



ghiglie
Members
-
Joined
-
Last visited
Everything posted by ghiglie
-
oops, sorry, I really dindnt' notice your message. I didn't record the data precisely. Using Sonarr/Lidarr/Prowlarr/Deluge + Plex , it's idling at 25W with disks spun down. CPU load is normally low, but it fulls at 100% with Plex transcoding (1 stream at time, tough). With NMEs getting cheaper, having thow NVMEs disks is quite... useless; it'd work better with a single one but on a single slot with X2/X4 PCI-Ex lanes (hey, mister obvious! :D). A RAID1 isn't that slow, anyway, but quite comparable to SSD on a SATA3 port. I'm at the end of trial period, I think... lol, still don't know if I'd replace the old config.
-
Updated to RC7 without any problems. I haven't any "hard test", but it's quite a shame having those NVMEs at 1x each... I pooled them (BTRFS) but performance is on the low side. Anyway, for a basic NAS with some docker apps, it's fairly good.... I wonder how the N6005 performs.
-
Besides the fan controller is not being recognized (but it's a Linux kernel limitation), so far so good. Even Plex transcoding is working normally.
-
-
Yep, it could be. This mainboard has tons of settings in BIOS, maybe there's something like a "legacy support" enabled. Now it's Parity-Sync'ing , I'll let it do its job. BTW... Could you suggest a test? I'm trying my normal operativity, but can't say if there some much more UnRAID-related test I could do.
-
Thanks @JorgeB! I tried almost all (setting the pool manually, mounting it... format here, format there... ), but I did not try that.... and it worked flawlessly! I'd try RAID0, since thx NVMEs are linked with a single lane . It's really a waste, but coherent with a low power / low budget platform.
-
Ok, now the strange thing: adding the two NVMEs makes the emhttp segfault: May 29 02:27:27 Castle emhttpd: shcmd (378): mkdir -p /mnt/cache May 29 02:27:27 Castle emhttpd: /sbin/btrfs filesystem show /dev/nvme0n1p1 2>&1 May 29 02:27:27 Castle emhttpd: ERROR: not a valid btrfs filesystem: /dev/nvme0n1p1 May 29 02:27:27 Castle emhttpd: cache: invalid config: total_devices 0 num_misplaced 0 num_missing 0 May 29 02:27:27 Castle kernel: emhttpd[18641]: segfault at 107 ip 0000149fddc0c58a sp 0000149fdd30bbe0 error 4 in libc-2.37.so[149fddb94000+169000] likely on CPU 1 (core 1, socket 0) May 29 02:27:27 Castle kernel: Code: 48 8d 3d 91 27 11 00 e8 c4 ba ff ff 0f 1f 40 00 48 85 ff 0f 84 bf 00 00 00 55 48 8d 77 f0 53 48 83 ec 18 48 8b 1d 6e d8 14 00 <48> 8b 47 f8 64 8b 2b a8 02 75 5b 48 8b 15 fc d7 14 00 64 48 83 3a If cache is set to a single disk, so it defaults to XFS, all starts normally.
