




Goldfire
Members
-
Joined
-
Last visited
-
This bit, right? I double checked that before making the post to save bothering you, I might redo the docker from scratch when I get a chance. Edit: I redid the docker and it's working now, unsure why it hung on to the old server name. Sorry to bother and thanks again.
-
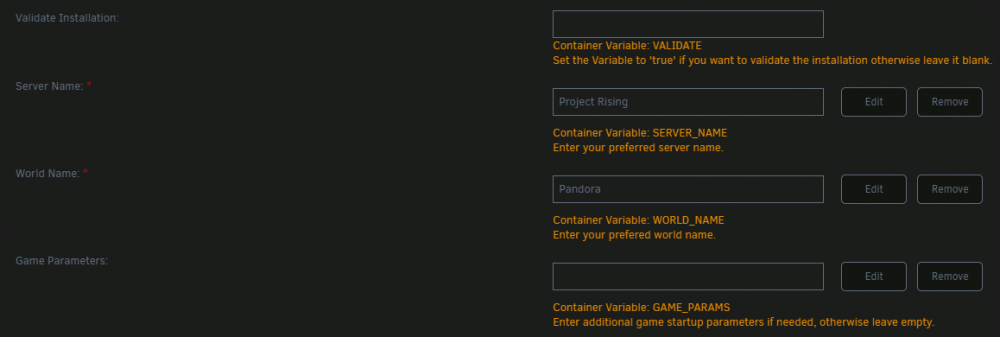
Thanks @ich777 for another great docker, can I get your input on this small issue I'm getting? Everything is working for the V Rising server, but it's not reading the server name correctly, it's being listed as "V Rising Docker" on the serverlist: { "Name": "Project Rising", "Description": "Project.R Pandora", "Port": 9876, "QueryPort": 9877, "MaxConnectedUsers": 40, "MaxConnectedAdmins": 4, "ServerFps": 30, "SaveName": "Pandora", "Password": "########", "Secure": true, "ListOnMasterServer": true, "AutoSaveCount": 50, "AutoSaveInterval": 600, "GameSettingsPreset": "", "AdminOnlyDebugEvents": true, "DisableDebugEvents": false } It's reading everything else correctly, the description and password is coming up correctly in-game, but not the name. Any suggestions?
-
To be honest, I don't remember removing the external drive during or after updating the plugin, I did try a few different things that may have included that though. Nevertheless, I had to restart for the stable 6.10 update anyway, so I'll keep this in mind going forward. Thanks.
-
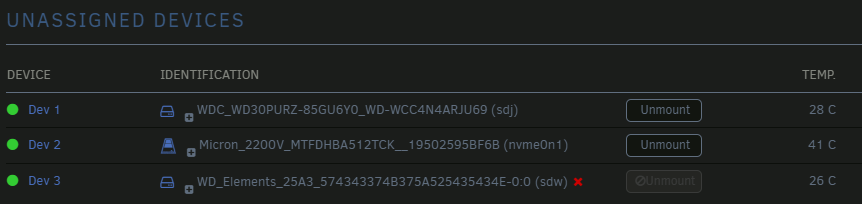
Same issue as @Hoopster - I'm running 6.10-rc4. Updated to Unassigned Devices 2022.05.18 today and I can't access my USB connected Elements that I normally have mounted for backups via the DirSyncPro docker.
-
Hi @ich777, I'm running your Unturned server which is working fine, even with custom maps. How do I go about saving and gracefully shutting down the docker so it can save correctly?
-
I'll look into that, thanks. I am using a reverse proxy, LetsEncrypt to be specific. Which config file are you specifically referring to? If I add that line to my proxy.conf file under letsencrypt\nginx, it will create the folder I specify when a transfer starts, but it won't actually use it and continues to remain empty. It'll still use the docker.img as its temp. I mentioned that I use the "external storages" in Nextcloud, which mount the /mnt/user/ folders, then I share those to my Nextcloud users - does this have any negative impact of when trying to use the temp path?
-
I have this same problem as well, I'm using external storages that point to my /mnt/ locations. I had 10GB for my docker.img file which was about 50% full, someone downloaded a file from me that came in at 4.5GB - it basically crippled and trashed my docker.img to the point where I had to delete it and recreate it from scratch. Painless process with the auto template usage from the apps tab, but it's still a pain when I have to take all the dockers down just to do it. The only thing I can think of in the short term is to increase the docker.img size to something larger than your single largest file and inform your users to not download multiple files as an archive. @MothyTim What are you using to replace Nextcloud? I found Nextcloud to "tick" all of my boxes but this problem is just a big strike through them all.
-
Annoyingly, it actually did work at some point in an older build of unRAID - something must have been changed regarding apcupsd. I wouldn't be able to tell you which one build, but I do recall seeing my UPS going into sleep correctly once back in late 2018.
-
Oh God, thank you. I've been looking on and off over the years for a fix to this. After looking for and testing different things for a lot of that time, I finally made a topic back in mid 2019, but no one had a fix (let alone a reply): I gave your fix a go, and it worked perfectly after a quick test last night. The UPS goes into sleep mode (LEDs cycling) once the shutdown delay has done its thing. I can even see the UPS logs reporting that the unRAID server has issued the PowerChute shutdown command - I don't recall ever seeing that before. Checking the IPMI interface during the shutdown process doesn't throw any apcupsd errors anymore (the ones you see in the screenshot of that thread). Before doing your fix, the UPS would just run its batteries right down to critical, causing unnecessary wear on them when I wanted it to shutdown around the 80% remaining mark. Thank you for this.
-
I'm using local with the Source Directory set to: /mnt/user I've also mounted an external drive via Unassigned Disks using the Path option: Within DirSyncPro, I have the /external mountpoint as my backup destination, which works fine. Unfortunately, that didn't have any positive effect. When attempting to "Analyze this job now", nothing with Japanese/Chinese unicode characters will be detected. I've also tried to delete the job and remake it. Other English named files within my test folder are detected. Take your time though, I appreciate you looking at this for me.
-
Sorry for the delay, different timezones and all of that. The Windows version of DirSyncPro works fine with Japanese characters. The small set of files I was using for testing works. Ah sorry, I was (poorly) assuming that other languages were also affected. Chinese (Simplified) is also affected, I only have a handful of files with Chinese naming - that would've been an annoyance if I needed to restore those files at a later date and they weren't there, ha.
-
@ich777 You may not be able to help with this because the docker itself isn't at fault (at least I don't think it is). If you could poke around with it, I'd appreciate it. There doesn't seem to be any support for Japanese unicode (Kanji/Katakana/Hiragana). When a backup is running, DirSyncPro will simply skip over these files. It seems anything that isn't English won't be backed up. For example, this filename won't be backed up: リライアンス I've left a bug report on their SourceForge as well in hopes of this being fixed up.
-
Updated and you nailed it, it's working perfectly. Thanks for your support, I appreciate it. It's my payday on Friday
-
I received the update and it's working. Although, I have an odd problem where the log file will stop updating after midnight, unsure if this is a limitation of the container, or the docker engine itself - I can still see the new entries in the logs\latest.txt provided by the Minecraft server itself. Is that something that can be fixed with an update?
-
Cool thanks, I'll let that update via the CA Auto Update tomorrow morning. Appreciate it.



