




jademonkee
Members
-
Joined
-
Last visited
Everything posted by jademonkee
-
FYI Customer Support have said that my maintenance has now completed and it's now ok for me to log back in again, so I have done so. Will see if the sync finishes and report back if it does/doesn't. Here's the email as it contains some good info:
-
I updated this morning and have this in the logs: It's not adding any extra lines (like, they're not repeating), and Swag + NextCloud are working fine (the only things that use it - and I don't even remeber if they both do, or just NC... heh)). Is that safe mode anything to worry about? Or is it all good?
-
The customer support agent that suggested I deauthorize told me not to log back in until they told me to. It's because there is some maintenance occuring on the data stored on their servers, and the file sync can sometimes interfere with that. So the deauthorization stops the file sync so that the maintenance can complete without interruption. By logging back in immediately, the maintenance doesn't have a chance to complete. So I'm waiting for the customer support agent to tell me when it's ok to log back in.
-
Yeah, I'm sick of these periods of syncing an no-backups. I've been considering buying an old HP Microserver and installing it in a closet at a friend's place to run a weekly rsync backup to. However, with CrashPlan only $12/month, it'll take a little too long to pay off... so I keep giving up on the idea.
-
I've just received the following from CrashPlan support: I'll report back on any progress.
-
I'm seeing a synchronization, yes. However, it's been however many days now and it's never hit 100%. It keeps climbing then dropping back to 0%, just as it did in my earlier posts. I've reached out to CrashPlan support to see if they can shed any light on it.
-
FYI I decided to upgrade to v6.2.26 using the docker tag: linuxserver/unifi-controller:version-6.2.26 I also updated the firmware of my two AP AC LR to v5.43.38 (from v4), although one of them kept failing, and I had to 'cache' it in the controller before the upgrade worked successfully (Settings > Maintenance > Cache). The other (slightly newer hardware) updated fine the first time (before I'd cached the firmware), however. I also had to change my guest network authentication to explicitly use a password, and then re-enter what used to be the "WPA2" password (I don't use a portal, it's just an isolated network I use for untrusted devices). I also changed the Internet > WAN > Advanced > DHCP to point to my pihole DHCP server (don't know if I had to, but there was no value in that box) as well as Network > LAN > Advanced > DHCP UniFi Controller to point to my pihole DHCP sever, too, just in case that was needed as well. Aside from the firmware update hiccup, everything seems to be working well. I can't really see anything missing from the 'new' interface, and am enjoying its layout. I am generally a 'set and forget' user, though, so power users may find the new interface lacking. I'll report back if anything breaks. Thanks for taking the initial plunge @PeteAsking!
-
Well, not anymore. I'm having the same problem of 'synchronizing file information' endlessly looping. I'm about ready to chuck in the towel with crashplan and just install another Unraid box at a friend's house and run an rsync once a week.
-
Let us know what you think of it in a couple weeks. I still haven't taken the plunge, although it seems like most of the big problems were sorted in this latest release.
-
If you've confirmed that your max memory variable is set correctly (see earlier in the thread for the command in CrashPlan that allows you to check), then that's all I had to do to solve my problems. FWIW I'm using 4096 MB memory and backing up 3.6 TB. Most of the time the Docker only uses around 1 GB, but it may have climbed during sync and I missed it (which may be why mine was resetting), so if you can spare the memory, might as well set it high. If you've set the memory correctly, try reaching out to Crashplan support, too - the can take a look at the logs and see if your block sync is failing for another reason.
-
6 weeks later, how goes it? Any problems from the upgrade to v6? Anything you like about it more than v5? I'm too afraid to even upgrade the firmware on my APs to the new v5 from v4 without also making the jump to controller v6.
-
Just out of curiosity: are you running it as Bridge or Host? Bridge is preferred and will work fine as long as you set the correct ports and then set the hostname for adoption in the settings. Just go back a page in this topic to see more info on that.
-
Try restarting the Docker. I believe that should have it upgrade to the latest version (I may be confusing it with another Docker though). If it doesn't upgrade, try a 'force upgrade' in advanced settings (the toggle switch at the top of the Docker page).
-
See this post: TL;DR increase the limit using the tips n tweaks plugin. There's no magic number, so don't ask for one. The bigger it is, the more RAM you'll need. However, I have mine set to 2097152 (16 GB RAM, no VMs) and it works well for the number of files I"m backing up (and also Plex). Learn more about inotify here: https://man7.org/linux/man-pages/man7/inotify.7.html
-
Just popping in to say that 30 days later I FINALLY have backups completed again. Thanks again, everyone, for your help.
-
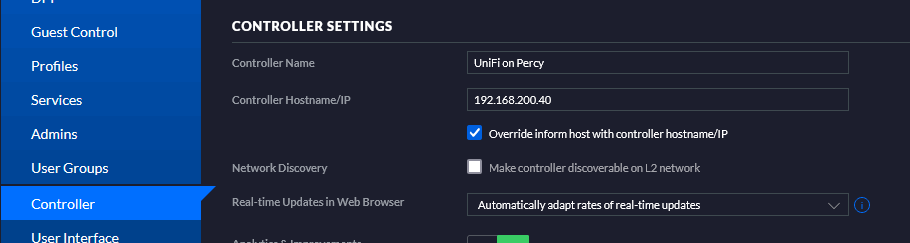
Mine works fine as Bridge. Never had adoption issues (well, there were some when I had to factory reset my devices and completely nuke the controller install, but that wasn't related). I have the following ports mapped and am running version 5.14.23-ls76: EDIT: Be sure to make sure you have the broadcast address set manually in Settings > Controller > "Controller Hostname/IP" too!

-
NEVERMIND I FIGURED IT OUT I'M SO SORRY I had manually added the CRASHPLAN_SRV_MAX_MEM variable, totally overlooking the one that was there by default, (worse yet: it looks like I had even previously set it to 3072M). I've now deleted the redundant variable, and changed the original one to 4096M, and the run command now looks like this: root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='CrashPlanPRO' --net='bridge' -e TZ="Europe/London" -e HOST_OS="Unraid" -e 'USER_ID'='99' -e 'GROUP_ID'='100' -e 'UMASK'='000' -e 'APP_NICENESS'='' -e 'DISPLAY_WIDTH'='1280' -e 'DISPLAY_HEIGHT'='768' -e 'X11VNC_EXTRA_OPTS'='' -e 'CRASHPLAN_SRV_MAX_MEM'='4096M' -e 'SECURE_CONNECTION'='0' -p '7810:5800/tcp' -p '7910:5900/tcp' -v '/mnt/user':'/storage':'ro' -v '/boot':'/flash':'ro' -v '/mnt/user/appdata/CrashPlanPRO':'/config':'rw' 'jlesage/crashplan-pro' 1e164b1c891c96fdf57ebe60e63903b41d51d0627f749574909eaa1793643510 So sorry for such a stupid mistake. Thank you for your time, and I apologise for wasting it.
-
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='CrashPlanPRO' --net='bridge' -e TZ="Europe/London" -e HOST_OS="Unraid" -e 'USER_ID'='99' -e 'GROUP_ID'='100' -e 'UMASK'='000' -e 'APP_NICENESS'='' -e 'DISPLAY_WIDTH'='1280' -e 'DISPLAY_HEIGHT'='768' -e 'X11VNC_EXTRA_OPTS'='' -e 'CRASHPLAN_SRV_MAX_MEM'='3072M' -e 'SECURE_CONNECTION'='0' -p '7810:5800/tcp' -p '7910:5900/tcp' -v '/mnt/user':'/storage':'ro' -v '/boot':'/flash':'ro' -v '/mnt/user/appdata/CrashPlanPRO':'/config':'rw' 'jlesage/crashplan-pro' e82c65fd7d8a47d2d87b0de10f6624f4dd8a7c11843e2e204e9ddaa55a3b08d1 EDIT: Just noticed that it has the 3072 value for mem, so here's a screencap of the variable (which I'm failry sure I added) for the server max mem, in case you can see something wrong.
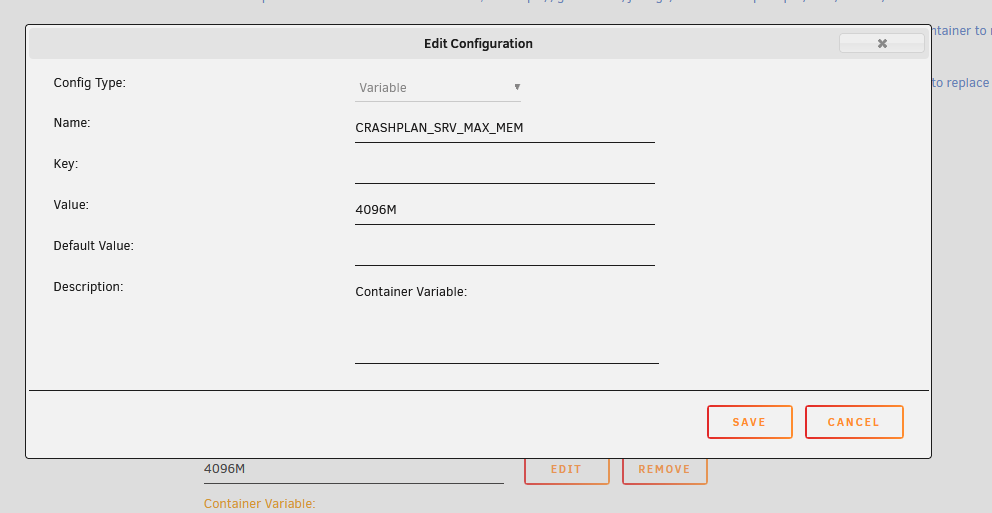
-
Correct. Container config has CRASHPLAN_SRV_MAX_MEM variable set as 4096M
-
The file synchronisation did complete, and then it moved to the next maintenance task. I thought that would be a good time to upgrade to the latest version (as Crashplan support mentioned that I should), so I updated the container and now it's doing a "deep maintenance" with 9 hours remaining. Curiously, it says it's only found 76.7 GB of backups, so I'm assuming (hoping?) after the deep maintenance it will go up to the correct 3.6 TB - hopefully without another file information sync... Memory usage is currenlty 828MB After the restart, "xmx" in /mnt/user/appdata/CrashPlanPRO/log/engine_output.log remains at 3072M
-
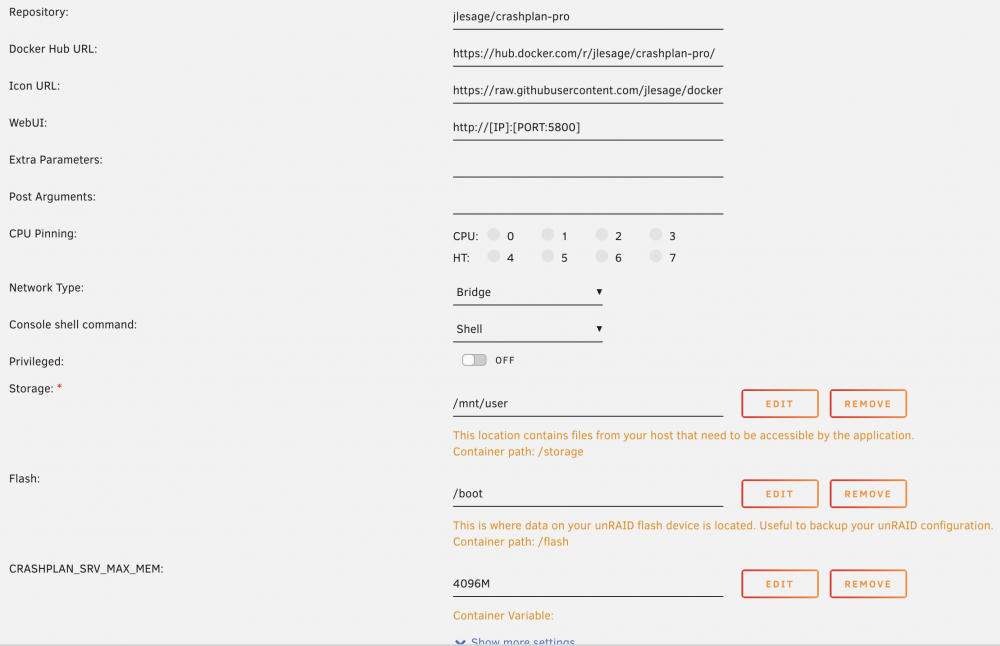
Under the 'advanced' view of the Docker page in the Unraid GUI. I assumed that the synchronisation task would be a high memory usage situation because of the comment from support: So I was thinking that the issue I was having (the "synchronising file information" task always failing and restarting), was due to low memory, and so am was hopeful that it would work correctly now that I've upped the memory allocation. And, indeed, even though the Docker is using the same amount of memory as before (around 1GB), the file info sync is now at 95% complete. So fingers crossed it completes this time! I was getting close to buying a second hand NAS to install at a friend's place and replacing CrashPlan with rsync...
