




apefray
Members
-
Joined
-
Last visited
-
Any idea on which cards have been dropped? Im currently on v7.2.6 and a not sure if I should upgrade to v7.3.0 without knowing if the TBS6909 will work with the upgrade closed source driver. Cheers
-
Did as you mentioned and the drives were recognised on the SATA ports. I made a mistake in my original post, where I said the UD drives were connected to the Intel expander via the Startech enclosure, but they weren't. They were connected to the SCU ports on the motherboard. So basically anything connected directly to the MB ports were working fine, and anything connected via the Intel Expander card weren't working. It turns out it was the Intel expander card that had failed for some reason. To cut a long story short, I just went ahead and bought a 2nd hand super micro server which has a built in expander on the backplane, so I'm now using just the HP HBA to connect all the drives including the UD ones, and the Startech is now connected to the SATA ports on the MB. I then moved the parity and 2 cache drives to the Startech enclosure and it's now back up and running. Also swapped the unraid usb boot to a new one as it had been running for 9 years, although there was nothing wrong with the old USB, just took the opportunity to update it whilst preparing the new server. I did come across a couple of networking niggles, so had to change the server IP address, but they appear to be sorting themselves out (cache maybe).
-
Hi, Can someone more technical look at the attached diagnostics and figure out why all my array disks are shown as missing please. The parity drive is still there, as are the two pool caches, but all of them are connected to sata ports on the motherboard directly. Also, the 4 unassigned disks are listed still, being housed in a Startech SAT35401U Rackmount enclosure. This is connected to the Server via a mini SAS cable to a Mini SAS External adapter, then connected internally to an Intel RES2SV240. The Intel RES2SV240 is then connected to a HP SAS HBA H220. All of this is contained within a generic 16 bay server case which has been fault free for the past 8 years. As I mention, the unassigned drives are showing in Unraid, whereas the Array drives as shown as missing, but all of them are connected to the same Intel Expander Card via the HP SAS HBA. I just cant figure out why they are not showing, other than maybe the backplane or all four cables are faulty. Can someone concur with this from the diagnostics? Cheers Chris tower-diagnostics-20250914-1925.zip
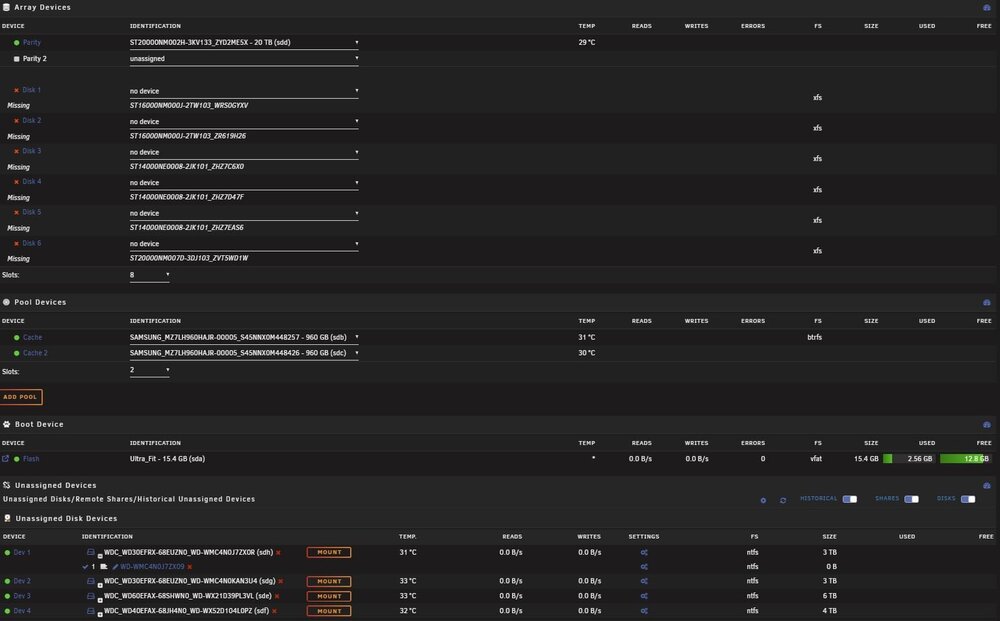
-
I've reinstalled IPMI again, and its been running for 3 days so far with no issues. Will send a log if anything happens
-
@SimonF Im running 6.12.13. I haven't touched the server for weeks, but all of a sudden, this problem has reared its head in the past week. I've uninstalled the plugin for now, so I haven't any logs currently, but I can reinstall it and see if it continues with crashing and if anything appears in the logs.
