




tuxbass
Members
-
Joined
-
Last visited
-
What's the current status of the plugin? Plugins page says it's unlisted.
-
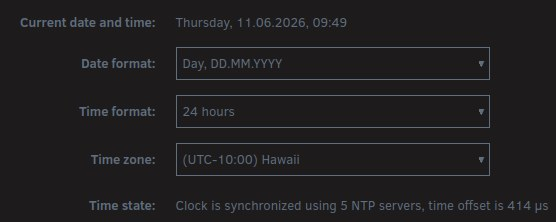
...and now discovered time config was borked: I'm EU-based. # ls -l /etc/localtime lrwxrwxrwx 1 root root 33 Jun 10 15:18 /etc/localtime -> /usr/share/zoneinfo/Europe/Madrid # ls -l /usr/share/zoneinfo/Europe/Madrid ls: cannot access '/usr/share/zoneinfo/Europe/Madrid': No such file or directory IIRC localtime used to be pointed at Paris node, no idea where Madrid now came from. Did the fancy new onboarding logic maybe deduct I'm somewhere in Spain and cleverly set it to Madrid without being asked to?
-
Upgraded from 7.2.7 to 3.1 and got a... on boarding prompt on a decade+ old installation?! I get that Unraid is a brand-new product and some things fall between the cracks, but come on.
-
There are "update stack" buttons, but how do you guys schedule images to automatically be updated, and old images/containers to be removed?
-
Anyone else getting 502 with emby? No idea when it started as local media player connects directly to the local IP, but external connection over reverse proxy now ends in 502: SSL_do_handshake() failed (SSL: error:0A00042E:SSL routines::tlsv1 alert protocol version:SSL alert number 70) while SSL handshaking to upstream, client: my.external.ip, server: emby.*, request: "GET / HTTP/2.0", upstream: "https://192.168.0.12:8920/", host: "emby.mydomain.com"Any idea as to what's changed? Edit: Fixed by changing proxy_pass to proxy_pass http://host.ip:8096; For years had it as proxy_pass https://host.ip:8920; so better question would be why did it ever work lol.
-
Has there been any announcement from dlandon as to what's going on? Are they just stopping work on it or are the repos/projects migrated somewhere else?
-
Can't say I'm intimately familiar with unraid plugin architecture, but this bit suggests my guess was correct.
-
My understanding was that property is only used by docker and wouldn't be in effect unless the plugin calls `compose up -d / compose start`, which is enabled by the toggle (which I have on the compose tab like on your screenshot). Is there plugin source available to see what it's doing?
-
I have a woodpecker stack consisting of two containers. autostart=false, yet one of the containers - the agent - is started on unraid startup. # cat woodpecker/autostart false # cat woodpecker/docker-compose.yml services: woodpecker-server: container_name: woodpecker-server image: woodpeckerci/woodpecker-server:v3 ports: - 8003:8000 volumes: - /mnt/user/appdata/woodpecker/server:/var/lib/woodpecker/ environment: - WOODPECKER_HOST=https://woodpecker.myserver.eu // other app env vars... networks: - main1 woodpecker-agent: container_name: woodpecker-agent image: woodpeckerci/woodpecker-agent:v3 command: agent restart: always depends_on: - woodpecker-server volumes: - /mnt/user/appdata/woodpecker/agent:/etc/woodpecker - /var/run/docker.sock:/var/run/docker.sock environment: - WOODPECKER_SERVER=woodpecker-server:9000 // other app env vars... networks: - main1 networks: main1: name: main external: true # use pre-existing network docker confirms there was no attempt to start the server: # docker ps --all | grep woodp 5f943419146d .../woodpecker-agent:v3 ... 30 hours ago Up 7 seconds (health: starting) bf936cadc804 .../woodpecker-server:v3 ... 30 hours ago Exited (0) 4 hours ago --- Why does the plugin try to start the agent?
-
# ls -A /boot/config/plugins/tablesorter/ tablesorter-2.27.6-x86_64-1.txz Is it okay to remove /boot/config/plugins/tablesorter/ dir with the plugin file? txz file is from 2016. Can't recall ever installing said plugin.
-
Good to know. Any idea as to why release notes made no mention of it nor why this issue isn't documented under 7.0.0 known issues? Reddit reccomended using tools such as Czkawka to search for duplicates. Are there any (semi-)official steps users should take to see whether they are affected and how to fix the problems? It's still a bit puzzling that unraid makes zero attempt at informing users about this.
-
Resolved as in further mover runs are OK. But should users look out for broken links and fix 'em manually?
-
GH mentions "This repository is compatible with slackpkg+" - how do you set up slackpkg+ on unraid to make use of your pre-built packages?
-
That's good to hear. I was referring to this report:
-
What about some users reporting mover failure creating dupes? Non-issue and users should ignore those comments?