-
The log contains the line -Xmx3072M I applied the Crashplan console command (java mx 4096) without restarting the container. My synchronisation is now at 83% so I'm going to wait to see if it completes before I change anything that will require a container restart. If the engine log shows 3072, then is it likely that Crashplan doesn't need more than the ~1.1 GB it's currently using? Thanks for your help.
-
I should note that in the output from the 'inspect' command above, the setting: Is inconsistent with the variable I have entered in the Edit Container page, which is 4096M
-
21/05/2021 17:17:34 Statistics events Received/ RawEquiv ( saved) 21/05/2021 17:17:34 ClientCutText : 3 | 73/ 73 ( 0.0%) 21/05/2021 17:17:34 PointerEvent : 419 | 2514/ 2514 ( 0.0%) 21/05/2021 17:17:34 FramebufferUpdate : 1645 | 16450/ 16450 ( 0.0%) 21/05/2021 17:17:34 SetEncodings : 1 | 56/ 56 ( 0.0%) 21/05/2021 17:17:34 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 21/05/2021 17:17:34 TOTALS : 2069 | 19113/ 19113 ( 0.0%) 21/05/2021 17:17:34 destroyed xdamage object: 0x40002c 24/05/2021 09:54:52 Got connection from client 127.0.0.1 24/05/2021 09:54:52 other clients: 24/05/2021 09:54:52 Got 'ws' WebSockets handshake 24/05/2021 09:54:52 Got protocol: binary 24/05/2021 09:54:52 - webSocketsHandshake: using binary/raw encoding 24/05/2021 09:54:52 - WebSockets client version hybi-13 24/05/2021 09:54:52 Disabled X server key autorepeat. 24/05/2021 09:54:52 to force back on run: 'xset r on' (3 times) 24/05/2021 09:54:52 incr accepted_client=2 for 127.0.0.1:47394 sock=10 24/05/2021 09:54:52 Client Protocol Version 3.8 24/05/2021 09:54:52 Protocol version sent 3.8, using 3.8 24/05/2021 09:54:52 rfbProcessClientSecurityType: executing handler for type 1 24/05/2021 09:54:52 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 24/05/2021 09:54:53 Pixel format for client 127.0.0.1: 24/05/2021 09:54:53 32 bpp, depth 24, little endian 24/05/2021 09:54:53 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 24/05/2021 09:54:53 no translation needed 24/05/2021 09:54:53 Enabling NewFBSize protocol extension for client 127.0.0.1 24/05/2021 09:54:53 Enabling full-color cursor updates for client 127.0.0.1 24/05/2021 09:54:53 Using image quality level 6 for client 127.0.0.1 24/05/2021 09:54:53 Using JPEG subsampling 0, Q79 for client 127.0.0.1 24/05/2021 09:54:53 Using compression level 9 for client 127.0.0.1 24/05/2021 09:54:53 Enabling LastRect protocol extension for client 127.0.0.1 24/05/2021 09:54:53 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 24/05/2021 09:54:53 Using tight encoding for client 127.0.0.1 24/05/2021 09:54:53 client_set_net: 127.0.0.1 0.0000 24/05/2021 09:54:53 created xdamage object: 0x40002e 24/05/2021 09:55:07 client 2 network rate 1498.5 KB/sec (23346.7 eff KB/sec) 24/05/2021 09:55:07 client 2 latency: 1.4 ms 24/05/2021 09:55:07 dt1: 0.0044, dt2: 0.0096 dt3: 0.0014 bytes: 20046 24/05/2021 09:55:07 link_rate: LR_LAN - 1 ms, 1498 KB/s 24/05/2021 09:59:53 idle keyboard: turning X autorepeat back on. 24/05/2021 10:01:52 got closure, reason 1001 24/05/2021 10:01:52 rfbProcessClientNormalMessage: read: Connection reset by peer 24/05/2021 10:01:52 client_count: 0 24/05/2021 10:01:52 Client 127.0.0.1 gone 24/05/2021 10:01:52 Statistics events Transmit/ RawEquiv ( saved) 24/05/2021 10:01:52 FramebufferUpdate : 13468 | 0/ 0 ( 0.0%) 24/05/2021 10:01:52 LastRect : 52 | 624/ 624 ( 0.0%) 24/05/2021 10:01:52 tight : 16843 | 14949322/209875204 ( 92.9%) 24/05/2021 10:01:52 RichCursor : 1 | 1374/ 1374 ( 0.0%) 24/05/2021 10:01:52 TOTALS : 30364 | 14951320/209877202 ( 92.9%) 24/05/2021 10:01:52 Statistics events Received/ RawEquiv ( saved) 24/05/2021 10:01:52 ClientCutText : 2 | 41/ 41 ( 0.0%) 24/05/2021 10:01:52 PointerEvent : 999 | 5994/ 5994 ( 0.0%) 24/05/2021 10:01:52 FramebufferUpdate : 13468 | 134680/ 134680 ( 0.0%) 24/05/2021 10:01:52 SetEncodings : 1 | 56/ 56 ( 0.0%) 24/05/2021 10:01:52 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 24/05/2021 10:01:52 TOTALS : 14471 | 140791/ 140791 ( 0.0%) 24/05/2021 10:01:52 destroyed xdamage object: 0x40002e 25/05/2021 09:33:14 Got connection from client 127.0.0.1 25/05/2021 09:33:14 other clients: 25/05/2021 09:33:14 Got 'ws' WebSockets handshake 25/05/2021 09:33:14 Got protocol: binary 25/05/2021 09:33:14 - webSocketsHandshake: using binary/raw encoding 25/05/2021 09:33:14 - WebSockets client version hybi-13 25/05/2021 09:33:14 Disabled X server key autorepeat. 25/05/2021 09:33:14 to force back on run: 'xset r on' (3 times) 25/05/2021 09:33:14 incr accepted_client=3 for 127.0.0.1:55954 sock=10 25/05/2021 09:33:14 Client Protocol Version 3.8 25/05/2021 09:33:14 Protocol version sent 3.8, using 3.8 25/05/2021 09:33:14 rfbProcessClientSecurityType: executing handler for type 1 25/05/2021 09:33:14 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 25/05/2021 09:33:14 Pixel format for client 127.0.0.1: 25/05/2021 09:33:14 32 bpp, depth 24, little endian 25/05/2021 09:33:14 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 25/05/2021 09:33:14 no translation needed 25/05/2021 09:33:14 Enabling NewFBSize protocol extension for client 127.0.0.1 25/05/2021 09:33:14 Enabling full-color cursor updates for client 127.0.0.1 25/05/2021 09:33:14 Using image quality level 6 for client 127.0.0.1 25/05/2021 09:33:14 Using JPEG subsampling 0, Q79 for client 127.0.0.1 25/05/2021 09:33:14 Using compression level 9 for client 127.0.0.1 25/05/2021 09:33:14 Enabling LastRect protocol extension for client 127.0.0.1 25/05/2021 09:33:14 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 25/05/2021 09:33:14 Using tight encoding for client 127.0.0.1 25/05/2021 09:33:15 client_set_net: 127.0.0.1 0.0000 25/05/2021 09:33:15 active keyboard: turning X autorepeat off. 25/05/2021 09:33:15 created xdamage object: 0x40002f 25/05/2021 09:33:31 client 3 network rate 1209.3 KB/sec (41587.0 eff KB/sec) 25/05/2021 09:33:31 client 3 latency: 1.3 ms 25/05/2021 09:33:31 dt1: 0.0033, dt2: 0.0096 dt3: 0.0013 bytes: 14877 25/05/2021 09:33:31 link_rate: LR_LAN - 1 ms, 1209 KB/s 25/05/2021 09:38:12 got closure, reason 1001 25/05/2021 09:38:12 rfbProcessClientNormalMessage: read: Connection reset by peer 25/05/2021 09:38:12 client_count: 0 25/05/2021 09:38:12 Restored X server key autorepeat to: 1 25/05/2021 09:38:12 Client 127.0.0.1 gone 25/05/2021 09:38:12 Statistics events Transmit/ RawEquiv ( saved) 25/05/2021 09:38:12 FramebufferUpdate : 9920 | 0/ 0 ( 0.0%) 25/05/2021 09:38:12 LastRect : 10 | 120/ 120 ( 0.0%) 25/05/2021 09:38:12 tight : 10783 | 11281941/131235572 ( 91.4%) 25/05/2021 09:38:12 RichCursor : 1 | 1374/ 1374 ( 0.0%) 25/05/2021 09:38:12 TOTALS : 20714 | 11283435/131237066 ( 91.4%) 25/05/2021 09:38:12 Statistics events Received/ RawEquiv ( saved) 25/05/2021 09:38:12 ClientCutText : 2 | 41/ 41 ( 0.0%) 25/05/2021 09:38:12 PointerEvent : 246 | 1476/ 1476 ( 0.0%) 25/05/2021 09:38:12 FramebufferUpdate : 9921 | 99210/ 99210 ( 0.0%) 25/05/2021 09:38:12 SetEncodings : 1 | 56/ 56 ( 0.0%) 25/05/2021 09:38:12 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 25/05/2021 09:38:12 TOTALS : 10171 | 100803/ 100803 ( 0.0%) 25/05/2021 09:38:12 destroyed xdamage object: 0x40002f 25/05/2021 14:48:17 Got connection from client 127.0.0.1 25/05/2021 14:48:17 other clients: 25/05/2021 14:48:17 Got 'ws' WebSockets handshake 25/05/2021 14:48:17 Got protocol: binary 25/05/2021 14:48:17 - webSocketsHandshake: using binary/raw encoding 25/05/2021 14:48:17 - WebSockets client version hybi-13 25/05/2021 14:48:17 Disabled X server key autorepeat. 25/05/2021 14:48:17 to force back on run: 'xset r on' (3 times) 25/05/2021 14:48:17 incr accepted_client=4 for 127.0.0.1:40196 sock=10 25/05/2021 14:48:17 Client Protocol Version 3.8 25/05/2021 14:48:17 Protocol version sent 3.8, using 3.8 25/05/2021 14:48:17 rfbProcessClientSecurityType: executing handler for type 1 25/05/2021 14:48:17 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 25/05/2021 14:48:17 Pixel format for client 127.0.0.1: 25/05/2021 14:48:17 32 bpp, depth 24, little endian 25/05/2021 14:48:17 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 25/05/2021 14:48:17 no translation needed 25/05/2021 14:48:17 Enabling NewFBSize protocol extension for client 127.0.0.1 25/05/2021 14:48:17 Enabling full-color cursor updates for client 127.0.0.1 25/05/2021 14:48:17 Using image quality level 6 for client 127.0.0.1 25/05/2021 14:48:17 Using JPEG subsampling 0, Q79 for client 127.0.0.1 25/05/2021 14:48:17 Using compression level 9 for client 127.0.0.1 25/05/2021 14:48:17 Enabling LastRect protocol extension for client 127.0.0.1 25/05/2021 14:48:17 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 25/05/2021 14:48:17 Using tight encoding for client 127.0.0.1 25/05/2021 14:48:17 client_set_net: 127.0.0.1 0.0000 25/05/2021 14:48:17 created xdamage object: 0x400030 25/05/2021 14:48:23 got closure, reason 1001 25/05/2021 14:48:23 rfbProcessClientNormalMessage: read: Connection reset by peer 25/05/2021 14:48:23 client_count: 0 25/05/2021 14:48:23 Restored X server key autorepeat to: 1 25/05/2021 14:48:23 Client 127.0.0.1 gone 25/05/2021 14:48:23 Statistics events Transmit/ RawEquiv ( saved) 25/05/2021 14:48:23 FramebufferUpdate : 190 | 0/ 0 ( 0.0%) 25/05/2021 14:48:23 LastRect : 1 | 12/ 12 ( 0.0%) 25/05/2021 14:48:23 tight : 263 | 257050/ 6357460 ( 96.0%) 25/05/2021 14:48:23 RichCursor : 1 | 1374/ 1374 ( 0.0%) 25/05/2021 14:48:23 TOTALS : 455 | 258436/ 6358846 ( 95.9%) 25/05/2021 14:48:23 Statistics events Received/ RawEquiv ( saved) 25/05/2021 14:48:23 PointerEvent : 106 | 636/ 636 ( 0.0%) 25/05/2021 14:48:23 FramebufferUpdate : 190 | 1900/ 1900 ( 0.0%) 25/05/2021 14:48:23 SetEncodings : 1 | 56/ 56 ( 0.0%) 25/05/2021 14:48:23 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 25/05/2021 14:48:23 TOTALS : 298 | 2612/ 2612 ( 0.0%) 25/05/2021 14:48:23 destroyed xdamage object: 0x400030 27/05/2021 10:30:38 Got connection from client 127.0.0.1 27/05/2021 10:30:38 other clients: 27/05/2021 10:30:38 Got 'ws' WebSockets handshake 27/05/2021 10:30:38 Got protocol: binary 27/05/2021 10:30:38 - webSocketsHandshake: using binary/raw encoding 27/05/2021 10:30:38 - WebSockets client version hybi-13 27/05/2021 10:30:38 Disabled X server key autorepeat. 