

Fredrick
-
Posts
173 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Fredrick
-
Need advice for DAS for my drives
Fredrick replied to Fredrick's topic in Storage Devices and Controllers
Well I can at least update here. I went for it as I felt it was a pretty good offer (about 100$ including one SFF-8088 cable and a HBA), and just got it fired up to test. I installed two brand new 8tb WD Reds (128mb cache), and started the preclear. I saw an average speed of about 180MB/s per drive which to me seems good. Obviously this wont be representative for the performance with 12 drives installed in each. As I've got two ESMs and two SAN-controllers, I'm not sure which is best. The ESMs are for redundancy, so I can probably have 1 of each in each of the EXP3000. This means I've already got all I need to hook up 24 drives to my system, awesome! With regards to performance, I'd really like some input if you folks have knowledge. As far as I can tell the bottleneck for performance be the SAS cable at 6Gb/s (i think). That should be 62,5MB/s per drive, and is likely to be enough during normal operation. @johnnie.black states: Is this correct? How can i check the speed of my cable/link? This also seems to me to be a better performance than I can achieve through the SAN-controllers at 4Gb/s? -
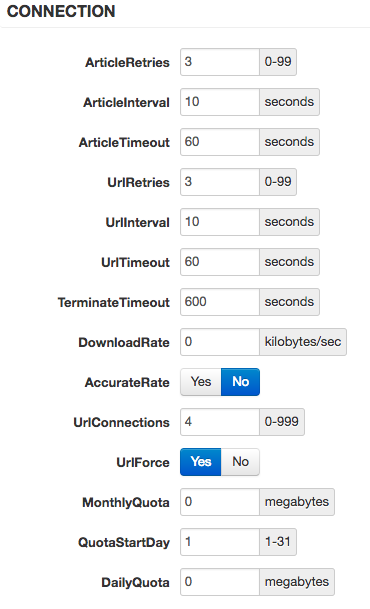
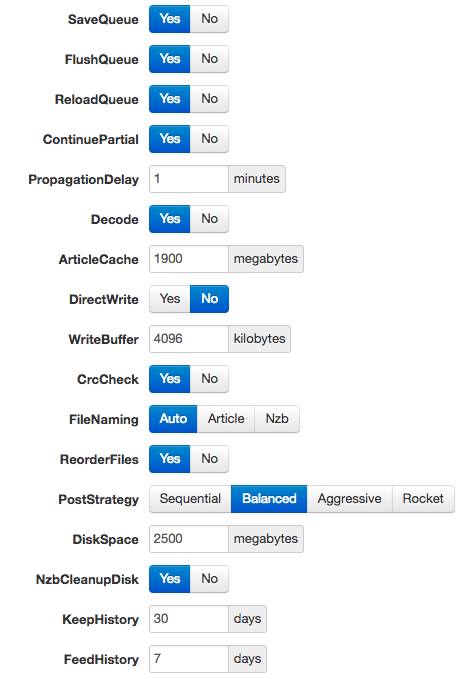
Hi guys, I've got these apps set up in dockers, and things are moving along nicely. The problem is I'm seeing a lot of iowait (15-30%) during periods where I'm downloading, and wondered if there is anything I can do with my settings to ease it up a bit. I've got a Proliant ML350 G6 with 42gb of ram and dual X5650 Xeons and a 500mbit connection I've got a 240gb SSD with about 190gb free for activities after the mover has run. NZBget is downloading and extracting to this drive, and Radarr/Sonarr is then moving the files to the array. I cant have Radarr/Sonarr move to cache as that would easily fill up my cache before the mover can run. Having a much larger cache would obviously solve my problems, but spinners cant keep up with my connection during extraction (i'm pretty sure), and SSDs are too expensive atm. My settings: So the question is simple. Can I improve this "workflow" to ease the strain on my system, particularily the array/iowait during downloads? Paging @neilt0 who seem to have some knowledge about this Thanks a lot

-
Hey guys, I'm currently on v. 1.9.0.4252 with Linuxio's image, but I've read several people recommending this image instead. As I'm running into a couple of issues with my PMS right now, I thought I'd make the switch. Are there any guides on how to best make this switch? Or is it pretty pointless? Thanks!