-
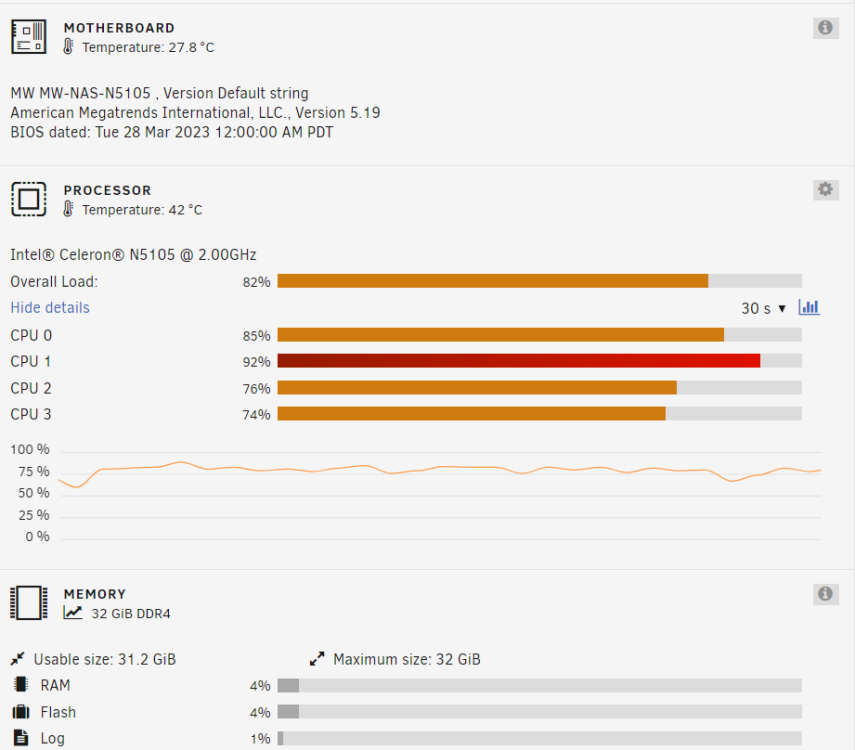
Preclearing 3 disks, I still have two Samsungs apart; CPU temp seems not bad:
-
So, got the RAM! A kit of Crucial got at the door today, plugged the picoPSU-160-XT with a 90W brick, and I'm ready to go. First boot took a bit of time, but then onboard beeper gave me confort. The mainboard came with v1 BIOS, definitely vast as AMI OEM ones... lots and lots of configuration options! I kept it at defaults. So, start from USB with UNRAID: 32Gb, all disks shows up, even all 4 NICs...! I Attaching my diagnostics. castle-diagnostics-20230527-2059.zip
-
Uh, it looks like I found the waking process! It seems it's been an rclone job, launched by Custom scripts. It looks like it was looping on retrying... Anyway, I put up the HBA and some spare HDDs. Long live the H97!
-
Hi @ConnerVT ! I got a N5105 mainboard, it has a CW-N5105-NAS rev. 1.0 watermark on it. Looks well built, I was expecting... well, worse, as construction. I was looking at that passive board for a Home Assistant baremetal install, but I've ended up staying quiet on a UDOO X86 that would be out of use. If you don't notice high temps, stressing it a bit more with some VMs wouldn't be that bad. Surely I'll exercize the mainboard for some time; I spare some disks, but I'd need a proper casing... I'll see where it gets! My current build is still solid, but a bit power hungry... but definitely efficient when it comes to PhotoPrism imports, Plex decoding, *arr stack management. I'm having a problem with drives not staying spun down, but I'll keep at least as this platform gets totally trustable. I really hope I'm not getting into that tunnel too - I could manage it, but I was to point my efforts elsewhere. BTW, the mainboard costed 160€ at the door. As for now... My SoDIMM banks is not working, so I'll have to grab a memory kit for the weekend
-
Hi there! Today I'm receiving a Topton/CWWK motherboard; I've read a lot about it on Brian Moses' blog putting together his DIY NAS 2023 Edition; then, after some aliexpress-fu, I found a discussion on ServeTheHome Forums about various use cases. Since I'm here as a UNRAID proud user, I'd like to check it with you specifically. You can find the specs in Brian's blog pages. I'll post my tests ASAP, in the while what do you think of it? I know it's very limited, but it looks perfect for low power build. Feel free to ask! Thanks all, Marco Curret testbed: CW-N5105-NAS v.10 (black mask, w/ BIOS string: MW-NAS-N5105 v5.19) 32Gb Crucial DDR4-3200MHz CL22 kit (CT2K16G4SFRA32A) 2 x Crucial P5 500Gb 4 x Samsung EcoGreen 1.00TB (HD103SI) 1 x WesternDigital Green 1.00TB (WD10EARS-00Y)