27/05/2021 10:30:38 to force back on run: 'xset r on' (3 times) 27/05/2021 10:30:38 incr accepted_client=5 for 127.0.0.1:48226 sock=10 27/05/2021 10:30:38 Client Protocol Version 3.8 27/05/2021 10:30:38 Protocol version sent 3.8, using 3.8 27/05/2021 10:30:38 rfbProcessClientSecurityType: executing handler for type 1 27/05/2021 10:30:38 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 27/05/2021 10:30:38 Pixel format for client 127.0.0.1: 27/05/2021 10:30:38 32 bpp, depth 24, little endian 27/05/2021 10:30:38 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 27/05/2021 10:30:38 no translation needed 27/05/2021 10:30:38 Enabling NewFBSize protocol extension for client 127.0.0.1 27/05/2021 10:30:38 Enabling full-color cursor updates for client 127.0.0.1 27/05/2021 10:30:38 Using image quality level 6 for client 127.0.0.1 27/05/2021 10:30:38 Using JPEG subsampling 0, Q79 for client 127.0.0.1 27/05/2021 10:30:38 Using compression level 9 for client 127.0.0.1 27/05/2021 10:30:38 Enabling LastRect protocol extension for client 127.0.0.1 27/05/2021 10:30:38 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 27/05/2021 10:30:38 Using tight encoding for client 127.0.0.1 27/05/2021 10:30:39 client_set_net: 127.0.0.1 0.0000 27/05/2021 10:30:39 created xdamage object: 0x400031 27/05/2021 10:31:31 client 5 network rate 1581.7 KB/sec (61128.6 eff KB/sec) 27/05/2021 10:31:31 client 5 latency: 0.8 ms 27/05/2021 10:31:31 dt1: 0.0036, dt2: 0.0049 dt3: 0.0008 bytes: 12827 27/05/2021 10:31:31 link_rate: LR_LAN - 1 ms, 1581 KB/s 27/05/2021 10:35:39 idle keyboard: turning X autorepeat back on. 27/05/2021 10:39:33 got closure, reason 1001 27/05/2021 10:39:33 rfbProcessClientNormalMessage: read: Connection reset by peer 27/05/2021 10:39:33 client_count: 0 27/05/2021 10:39:33 Client 127.0.0.1 gone 27/05/2021 10:39:33 Statistics events Transmit/ RawEquiv ( saved) 27/05/2021 10:39:33 ServerCutText : 2 | 27/ 27 ( 0.0%) 27/05/2021 10:39:33 FramebufferUpdate : 17527 | 0/ 0 ( 0.0%) 27/05/2021 10:39:33 LastRect : 8 | 96/ 96 ( 0.0%) 27/05/2021 10:39:33 tight : 18970 | 19907892/228077368 ( 91.3%) 27/05/2021 10:39:33 RichCursor : 1 | 1374/ 1374 ( 0.0%) 27/05/2021 10:39:33 TOTALS : 36508 | 19909389/228078865 ( 91.3%) 27/05/2021 10:39:33 Statistics events Received/ RawEquiv ( saved) 27/05/2021 10:39:33 ClientCutText : 2 | 41/ 41 ( 0.0%) 27/05/2021 10:39:33 PointerEvent : 940 | 5640/ 5640 ( 0.0%) 27/05/2021 10:39:33 FramebufferUpdate : 17527 | 175270/ 175270 ( 0.0%) 27/05/2021 10:39:33 SetEncodings : 1 | 56/ 56 ( 0.0%) 27/05/2021 10:39:33 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 27/05/2021 10:39:33 TOTALS : 18471 | 181027/ 181027 ( 0.0%) 27/05/2021 10:39:33 destroyed xdamage object: 0x400031 27/05/2021 17:11:31 Got connection from client 127.0.0.1 27/05/2021 17:11:31 other clients: 27/05/2021 17:11:31 Got 'ws' WebSockets handshake 27/05/2021 17:11:31 Got protocol: binary 27/05/2021 17:11:31 - webSocketsHandshake: using binary/raw encoding 27/05/2021 17:11:31 - WebSockets client version hybi-13 27/05/2021 17:11:31 Disabled X server key autorepeat. 27/05/2021 17:11:31 to force back on run: 'xset r on' (3 times) 27/05/2021 17:11:31 incr accepted_client=6 for 127.0.0.1:38430 sock=10 27/05/2021 17:11:31 Client Protocol Version 3.8 27/05/2021 17:11:31 Protocol version sent 3.8, using 3.8 27/05/2021 17:11:31 rfbProcessClientSecurityType: executing handler for type 1 27/05/2021 17:11:31 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 27/05/2021 17:11:31 Pixel format for client 127.0.0.1: 27/05/2021 17:11:31 32 bpp, depth 24, little endian 27/05/2021 17:11:31 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 27/05/2021 17:11:31 no translation needed 27/05/2021 17:11:31 Enabling NewFBSize protocol extension for client 127.0.0.1 27/05/2021 17:11:31 Enabling full-color cursor updates for client 127.0.0.1 27/05/2021 17:11:31 Using image quality level 6 for client 127.0.0.1 27/05/2021 17:11:31 Using JPEG subsampling 0, Q79 for client 127.0.0.1 27/05/2021 17:11:31 Using compression level 9 for client 127.0.0.1 27/05/2021 17:11:31 Enabling LastRect protocol extension for client 127.0.0.1 27/05/2021 17:11:31 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 27/05/2021 17:11:31 Using tight encoding for client 127.0.0.1 27/05/2021 17:11:34 client_set_net: 127.0.0.1 0.0000 27/05/2021 17:11:34 active keyboard: turning X autorepeat off. 27/05/2021 17:11:34 created xdamage object: 0x400032 27/05/2021 17:11:48 client 6 network rate 449.4 KB/sec (17186.3 eff KB/sec) 27/05/2021 17:11:48 client 6 latency: 2.0 ms 27/05/2021 17:11:48 dt1: 0.0034, dt2: 0.0260 dt3: 0.0020 bytes: 12794 27/05/2021 17:11:48 link_rate: LR_LAN - 2 ms, 449 KB/s 27/05/2021 17:16:32 idle keyboard: turning X autorepeat back on. 27/05/2021 17:18:59 got closure, reason 1001 27/05/2021 17:18:59 rfbProcessClientNormalMessage: read: Connection reset by peer 27/05/2021 17:18:59 client_count: 0 27/05/2021 17:18:59 Client 127.0.0.1 gone 27/05/2021 17:18:59 Statistics events Transmit/ RawEquiv ( saved) 27/05/2021 17:18:59 FramebufferUpdate : 15384 | 0/ 0 ( 0.0%) 27/05/2021 17:18:59 LastRect : 9 | 108/ 108 ( 0.0%) 27/05/2021 17:18:59 tight : 16737 | 17555953/201404812 ( 91.3%) 27/05/2021 17:18:59 RichCursor : 1 | 1374/ 1374 ( 0.0%) 27/05/2021 17:18:59 TOTALS : 32131 | 17557435/201406294 ( 91.3%) 27/05/2021 17:18:59 Statistics events Received/ RawEquiv ( saved) 27/05/2021 17:18:59 ClientCutText : 1 | 32/ 32 ( 0.0%) 27/05/2021 17:18:59 PointerEvent : 302 | 1812/ 1812 ( 0.0%) 27/05/2021 17:18:59 FramebufferUpdate : 15385 | 153850/ 153850 ( 0.0%) 27/05/2021 17:18:59 SetEncodings : 1 | 56/ 56 ( 0.0%) 27/05/2021 17:18:59 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 27/05/2021 17:18:59 TOTALS : 15690 | 155770/ 155770 ( 0.0%) 27/05/2021 17:18:59 destroyed xdamage object: 0x400032 [services.d] stopping services [services.d] stopping app... [services.d] stopping x11vnc... caught signal: 15 27/05/2021 17:19:02 deleted 40 tile_row polling images. [services.d] stopping openbox... [services.d] stopping logmonitor... [services.d] stopping statusmonitor... [services.d] stopping CrashPlanEngine... s6-svlisten1: fatal: timed out [services.d] stopping xvfb... [services.d] stopping nginx... [services.d] stopping certsmonitor... [services.d] stopping s6-fdholderd... [cont-finish.d] executing container finish scripts... [cont-finish.d] done. [s6-finish] syncing disks. [s6-finish] sending all processes the TERM signal. [s6-finish] sending all processes the KILL signal and exiting. [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 00-app-niceness.sh: executing... [cont-init.d] 00-app-niceness.sh: exited 0. [cont-init.d] 00-app-script.sh: executing... [cont-init.d] 00-app-script.sh: exited 0. [cont-init.d] 00-app-user-map.sh: executing... [cont-init.d] 00-app-user-map.sh: exited 0. [cont-init.d] 00-clean-logmonitor-states.sh: executing... [cont-init.d] 00-clean-logmonitor-states.sh: exited 0. [cont-init.d] 00-clean-tmp-dir.sh: executing... [cont-init.d] 00-clean-tmp-dir.sh: exited 0. [cont-init.d] 00-set-app-deps.sh: executing... [cont-init.d] 00-set-app-deps.sh: exited 0. [cont-init.d] 00-set-home.sh: executing... [cont-init.d] 00-set-home.sh: exited 0. [cont-init.d] 00-take-config-ownership.sh: executing... [cont-init.d] 00-take-config-ownership.sh: exited 0. [cont-init.d] 00-xdg-runtime-dir.sh: executing... [cont-init.d] 00-xdg-runtime-dir.sh: exited 0. [cont-init.d] 10-certs.sh: executing... [cont-init.d] 10-certs.sh: exited 0. [cont-init.d] 10-cjk-font.sh: executing... [cont-init.d] 10-cjk-font.sh: exited 0. [cont-init.d] 10-nginx.sh: executing... [cont-init.d] 10-nginx.sh: exited 0. [cont-init.d] 10-vnc-password.sh: executing... [cont-init.d] 10-vnc-password.sh: exited 0. [cont-init.d] 10-web-index.sh: executing... [cont-init.d] 10-web-index.sh: exited 0. [cont-init.d] crashplan-pro.sh: executing... [cont-init.d] crashplan-pro.sh: setting CrashPlan Engine maximum memory to 3072M [cont-init.d] crashplan-pro.sh: exited 0. [cont-init.d] validate_max_mem.sh: executing... [cont-init.d] validate_max_mem.sh: exited 0. [cont-init.d] done. [services.d] starting services [services.d] starting s6-fdholderd... [services.d] starting certsmonitor... [services.d] starting nginx... [services.d] starting xvfb... [nginx] starting... [certsmonitor] disabling service: secure connection not enabled. [xvfb] starting... [services.d] starting CrashPlanEngine... [CrashPlanEngine] starting... s6-svwait: fatal: timed out [services.d] starting logmonitor... [services.d] starting statusmonitor... [services.d] starting openbox... [logmonitor] starting... [statusmonitor] starting... [openbox] starting... [services.d] starting x11vnc... [services.d] starting app... [x11vnc] starting... [app] starting CrashPlan for Small Business... 