-
Hi guys. I'm currently running my drives (10 in number) through a LSI SAS-9201 16e card, and the drives are placed in a cheap chassis that has poor air flow, and is unsuitable for swapping drives etc. I've been looking for a used DAS/chassis that would better suit my needs. The server is a Proliant ML350 G6. Well, an opportunity has presented itself. I can get two IBM EXP3000 for cheap, but as I've previously bought something that didn't work I'd like to check with you guys. The specs are pretty thin, but the seller lists this: - 2x Fibre Channel SAS controllere (39R6502) - 2x ESM controller (39R6516) From the pictures it seems one of them has both ESM-controllers, and one has both SAS-controllers So my question is simple. Can I use these and hook them up to my LSI-card with a SFF-8088 cable? Do I need a fiber HBA to use the one with SAS-controllers? (I only need one of them today, but in the future I'll likely get more drives) How will the performance be compared to just running it from SFF-8088 to SATA cables I'm using today? This opportunity will probably be gone tomorrow, so I hope someone with knowledge can confirm this will work. Searching the forum I found this thread which seems very positive


-
Different CPU numbers on dashboard vs VM vs dockers
Fredrick replied to Fredrick's topic in General Support
I'd prefer to stick with stable releases tbh -
Hi guys, I'm trying to spread the load around and need some help understanding the numbering of my CPUs. I've got 2 Xeon X5650 processors. This is the view on the dashboard: Note that CPU 24-27 does not have any load, and has never seen any load. Meanwhile CPU 12-15 is "missing". This load you can see here is with Handbrake running an encode with the following parameters: As we are not seeing load on CPU 20-23, and instead seeing it on 16-18 I'm suspecting the dashboard view to be skewed, and that it should have been 0-23 instead of skipping 12-15. Also, when I'm adding a VM this is the numbers I can choose from: So my guess is that it's the dashboard view that is in fact "off". Any idea how I can fix this? Also does this mean core pairing should be: 0-12 1-13 2-14 3-15 etc. PS. Do you have Handbrake pinned to cores when its running with the SYS_NICE parameter, which I understand is "low priority"? Maybe I can just let it have access to all cores, and the OS will just prfioritize other tasks?



-
[SOLVED] Cant start VM after passing through a USB-controller
Fredrick replied to Fredrick's topic in General Support
I found a solution, my current config looks like this, and seems to work well. default /syslinux/menu.c32 menu title Lime Technology, Inc. prompt 0 timeout 50 label unRAID OS menu default kernel /bzimage append vfio_iommu_type1.allow_unsafe_interrupts=1 pcie_acs_override=downstream vfio-pci.ids=1912:0015 initrd=/bzroot label unRAID OS GUI Mode kernel /bzimage append pcie_acs_override=downstream initrd=/bzroot,/bzroot-gui label unRAID OS Safe Mode (no plugins, no GUI) kernel /bzimage append pcie_acs_override=downstream initrd=/bzroot unraidsafemode label unRAID OS GUI Safe Mode (no plugins) kernel /bzimage append pcie_acs_override=downstream initrd=/bzroot,/bzroot-gui unraidsafemode label Memtest86+ kernel /memtest -
Hi guys, I'm trying to pass through a USB-controller as I've had issues with passing just the USB-unit to my VM. I'm following this guide by Spaceinvare1, and found out I had to buy a PCI-controller as all my other controllers were in IOMMU groups with devices I couldn't pass. So I've updated my config to look like this, and have edited the VM to pass the PCI-device. I rebooted the server after editing the config. default /syslinux/menu.c32 menu title Lime Technology, Inc. prompt 0 timeout 50 label unRAID OS menu default kernel /bzimage append vfio-pci.ids=1912:0015 initrd=/bzroot label unRAID OS GUI Mode kernel /bzimage append initrd=/bzroot,/bzroot-gui label unRAID OS Safe Mode (no plugins, no GUI) kernel /bzimage append initrd=/bzroot unraidsafemode label unRAID OS GUI Safe Mode (no plugins) kernel /bzimage append initrd=/bzroot,/bzroot-gui unraidsafemode label Memtest86+ kernel /memtest Unfortunately, when starting the VM I get the following error in the log: 2017-09-11T07:54:01.555885Z qemu-system-x86_64: -device vfio-pci,host=05:00.0,id=hostdev0,bus=pci.0,addr=0x6: vfio: failed to set iommu for container: Operation not permitted 2017-09-11T07:54:01.555915Z qemu-system-x86_64: -device vfio-pci,host=05:00.0,id=hostdev0,bus=pci.0,addr=0x6: vfio: failed to setup container for group 19 2017-09-11T07:54:01.555931Z qemu-system-x86_64: -device vfio-pci,host=05:00.0,id=hostdev0,bus=pci.0,addr=0x6: vfio: failed to get group 19 2017-09-11T07:54:01.555947Z qemu-system-x86_64: -device vfio-pci,host=05:00.0,id=hostdev0,bus=pci.0,addr=0x6: Device initialization failed 2017-09-11 07:54:01.596+0000: shutting down, reason=failed Why can't this device be initialized? EDIT: Just to be clear. The only device in IOMMU group 19 is the controller I'm trying to pass. Thanks!
