




Markland
Members
-
Joined
-
Last visited
-
It has done the trick. Something of interest though is that If I have two cables hooked up to one of the controllers in the disk shelf I see all of the disks. If I hook it up to the other one I don't. And when I have both of the ports filled I don't get the "problem getting id" message and I dont get the BTRFS error any more. I do have a new one though lol Nov 7 00:02:44 GLaDOS kernel: blk_update_request: critical target error, dev sdc, sector 1950351263 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 I am curious if the two cables to one controller is causing that, or if its the controller as you had mentioned. Time for some more debugging and testing! Thank you for your help!
-
Awesome! I will try that when I get home. When you say controller do you mean like the LSI controller or the one in the disk self? Thank you for your help!
-
I have a problem with my unraid set up. It has to deal with the ssds in my system that I am using for my cache drive. The error I believe started primarily when I started using auto backup but I believe the errors were happening all along since I upgraded my unraid set up to include a Netapp DS2246 for my hhd and ssd. Its all being controlled by a LSI 9200-16e. I can reliable generate the issue by causing the auto back up tool to auto back up and bring the cache drive down. Once the back up is done I get a constant disk write error and all the apps trying to use my cache disk which is the disk in question cant access it but its still actively mounted to the array. The errors when the array is not mounted yet: Nov 2 19:54:46 GLaDOS emhttpd: device /dev/sdq problem getting id Nov 2 19:54:46 GLaDOS emhttpd: device /dev/sdo problem getting id This is said constantly. After the array is started no issues/error messages immediately: But some times I continue to have the problem getting id and then sometimes it turns into the bellow btrfs error. This ahappens randomly after some time but reliable I can trigger it with an auto back up. This is after the ca auto back up occurs I get the following error message: ov 2 20:42:03 GLaDOS kernel: BTRFS error (device sdh1): bdev /dev/sdh1 errs: wr 0, rd 5525, flush 0, corrupt 0, gen 0 Nov 2 20:42:03 GLaDOS kernel: BTRFS error (device sdh1): bdev /dev/sdh1 errs: wr 0, rd 5526, flush 0, corrupt 0, gen 0 Nov 2 20:42:03 GLaDOS kernel: BTRFS error (device sdh1): bdev /dev/sdh1 errs: wr 0, rd 5527, flush 0, corrupt 0, gen 0 Nov 2 20:42:03 GLaDOS kernel: BTRFS error (device sdh1): bdev /dev/sdh1 errs: wr 0, rd 5528, flush 0, corrupt 0, gen 0 Nov 2 20:42:03 GLaDOS kernel: BTRFS error (device sdh1): bdev /dev/sdh1 errs: wr 0, rd 5529, flush 0, corrupt 0, gen 0 Nov 2 20:42:03 GLaDOS kernel: BTRFS error (device sdh1): bdev /dev/sdh1 errs: wr 0, rd 5530, flush 0, corrupt 0, gen 0 Nov 2 20:42:03 GLaDOS kernel: BTRFS error (device sdh1): error loading props for ino 4047063 (root 5): -5 Nov 2 20:42:04 GLaDOS kernel: BTRFS error (device sdh1): error loading props for ino 4047796 (root 5): -5 Attached is my diagnostic report if it helps. If you guys/gals need anything else please let me know. Thank you for your time! Mark M. glados-diagnostics-20211102-2043.zip
-
I was wondering what was going wrong..... well that is frustrating oh well. Thanks for confirming my suspicions.
-
Nope this docker for one still comes with the override directory when you pull it. Its still in the template. Two that override dir does nothing as netdata no longer uses it and so when you modify the template before installing to be etc/netdata it doesn't work their are no configs but there were configs when the the template was pointing to the override folder. Also I checked it on the other one you mentioned and both have the same behavior. The etc/netdata folder the should contain configs is empty except for .opt-out-form.... and the claim.d
-
Ok so I found a weird bug I think. When I install the netdata-glibc stock their is no config file in the override folder. I noticed that when I told it to not mnt the override folder all of a sudden the config files appeared in the /etc/netdata. Has anyone run into something similar and or a fix for this?
-
Guys I posted this on Reddit and got it to work by using a different docker. Linked is the Reddit thread. And what I did: "I took D34DC3N73R's docker and shoved it in Data-monkey aka roland's template from the CA Hub and tada it works. All of my gpus that support nvidia-smi showed up! Now onto custom configs and things. Muahahaha!" I dont know if everything works but it seems to be! D34DC3N73R's docker: https://hub.docker.com/r/d34dc3n73r/netdata-glibc
-
I have tired to get it to work as well and I cant figure it out. Anyone know of a way to install an earlier release of the container? Maybe that would work?
-
I second this when you get the chance! Thank you for the great plugin!