-
Upgraded to RC6, but unluckiliy no free solution... I think I've messed up something. How can I "reset" my system and star new? I can save my appdata, but what about the array? Thanks all! Marco
-
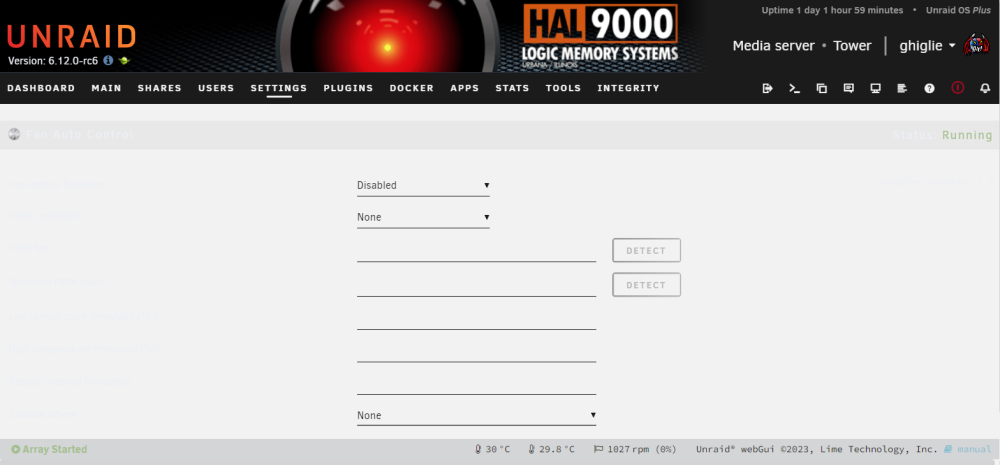
Hi there! These day my Unraid Server is acting... strange! As you can see, AutoFan is enable and running, but the setting page is blank: It's logging anyway: May 19 11:18:35 Tower autofan: autofan process ID 26891 started, To terminate it, type: autofan -q -c /sys/devices/platform/it87.2608/hwmon/hwmon3/pwm2 -f /sys/devices/platform/it87.2608/hwmon/hwmon3/fan1_input Did I mess something?
-
Yet done, it was my first try! I'm noticing that the wake order is always the same: sdf, sdd, sdg, sdc, sdh : May 16 19:08:17 Tower emhttpd: spinning down /dev/sdc May 16 19:08:18 Tower emhttpd: spinning down /dev/sdg May 16 19:08:19 Tower emhttpd: spinning down /dev/sdh May 16 19:08:20 Tower emhttpd: spinning down /dev/sdf May 16 19:08:21 Tower emhttpd: spinning down /dev/sdd May 16 19:09:09 Tower emhttpd: read SMART /dev/sdf May 16 19:09:16 Tower emhttpd: read SMART /dev/sdd May 16 19:09:31 Tower emhttpd: read SMART /dev/sdg May 16 19:09:31 Tower emhttpd: read SMART /dev/sdc May 16 19:09:40 Tower emhttpd: read SMART /dev/sdh "BTW, what is this task? /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update"
-
small update: no news... It happens even on Maintenance mode, no logs in activity plugin . May 16 01:38:02 Tower emhttpd: spinning down /dev/sde May 16 01:46:48 Tower emhttpd: spinning down /dev/nvme0n1 May 16 01:46:48 Tower emhttpd: sdspin /dev/nvme0n1 down: 25 May 16 01:48:00 Tower emhttpd: spinning down /dev/sdg May 16 01:48:01 Tower emhttpd: spinning down /dev/sdh May 16 01:48:01 Tower emhttpd: spinning down /dev/sdd May 16 01:48:01 Tower emhttpd: spinning down /dev/sdf May 16 01:48:01 Tower emhttpd: spinning down /dev/sdc May 16 01:48:06 Tower emhttpd: read SMART /dev/sdd May 16 01:48:06 Tower emhttpd: read SMART /dev/sdf May 16 01:48:19 Tower emhttpd: read SMART /dev/sdg May 16 01:48:19 Tower emhttpd: read SMART /dev/sdc May 16 01:48:28 Tower emhttpd: read SMART /dev/sdh
-
So it's an effect, and not a cause... mmm... In the while, Parity check finished in safe mode, but... same issue, even in safe mode. I'm stopping the server to prevent a spinning recycle. During the night (...) I'll try to put back the HBA in, even I'd spare gladly those 10Watts (it's a 9211-8i flashed in IT mode).
