




TechGeek01
Members
-
Joined
-
Last visited
Everything posted by TechGeek01
-
Yep, turns out a 32 character password works just fine. Seems odd that there's a limit here, as the 64 character worked fine in browser. Do you know if there's a limit in your code, whether that's a limitation or artificial, at all, or is this just a weird bug?
-
So it was working on Unraid, as was sabnzbdvpn. I was attempting to get a second instance up and running (testing with my login, but setting up for a friend), and after running into these same issues, I changed the password, and updated the containers on Unraid. The only thing changed was the password. It's alphanumeric with no special characters, and 64 characters. Does it maybe need to be shortened a bit?
-
So I'm having issues connecting with NordVPN UDP. Logs show the following repeated constantly: 2021-09-27 22:21:47,937 DEBG 'start-script' stdout output: 2021-09-27 22:21:47 DEPRECATED OPTION: --cipher set to 'AES-256-CBC' but missing in --data-ciphers (AES-256-GCM:AES-128-GCM). Future OpenVPN version will ignore --cipher for cipher negotiations. Add 'AES-256-CBC' to --data-ciphers or change --cipher 'AES-256-CBC' to --data-ciphers-fallback 'AES-256-CBC' to silence this warning. 2021-09-27 22:21:47,938 DEBG 'start-script' stdout output: 2021-09-27 22:21:47 WARNING: file 'credentials.conf' is group or others accessible 2021-09-27 22:21:47 OpenVPN 2.5.1 [git:makepkg/f186691b32e68362+] x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Feb 24 2021 2021-09-27 22:21:47 library versions: OpenSSL 1.1.1k 25 Mar 2021, LZO 2.10 2021-09-27 22:21:47,939 DEBG 'start-script' stdout output: 2021-09-27 22:21:47 WARNING: --ping should normally be used with --ping-restart or --ping-exit 2021-09-27 22:21:47 NOTE: the current --script-security setting may allow this configuration to call user-defined scripts 2021-09-27 22:21:47,940 DEBG 'start-script' stdout output: 2021-09-27 22:21:47 Outgoing Control Channel Authentication: Using 512 bit message hash 'SHA512' for HMAC authentication 2021-09-27 22:21:47 Incoming Control Channel Authentication: Using 512 bit message hash 'SHA512' for HMAC authentication 2021-09-27 22:21:47,940 DEBG 'start-script' stdout output: 2021-09-27 22:21:47 TCP/UDP: Preserving recently used remote address: [AF_INET]89.187.182.71:1194 2021-09-27 22:21:47 Socket Buffers: R=[212992->212992] S=[212992->212992] 2021-09-27 22:21:47 UDP link local: (not bound) 2021-09-27 22:21:47 UDP link remote: [AF_INET]89.187.182.71:1194 2021-09-27 22:21:47,954 DEBG 'start-script' stdout output: 2021-09-27 22:21:47 TLS: Initial packet from [AF_INET]89.187.182.71:1194, sid=df5141ca 49f1b7f1 2021-09-27 22:21:47,988 DEBG 'start-script' stdout output: 2021-09-27 22:21:47 VERIFY OK: depth=2, C=PA, O=NordVPN, CN=NordVPN Root CA 2021-09-27 22:21:47,988 DEBG 'start-script' stdout output: 2021-09-27 22:21:47 VERIFY OK: depth=1, C=PA, O=NordVPN, CN=NordVPN CA6 2021-09-27 22:21:47,989 DEBG 'start-script' stdout output: 2021-09-27 22:21:47 VERIFY KU OK 2021-09-27 22:21:47 Validating certificate extended key usage 2021-09-27 22:21:47 ++ Certificate has EKU (str) TLS Web Server Authentication, expects TLS Web Server Authentication 2021-09-27 22:21:47 VERIFY EKU OK 2021-09-27 22:21:47 VERIFY OK: depth=0, CN=us6722.nordvpn.com 2021-09-27 22:21:50,007 DEBG 'start-script' stdout output: 2021-09-27 22:21:50 Control Channel: TLSv1.3, cipher TLSv1.3 TLS_AES_256_GCM_SHA384, 4096 bit RSA 2021-09-27 22:21:50 [us6722.nordvpn.com] Peer Connection Initiated with [AF_INET]89.187.182.71:1194 2021-09-27 22:21:50,007 DEBG 'start-script' stdout output: 2021-09-27 22:21:50 Control Channel: TLSv1.3, cipher TLSv1.3 TLS_AES_256_GCM_SHA384, 4096 bit RSA 2021-09-27 22:21:50 [us6722.nordvpn.com] Peer Connection Initiated with [AF_INET]89.187.182.71:1194 2021-09-27 22:21:51,157 DEBG 'start-script' stdout output: 2021-09-27 22:21:51 SENT CONTROL [us6722.nordvpn.com]: 'PUSH_REQUEST' (status=1) 2021-09-27 22:21:51,171 DEBG 'start-script' stdout output: 2021-09-27 22:21:51 AUTH: Received control message: AUTH_FAILED 2021-09-27 22:21:51,172 DEBG 'start-script' stdout output: 2021-09-27 22:21:51 SIGTERM[soft,auth-failure] received, process exiting Debug is enabled, credentials are recently changed, have no special characters, and have been verified to work in browser. openvpn directory contains the UDP .ovpn file, as well as the cert files for the associated server. Both delugevpn and Unraid are up to date at the time of writing this. Any ideas here?
-
Didn't seem appropriate to open a bug report for this, but I noticed in the shares page, the help ? section on the column headers makes mention of AFP still being a thing, despite it having been removed everywhere else.