27/05/2021 17:19:24 passing arg to libvncserver: -rfbport 27/05/2021 17:19:24 passing arg to libvncserver: 5900 27/05/2021 17:19:24 passing arg to libvncserver: -rfbportv6 27/05/2021 17:19:24 passing arg to libvncserver: -1 27/05/2021 17:19:24 passing arg to libvncserver: -httpportv6 27/05/2021 17:19:24 passing arg to libvncserver: -1 27/05/2021 17:19:24 passing arg to libvncserver: -desktop 27/05/2021 17:19:24 passing arg to libvncserver: CrashPlan for Small Business [services.d] done. 27/05/2021 17:19:24 x11vnc version: 0.9.14 lastmod: 2015-11-14 pid: 5226 27/05/2021 17:19:24 Using X display :0 27/05/2021 17:19:24 rootwin: 0x43 reswin: 0x400001 dpy: 0xf19bfa00 27/05/2021 17:19:24 27/05/2021 17:19:24 ------------------ USEFUL INFORMATION ------------------ 27/05/2021 17:19:24 X DAMAGE available on display, using it for polling hints. 27/05/2021 17:19:24 To disable this behavior use: '-noxdamage' 27/05/2021 17:19:24 27/05/2021 17:19:24 Most compositing window managers like 'compiz' or 'beryl' 27/05/2021 17:19:24 cause X DAMAGE to fail, and so you may not see any screen 27/05/2021 17:19:24 updates via VNC. Either disable 'compiz' (recommended) or 27/05/2021 17:19:24 supply the x11vnc '-noxdamage' command line option. 27/05/2021 17:19:24 X COMPOSITE available on display, using it for window polling. 27/05/2021 17:19:24 To disable this behavior use: '-noxcomposite' 27/05/2021 17:19:24 27/05/2021 17:19:24 Wireframing: -wireframe mode is in effect for window moves. 27/05/2021 17:19:24 If this yields undesired behavior (poor response, painting 27/05/2021 17:19:24 errors, etc) it may be disabled: 27/05/2021 17:19:24 - use '-nowf' to disable wireframing completely. 27/05/2021 17:19:24 - use '-nowcr' to disable the Copy Rectangle after the 27/05/2021 17:19:24 moved window is released in the new position. 27/05/2021 17:19:24 Also see the -help entry for tuning parameters. 27/05/2021 17:19:24 You can press 3 Alt_L's (Left "Alt" key) in a row to 27/05/2021 17:19:24 repaint the screen, also see the -fixscreen option for 27/05/2021 17:19:24 periodic repaints. 27/05/2021 17:19:24 GrabServer control via XTEST. 27/05/2021 17:19:24 27/05/2021 17:19:24 Scroll Detection: -scrollcopyrect mode is in effect to 27/05/2021 17:19:24 use RECORD extension to try to detect scrolling windows 27/05/2021 17:19:24 (induced by either user keystroke or mouse input). 27/05/2021 17:19:24 If this yields undesired behavior (poor response, painting 27/05/2021 17:19:24 errors, etc) it may be disabled via: '-noscr' 27/05/2021 17:19:24 Also see the -help entry for tuning parameters. 27/05/2021 17:19:24 You can press 3 Alt_L's (Left "Alt" key) in a row to 27/05/2021 17:19:24 repaint the screen, also see the -fixscreen option for 27/05/2021 17:19:24 periodic repaints. 27/05/2021 17:19:24 27/05/2021 17:19:24 XKEYBOARD: number of keysyms per keycode 7 is greater 27/05/2021 17:19:24 than 4 and 51 keysyms are mapped above 4. 27/05/2021 17:19:24 Automatically switching to -xkb mode. 27/05/2021 17:19:24 If this makes the key mapping worse you can 27/05/2021 17:19:24 disable it with the "-noxkb" option. 27/05/2021 17:19:24 Also, remember "-remap DEAD" for accenting characters. 27/05/2021 17:19:24 27/05/2021 17:19:24 X FBPM extension not supported. 27/05/2021 17:19:24 X display is not capable of DPMS. 27/05/2021 17:19:24 -------------------------------------------------------- 27/05/2021 17:19:24 27/05/2021 17:19:24 Default visual ID: 0x21 27/05/2021 17:19:24 Read initial data from X display into framebuffer. 27/05/2021 17:19:24 initialize_screen: fb_depth/fb_bpp/fb_Bpl 24/32/5120 27/05/2021 17:19:24 27/05/2021 17:19:24 X display :0 is 32bpp depth=24 true color 27/05/2021 17:19:24 27/05/2021 17:19:24 Listening for VNC connections on TCP port 5900 27/05/2021 17:19:24 27/05/2021 17:19:24 Xinerama is present and active (e.g. multi-head). 27/05/2021 17:19:24 Xinerama: number of sub-screens: 1 27/05/2021 17:19:24 Xinerama: no blackouts needed (only one sub-screen) 27/05/2021 17:19:24 27/05/2021 17:19:24 fb read rate: 1163 MB/sec 27/05/2021 17:19:24 fast read: reset -wait ms to: 10 27/05/2021 17:19:24 fast read: reset -defer ms to: 10 27/05/2021 17:19:24 The X server says there are 10 mouse buttons. 27/05/2021 17:19:24 screen setup finished. 27/05/2021 17:19:24 The VNC desktop is: 1e463f695312:0 PORT=5900 ****************************************************************************** Have you tried the x11vnc '-ncache' VNC client-side pixel caching feature yet? The scheme stores pixel data offscreen on the VNC viewer side for faster retrieval. It should work with any VNC viewer. Try it by running: x11vnc -ncache 10 ... One can also add -ncache_cr for smooth 'copyrect' window motion. More info: http://www.karlrunge.com/x11vnc/faq.html#faq-client-caching 27/05/2021 17:19:33 Got connection from client 127.0.0.1 27/05/2021 17:19:33 other clients: 27/05/2021 17:19:33 Got 'ws' WebSockets handshake 27/05/2021 17:19:33 Got protocol: binary 27/05/2021 17:19:33 - webSocketsHandshake: using binary/raw encoding 27/05/2021 17:19:33 - WebSockets client version hybi-13 27/05/2021 17:19:33 Disabled X server key autorepeat. 27/05/2021 17:19:33 to force back on run: 'xset r on' (3 times) 27/05/2021 17:19:33 incr accepted_client=1 for 127.0.0.1:38900 sock=10 27/05/2021 17:19:33 Client Protocol Version 3.8 27/05/2021 17:19:33 Protocol version sent 3.8, using 3.8 27/05/2021 17:19:33 rfbProcessClientSecurityType: executing handler for type 1 27/05/2021 17:19:33 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 27/05/2021 17:19:33 Pixel format for client 127.0.0.1: 27/05/2021 17:19:33 32 bpp, depth 24, little endian 27/05/2021 17:19:33 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 27/05/2021 17:19:33 no translation needed 27/05/2021 17:19:33 Enabling NewFBSize protocol extension for client 127.0.0.1 27/05/2021 17:19:33 Enabling full-color cursor updates for client 127.0.0.1 27/05/2021 17:19:33 Using image quality level 6 for client 127.0.0.1 27/05/2021 17:19:33 Using JPEG subsampling 0, Q79 for client 127.0.0.1 27/05/2021 17:19:33 Using compression level 9 for client 127.0.0.1 27/05/2021 17:19:33 Enabling LastRect protocol extension for client 127.0.0.1 27/05/2021 17:19:33 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 27/05/2021 17:19:33 Using tight encoding for client 127.0.0.1 27/05/2021 17:19:34 client_set_net: 127.0.0.1 0.0000 27/05/2021 17:19:34 created xdamage object: 0x40002c 27/05/2021 17:19:34 copy_tiles: allocating first_line at size 41 27/05/2021 17:19:42 created selwin: 0x40002d 27/05/2021 17:19:42 called initialize_xfixes() 27/05/2021 17:19:47 client 1 network rate 581.5 KB/sec (20059.9 eff KB/sec) 27/05/2021 17:19:47 client 1 latency: 1.3 ms 27/05/2021 17:19:47 dt1: 0.0036, dt2: 0.0225 dt3: 0.0013 bytes: 14831 27/05/2021 17:19:47 link_rate: LR_LAN - 1 ms, 581 KB/s 27/05/2021 17:20:14 got closure, reason 1001 27/05/2021 17:20:14 rfbProcessClientNormalMessage: read: Connection reset by peer 27/05/2021 17:20:14 client_count: 0 27/05/2021 17:20:14 Restored X server key autorepeat to: 1 27/05/2021 17:20:14 Client 127.0.0.1 gone 27/05/2021 17:20:14 Statistics events Transmit/ RawEquiv ( saved) 27/05/2021 17:20:14 FramebufferUpdate : 1080 | 0/ 0 ( 0.0%) 27/05/2021 17:20:14 LastRect : 9 | 108/ 108 ( 0.0%) 27/05/2021 17:20:14 tight : 1275 | 1204996/ 18245444 ( 93.4%) 27/05/2021 17:20:14 RichCursor : 1 | 1374/ 1374 ( 0.0%) 27/05/2021 17:20:14 TOTALS : 2365 | 1206478/ 18246926 ( 93.4%) 27/05/2021 17:20:14 Statistics events Received/ RawEquiv ( saved) 27/05/2021 17:20:14 ClientCutText : 1 | 32/ 32 ( 0.0%) 27/05/2021 17:20:14 PointerEvent : 290 | 1740/ 1740 ( 0.0%) 27/05/2021 17:20:14 FramebufferUpdate : 1080 | 10800/ 10800 ( 0.0%) 27/05/2021 17:20:14 SetEncodings : 1 | 56/ 56 ( 0.0%) 27/05/2021 17:20:14 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 27/05/2021 17:20:14 TOTALS : 1373 | 12648/ 12648 ( 0.0%) 27/05/2021 17:20:14 destroyed xdamage object: 0x40002c 28/05/2021 11:38:21 Got connection from client 127.0.0.1 28/05/2021 11:38:21 other clients: 28/05/2021 11:38:21 Got 'ws' WebSockets handshake 28/05/2021 11:38:21 Got protocol: binary 28/05/2021 11:38:21 - webSocketsHandshake: using binary/raw encoding 28/05/2021 11:38:21 - WebSockets client version hybi-13 28/05/2021 11:38:21 Disabled X server key autorepeat. 28/05/2021 11:38:21 to force back on run: 'xset r on' (3 times) 28/05/2021 11:38:21 incr accepted_client=2 for 127.0.0.1:39826 sock=10 28/05/2021 11:38:21 Client Protocol Version 3.8 28/05/2021 11:38:21 Protocol version sent 3.8, using 3.8 28/05/2021 11:38:21 rfbProcessClientSecurityType: executing handler for type 1 28/05/2021 11:38:21 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 28/05/2021 11:38:21 Pixel format for client 127.0.0.1: 28/05/2021 11:38:21 32 bpp, depth 24, little endian 28/05/2021 11:38:21 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 28/05/2021 11:38:21 no translation needed 28/05/2021 11:38:21 Enabling NewFBSize protocol extension for client 127.0.0.1 28/05/2021 11:38:21 Enabling full-color cursor updates for client 127.0.0.1 28/05/2021 11:38:21 Using image quality level 6 for client 127.0.0.1 28/05/2021 11:38:21 Using JPEG subsampling 0, Q79 for client 127.0.0.1 28/05/2021 11:38:21 Using compression level 9 for client 127.0.0.1 28/05/2021 11:38:21 Enabling LastRect protocol extension for client 127.0.0.1 28/05/2021 11:38:21 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 28/05/2021 11:38:21 Using tight encoding for client 127.0.0.1 28/05/2021 11:38:22 client_set_net: 127.0.0.1 0.0001 28/05/2021 11:38:22 created xdamage object: 0x40002e 28/05/2021 11:43:22 idle keyboard: turning X autorepeat back on. 28/05/2021 15:13:22 active keyboard: turning X autorepeat off. 28/05/2021 15:18:22 idle keyboard: turning X autorepeat back on. 28/05/2021 16:44:58 active keyboard: turning X autorepeat off. 28/05/2021 16:49:58 idle keyboard: turning X autorepeat back on. 28/05/2021 17:35:24 client 2 network rate 391.1 KB/sec (15056.6 eff KB/sec) 28/05/2021 17:35:24 client 2 latency: 1.3 ms 28/05/2021 