_dirs instance running in the background, but it is not killing any running (ongoing) 'find' command. So when you try to stop the array soon after you started up cache_dirs, the running 'find' command(s) can keep drive(s) busy even for longer time, resulting a long 'unmounting' on the unRAID interface unless you kill the 'find(s)' manually. Could killing of 'find' command(s) be added to 'cache_dirs -q' so that it can shut down gracefully? Thank you for your feedback in advance.
-
Thank you very much. Works perfectly!
-
Hey ClunkClunk, Do you have a recent handbrakecli SVN revision packaged to unRAID by any chance?
-
First post updated, I will finish the rest once I got home Yes, if I check the link above on the drive enclosure, you will see how it's slidable.
-
Third part.
-
Second part.
-
Here is mine. If you are interested in the parts, let me know. Chassis: Lian-Li Armorsuit PC-P50 http://www.lian-li.com/v2/en/product/product06.php?pr_index=321&cl_index=1&sc_index=25&ss_index=62 Drive enclosure 4in3 Nr.1 (top): Lian-Li EX-34N http://www.lian-li.com/v2/en/product/product06.php?pr_index=321&cl_index=1&sc_index=25&ss_index=62 Drive enclosure 4in3 Nr.2 (middle): Scythe Hard Drive Stabiliser X4 http://www.scythe-usa.com/product/acc/042/scyhdsx4-detail.html Drive enclosure 4in3 Nr.3 (bottom): Lian-Li EX-H34 http://www.lian-li.com/v2/en/product/product06.php?pr_index=285&cl_index=2&sc_index=5&ss_index=71 Motherboard: to be added CPU: Intel® Celeron® CPU E3300 @ 2.50GHz RAM: 3GB CPU Heatsink: Thermalright HR-01 Plus http://www.thermalright.com/new_a_page/product_page/cpu/hr01plus/product_cpu_cooler_hr01plus.htm Chipset Heatsink: Thermalright HR-05 http://www.thermalright.com/new_a_page/product_page/chipset/hr05/product_chitset_cooler_hr05.htm Drives: Parity: WD Caviar Green WD20EARS 2TB Data: 7 x WD Caviar Green WD15EADS 1.5TB 1 x WD Caviar Green WD10EADS 1.0TB 2 x WD Caviar Green WD10EACS 1.0TB 1 x SAMSUNG_HD103UJ 1.0TB Cache: WD Caviar Blue WD3200AAKS 320GB SATA Controllers: Adaptec 1430SA (4X sata) Generic Sil 3124-based SATAII Controller (2x sata) PSU: Seasonic S12-430
-
That was it Joe L.! Thank you very much! It works perfectly this way. Now, just out of curiosity: if this is a memory issue, shouldn't it happen also with your original script when all the ISOs are in the same dir?
-
Hi Joe L., Still from abroad, but I had some time and connection to try it out, and now I am even more confused. It seems that this way, not only the handbrake command for the first ISO gets written to /tmp/iso_hb (as I would expect from the above), but for the last ISO. For me it doesn't make any sense and I feel really like a dumb, but please see the attached screenshot. The script lists all the 3 iso files I have in that test dir, but it only writes the handbrake command for the last to /tmp/hb_iso I hope everyrhing will be visible on the screenshot.
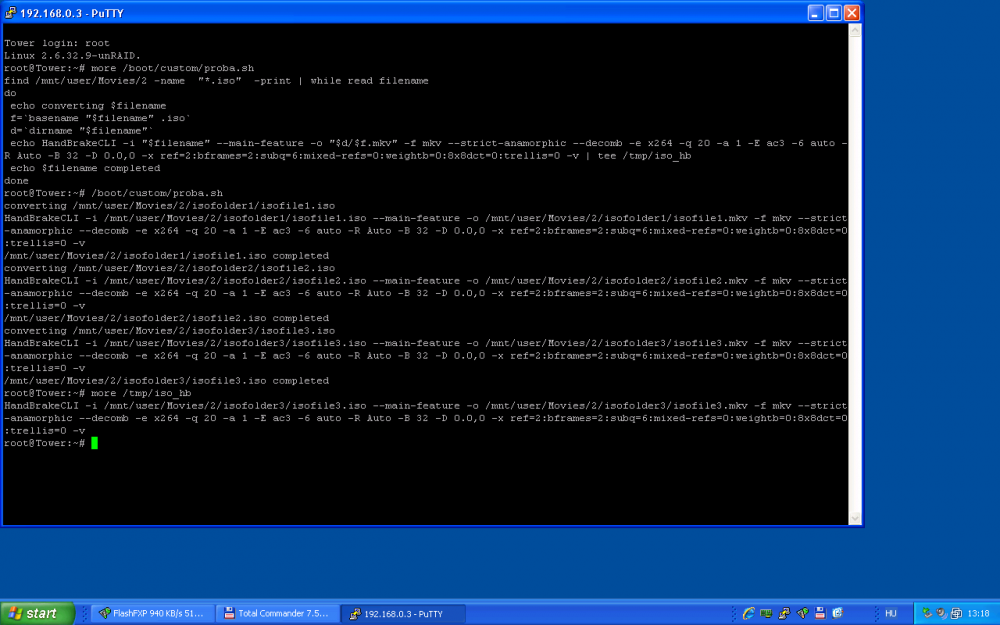
-
Thanks Joe L.! Sorry for the late reponse, but I am abroad for a week with very limited access to Internet. I will try out your suggestion when I am back at home. (Concerning the memory issue, I think 3GB should be enough for my test dir with only 3 ISOs , so I guess there has to be something else). Thank you again!
-
I am really not able to figure this out. I have tried many combinatation without success. If I copy over a few ISOs to a single dir and using your very original script from the first page, then it works perfectly and convert all the ISOs in the dir. But if I put the same ISOs to a subdir and running the script above, then it always only convert the ISO in the first dir. More weirdly, if I put the echo command before the Handbrake command line, then if I run the script it is correctly listing the Handbrake command for all the ISOs in all the subdirs. I've also noticed, that in the first case (when all the ISOs are in the same dir and I am using the original script), if I hit ctrl-c to cancel the script, it is only canceling the current convert and the script starts the next one in the queue, so I have to hit ctrl-c as many ISOs are in the queue. In case I use the "new" script on a subdirs structure, if I hit ctrl-c, the script exits immediately (it is not starting the next ISO in the queue). Is this something coming for the different behaviour of for and while?
-
Sorry Joe L., obviously I didn't expect you to see exactly what's wrong here. I just use the wrong expression. ...and I wasn't so clear either. I meant, when I run "find /mnt/user -name "*.ISO" -print " command separately, then all the ISOs found recursively in the target folder. Now I've tried the "Echo" debug step to check what the script would invoke and it also looks perfect, it lists the command for all the ISOs, but when I actually run the script, it's still exiting after the first ISO. So the script is perfect, thank you for this again, the problem is on my end, now it's my turn to do my homework and try to figure out what's going on here. Thank you!
-
Hi Joe L., I have tried it and seems that at on my end it is only converting the first find of "find /mnt/user -name "*.ISO" -print | while read filename" If I just run the command in itself then it finds all the ISOs recursively in the target dir, but the encode gets done only on the first item with a returned prompt: Rip done! HandBrake has exited. /mnt/user/TargetDir/FirstItem.iso completed root@Tower:/boot/custom/HandBrakeCLI# I haven't modified anything on the script you created. Am I doing something wrong?
-
Thank you very much Joe L.! As always, you are more than helpful! Cheers, Bence