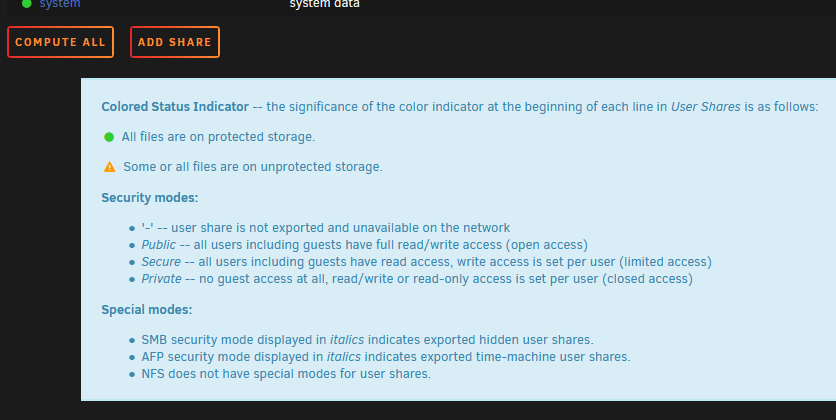
-
Yeah, that's what I'm doing currently now as well. Only difference is before, I didn't have the custom header color, so the header was default white, while my text was also white. Maybe you could add a check for other users that have the same deal I did (dark custom header image, but default color), and make it so that if the custom text color, and the header color are too close together, provided they're not both user-set (I didn't have a custom header color before, just the theme default), have it change the unset one to contrast? That is, if I had white text, but an unset header color, it would see they're both close together, and change the color the menu uses to something darker and readable. Not sure if this is the most elegant way to do that while retaining the custom display options, but it would at least help readability in that edge case.
-
Also chiming in, seeing the same thing with the Supermicro 846 icon in the list. No icon for me in the my servers page.
-
Just wanted to chime in on a coloring issue. I'm using the "black" color theme, and have a white header. I have a custom header image that's gray, so the tab bar is black text on white, but the header image is gray with some stuff in it. To see text here, I have the custom text color set to white in display settings. The menus for me are unreadable in this plugin in the header. Seems that after testing, the background of the flyout menu takes the custom text color, and text takes the custom background color. Presumably the correct approach is for the text in the header to take the text color of the tabs, and for the flyout to match this? Without a custom header color set, the default in this theme is white. With my custom text color set to white to see version number and such on a gray header image, this otherwise makes text unreadable. This plugin, since it takes the color of the header, should more than likely do the same thing the tabs do, and ignore the custom text color and just set text to white/black depending on luminance of the header color.
-
IPMI/system log shows nothing unusual, unfortunately. Memtest completely freaked on the bit fade test. Like, millions of errors in the first several hundred MB, so I'm currently in the process of finding what I hope is a bad stick, and not a slot or something.
-
In the last couple months, I moved Unraid over from a Dell R510 to a Supermicro build, and since then, I see occasional warnings about machine check errors. Dec 19 16:49:16 helium kernel: mce: [Hardware Error]: Machine check events logged Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: HANDLING MCE MEMORY ERROR Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: CPU 6: Machine Check Event: 0 Bank 10: 8c000046000800c1 Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: TSC 51ce458bc87a8 Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: ADDR c5c6ea000 Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: MISC 900100010000c8c Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: PROCESSOR 0:306f2 TIME 1608418156 SOCKET 1 APIC 10 Dec 19 16:49:16 helium kernel: EDAC MC0: 1 CE memory scrubbing error on CPU_SrcID#1_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0xc5c6ea offset:0x0 grain:32 syndrome:0x0 - area:DRAM err_code:0008:00c1 socket:1 ha:0 channel_mask:2 rank:0) Current system is a Supermicro X10DRi with dual E5-2620 v3 processors, and 64GB of RAM, configured as 2x16GB per socket. This obviously is a memory issue, but what exactly causes this, and how do I go about fixing it? I don't know a lot about these sort of logs. Presumably this isn't logging of things like ECC corrections, and this indicates a memory issue where I may have to replace the stick, correct? helium-diagnostics-20201219-2044.zip
-
In the last couple months, I moved Unraid over from a Dell R510 to a Supermicro build, and since then, I see occasional warnings about machine check errors. Dec 19 16:49:16 helium kernel: mce: [Hardware Error]: Machine check events logged Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: HANDLING MCE MEMORY ERROR Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: CPU 6: Machine Check Event: 0 Bank 10: 8c000046000800c1 Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: TSC 51ce458bc87a8 Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: ADDR c5c6ea000 Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: MISC 900100010000c8c Dec 19 16:49:16 helium kernel: EDAC sbridge MC0: PROCESSOR 0:306f2 TIME 1608418156 SOCKET 1 APIC 10 Dec 19 16:49:16 helium kernel: EDAC MC0: 1 CE memory scrubbing error on CPU_SrcID#1_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0xc5c6ea offset:0x0 grain:32 syndrome:0x0 - area:DRAM err_code:0008:00c1 socket:1 ha:0 channel_mask:2 rank:0) Current system is a Supermicro X10DRi with dual E5-2620 v3 processors, and 64GB of RAM, configured as 2x16GB per socket. This obviously is a memory issue, but what exactly causes this, and how do I go about fixing it? I don't know a lot about these sort of logs. Presumably this isn't logging of things like ECC corrections, and this indicates a memory issue where I may have to replace the stick, correct? helium-diagnostics-20201219-2044.zip