17:35:24 dt1: 0.0048, dt2: 0.0288 dt3: 0.0013 bytes: 12875 28/05/2021 17:35:24 link_rate: LR_LAN - 1 ms, 391 KB/s 28/05/2021 17:37:02 got closure, reason 1001 28/05/2021 17:37:02 rfbProcessClientNormalMessage: read: Connection reset by peer 28/05/2021 17:37:02 client_count: 0 28/05/2021 17:37:02 Client 127.0.0.1 gone 28/05/2021 17:37:02 Statistics events Transmit/ RawEquiv ( saved) 28/05/2021 17:37:02 FramebufferUpdate : 758574 | 0/ 0 ( 0.0%) 28/05/2021 17:37:02 LastRect : 26 | 312/ 312 ( 0.0%) 28/05/2021 17:37:02 tight : 817643 | 866208532/1130742276 ( 23.4%) 28/05/2021 17:37:02 RichCursor : 1 | 1374/ 1374 ( 0.0%) 28/05/2021 17:37:02 TOTALS : 1576244 | 866210218/1130743962 ( 23.4%) 28/05/2021 17:37:02 Statistics events Received/ RawEquiv ( saved) 28/05/2021 17:37:02 ClientCutText : 2 | 41/ 41 ( 0.0%) 28/05/2021 17:37:02 KeyEvent : 6 | 48/ 48 ( 0.0%) 28/05/2021 17:37:02 PointerEvent : 1019 | 6114/ 6114 ( 0.0%) 28/05/2021 17:37:02 FramebufferUpdate : 758575 | 7585750/ 7585750 ( 0.0%) 28/05/2021 17:37:02 SetEncodings : 1 | 56/ 56 ( 0.0%) 28/05/2021 17:37:02 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 28/05/2021 17:37:02 TOTALS : 759604 | 7592029/ 7592029 ( 0.0%) 28/05/2021 17:37:02 destroyed xdamage object: 0x40002e 28/05/2021 20:53:15 Got connection from client 127.0.0.1 28/05/2021 20:53:15 other clients: 28/05/2021 20:53:15 Got 'ws' WebSockets handshake 28/05/2021 20:53:15 Got protocol: binary 28/05/2021 20:53:15 - webSocketsHandshake: using binary/raw encoding 28/05/2021 20:53:15 - WebSockets client version hybi-13 28/05/2021 20:53:15 Disabled X server key autorepeat. 28/05/2021 20:53:15 to force back on run: 'xset r on' (3 times) 28/05/2021 20:53:15 incr accepted_client=3 for 127.0.0.1:36782 sock=10 28/05/2021 20:53:15 Client Protocol Version 3.8 28/05/2021 20:53:15 Protocol version sent 3.8, using 3.8 28/05/2021 20:53:15 rfbProcessClientSecurityType: executing handler for type 1 28/05/2021 20:53:15 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 28/05/2021 20:53:15 Pixel format for client 127.0.0.1: 28/05/2021 20:53:15 32 bpp, depth 24, little endian 28/05/2021 20:53:15 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 28/05/2021 20:53:15 no translation needed 28/05/2021 20:53:15 Enabling NewFBSize protocol extension for client 127.0.0.1 28/05/2021 20:53:15 Enabling full-color cursor updates for client 127.0.0.1 28/05/2021 20:53:15 Using image quality level 6 for client 127.0.0.1 28/05/2021 20:53:15 Using JPEG subsampling 0, Q79 for client 127.0.0.1 28/05/2021 20:53:15 Using compression level 9 for client 127.0.0.1 28/05/2021 20:53:15 Enabling LastRect protocol extension for client 127.0.0.1 28/05/2021 20:53:15 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 28/05/2021 20:53:15 Using tight encoding for client 127.0.0.1 28/05/2021 20:53:15 client_set_net: 127.0.0.1 0.0001 28/05/2021 20:53:15 active keyboard: turning X autorepeat off. 28/05/2021 20:53:15 created xdamage object: 0x40002f 28/05/2021 20:58:17 idle keyboard: turning X autorepeat back on. 28/05/2021 21:53:43 client_count: 0 28/05/2021 21:53:43 Client 127.0.0.1 gone 28/05/2021 21:53:43 Statistics events Transmit/ RawEquiv ( saved) 28/05/2021 21:53:43 FramebufferUpdate : 142464 | 0/ 0 ( 0.0%) 28/05/2021 21:53:43 LastRect : 1 | 12/ 12 ( 0.0%) 28/05/2021 21:53:43 tight : 154830 | 162744052/1828173608 ( 91.1%) 28/05/2021 21:53:43 RichCursor : 1 | 1374/ 1374 ( 0.0%) 28/05/2021 21:53:43 TOTALS : 297296 | 162745438/1828174994 ( 91.1%) 28/05/2021 21:53:43 Statistics events Received/ RawEquiv ( saved) 28/05/2021 21:53:43 PointerEvent : 193 | 1158/ 1158 ( 0.0%) 28/05/2021 21:53:43 FramebufferUpdate : 142464 | 1424640/ 1424640 ( 0.0%) 28/05/2021 21:53:43 SetEncodings : 1 | 56/ 56 ( 0.0%) 28/05/2021 21:53:43 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 28/05/2021 21:53:43 TOTALS : 142659 | 1425874/ 1425874 ( 0.0%) 28/05/2021 21:53:43 destroyed xdamage object: 0x40002f 01/06/2021 11:05:16 Got connection from client 127.0.0.1 01/06/2021 11:05:16 other clients: 01/06/2021 11:05:16 Got 'ws' WebSockets handshake 01/06/2021 11:05:16 Got protocol: binary 01/06/2021 11:05:16 - webSocketsHandshake: using binary/raw encoding 01/06/2021 11:05:16 - WebSockets client version hybi-13 01/06/2021 11:05:16 Disabled X server key autorepeat. 01/06/2021 11:05:16 to force back on run: 'xset r on' (3 times) 01/06/2021 11:05:16 incr accepted_client=4 for 127.0.0.1:57574 sock=10 01/06/2021 11:05:16 Client Protocol Version 3.8 01/06/2021 11:05:16 Protocol version sent 3.8, using 3.8 01/06/2021 11:05:16 rfbProcessClientSecurityType: executing handler for type 1 01/06/2021 11:05:16 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 01/06/2021 11:05:17 Pixel format for client 127.0.0.1: 01/06/2021 11:05:17 32 bpp, depth 24, little endian 01/06/2021 11:05:17 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 01/06/2021 11:05:17 no translation needed 01/06/2021 11:05:17 Enabling NewFBSize protocol extension for client 127.0.0.1 01/06/2021 11:05:17 Enabling full-color cursor updates for client 127.0.0.1 01/06/2021 11:05:17 Using image quality level 6 for client 127.0.0.1 01/06/2021 11:05:17 Using JPEG subsampling 0, Q79 for client 127.0.0.1 01/06/2021 11:05:17 Using compression level 9 for client 127.0.0.1 01/06/2021 11:05:17 Enabling LastRect protocol extension for client 127.0.0.1 01/06/2021 11:05:17 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 01/06/2021 11:05:17 Using tight encoding for client 127.0.0.1 01/06/2021 11:05:21 client_set_net: 127.0.0.1 0.0000 01/06/2021 11:05:21 active keyboard: turning X autorepeat off. 01/06/2021 11:05:21 created xdamage object: 0x400030 01/06/2021 11:06:43 client 4 network rate 1126.5 KB/sec (39085.3 eff KB/sec) 01/06/2021 11:06:43 client 4 latency: 1.2 ms 01/06/2021 11:06:43 dt1: 0.0044, dt2: 0.0101 dt3: 0.0012 bytes: 15651 01/06/2021 11:06:43 link_rate: LR_LAN - 1 ms, 1126 KB/s 01/06/2021 11:10:17 idle keyboard: turning X autorepeat back on. 01/06/2021 11:36:33 active keyboard: turning X autorepeat off. 01/06/2021 11:41:47 idle keyboard: turning X autorepeat back on. 01/06/2021 12:36:13 got closure, reason 1001 01/06/2021 12:36:13 rfbProcessClientNormalMessage: read: Connection reset by peer 01/06/2021 12:36:13 client_count: 0 01/06/2021 12:36:13 Client 127.0.0.1 gone 01/06/2021 12:36:13 Statistics events Transmit/ RawEquiv ( saved) 01/06/2021 12:36:13 FramebufferUpdate : 196623 | 0/ 0 ( 0.0%) 01/06/2021 12:36:13 LastRect : 577 | 6924/ 6924 ( 0.0%) 01/06/2021 12:36:13 tight : 234878 | 241511129/-1238813464 ( 0.0%) 01/06/2021 12:36:13 RichCursor : 1 | 1374/ 1374 ( 0.0%) 01/06/2021 12:36:13 TOTALS : 432079 | 241519427/-1238805166 ( 0.0%) 01/06/2021 12:36:13 Statistics events Received/ RawEquiv ( saved) 01/06/2021 12:36:13 KeyEvent : 15 | 120/ 120 ( 0.0%) 01/06/2021 12:36:13 ClientCutText : 4 | 105/ 105 ( 0.0%) 01/06/2021 12:36:13 PointerEvent : 3372 | 20232/ 20232 ( 0.0%) 01/06/2021 12:36:13 FramebufferUpdate : 196623 | 1966230/ 1966230 ( 0.0%) 01/06/2021 12:36:13 SetEncodings : 1 | 56/ 56 ( 0.0%) 01/06/2021 12:36:13 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 01/06/2021 12:36:13 TOTALS : 200016 | 1986763/ 1986763 ( 0.0%) 01/06/2021 12:36:13 destroyed xdamage object: 0x400030 02/06/2021 09:40:40 Got connection from client 127.0.0.1 02/06/2021 09:40:40 other clients: 02/06/2021 09:40:40 Got 'ws' WebSockets handshake 02/06/2021 09:40:40 Got protocol: binary 02/06/2021 09:40:40 - webSocketsHandshake: using binary/raw encoding 02/06/2021 09:40:40 - WebSockets client version hybi-13 02/06/2021 09:40:40 Disabled X server key autorepeat. 02/06/2021 09:40:40 to force back on run: 'xset r on' (3 times) 02/06/2021 09:40:40 incr accepted_client=5 for 127.0.0.1:32850 sock=10 02/06/2021 09:40:40 Client Protocol Version 3.8 02/06/2021 09:40:40 Protocol version sent 3.8, using 3.8 02/06/2021 09:40:40 rfbProcessClientSecurityType: executing handler for type 1 02/06/2021 09:40:40 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 02/06/2021 09:40:41 Pixel format for client 127.0.0.1: 02/06/2021 09:40:41 32 bpp, depth 24, little endian 02/06/2021 09:40:41 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 02/06/2021 09:40:41 no translation needed 02/06/2021 09:40:41 Enabling NewFBSize protocol extension for client 127.0.0.1 02/06/2021 09:40:41 Enabling full-color cursor updates for client 127.0.0.1 02/06/2021 09:40:41 Using image quality level 6 for client 127.0.0.1 02/06/2021 09:40:41 Using JPEG subsampling 0, Q79 for client 127.0.0.1 02/06/2021 09:40:41 Using compression level 9 for client 127.0.0.1 02/06/2021 09:40:41 Enabling LastRect protocol extension for client 127.0.0.1 02/06/2021 09:40:41 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 02/06/2021 09:40:41 Using tight encoding for client 127.0.0.1 02/06/2021 09:40:45 client_set_net: 127.0.0.1 0.0000 02/06/2021 09:40:45 active keyboard: turning X autorepeat off. 02/06/2021 09:40:45 created xdamage object: 0x400031 02/06/2021 09:45:41 idle keyboard: turning X autorepeat back on. 02/06/2021 09:52:18 client 5 network rate 417.3 KB/sec (16128.7 eff KB/sec) 02/06/2021 09:52:18 client 5 latency: 1.3 ms 02/06/2021 09:52:18 dt1: 0.0039, dt2: 0.0295 dt3: 0.0013 bytes: 13639 02/06/2021 09:52:18 link_rate: LR_LAN - 1 ms, 417 KB/s 02/06/2021 09:53:34 got closure, reason 1001 02/06/2021 09:53:34 rfbProcessClientNormalMessage: read: Connection reset by peer 02/06/2021 09:53:34 client_count: 0 02/06/2021 09:53:34 Client 127.0.0.1 gone 02/06/2021 09:53:34 Statistics events Transmit/ RawEquiv ( saved) 02/06/2021 09:53:34 FramebufferUpdate : 3184 | 0/ 0 ( 0.0%) 02/06/2021 09:53:34 LastRect : 13 | 156/ 156 ( 0.0%) 02/06/2021 09:53:34 tight : 3523 | 3150918/ 40954148 ( 92.3%) 02/06/2021 09:53:34 RichCursor : 1 | 1374/ 1374 ( 0.0%) 02/06/2021 09:53:34 TOTALS : 6721 | 3152448/ 40955678 ( 92.3%) 02/06/2021 09:53:34 Statistics events Received/ RawEquiv ( saved) 02/06/2021 09:53:34 ClientCutText : 1 | 32/ 32 ( 0.0%) 02/06/2021 09:53:34 PointerEvent : 193 | 1158/ 1158 ( 0.0%) 02/06/2021 09:53:34 FramebufferUpdate : 3185 | 31850/ 31850 ( 0.0%) 02/06/2021 09:53:34 SetEncodings : 1 | 56/ 56 ( 0.0%) 02/06/2021 09:53:34 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 02/06/2021 09:53:34 TOTALS : 3381 | 33116/ 33116 ( 0.0%) 02/06/2021 09:53:34 destroyed xdamage object: 0x400031 03/06/2021 09:09:17 Got connection from client 127.0.0.1 03/06/2021 09:09:17 other clients: 03/06/2021 09:09:17 Got 'ws' WebSockets handshake 03/06/2021 09:09:17 Got protocol: binary 03/06/2021 09:09:17 - webSocketsHandshake: using binary/raw encoding 03/06/2021 09:09:17 - WebSockets client version hybi-13 03/06/2021 09:09:17 Disabled X server key autorepeat. 