




jademonkee
Members
-
Joined
-
Last visited
Everything posted by jademonkee
-
@dlandon Version 9.1.1 is out. Can you please do a refresh of the Docker image? Many thanks! If anyone is interested, the changelog is here: GitHubCommits · LMS-Community/slimserverServer for Squeezebox and compatible players. This server is also called Lyrion Music Server. - Commits · LMS-Community/slimserverEDIT: Better, more readable, changelog here: https://lyrion.org/getting-started/changelog-lms9/
-
Wow, doing a quick Google search and that model ranges from £175 to like £1000+ over here in the UK...
-
Updated from 7.3.0 seemingly without issue.
-
This ☝️x100 @SirCadian I definitely recommend moving PiHole from your Unraid server to a Raspberry Pi. Even an original Raspberry Pi can comfortably run PiHole (including with Unbound) - I did so for years. You can pick up a second-hand Pi 3B+ for like £20-£30. It's so much easier/reliable than having your internet tied to your server's uptime. PiHole is super easy to set up on a Pi, too: https://github.com/pi-hole/pi-hole/#one-step-automated-install And if you want better anonymity, you can run Unbound as your own DNS, too (just don't expose it to the internet and accidentally make it a public DNS): https://docs.pi-hole.net/guides/dns/unbound/
-
That's wild. Sorry to hear it: this has been the best update for me since the jump to v7. My CPU now runs cooler, and draws around 25w less on average with no performance degradation, thanks to the improvements to the EPP AMD Pstate drivers. The Tips & Tweaks plugin (now known as Tips & Tweaks Next) has also been updated to easily change between them, too, and better support the different approaches to Intel & AMD power profiles. All my Dockers worked without issue from the get-go. I don't know why some people are having problems with Docker. I know the jump with the eailer 7.2.5 (or .6?) updated the Docker engine, which caused some troubles, but mine were quickly reolved. So I say again: well done, Unraid. I'm very pleased with this update.
-
Just FYI, since upgrading to Unraid 7.3.0, I've noticed a ~20w drop in power consumption. I believe it's due to improvements to the amd-pstate driver in the newer Kernel. (see my post at: https://forums.unraid.net/topic/198745-unraid-730-stable-now-available/page/3/#findComment-1623014 ) Tips & Tweaks currently has my server set using "Normal" governor as "Balanced Performance" in the drop-down, while the info column to the right reports it as "CPU Frequency Scaling - Driver: AMD Pstate EPP - Governor: Power Save". In the Unraid "Power Mode" setttings, I have it set to "Best Power Efficiency" I'm probably going to change the "Normal CPU Scalig Governor" setting in Tips & Tweaks to "Balanced Power" to see if it does anything meaningful. But may I ask: What's the relationship between the options in Tips & Tweaks and the Unraid Power Save setting? Does one cancel out the other (specifically for my AMD EPYC CPU - see sig)? Many thanks.
-
A day later, and yes: it seems that my UPS is reporting that my machine (of course, this includes the other peripherals attached to the UPS) is sitting around 90-100w when 'idle' (IE, no VM running, but all my usual Dockers running), whereas it used to idle around 120w-140w. Looks like the newer kernel is properly using amd-pstate rather than acpi-cpufreq. The min freq of the CPU has also changed from 545.0000 MHz to 429.5810 MHz. Great stuff!
-
Upgraded to 7.3.0 without issue. It seems to me that my power consumption has dropped? I think my CPU is falling into low-power states more easily/often now. Thanks for all the hard work ✌️
-
Can confirm: I had LMS as Bridge, and setting it to Host fixed the problem. So all good now. It seems that Docker 28+ broke UDP broadcast forwarding into bridge containers, which kills Slimproto discovery and connectivity for Squeezebox Radio / PiCorePlayer. So switching to Host is now considered best practice for LMS (indeed, I note that this container defaults to Host, but I have been using various LMS containers for so long that I continued to use Bridge).
-
I belive in the release notes it says that if you manually assigned a MAC address using the "Exra Parameters" field in the Docker Container UI, that it will automatically carry over. So I think this is why they used "may". In all other circumstances, I beleive your containers will be assigned new, random MAC addresses. I have no idea if they're persistent across reboots. It also seems like they have different IP assignments, too (though still within the defined subnet).