-
Sob, I decided for another run in safe mode and... last shutdown, even it was clear, triggered a parity check. I'm goint to let it finish.
-
Geez, didn't notice that folder. It's empty fortunately, I'm removing it .. now! I shut down the autofan too - removing the cache dir plugin, I'll report back soon. ( thanks for your prompt replies!)
-
Hi Simon! Yes, I did, but it keeps doing so. Disks spin down individually, but after some time are woken up. Before that hardware rework (tried to save some power) it was working like a charm...
-
Hi there! I'm facing a strange problem - I've seen a number of similar threads, but none seems to fit. I reworked my unraid box, moving taking out a SATA SSD and the HBA, plugging in an NVME as cache, and other disks on the mobo connectors. Since then, disks spin down, but always get up by a SMART reading: May 14 15:54:20 Tower apcupsd[8958]: Communications with UPS lost. May 14 16:02:03 Tower emhttpd: spinning down /dev/sdf May 14 16:03:08 Tower emhttpd: read SMART /dev/sdf May 14 16:03:10 Tower emhttpd: spinning down /dev/sdd May 14 16:03:11 Tower emhttpd: spinning down /dev/sdg May 14 16:03:11 Tower emhttpd: spinning down /dev/sdc May 14 16:03:27 Tower emhttpd: spinning down /dev/sdh May 14 16:04:08 Tower emhttpd: read SMART /dev/sdd May 14 16:04:23 Tower emhttpd: read SMART /dev/sdg May 14 16:04:23 Tower emhttpd: read SMART /dev/sdc May 14 16:04:29 Tower apcupsd[8958]: Communications with UPS lost. May 14 16:04:32 Tower emhttpd: read SMART /dev/sdh May 14 16:14:37 Tower apcupsd[8958]: Communications with UPS lost. May 14 16:24:46 Tower apcupsd[8958]: Communications with UPS lost. May 14 16:33:03 Tower emhttpd: spinning down /dev/sdf May 14 16:34:09 Tower emhttpd: read SMART /dev/sdf May 14 16:34:09 Tower emhttpd: spinning down /dev/sdd May 14 16:34:11 Tower emhttpd: read SMART /dev/sdd May 14 16:34:11 Tower emhttpd: spinning down /dev/sdg May 14 16:34:11 Tower emhttpd: spinning down /dev/sdc May 14 16:34:13 Tower emhttpd: read SMART /dev/sdc As you can see, I still have to connect again the UPS USB cable I've tried almost anything: disks are idling, dockers (I have a number!) and VMs are set off. Running 6.12rc5. What could I try? tower-diagnostics-20230514-1703.zip
-
Are you planning NVMe devices, or mixed types?
-
Just reporting back a plain success. Just cross flashed an M1015 to 9211-8i firmware P20, with BIOS and EFI BSD. Now I have two more cards to play with, another M1015 and a Br10i. Inviato dal mio SM-A530F utilizzando Tapatalk
-
Hi there, I'm having some probs with autofan 1.5 on 6.4.0_rc15e - it's not recognising my PWM controller any more. I'm running on a Gigabyte H97N-Wifi , ITE87 . It wasn't working anyway with last unRAID stable. Any ideas where I could search for more infos? tnx, Marco EDIT: SOLVE! Had to modprobe the ITE87 module manually.
-
Is there a way to fix it? Do you have it running as host and not as bridge? Oops... Yes, fixed setting as bridge. Inviato dal mio D5803 utilizzando Tapatalk