-
I've set those values now, so lets hope the problem disappears Thanks!
-
Hi guys, Was notified by Fix Common Problems plugin that I've got Call Traces, and to put my diagnostics on the forum. I tried searching and found various threads but the "Call Trace" error has multiple underlying causes so I need some help reading these logs. The first Call trace in my syslog seems to be this one, the full diagnostics file is attached: Sep 8 21:18:40 Tower kernel: Hardware name: HP ProLiant ML350 G6, BIOS D22 05/05/2011 Sep 8 21:18:40 Tower kernel: ffffc9001948bb28 ffffffff813a4a1b 0000000000000001 0000000000000000 Sep 8 21:18:40 Tower kernel: ffffc9001948bbb8 ffffffff810cb5b1 024201ca97ffbb80 ffffffff8193d4e2 Sep 8 21:18:40 Tower kernel: ffffc9001948bb50 ffffffff00000010 ffffc9001948bbc8 ffffc9001948bb68 Sep 8 21:18:40 Tower kernel: Call Trace: Sep 8 21:18:40 Tower kernel: [<ffffffff813a4a1b>] dump_stack+0x61/0x7e Sep 8 21:18:40 Tower kernel: [<ffffffff810cb5b1>] warn_alloc+0x102/0x116 Sep 8 21:18:40 Tower kernel: [<ffffffff810cbb67>] __alloc_pages_nodemask+0x541/0xc71 Sep 8 21:18:40 Tower kernel: [<ffffffff810d0d55>] ? __do_page_cache_readahead+0x1ed/0x21f Sep 8 21:18:40 Tower kernel: [<ffffffff81102d82>] alloc_pages_current+0xbe/0xe8 Sep 8 21:18:40 Tower kernel: [<ffffffff810c4d78>] __page_cache_alloc+0x89/0x9f Sep 8 21:18:40 Tower kernel: [<ffffffff810c6971>] filemap_fault+0x23d/0x458 Sep 8 21:18:40 Tower kernel: [<ffffffff810e8f38>] __do_fault+0x68/0xbb Sep 8 21:18:40 Tower kernel: [<ffffffff810edf55>] handle_mm_fault+0x6b1/0xf96 Sep 8 21:18:40 Tower kernel: [<ffffffff81042252>] __do_page_fault+0x24a/0x3ed Sep 8 21:18:40 Tower kernel: [<ffffffff81042438>] do_page_fault+0x22/0x27 Sep 8 21:18:40 Tower kernel: [<ffffffff81680f18>] page_fault+0x28/0x30 Sep 8 21:18:40 Tower kernel: Mem-Info: Sep 8 21:18:40 Tower kernel: active_anon:3619000 inactive_anon:11419 isolated_anon:0 Sep 8 21:18:40 Tower kernel: active_file:5574779 inactive_file:1190617 isolated_file:64 Sep 8 21:18:40 Tower kernel: unevictable:0 dirty:1158386 writeback:1265 unstable:0 Sep 8 21:18:40 Tower kernel: slab_reclaimable:172220 slab_unreclaimable:95433 Sep 8 21:18:40 Tower kernel: mapped:41909 shmem:252644 pagetables:17301 bounce:0 Sep 8 21:18:40 Tower kernel: free:63375 free_pcp:2 free_cma:0 The server was as far as I can tell/remember not doing much at this point. I was streaming a 40+ mbps 3D-Remux of The Hobbit, and had some slow downloads going in a Deluge container. I still had my one VM running and 12 Dockers, all mostly idling at this point. Should I be concerned, is there anything I can do? I ran extensive memtest before installing Unraid on this server. tower-diagnostics-20170910-0708.zip
-
Just to followup if anyone every were to find this thread: The old DAS/SAN is useless, it only supports small drives with certain firmware from EMC. There are some Seagate drives that can be flashed with this firmware, but the risk vs. reward was not worth it for me to go through the hassle.
