




Fredrick
Members
-
Joined
-
Last visited
Everything posted by Fredrick
-
So to anyone in my shoes, I made it work The config folder and BT_backup folder location has changed between these versions. I figured out where the new docker looked for the configs and then just manually put qbittorent.conf and the torrent files there, and it's up and running :)
-
Trying to move from an older version of qbitorrent (Linuxserver v.14.3.2) to this docker. The VPN config seems to be OK, but I was hoping I could simply copy my database and migrate every torrent over the easy way. I copied my old appdata/qbitorrent to this new binhex-qbitorrent. It still starts with no torrents in the webui. Any tips, or do I need to manually import torrents? Thanks!
-
Did you ever fix this ? I'm having the same issue on my installation. It works with Nextcloud, but I cant access either nextcloud or root account in commandline/adminer.
-
Hi, The green arrow already communicates that the container has starter so I figured why not change the actualy text with some buttons to launch WebUI, restart container or update (if update is available) and such. Maybe the buttons can be configurable as we might not want a restart button on the dashboard to avoid unintentionally misclicking it. Excuse my dirty mockup to illustrate:

-
Ah yea I'd forgot about that. I've actually got a new (well used but newer) PSU lying around, maybe this is the right time to get it swapped in (after preclear and rebuild of disk 3 I guess). Any other tips other than just having it preclear and rebuild without touching the server at all risking a new jank to appear?
-
Hi guys, Slightly panicked here now 🥲 I've installed a Coral TPU in the M.2 slot, and discovered that using the second m.2 slot disables a couple of my SATA-ports. No worries, I had more slots on my SAS-controller so I moved the SATA disks over there. Now I must have been careless with a couple of cables because after booting I still could't find the disks. I re-seated cables and tried again. Array went up fine, but after a short while Disk 3 and Disk 9 errored out and was emulated. I rebooted, did short SMART tests and then started a re-build. Disk 3 finished first (on account of being just 4TB), but again errored out while Disk 9 was being rebuilt. Seeing as Disk 3 was my oldest and smallest disk I decided to buy a new and just replace it. However when I'm currently preclearing this new drive I see Disk 10 error out which has me very concerned. I'm in the midst of a big preclear / rebuild and I'm without parity protection. I'm attaching diagnostics that I fetched yesterday (when the old Disk 3 was still present) and current diagnostics which is during the rebuild. Any advice on my course of action to maximize likelyhood of success would be greatly appreciated. Thanks! tower-diagnostics-20230511-1908.zip tower-diagnostics-20230510-2236.zip
-
Thanks - seems to build now. Lets see if I can also get it to produce output Perhaps should be updated in OP And thank you for the heads up about the access token. I've invalidated it on Huggingface now so it doesn't matter.
-
I'm trying to run this using CPU with the --gpus 0 extra parameter as shown in the guide, but I still get this error when trying to build docker run -d --name='InvokeAIv2.3' --net='bridge' -e TZ="Europe/Berlin" -e HOST_OS="Unraid" -e HOST_HOSTNAME="Tower" -e HOST_CONTAINERNAME="InvokeAIv2.3" -e 'HUGGING_FACE_HUB_TOKEN'='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' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:9090]/' -l net.unraid.docker.icon='https://i.ibb.co/LPkz8X8/logo-13003d72.png' -p '9090:9090/tcp' -v '/mnt/cache/appdata/invokeai_v23/invokeai/':'/home/invokeuser/InvokeAI/':'rw' -v '/mnt/cache/appdata/invokeai_V23/userfiles/':'/home/invokeuser/userfiles/':'rw' -v '/mnt/cache/appdata/invokeai_v23/venv/':'/home/invokeuser/venv/':'rw' --gpus 0 'mickr777/invokeai_unraid_v2.3' 59777f26be903777989ed8b5b8e4a89d48d1d8f12804c8e369e02dfc39edebec docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]. The command failed.