03/06/2021 09:09:17 to force back on run: 'xset r on' (3 times) 03/06/2021 09:09:17 incr accepted_client=6 for 127.0.0.1:45638 sock=10 03/06/2021 09:09:17 Client Protocol Version 3.8 03/06/2021 09:09:17 Protocol version sent 3.8, using 3.8 03/06/2021 09:09:17 rfbProcessClientSecurityType: executing handler for type 1 03/06/2021 09:09:17 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 03/06/2021 09:09:17 Pixel format for client 127.0.0.1: 03/06/2021 09:09:17 32 bpp, depth 24, little endian 03/06/2021 09:09:17 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 03/06/2021 09:09:17 no translation needed 03/06/2021 09:09:17 Enabling NewFBSize protocol extension for client 127.0.0.1 03/06/2021 09:09:17 Enabling full-color cursor updates for client 127.0.0.1 03/06/2021 09:09:17 Using image quality level 6 for client 127.0.0.1 03/06/2021 09:09:17 Using JPEG subsampling 0, Q79 for client 127.0.0.1 03/06/2021 09:09:17 Using compression level 9 for client 127.0.0.1 03/06/2021 09:09:17 Enabling LastRect protocol extension for client 127.0.0.1 03/06/2021 09:09:17 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 03/06/2021 09:09:17 Using tight encoding for client 127.0.0.1 03/06/2021 09:09:17 client_set_net: 127.0.0.1 0.0001 03/06/2021 09:09:17 active keyboard: turning X autorepeat off. 03/06/2021 09:09:17 created xdamage object: 0x400032 03/06/2021 09:11:49 client 6 network rate 1535.0 KB/sec (75008.3 eff KB/sec) 03/06/2021 09:11:49 client 6 latency: 4.5 ms 03/06/2021 09:11:49 dt1: 0.0094, dt2: 0.0128 dt3: 0.0045 bytes: 30730 03/06/2021 09:11:49 link_rate: LR_LAN - 4 ms, 1534 KB/s 03/06/2021 09:18:27 idle keyboard: turning X autorepeat back on. 03/06/2021 10:01:55 got closure, reason 1001 03/06/2021 10:01:55 rfbProcessClientNormalMessage: read: Connection reset by peer 03/06/2021 10:01:55 client_count: 0 03/06/2021 10:01:55 Client 127.0.0.1 gone 03/06/2021 10:01:55 Statistics events Transmit/ RawEquiv ( saved) 03/06/2021 10:01:55 FramebufferUpdate : 91531 | 0/ 0 ( 0.0%) 03/06/2021 10:01:55 LastRect : 74 | 888/ 888 ( 0.0%) 03/06/2021 10:01:55 tight : 94302 | 104620984/1221656936 ( 91.4%) 03/06/2021 10:01:55 RichCursor : 1 | 1374/ 1374 ( 0.0%) 03/06/2021 10:01:55 TOTALS : 185908 | 104623246/1221659198 ( 91.4%) 03/06/2021 10:01:55 Statistics events Received/ RawEquiv ( saved) 03/06/2021 10:01:55 ClientCutText : 1 | 20/ 20 ( 0.0%) 03/06/2021 10:01:55 KeyEvent : 78 | 624/ 624 ( 0.0%) 03/06/2021 10:01:55 PointerEvent : 1401 | 8406/ 8406 ( 0.0%) 03/06/2021 10:01:55 FramebufferUpdate : 91531 | 915310/ 915310 ( 0.0%) 03/06/2021 10:01:55 SetEncodings : 1 | 56/ 56 ( 0.0%) 03/06/2021 10:01:55 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 03/06/2021 10:01:55 TOTALS : 93013 | 924436/ 924436 ( 0.0%) 03/06/2021 10:01:55 destroyed xdamage object: 0x400032 03/06/2021 10:40:07 Got connection from client 127.0.0.1 03/06/2021 10:40:07 other clients: 03/06/2021 10:40:07 Got 'ws' WebSockets handshake 03/06/2021 10:40:07 Got protocol: binary 03/06/2021 10:40:07 - webSocketsHandshake: using binary/raw encoding 03/06/2021 10:40:07 - WebSockets client version hybi-13 03/06/2021 10:40:07 Disabled X server key autorepeat. 03/06/2021 10:40:07 to force back on run: 'xset r on' (3 times) 03/06/2021 10:40:07 incr accepted_client=7 for 127.0.0.1:51916 sock=10 03/06/2021 10:40:07 Client Protocol Version 3.8 03/06/2021 10:40:07 Protocol version sent 3.8, using 3.8 03/06/2021 10:40:07 rfbProcessClientSecurityType: executing handler for type 1 03/06/2021 10:40:07 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 03/06/2021 10:40:07 Pixel format for client 127.0.0.1: 03/06/2021 10:40:07 32 bpp, depth 24, little endian 03/06/2021 10:40:07 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 03/06/2021 10:40:07 no translation needed 03/06/2021 10:40:07 Enabling NewFBSize protocol extension for client 127.0.0.1 03/06/2021 10:40:07 Enabling full-color cursor updates for client 127.0.0.1 03/06/2021 10:40:07 Using image quality level 6 for client 127.0.0.1 03/06/2021 10:40:07 Using JPEG subsampling 0, Q79 for client 127.0.0.1 03/06/2021 10:40:07 Using compression level 9 for client 127.0.0.1 03/06/2021 10:40:07 Enabling LastRect protocol extension for client 127.0.0.1 03/06/2021 10:40:07 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 03/06/2021 10:40:07 Using tight encoding for client 127.0.0.1 03/06/2021 10:40:08 client_set_net: 127.0.0.1 0.0000 03/06/2021 10:40:08 active keyboard: turning X autorepeat off. 03/06/2021 10:40:08 created xdamage object: 0x400033 03/06/2021 10:45:08 idle keyboard: turning X autorepeat back on. 03/06/2021 11:50:14 got closure, reason 1001 03/06/2021 11:50:14 rfbProcessClientNormalMessage: read: Connection reset by peer 03/06/2021 11:50:14 client_count: 0 03/06/2021 11:50:14 Client 127.0.0.1 gone 03/06/2021 11:50:14 Statistics events Transmit/ RawEquiv ( saved) 03/06/2021 11:50:14 FramebufferUpdate : 122545 | 0/ 0 ( 0.0%) 03/06/2021 11:50:14 LastRect : 7 | 84/ 84 ( 0.0%) 03/06/2021 11:50:14 tight : 122817 | 139696484/1574816140 ( 91.1%) 03/06/2021 11:50:14 RichCursor : 1 | 1374/ 1374 ( 0.0%) 03/06/2021 11:50:14 TOTALS : 245370 | 139697942/1574817598 ( 91.1%) 03/06/2021 11:50:14 Statistics events Received/ RawEquiv ( saved) 03/06/2021 11:50:14 PointerEvent : 140 | 840/ 840 ( 0.0%) 03/06/2021 11:50:14 FramebufferUpdate : 122546 | 1225460/ 1225460 ( 0.0%) 03/06/2021 11:50:14 SetEncodings : 1 | 56/ 56 ( 0.0%) 03/06/2021 11:50:14 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 03/06/2021 11:50:14 TOTALS : 122688 | 1226376/ 1226376 ( 0.0%) 03/06/2021 11:50:14 destroyed xdamage object: 0x400033 03/06/2021 11:50:18 Got connection from client 127.0.0.1 03/06/2021 11:50:18 other clients: 03/06/2021 11:50:18 Got 'ws' WebSockets handshake 03/06/2021 11:50:18 Got protocol: binary 03/06/2021 11:50:18 - webSocketsHandshake: using binary/raw encoding 03/06/2021 11:50:18 - WebSockets client version hybi-13 03/06/2021 11:50:18 Disabled X server key autorepeat. 03/06/2021 11:50:18 to force back on run: 'xset r on' (3 times) 03/06/2021 11:50:18 incr accepted_client=8 for 127.0.0.1:56464 sock=10 03/06/2021 11:50:18 Client Protocol Version 3.8 03/06/2021 11:50:18 Protocol version sent 3.8, using 3.8 03/06/2021 11:50:18 rfbProcessClientSecurityType: executing handler for type 1 03/06/2021 11:50:18 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 03/06/2021 11:50:18 Pixel format for client 127.0.0.1: 03/06/2021 11:50:18 32 bpp, depth 24, little endian 03/06/2021 11:50:18 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 03/06/2021 11:50:18 no translation needed 03/06/2021 11:50:18 Enabling NewFBSize protocol extension for client 127.0.0.1 03/06/2021 11:50:18 Enabling full-color cursor updates for client 127.0.0.1 03/06/2021 11:50:18 Using image quality level 6 for client 127.0.0.1 03/06/2021 11:50:18 Using JPEG subsampling 0, Q79 for client 127.0.0.1 03/06/2021 11:50:18 Using compression level 9 for client 127.0.0.1 03/06/2021 11:50:18 Enabling LastRect protocol extension for client 127.0.0.1 03/06/2021 11:50:18 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 03/06/2021 11:50:18 Using tight encoding for client 127.0.0.1 03/06/2021 11:50:18 client 8 network rate 1012.6 KB/sec (86104.1 eff KB/sec) 03/06/2021 11:50:18 client 8 latency: 6.1 ms 03/06/2021 11:50:18 dt1: 0.0190, dt2: 0.0297 dt3: 0.0061 bytes: 46270 03/06/2021 11:50:18 link_rate: LR_LAN - 6 ms, 1012 KB/s 03/06/2021 11:50:18 client_set_net: 127.0.0.1 0.0000 03/06/2021 11:50:18 active keyboard: turning X autorepeat off. 03/06/2021 11:50:18 created xdamage object: 0x400034 03/06/2021 11:55:20 idle keyboard: turning X autorepeat back on. 03/06/2021 12:15:58 webSocketsDecodeHybi: unhandled opcode 9, b0: 89, b1: 84 03/06/2021 12:15:58 rfbProcessClientNormalMessage: read: Invalid argument 03/06/2021 12:15:58 client_count: 0 03/06/2021 12:15:58 Client 127.0.0.1 gone 03/06/2021 12:15:58 Statistics events Transmit/ RawEquiv ( saved) 03/06/2021 12:15:58 FramebufferUpdate : 26194 | 0/ 0 ( 0.0%) 03/06/2021 12:15:58 LastRect : 1 | 12/ 12 ( 0.0%) 03/06/2021 12:15:58 tight : 26293 | 29884144/339633020 ( 91.2%) 03/06/2021 12:15:58 RichCursor : 1 | 1374/ 1374 ( 0.0%) 03/06/2021 12:15:58 TOTALS : 52489 | 29885530/339634406 ( 91.2%) 03/06/2021 12:15:58 Statistics events Received/ RawEquiv ( saved) 03/06/2021 12:15:58 PointerEvent : 46 | 276/ 276 ( 0.0%) 03/06/2021 12:15:58 FramebufferUpdate : 26194 | 261940/ 261940 ( 0.0%) 03/06/2021 12:15:58 SetEncodings : 1 | 56/ 56 ( 0.0%) 03/06/2021 12:15:58 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 03/06/2021 12:15:58 TOTALS : 26242 | 262292/ 262292 ( 0.0%) 03/06/2021 12:16:00 destroyed xdamage object: 0x400034 03/06/2021 12:16:13 Got connection from client 127.0.0.1 03/06/2021 12:16:13 other clients: 03/06/2021 12:16:13 Got 'ws' WebSockets handshake 03/06/2021 12:16:13 Got protocol: binary 03/06/2021 12:16:13 - webSocketsHandshake: using binary/raw encoding 03/06/2021 12:16:13 - WebSockets client version hybi-13 03/06/2021 12:16:13 Disabled X server key autorepeat. 