-
I too am experiencing this @SimonF having the same motherboard as @debit lagos. This started in the past week for me, and i have had to remove the plugin. For no explained reason, I would come home to find all the fans had ramped up and the IPMI plugin none responsive with the temp details in the bottom bar missing.
-
@SpaceInvaderOne Anybody else having an issue with installing the Docker? Every time I start the Docker to install the VM instance, I just get the following:
-
😳 Ahhhh, you would be correct in assuming a controller failure of some sorts. I have an external 4 bay drive enclosure, which I thought was set to auto start when power returns, just like the unraid server. The server did indeed start, but the external enclosure didn't, hence me being slightly embarrassed. So yes, you are correct in the sense that it was a controller failure, but only because the external bay hadn't powered on..... Lesson learned, check before posting........
-
Hi. I have just recovered my unraid server from a major power cut (I do have battery backup, but this only lasts an hour, and the power was off for nearly 3 hours). Everything is up and running again, unraid is running fine, and the array has started, except the 4 unassigned disks I have. All 4 are now showing under Historical Devices instead of under unassigned devices, ready for me to mount. How can I get them back under Unassigend Devices? Please ignore the disk ending H45A as this is a failed disk from the array that I need to remove. Cheers
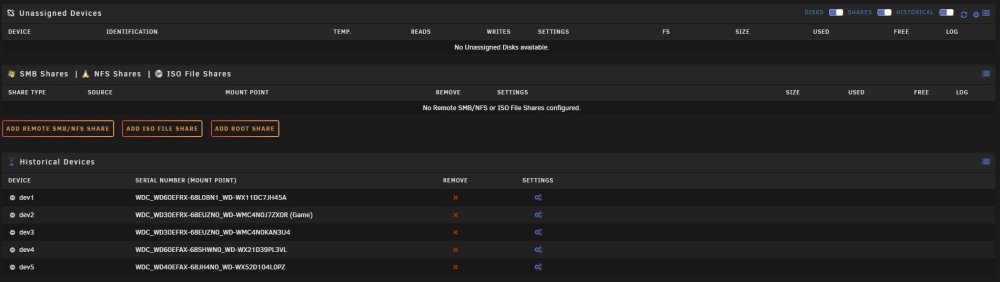
-
Cheers guys..... Its doing the parity as we speak, following @itimpiadvice above. I have now removed the offending drive, and the data is intact on Drive 4, so nothing was lost.
-
I used Unbalance to copy the data from the emulated disk to disk 4 so I have the data on another disk (Im guessing its still being emulated as well until a parity check is done) I can now remove the failed disk, but just need to do a parity check so that the parity now sees disk 4 with the data.
-
Just a thought on this, but seeing as the data is now residing on disk 4 and removed from disk 5 (the failed disk), could I follow this: If i can remove the failed disk, then force a parity sync, could this resolve my issue?
-
tower-diagnostics-20230805-1329.zip Thanks @itimpi That makes perfect sense now. So, I've moved the drive that has been disabled from bay 5 (thinking it maybe an issue with a cable) to bay 14 of the server. Unraid, again, has restarted a re-build after assigning the drive back to Disk 5, but yet again, it stopped rebuilding after 26 minutes and has disabled the drive. Remember, this drive is now in another bay in the server so isn't on the same cable as previously. So, what next..... As @JorgeB says, it appears the disk looks healthy so not sure why Unraid keeps disabling it. I have attached another diagnostics, so someone might be able to tell what is going on. Remember also, I do have 2 empty drives (disk's 4 & 6, although one of them is holding the data that I copied using unbalance from the emulated drive) that I could utilise, however both are 3TB drives, whereas the drive that is giving me issues is a 6TB drive, but it only contains 1.03TB of data. The disk causing the issue is currently empty, as Unraid thinks the data now resides on Disk 4, but its the parity I'm trying to sort out to protect the data.