-
I ended up going with a VM instead of Docker for this use case
-
Hi guys! I've actually spent two full nights now and am still very much unsuccessful in launching a container based on this github-repo. I can get it built using docker-compose in ssh on my server - the image is huge but I suspect that has something to do with it actually downloading a ubuntu-distro and huge CUDA libraries (?) into the docker.img. No matter I increased the size and tried it out. The web-server needs to find a language model that I'm downloading and storing in /mnt/user/appdata/oobabooga/models, but for some reason the web-server cant find my models. Think I'm messing up my mounts somehow. Here's the Docker-compose, i.e. it's fairly untouched apart from removing the GPU part and changing the /app/models mount. version: "3.3" services: text-generation-webui: build: context: . args: # specify which cuda version your card supports: https://developer.nvidia.com/cuda-gpus TORCH_CUDA_ARCH_LIST: ${TORCH_CUDA_ARCH_LIST} WEBUI_VERSION: ${WEBUI_VERSION} env_file: .env ports: - "${HOST_PORT}:${CONTAINER_PORT}" - "${HOST_API_PORT}:${CONTAINER_API_PORT}" stdin_open: true tty: true volumes: - ./characters:/app/characters - ./extensions:/app/extensions - ./loras:/app/loras - /mnt/user/appdata/oobabooga/models:/app/models - ./presets:/app/presets - ./prompts:/app/prompts - ./softprompts:/app/softprompts - ./training:/app/training Ideally I'd just have this entire image set up using Unraid frontend completely bypassing docker-compose, but my attempts at that solution was even more of a failure so I'm not sure there's any point in writing it up. Anyone got any ideas where I'm going wrong or how I can get this set up in the simplest way? Anyone running text-generator-webui on Unraid? Thanks!
-
Yea but I'm pretty much "all in" at this point so I'm not gonna turn. Just gonna remove the drive from UDM which I'm not using, that could possible save a penny. Yes that's what I'm gonna get I'm looking at Inter-Tech 4F28 More efficient PSU is mostly cause I'm gonna need a new one when moving all drives to a single one. Currently most drives are fed by the dual PSU DAS. Any tip on a good SATA-card? I'd still need some room for expansion I didn't quite understand this. I know what I have on my different shares, but I don't know which docker keeps accessing and spinning up disks. Thats also the idea behind shutting dockers down tbh, but I see most of them are ery inactive like you say. And I have no VMs, docker and appdata completely on cache Yea but getting used parts is kind of a pain. setting up an intel machine would probably set me back 300€. Even with high energy prices we do get a lot subsidised in Norway atm. Saving 20-30W is only 50€ or so per year. Thank you for answering!
-
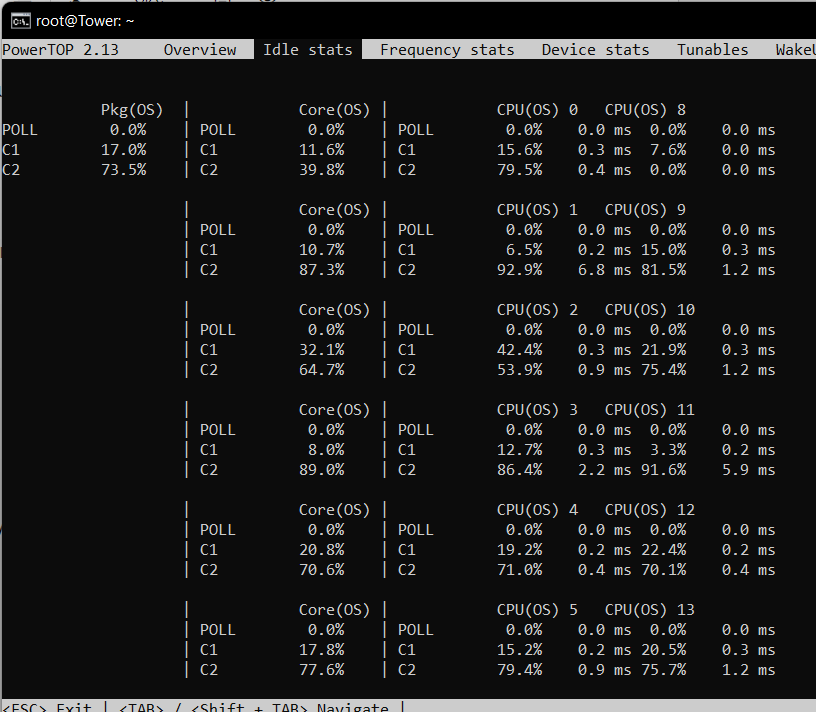
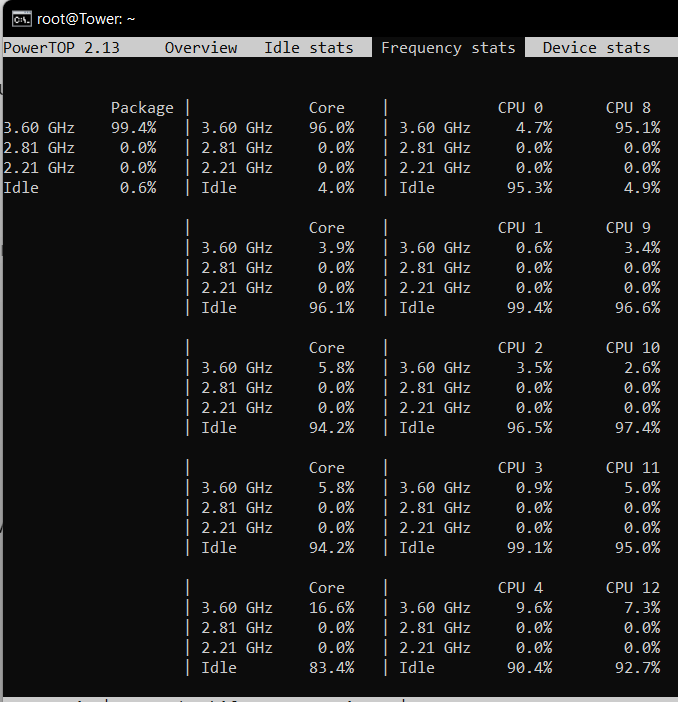
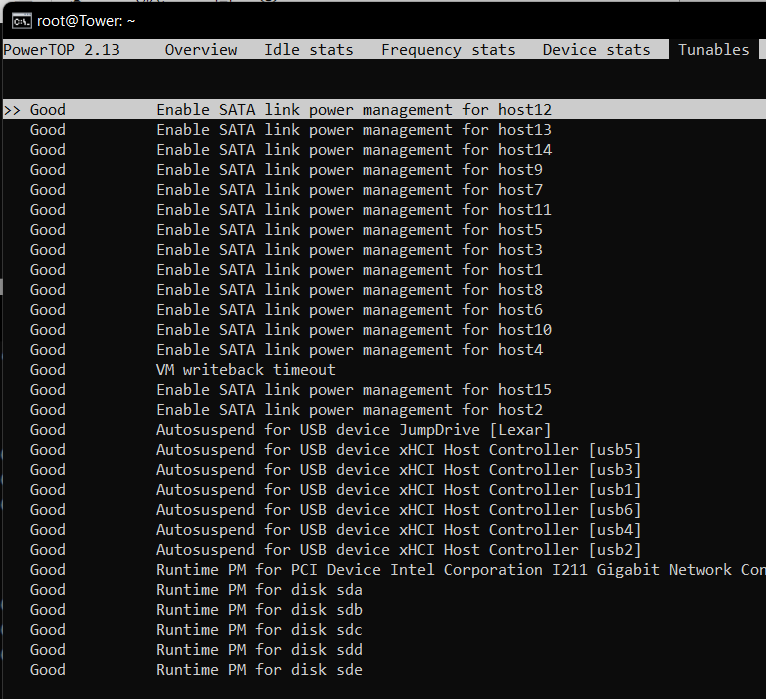