03/06/2021 12:16:13 to force back on run: 'xset r on' (3 times) 03/06/2021 12:16:13 incr accepted_client=9 for 127.0.0.1:58006 sock=10 03/06/2021 12:16:13 Client Protocol Version 3.8 03/06/2021 12:16:13 Protocol version sent 3.8, using 3.8 03/06/2021 12:16:13 rfbProcessClientSecurityType: executing handler for type 1 03/06/2021 12:16:13 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 03/06/2021 12:16:13 Pixel format for client 127.0.0.1: 03/06/2021 12:16:13 32 bpp, depth 24, little endian 03/06/2021 12:16:13 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 03/06/2021 12:16:13 no translation needed 03/06/2021 12:16:13 Enabling NewFBSize protocol extension for client 127.0.0.1 03/06/2021 12:16:13 Enabling full-color cursor updates for client 127.0.0.1 03/06/2021 12:16:13 Using image quality level 6 for client 127.0.0.1 03/06/2021 12:16:13 Using JPEG subsampling 0, Q79 for client 127.0.0.1 03/06/2021 12:16:13 Using compression level 9 for client 127.0.0.1 03/06/2021 12:16:13 Enabling LastRect protocol extension for client 127.0.0.1 03/06/2021 12:16:13 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 03/06/2021 12:16:13 Using tight encoding for client 127.0.0.1 03/06/2021 12:16:13 client 9 network rate 273.4 KB/sec (23368.4 eff KB/sec) 03/06/2021 12:16:13 client 9 latency: 6.3 ms 03/06/2021 12:16:13 dt1: 0.0085, dt2: 0.1630 dt3: 0.0063 bytes: 46024 03/06/2021 12:16:13 link_rate: LR_UNKNOWN - 6 ms, 273 KB/s 03/06/2021 12:16:13 client_set_net: 127.0.0.1 0.0000 03/06/2021 12:16:13 active keyboard: turning X autorepeat off. 03/06/2021 12:16:13 created xdamage object: 0x400035 03/06/2021 12:16:23 got closure, reason 1001 03/06/2021 12:16:23 rfbProcessClientNormalMessage: read: Connection reset by peer 03/06/2021 12:16:23 client_count: 0 03/06/2021 12:16:23 Restored X server key autorepeat to: 1 03/06/2021 12:16:23 Client 127.0.0.1 gone 03/06/2021 12:16:23 Statistics events Transmit/ RawEquiv ( saved) 03/06/2021 12:16:23 FramebufferUpdate : 215 | 0/ 0 ( 0.0%) 03/06/2021 12:16:23 LastRect : 1 | 12/ 12 ( 0.0%) 03/06/2021 12:16:23 tight : 281 | 284824/ 6629676 ( 95.7%) 03/06/2021 12:16:23 RichCursor : 1 | 1374/ 1374 ( 0.0%) 03/06/2021 12:16:23 TOTALS : 498 | 286210/ 6631062 ( 95.7%) 03/06/2021 12:16:23 Statistics events Received/ RawEquiv ( saved) 03/06/2021 12:16:23 PointerEvent : 39 | 234/ 234 ( 0.0%) 03/06/2021 12:16:23 FramebufferUpdate : 216 | 2160/ 2160 ( 0.0%) 03/06/2021 12:16:23 SetEncodings : 1 | 56/ 56 ( 0.0%) 03/06/2021 12:16:23 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 03/06/2021 12:16:23 TOTALS : 257 | 2470/ 2470 ( 0.0%) 03/06/2021 12:16:23 destroyed xdamage object: 0x400035 03/06/2021 12:17:58 Got connection from client 127.0.0.1 03/06/2021 12:17:58 other clients: 03/06/2021 12:17:58 Got 'ws' WebSockets handshake 03/06/2021 12:17:58 Got protocol: binary 03/06/2021 12:17:58 - webSocketsHandshake: using binary/raw encoding 03/06/2021 12:17:58 - WebSockets client version hybi-13 03/06/2021 12:17:58 Disabled X server key autorepeat. 03/06/2021 12:17:58 to force back on run: 'xset r on' (3 times) 03/06/2021 12:17:58 incr accepted_client=10 for 127.0.0.1:58072 sock=10 03/06/2021 12:17:58 Client Protocol Version 3.8 03/06/2021 12:17:58 Protocol version sent 3.8, using 3.8 03/06/2021 12:17:58 rfbProcessClientSecurityType: executing handler for type 1 03/06/2021 12:17:58 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 03/06/2021 12:17:58 Pixel format for client 127.0.0.1: 03/06/2021 12:17:58 32 bpp, depth 24, little endian 03/06/2021 12:17:58 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 03/06/2021 12:17:58 no translation needed 03/06/2021 12:17:58 Enabling NewFBSize protocol extension for client 127.0.0.1 03/06/2021 12:17:58 Enabling full-color cursor updates for client 127.0.0.1 03/06/2021 12:17:58 Using image quality level 6 for client 127.0.0.1 03/06/2021 12:17:58 Using JPEG subsampling 0, Q79 for client 127.0.0.1 03/06/2021 12:17:58 Using compression level 9 for client 127.0.0.1 03/06/2021 12:17:58 Enabling LastRect protocol extension for client 127.0.0.1 03/06/2021 12:17:58 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 03/06/2021 12:17:58 Using tight encoding for client 127.0.0.1 03/06/2021 12:17:59 client_set_net: 127.0.0.1 0.0000 03/06/2021 12:17:59 created xdamage object: 0x400036 03/06/2021 12:47:10 client_count: 0 03/06/2021 12:47:10 Client 127.0.0.1 gone 03/06/2021 12:47:10 Statistics events Transmit/ RawEquiv ( saved) 03/06/2021 12:47:10 FramebufferUpdate : 21139 | 0/ 0 ( 0.0%) 03/06/2021 12:47:10 LastRect : 1 | 12/ 12 ( 0.0%) 03/06/2021 12:47:10 tight : 21250 | 24134518/274898968 ( 91.2%) 03/06/2021 12:47:10 RichCursor : 1 | 1374/ 1374 ( 0.0%) 03/06/2021 12:47:10 TOTALS : 42391 | 24135904/274900354 ( 91.2%) 03/06/2021 12:47:10 Statistics events Received/ RawEquiv ( saved) 03/06/2021 12:47:10 PointerEvent : 24 | 144/ 144 ( 0.0%) 03/06/2021 12:47:10 FramebufferUpdate : 21139 | 211390/ 211390 ( 0.0%) 03/06/2021 12:47:10 SetEncodings : 1 | 56/ 56 ( 0.0%) 03/06/2021 12:47:10 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 03/06/2021 12:47:10 TOTALS : 21165 | 211610/ 211610 ( 0.0%) 03/06/2021 12:47:12 destroyed xdamage object: 0x400036 03/06/2021 12:48:32 Got connection from client 127.0.0.1 03/06/2021 12:48:32 other clients: 03/06/2021 12:48:32 Got 'ws' WebSockets handshake 03/06/2021 12:48:32 Got protocol: binary 03/06/2021 12:48:32 - webSocketsHandshake: using binary/raw encoding 03/06/2021 12:48:32 - WebSockets client version hybi-13 03/06/2021 12:48:32 Disabled X server key autorepeat. 03/06/2021 12:48:32 to force back on run: 'xset r on' (3 times) 03/06/2021 12:48:32 incr accepted_client=11 for 127.0.0.1:59598 sock=10 03/06/2021 12:48:32 Client Protocol Version 3.8 03/06/2021 12:48:32 Protocol version sent 3.8, using 3.8 03/06/2021 12:48:32 rfbProcessClientSecurityType: executing handler for type 1 03/06/2021 12:48:32 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 03/06/2021 12:48:33 Pixel format for client 127.0.0.1: 03/06/2021 12:48:33 32 bpp, depth 24, little endian 03/06/2021 12:48:33 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 03/06/2021 12:48:33 no translation needed 03/06/2021 12:48:33 Enabling NewFBSize protocol extension for client 127.0.0.1 03/06/2021 12:48:33 Enabling full-color cursor updates for client 127.0.0.1 03/06/2021 12:48:33 Using image quality level 6 for client 127.0.0.1 03/06/2021 12:48:33 Using JPEG subsampling 0, Q79 for client 127.0.0.1 03/06/2021 12:48:33 Using compression level 9 for client 127.0.0.1 03/06/2021 12:48:33 Enabling LastRect protocol extension for client 127.0.0.1 03/06/2021 12:48:33 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 03/06/2021 12:48:33 Using tight encoding for client 127.0.0.1 03/06/2021 12:48:33 client_set_net: 127.0.0.1 0.0000 03/06/2021 12:48:33 created xdamage object: 0x400037 03/06/2021 12:48:39 got closure, reason 1001 03/06/2021 12:48:39 rfbProcessClientNormalMessage: read: Connection reset by peer 03/06/2021 12:48:39 client_count: 0 03/06/2021 12:48:39 Restored X server key autorepeat to: 1 03/06/2021 12:48:39 Client 127.0.0.1 gone 03/06/2021 12:48:39 Statistics events Transmit/ RawEquiv ( saved) 03/06/2021 12:48:39 FramebufferUpdate : 71 | 0/ 0 ( 0.0%) 03/06/2021 12:48:39 LastRect : 1 | 12/ 12 ( 0.0%) 03/06/2021 12:48:39 tight : 137 | 124691/ 4830828 ( 97.4%) 03/06/2021 12:48:39 RichCursor : 1 | 1374/ 1374 ( 0.0%) 03/06/2021 12:48:39 TOTALS : 210 | 126077/ 4832214 ( 97.4%) 03/06/2021 12:48:39 Statistics events Received/ RawEquiv ( saved) 03/06/2021 12:48:39 PointerEvent : 40 | 240/ 240 ( 0.0%) 03/06/2021 12:48:39 FramebufferUpdate : 72 | 720/ 720 ( 0.0%) 03/06/2021 12:48:39 SetEncodings : 1 | 56/ 56 ( 0.0%) 03/06/2021 12:48:39 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 03/06/2021 12:48:39 TOTALS : 114 | 1036/ 1036 ( 0.0%) 03/06/2021 12:48:39 destroyed xdamage object: 0x400037 03/06/2021 13:13:33 Got connection from client 127.0.0.1 03/06/2021 13:13:33 other clients: 03/06/2021 13:13:33 Got 'ws' WebSockets handshake 03/06/2021 13:13:33 Got protocol: binary 03/06/2021 13:13:33 - webSocketsHandshake: using binary/raw encoding 03/06/2021 13:13:33 - WebSockets client version hybi-13 03/06/2021 13:13:33 Disabled X server key autorepeat. 