-
Dang. Looks like it's gonna be a long troubleshooting session 🫠
-
Anyone having trouble with PiCorePlayer or Squeezebox radios since upgrading to 7.2.5? My other players work fine (mostly Squeezebox Receivers), as does connecting to the GUI/Material Skin using my Android phone or Laptop, but I can't connect to my Library using PiCorePlayer (I only use it as a GUI for controlling a Squeezebox Receiver), or my SqueezeBox Touch. Wondering if it's due to some changes in the new Docker version. If anyone else is having a similar problem, I'd love to know if you've found a solution. Many thanks.
-
Can we consider the 'latest' tag build to be the same as the previous builds? IE, Stable will get the incrememental/nightly updates, but 'latest' won't? Many thanks.
-
I think you're getting throttled. Check your Nextcloud logs to confirm. I had an issue with my (third party) Photos app on Android being throttled by the Nextcloud intrusion detection. The only solution I found was to whitelist my local network. It's a blunt solution, but it allowed me to use the photos app (at least its initial sync) from my local LAN without issue. I didn't have the time to figure out how to solve it properly. You can set it via Administration Settings > Security.
-
Just updated from 7.2.3. No issues at all.
-
It may not be the same issue, but when I upgraded to last week's LSIO image, I had two cores pegged at 100% due to a PHP process. I checked the Admin dashboard shortly after updating, and the security checks never stopped loading. I think it was the security checks that kicked off some process that wasn't ready to be run so shortly after the update. I restarted the Docker container and everything has been fine since. This looks different to my error, but it might be worth restarting to see if it's related.