Hey guys, Looking to get some insight. I've got a very power hungry setup that I need to tweak, and obviously want to spend my money on the most efficient changes. In total my rack pulls about 350-370W at the wall. Network gear and PoE-cameras: 65W. This is a UDM Pro SE, Unifi Switch 24 Pro, 2 APs and 4 cameras via PoE. I don't think theres much to be done with this Server: 90-130W Ryzen 7 3800X 32Gb RAM LSI SAS 9202-16E (or something similar) Intel 4xgbit NIC PCI USB-controller (previously used to pass through to VM) DAS: 180W Array of 12 drives My plan is: Buy new chassis and more efficient PSU to ditch the DAS and move drives into same chassis as server Drop the USB-controller and NIC-controller. I can manage without redundant NIC Investige what makes my disks spin up. Currently I run about 24 dockers so I think pinpointing the culprits could be a pain Turn off some dockers for most of the day . I.e. I don't need Plex and arr's during the night and so on. Actually swapping the Ryzen I think is too expensive (?) to make sense in an effort to reduce my power bill Anything I've missed or should do different?
-
Hey did you ever solve this? I want to have my wireguard peer access another VLAN than my unRAID, but I can't seem to get it set up. Hoping i can avoid setting up a different VPN
-
I'm having this issue right now, do you know if there is another issue atm? @ljm42
-
Just wanted to report that it worked and I'm now back online with all my dockers. Also I've created a fresh backup
-
They don't predate, so I don't understand what has happend. I haven't changed the config since 2021, and backups are from 05.2022 and 07.2022. Maybe the flash had already started corrupting or something when the backup ran. I've decided to not dig into it more than needed as I seem to have identified the solution - thanks for confirming!
-
Hi guys, I've recently had a power outage, and even though the server is set up with a PSU to gracefully shut down it seems to have corrupted or damaged my flash. I've got multiple backups, but I seem to have some issues (and want to be extra sure not to mess things up). I had two cache pools with a single drive in each. When I booted from the restored (fresh) USB it correctly assigned my array, but I didn't notice until after starting the array that the cache pools were missing. This caused Unraid to create a new docker.img on my arraid. I've tried multiple backups, both from (the outdated) backup&restore plugin, and from My Unraid. Neither seem to have cache pools config for some reason. I've mounted my cache-drives using Unassigned now just to create a fresh backup of docker.img and appdata in case something goes wrong. After that I plan on creating the same cache pools I had before and assigning the same drives to them. As far as I can tell this is the right way, and will avoid formatting the drives? Thanks!