-
I'm having the same issue here, netstat shows I/Owait off the charts, and unpacking is very very slow. I have pinned CPUs for my SAB-docker, but I guess that doesn't help when its hogging the array. I've got it set up to download and extract to the SSD-cache, but when Radarr moves the files they are shipped directly to array. Might have been better to also move to cache, and have the mover do its job during the night, but my SSD is too small to handle days with heavy downloading unfortunately. Anyone have ideas?
-
Hi, I've bought this old DAS/SAN and wondered if there is a possibility of using this with Unraid? From the information I found, it supports being connected as DAS to a server through fibre channel HBA cards. Does anyone have experience with this? Does it work, does it have flaws? On the other hand, it seems to support maximum 500gb/1tb drives, which would make it pretty useless
-
Thanks, I've got cAdvisor and the ca.resource.monitor, but that just seemed like a cleaner UI
-
Not from the net, no. Was to gather all dockers/local services in Organizr, not exposed to the world (i.e. Organizr not accessible outside LAN) Where can I find this screen? Is it made by a plugin?
-
Did you solve this?
-
Hey guys, I've set this up, and I feel like I am really close to the finish line, but can't seem to get there. I've tried with sonarr, and when entering the adresse (/sonarr) I'm sent to a page that simply says "Sonarr Ver." I've also tried with plex, and can see that I'm being forwarded from /web to /web/index.html, but the page is blank. Any ideas? This is the same using local IP and external domain adress. EDIT: Got Sonarr working by setting a url-base in general-settings. Now I guess I just have to google the rest of the services aswell
-
Thanks, thats it! Im running a Docker with Unifi (network admin tool for my router/APs), and it has to be run in host-mode to work properly. Any tips for getting around this? ATM im just stopping the Unifi docker to test. PS. Removed my diagnostics from the previous post to be on the safe side.
-
Like this? Anything in the diagnostics (anonymized) that still shouldnt be posted here?

-
In the GUI almost immediately when pressing Start Any way to get more logs? Cant see anything happening in either the docker log or the system log.
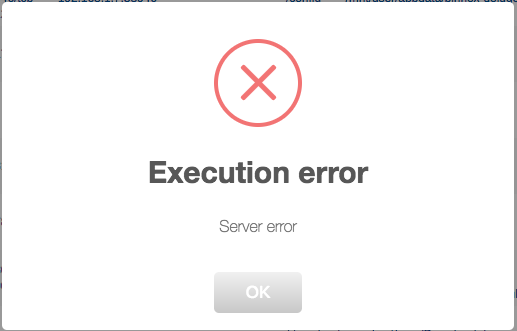
-
Just got notified that there was an update available, when I updated I'm no longer able to start the docker. Getting a "Execution error - Server error", but cant find anything in the logs. Anyone experiencing the same thing?
-
Hi! I've just started dipping my toes in what seems like great software, time to also test the community! So I've established an array with two drives (no parity yet), and I'm currently transferring my data back to a "Media" share from another local computer. The speeds are great, very stable 112MB/s over gbit network. The share resides solely on in the pool (No cache) while I copy my data. I've also installed various apps in Dockers like SABnzbd etc. These are installed on the cache only, and my downloads share is also solely on the cache drive. I should not be limited by drivespeed. If I download a file with ~50MB/s to the downloads share with SAB, the copying speed to my media-share drops equally 50MB/s. This seems likely given the gbit limitation of a network connection here at home. However, my UnRAID host has 2 gbit NICs, and they are both connected. Is there any way to direct this network traffic to independent NICs? Thanks!
-
I'm coming from a Windows installation going over to Docker now. Which version of the Controller is this running, and can I restore my backup from v. 5.4.16? EDIT: I just did what I said, but I used Unifi from Linuxserver's repo. Worked great. I assume it will work with this version aswell