-
FWIW I recently updated my flash drive to a ATP NanoDura 4GB USB 2.0 SLC drive and it's been working well. No problems with moving the license/GUIDs. I bought it from DigiKey.
-
Congratulations Simon! I didn't realise you were behind so many plugins that I rely on. Glad to see you're now "official" ;)
-
Upgraded from 7.2.2. No issues. As always, thanks for a great OS!
-
I have mine set up like this: (note that those are my own notes under "Description." Though it wouldn't hurt for you to add them, too.
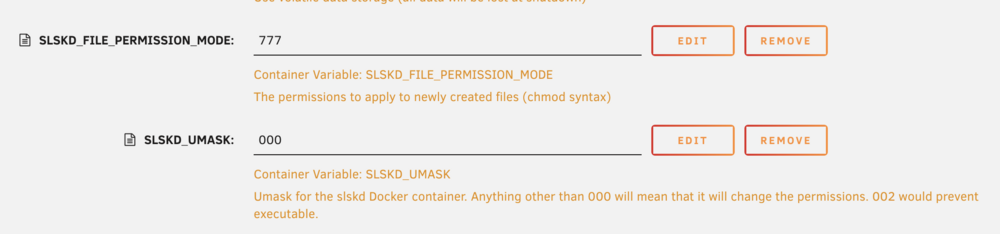
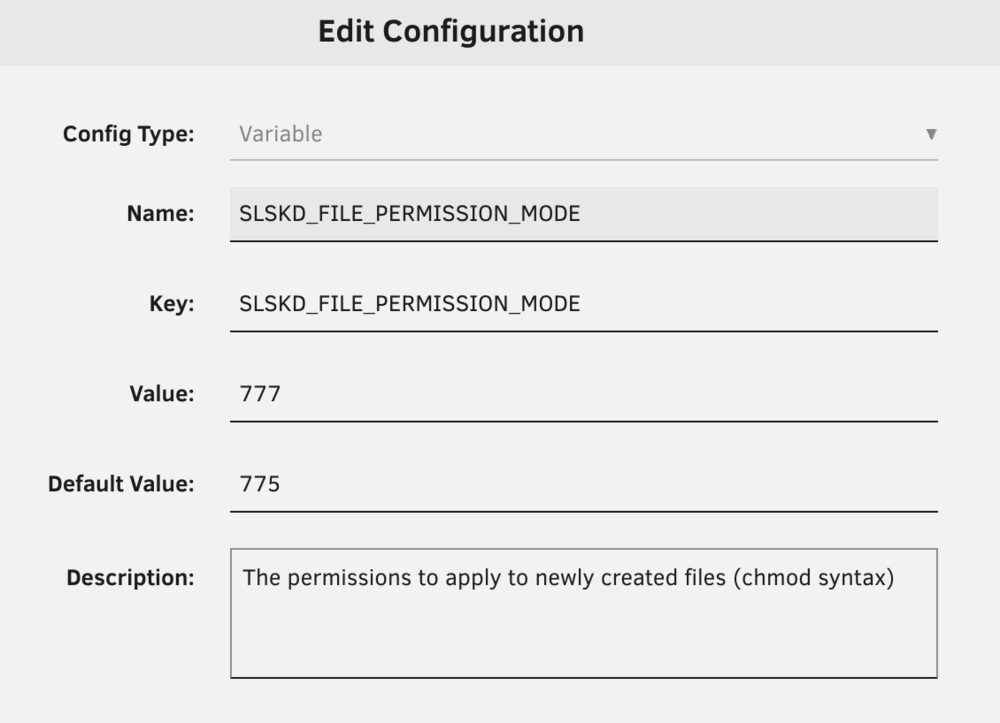
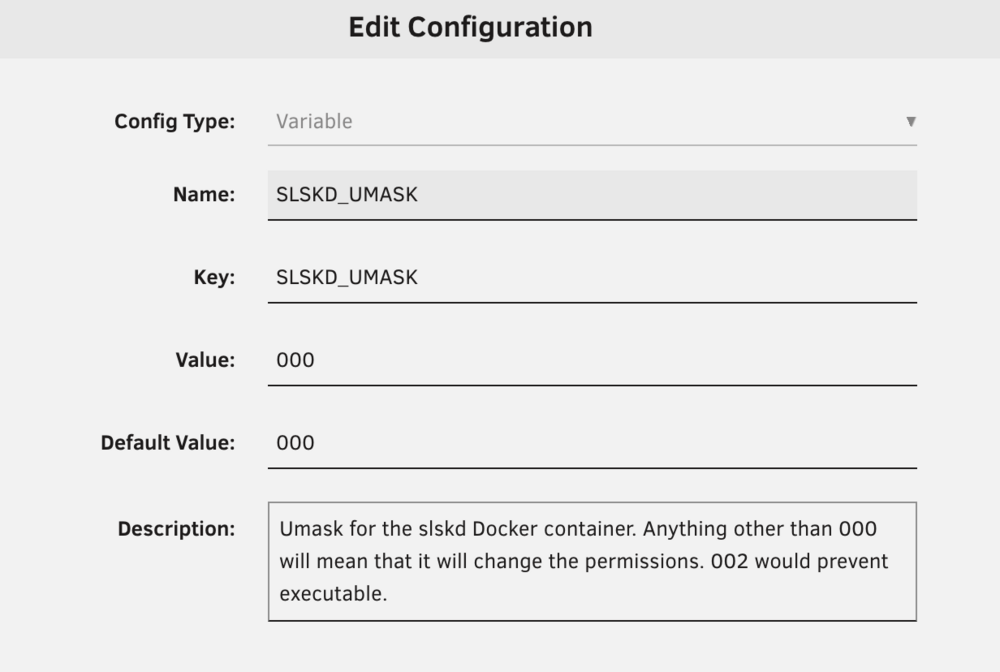
-
Out of curiosity, does this issue still apply with this Docker? Are people running it in Volatile mode, on a non-ZFS or non-BTRFS disk, or just running it normally with no issue? Your feedback is appreciated.
-
And just to double check: the files are new files (since changing the Docker perms), right? The changed permissions won't be applied retroactively to any files. If you want to fix any existing files, run the "Docker Safe New Perms" tool under the "Tools" menu in Unraid.
-
Are you trying to copy from Windows? There's a chance that maybe the paths are too long? I sometimes get weird file errors when renaming files if the directory length is longer than 260 characters. Just a guess, though, as it's usually reading or renaming those long files that causes those issues, not moving them.
-
Did you also add these? It's hard for me to diagnose your problem when I don't have a clear understanding of what your settings are.
-
That was what I mentioned needed to be done in the original post I linked you to...