-
I just had a different error, but permissions related too (I couldn't log into the webui). Heres what I did that worked. This is from ssh in Unraid. docker exec -u root -it Grafana /bin/bash chmod -R a+w /var/lib/grafana EDIT: Seems I spoke too soon. I still have issues. Namely that I can't get disable_login to work. It always redirects to /login even though it's disabled. Any ideas?
-
Hey - No I didn't. I actually gave up the whole shebang.
-
I have found more weird stuff.. I changed this block in the subfolder.conf. I commented out the substitute variables and instead hardcoded them into the proxy_pass line. location ^~ /tautulli { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth, also customize and enable ldap.conf in the default conf #auth_request /auth; #error_page 401 =200 /ldaplogin; # enable for Authelia, also enable authelia-server.conf in the default site config #include /config/nginx/authelia-location.conf; include /config/nginx/proxy.conf; include /config/nginx/resolver.conf; #set $upstream_app tautulli; #set $upstream_port 8181; #set $upstream_proto http; proxy_pass http://tautulli:8181; } And this works! Why, why why does this work?
-
This looks like a subdirectory block?
-
Here it is: ## Version 2021/05/18 # first go into tautulli settings, under "Web Interface", click on show advanced, set the HTTP root to /tautulli and restart the tautulli container location ^~ /tautulli { include /config/nginx/proxy.conf; include /config/nginx/resolver.conf; set $upstream_app tautulli; set $upstream_port 8181; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } location ^~ /tautulli/api { include /config/nginx/proxy.conf; include /config/nginx/resolver.conf; set $upstream_app tautulli; set $upstream_port 8181; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } location ^~ /tautulli/newsletter { include /config/nginx/proxy.conf; include /config/nginx/resolver.conf; set $upstream_app tautulli; set $upstream_port 8181; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } location ^~ /tautulli/image { include /config/nginx/proxy.conf; include /config/nginx/resolver.conf; set $upstream_app tautulli; set $upstream_port 8181; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } /tautulli has been set as the baseurl as per the instructions on the second line. This problem is not isolated to tautulli either. Same goes fro Sonarr, Overseerr and Organizr which I've also tested. error.log from nginx: 2022/01/04 20:11:36 [error] 517#517: *2532 tautulli could not be resolved (3: Host not found), client: 192.168.1.1, server: domain.com, request: "GET /tautulli HTTP/2.0", host: "domain.com" I have also verified that the containers resolve on the same network using docker network inspect proxynet. Its not marked as default and ICC is enabled. My site-conf/default too for reference. I've commented out the location / block as per this guide: ## Version 2021/04/27 - Changelog: https://github.com/linuxserver/docker-swag/commits/master/root/defaults/default error_page 502 /502.html; # redirect all traffic to https server { listen 80 default_server; listen [::]:80 default_server; server_name _; return 301 https://$host$request_uri; } # main server block server { listen 443 ssl http2 default_server; listen [::]:443 ssl http2 default_server; root /config/www; index index.html index.htm index.php; server_name domain.com; # enable subfolder method reverse proxy confs include /config/nginx/proxy-confs/*.subfolder.conf; # all ssl related config moved to ssl.conf include /config/nginx/ssl.conf; client_max_body_size 0; #location / { # try_files $uri $uri/ /index.html /index.php?$args =404; #} location ~ \.php$ { fastcgi_split_path_info ^(.+\.php)(/.+)$; fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; include /etc/nginx/fastcgi_params; } } # enable subdomain method reverse proxy confs include /config/nginx/proxy-confs/*.subdomain.conf; # enable proxy cache for auth proxy_cache_path cache/ keys_zone=auth_cache:10m;
-
I've tried this too now with no luck unfortunately. I still need to hard code the IPs or it will just give me 404. I've also tried restarting my server just to make sure.
-
Heres an example with tautulli: domain.com/tautulli works if tautulli.subfolder.conf looks like this: set $upstream_app 172.18.0.10; set $upstream_port 8181; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; But if I have it like this I'm just getting 404 on domain.com/tautulli set $upstream_app tautulli; set $upstream_port 8181; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; As you can see I'm still able to ping tautulli from my swag-container - and it resolves to the correct IP, so I'm not really sure whats going on here.

-
Yes. I've tried with both organizr and overseerr too. All running in the same custom bridge network.