-
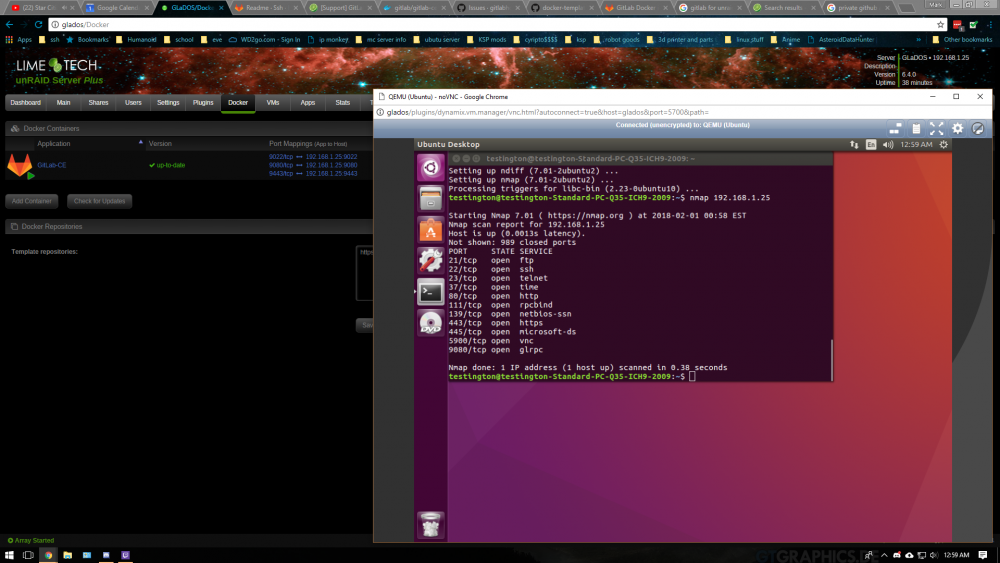
Hi Everyone, Just a bit of an update that seems weird to me is that the ports aren't being forwarded. Am I seeing things or could this be my problem?
-
Hi everyone, I am currently trying out gitlab for the first time and am having issues with the ssh connection. It continues to ask for a password and I cant seem to find out what is causing this issue. Does anyone have any ideas what could be causing this and or also having this issue? Mark
-
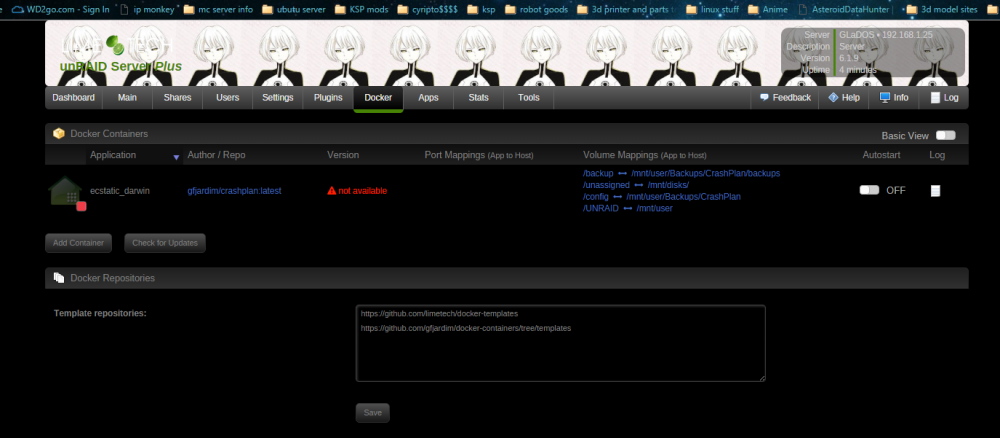
Ah alright. Awesome. That seems to have fixed the issue about running out of room. But I am not 100% sure if thats the case because it crashed. and then i restarted the server because it has crashed before and that fixed it but this time something different happened. The name of the container changed from Crashplan to ecstatic_darwin and here is the proof below. Any idea what possibly could have happened? And if any other information is needed please let me know! Thank you for your help in advance! Mark
-
Hello Everyone, I apologize in advance for an stupid questions I may have as I am new to linux, unraid and defiantly containers. Now with that being said I am having issues with my crash plan container. I have looked far and wide to try to figure out why and or how crash plan has run out of room to back up. What I have determined is that the container is limited to a certain size and therefore I cant back up more since I filled the container. This confuses me since then that means I would have to make a huge container and that isnt in the guide on page 1 of the crash plan thread. So I looked else where and have found one possibility. The config is not in a cache drive. Since I don't have cache I threw it on a disk. Could this be what is causing all of my trouble? And if so is their a work around without me getting a whole new drive? Thank you for any help you can give me! Mark