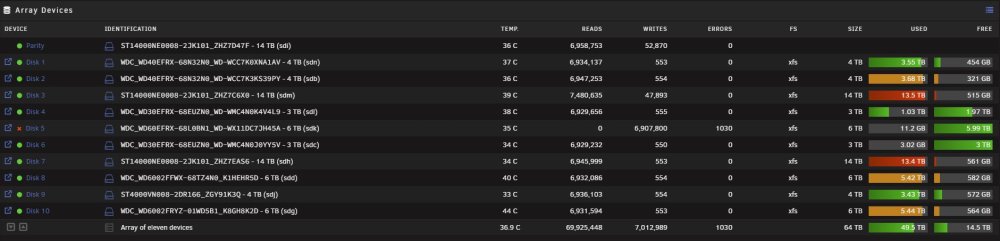
-
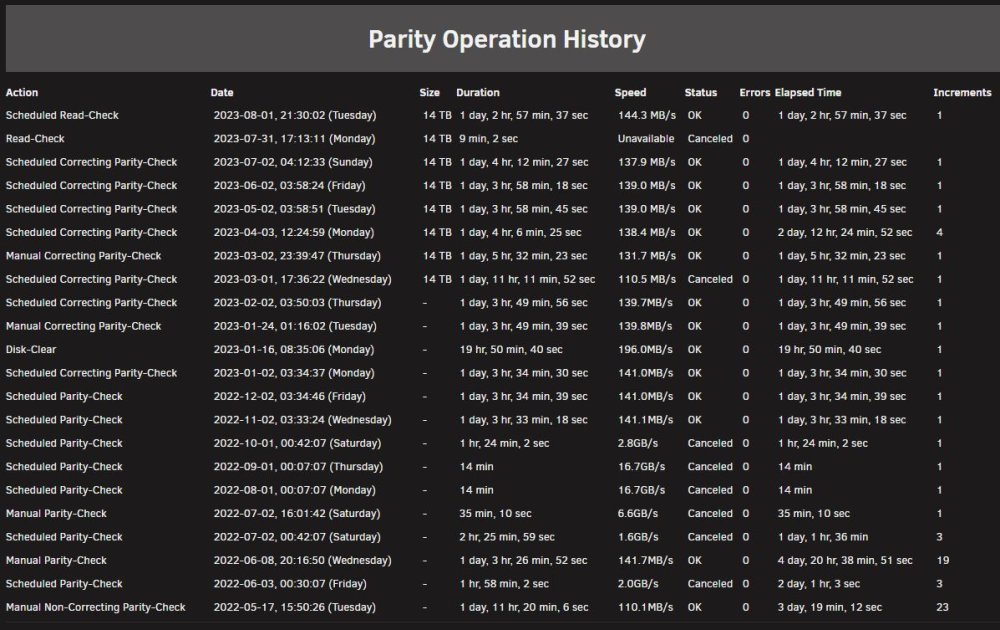
@JorgeB Why, if I have a parity drive installed (as per picture above) am I now only seeing Read-Check instead of Parity Check and am unable to run a parity check either manually or through the scheduler. On the Main Page, the check button starts a Read-Check, and if I set it under schedule, as you quite rightly pointed out, it also only does a Read-Check even though I have a parity drive? As can be seen, parity checks were working perfectly until this drive was disabled? Am I missing something?
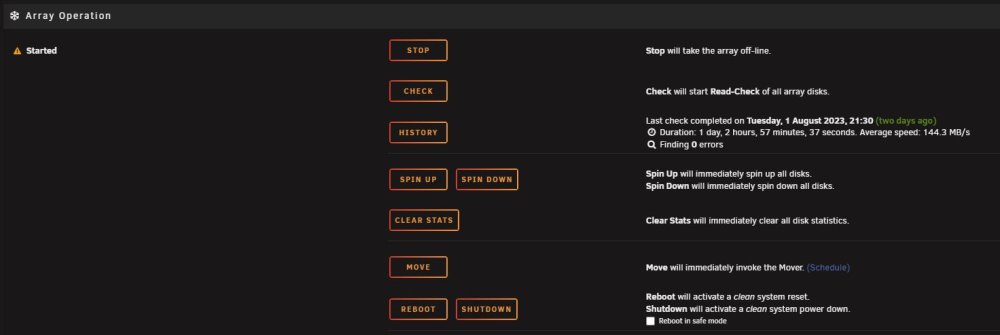
-
Actually, just a thought. If I stop whatever is running (parity or read check), shutdown the server move disk 5 to an empty Bay, then follow your link to rebuild, that should do the trick shouldn't it? I can delete the data on disk 4 once the rebuild has finished. Doing this should get me back up and running and will confirm if its the power or Sata cable that is causing the issue.