03/06/2021 13:13:33 to force back on run: 'xset r on' (3 times) 03/06/2021 13:13:33 incr accepted_client=12 for 127.0.0.1:60612 sock=10 03/06/2021 13:13:33 Client Protocol Version 3.8 03/06/2021 13:13:33 Protocol version sent 3.8, using 3.8 03/06/2021 13:13:33 rfbProcessClientSecurityType: executing handler for type 1 03/06/2021 13:13:33 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 03/06/2021 13:13:33 Pixel format for client 127.0.0.1: 03/06/2021 13:13:33 32 bpp, depth 24, little endian 03/06/2021 13:13:33 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 03/06/2021 13:13:33 no translation needed 03/06/2021 13:13:33 Enabling NewFBSize protocol extension for client 127.0.0.1 03/06/2021 13:13:33 Enabling full-color cursor updates for client 127.0.0.1 03/06/2021 13:13:33 Using image quality level 6 for client 127.0.0.1 03/06/2021 13:13:33 Using JPEG subsampling 0, Q79 for client 127.0.0.1 03/06/2021 13:13:33 Using compression level 9 for client 127.0.0.1 03/06/2021 13:13:33 Enabling LastRect protocol extension for client 127.0.0.1 03/06/2021 13:13:33 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 03/06/2021 13:13:33 Using tight encoding for client 127.0.0.1 03/06/2021 13:13:33 client_set_net: 127.0.0.1 0.0000 03/06/2021 13:13:33 created xdamage object: 0x400038 03/06/2021 13:14:03 client 12 network rate 1174.0 KB/sec (49598.7 eff KB/sec) 03/06/2021 13:14:03 client 12 latency: 4.4 ms 03/06/2021 13:14:03 dt1: 0.0061, dt2: 0.0110 dt3: 0.0044 bytes: 17449 03/06/2021 13:14:03 link_rate: LR_LAN - 4 ms, 1174 KB/s 03/06/2021 13:26:33 got closure, reason 1001 03/06/2021 13:26:33 rfbProcessClientNormalMessage: read: Connection reset by peer 03/06/2021 13:26:33 client_count: 0 03/06/2021 13:26:33 Client 127.0.0.1 gone 03/06/2021 13:26:33 Statistics events Transmit/ RawEquiv ( saved) 03/06/2021 13:26:33 FramebufferUpdate : 21449 | 0/ 0 ( 0.0%) 03/06/2021 13:26:33 LastRect : 15 | 180/ 180 ( 0.0%) 03/06/2021 13:26:33 tight : 23120 | 24501568/281052096 ( 91.3%) 03/06/2021 13:26:33 RichCursor : 1 | 1374/ 1374 ( 0.0%) 03/06/2021 13:26:33 TOTALS : 44585 | 24503122/281053650 ( 91.3%) 03/06/2021 13:26:33 Statistics events Received/ RawEquiv ( saved) 03/06/2021 13:26:33 ClientCutText : 1 | 32/ 32 ( 0.0%) 03/06/2021 13:26:33 PointerEvent : 344 | 2064/ 2064 ( 0.0%) 03/06/2021 13:26:33 FramebufferUpdate : 21450 | 214500/ 214500 ( 0.0%) 03/06/2021 13:26:33 SetEncodings : 1 | 56/ 56 ( 0.0%) 03/06/2021 13:26:33 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 03/06/2021 13:26:33 TOTALS : 21797 | 216672/ 216672 ( 0.0%) 03/06/2021 13:26:33 destroyed xdamage object: 0x400038 03/06/2021 13:26:37 Got connection from client 127.0.0.1 03/06/2021 13:26:37 other clients: 03/06/2021 13:26:37 Got 'ws' WebSockets handshake 03/06/2021 13:26:37 Got protocol: binary 03/06/2021 13:26:37 - webSocketsHandshake: using binary/raw encoding 03/06/2021 13:26:37 - WebSockets client version hybi-13 03/06/2021 13:26:37 Disabled X server key autorepeat. 03/06/2021 13:26:37 to force back on run: 'xset r on' (3 times) 03/06/2021 13:26:37 incr accepted_client=13 for 127.0.0.1:32894 sock=10 03/06/2021 13:26:37 Client Protocol Version 3.8 03/06/2021 13:26:37 Protocol version sent 3.8, using 3.8 03/06/2021 13:26:37 rfbProcessClientSecurityType: executing handler for type 1 03/06/2021 13:26:37 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 03/06/2021 13:26:37 Pixel format for client 127.0.0.1: 03/06/2021 13:26:37 32 bpp, depth 24, little endian 03/06/2021 13:26:37 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 03/06/2021 13:26:37 no translation needed 03/06/2021 13:26:37 Enabling NewFBSize protocol extension for client 127.0.0.1 03/06/2021 13:26:37 Enabling full-color cursor updates for client 127.0.0.1 03/06/2021 13:26:37 Using image quality level 6 for client 127.0.0.1 03/06/2021 13:26:37 Using JPEG subsampling 0, Q79 for client 127.0.0.1 03/06/2021 13:26:37 Using compression level 9 for client 127.0.0.1 03/06/2021 13:26:37 Enabling LastRect protocol extension for client 127.0.0.1 03/06/2021 13:26:37 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 03/06/2021 13:26:37 Using tight encoding for client 127.0.0.1 03/06/2021 13:26:37 client_set_net: 127.0.0.1 0.0000 03/06/2021 13:26:37 created xdamage object: 0x400039 03/06/2021 15:26:01 client 13 network rate 1204.5 KB/sec (64346.6 eff KB/sec) 03/06/2021 15:26:01 client 13 latency: 4.3 ms 03/06/2021 15:26:01 dt1: 0.0087, dt2: 0.0145 dt3: 0.0043 bytes: 25435 03/06/2021 15:26:01 link_rate: LR_LAN - 4 ms, 1204 KB/s FYI I think the web terminal is limited to the number of lines, so it has truncated the top.
-
[ { "Id": "1e463f69531251a51b36df5b799649a82b9d90857c2b53b63f4a3fafdf20c8cf", "Created": "2021-03-20T12:55:54.112795714Z", "Path": "/init", "Args": [], "State": { "Status": "running", "Running": true, "Paused": false, "Restarting": false, "OOMKilled": false, "Dead": false, "Pid": 49262, "ExitCode": 0, "Error": "", "StartedAt": "2021-05-27T16:19:11.877809809Z", "FinishedAt": "2021-05-27T16:19:11.394276837Z" }, "Image": "sha256:59eb951d61078a0b609230e4aba38e2eb1e5f6965cebc0532ac22c257d4d805c", "ResolvConfPath": "/var/lib/docker/containers/1e463f69531251a51b36df5b799649a82b9d90857c2b53b63f4a3fafdf20c8cf/resolv.conf", "HostnamePath": "/var/lib/docker/containers/1e463f69531251a51b36df5b799649a82b9d90857c2b53b63f4a3fafdf20c8cf/hostname", "HostsPath": "/var/lib/docker/containers/1e463f69531251a51b36df5b799649a82b9d90857c2b53b63f4a3fafdf20c8cf/hosts", "LogPath": "/var/lib/docker/containers/1e463f69531251a51b36df5b799649a82b9d90857c2b53b63f4a3fafdf20c8cf/1e463f69531251a51b36df5b799649a82b9d90857c2b53b63f4a3fafdf20c8cf-json.log", "Name": "/CrashPlanPRO", "RestartCount": 0, "Driver": "btrfs", "Platform": "linux", "MountLabel": "", "ProcessLabel": "", "AppArmorProfile": "", "ExecIDs": null, "HostConfig": { "Binds": [ "/boot:/flash:ro", "/mnt/user/appdata/CrashPlanPRO:/config:rw", "/mnt/user:/storage:ro" ], "ContainerIDFile": "", "LogConfig": { "Type": "json-file", "Config": {} }, "NetworkMode": "bridge", "PortBindings": { "5800/tcp": [ { "HostIp": "", "HostPort": "7810" } ], "5900/tcp": [ { "HostIp": "", "HostPort": "7910" } ] }, "RestartPolicy": { "Name": "no", "MaximumRetryCount": 0 }, "AutoRemove": false, "VolumeDriver": "", "VolumesFrom": null, "CapAdd": null, "CapDrop": null, "CgroupnsMode": "", "Dns": [], "DnsOptions": [], "DnsSearch": [], "ExtraHosts": null, "GroupAdd": null, "IpcMode": "private", "Cgroup": "", "Links": null, "OomScoreAdj": 0, "PidMode": "", "Privileged": false, "PublishAllPorts": false, "ReadonlyRootfs": false, "SecurityOpt": null, "UTSMode": "", "UsernsMode": "", "ShmSize": 67108864, "Runtime": "runc", "ConsoleSize": [ 0, 0 ], "Isolation": "", "CpuShares": 0, "Memory": 0, "NanoCpus": 0, "CgroupParent": "", "BlkioWeight": 0, "BlkioWeightDevice": [], "BlkioDeviceReadBps": null, "BlkioDeviceWriteBps": null, "BlkioDeviceReadIOps": null, "BlkioDeviceWriteIOps": null, "CpuPeriod": 0, "CpuQuota": 0, "CpuRealtimePeriod": 0, "CpuRealtimeRuntime": 0, "CpusetCpus": "", "CpusetMems": "", "Devices": [], "DeviceCgroupRules": null, "DeviceRequests": null, "KernelMemory": 0, "KernelMemoryTCP": 0, "MemoryReservation": 0, "MemorySwap": 0, "MemorySwappiness": null, "OomKillDisable": false, "PidsLimit": null, "Ulimits": null, "CpuCount": 0, "CpuPercent": 0, "IOMaximumIOps": 0, "IOMaximumBandwidth": 0, "MaskedPaths": [ "/proc/asound", "/proc/acpi", "/proc/kcore", "/proc/keys", "/proc/latency_stats", "/proc/timer_list", "/proc/timer_stats", "/proc/sched_debug", "/proc/scsi", "/sys/firmware" ], "ReadonlyPaths": [ "/proc/bus", "/proc/fs", "/proc/irq", "/proc/sys", "/proc/sysrq-trigger" ] }, "GraphDriver": { "Data": null, "Name": "btrfs" }, "Mounts": [ { "Type": "bind", "Source": "/boot", "Destination": "/flash", "Mode": "ro", "RW": false, "Propagation": "rprivate" }, { "Type": "bind", "Source": "/mnt/user", "Destination": "/storage", "Mode": "ro", "RW": false, "Propagation": "rprivate" }, { "Type": "bind", "Source": "/mnt/user/appdata/CrashPlanPRO", "Destination": "/config", "Mode": "rw", "RW": true, "Propagation": "rprivate" } ], "Config": { "Hostname": "1e463f695312", "Domainname": "", "User": "", "AttachStdin": false, "AttachStdout": false, "AttachStderr": false, "ExposedPorts": { "5800/tcp": {}, "5900/tcp": {} }, "Tty": false, "OpenStdin": false, "StdinOnce": false, "Env": [ "TZ=Europe/London", "HOST_OS=Unraid", "GROUP_ID=100", "DISPLAY_WIDTH=1280", "DISPLAY_HEIGHT=768", "X11VNC_EXTRA_OPTS=", "USER_ID=99", "UMASK=000", "APP_NICENESS=", "CRASHPLAN_SRV_MAX_MEM=3072M", "SECURE_CONNECTION=0", "PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin", "LANG=en_US.UTF-8", "S6_BEHAVIOUR_IF_STAGE2_FAILS=3", "S6_SERVICE_DEPS=1", "APP_NAME=CrashPlan for Small Business", "APP_USER=app", "XDG_DATA_HOME=/config/xdg/data", "XDG_CONFIG_HOME=/config/xdg/config", "XDG_CACHE_HOME=/config/xdg/cache", "XDG_RUNTIME_DIR=/tmp/run/user/app", "DISPLAY=:0", "S6_WAIT_FOR_SERVICE_MAXTIME=10000", "KEEP_APP_RUNNING=1" ], "Cmd": [ "/init" ], "Image": "jlesage/crashplan-pro", "Volumes": { "/config": {}, "/storage": {} }, "WorkingDir": "/tmp", "Entrypoint": null, "OnBuild": null, "Labels": { "org.label-schema.description": "Docker container for CrashPlan PRO", "org.label-schema.name": "crashplan-pro", "org.label-schema.schema-version": "1.0", "org.label-schema.vcs-url": "https://github.com/jlesage/docker-crashplan-pro", "org.label-schema.version": "2.14.0", "org.opencontainers.image.created": "2021-03-18T22:22:10Z", "org.opencontainers.image.revision": "d310131ab13956748710b5c860d95d45955e0435", "org.opencontainers.image.source": "https://github.com/jlesage/docker-crashplan-pro.git", "org.opencontainers.image.url": "https://github.com/jlesage/docker-crashplan-pro" } }, "NetworkSettings": { "Bridge": "", "SandboxID": "966adad5127d25d5fe54ee6011080ee34e03771f74199cec950b03b21ff39686", "HairpinMode": false, "LinkLocalIPv6Address": "", "LinkLocalIPv6PrefixLen": 0, "Ports": { "5800/tcp": [ { "HostIp": "0.0.0.0", "HostPort": "7810" } ], "5900/tcp": [ { "HostIp": "0.0.0.0", "HostPort": "7910" } ] }, "SandboxKey": "/var/run/docker/netns/966adad5127d", "SecondaryIPAddresses": null, "SecondaryIPv6Addresses": null, "EndpointID": "8e48b62834d48df67f84a155c23301244e4690f0abfbd0ff1c404eca24d83867", "Gateway": "172.17.0.1", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "IPAddress": "172.17.0.9", "IPPrefixLen": 16, "IPv6Gateway": "", "MacAddress": "02:42:ac:11:00:09", "Networks": { "bridge": { "IPAMConfig": null, "Links": null, "Aliases": null, "NetworkID": "48f0a4627c58ac7c77b368777edbadb116c83b04817fa9c00dce2a6995aed5ed", "EndpointID": "8e48b62834d48df67f84a155c23301244e4690f0abfbd0ff1c404eca24d83867", "Gateway": "172.17.0.1", "IPAddress": "172.17.0.9", "IPPrefixLen": 16, "IPv6Gateway": "", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "MacAddress": "02:42:ac:11:00:09", "DriverOpts": null } } } } ]





