




Fredrick
Members
-
Joined
-
Last visited
Everything posted by Fredrick
-
Hey guys, I'm setting up this container from scratch now instead of moving my old Letsencrypt folder. The readme in the proxy-conf folder says this: - If you are using unraid, create a custom network in command line via `docker network create [networkname]`, then go to docker service settings (under advanced) and set the option `Preserve user defined networks:` to `Yes`. Then in each container setting, including the swag container, in the network type dropdown, select `Custom : [networkname]`. This is a necessary step as the bridge network that unraid uses by default does not allow container to container communication. And I've done that. Yet when I try the default set $upstream_app plex; set $upstream_port 32400; It doesn't work (502 missing gateway). I have to edit it to either use the docker-IP and container-port: set $upstream_app 172.18.0.2; set $upstream_port 32400; or use the host-IP and host-PORT: set $upstream_app 192.168.1.7; set $upstream_port [HOST PORT]; As far as I can tell using the first example means container to container communication, which means the docker-network-setup has been successful. I don't understand why the dns-lookup from the sample config doesn't work? Would like to get this working before setting it up on all other containers too. It would be sweet if I didn't have to hard-code the IPs/ports as it's more robust using the name I think.
-
I'm still unable to connect to my server, even when just telnet the local port it's timing out. I'm seeing this in the log, is it usual to have multiple ports listed here? The second one seems random as it's a different one any time i restart the container.
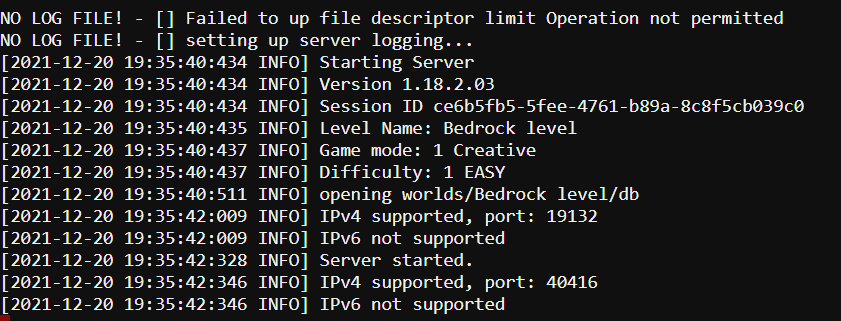
-
I'm not, sorry. I set it up again and forgot about this problem. It does mean it's kinda likely to happen again though..
-
I cant get this to work, I don't understand why I cant access the server once it's running. I'm pretty well versed in port forwarding, and I've tried both bridge, host and a separate br0-network connection. I might be misunderstanding something here, but why is the template set up with port 19137 here? It's the same for the UDP-port. EDIT: Removed the image and installed fresh from community applications and it's correctly showing 19132 again now. I still cant see the port working on canyouseeme.org though.. Here is my port-forward-rules on my Dream Machine: Docker-settings:
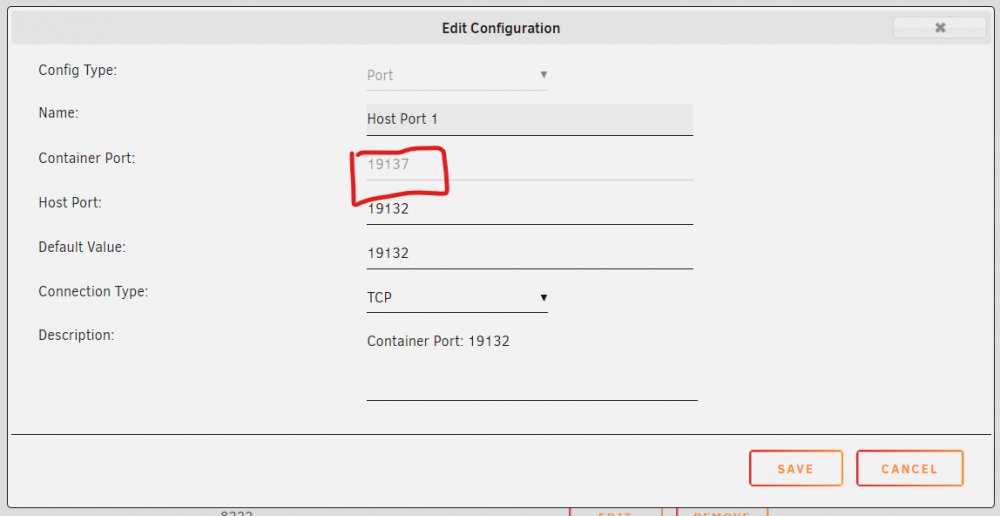


-
Hi guys, I've got a NIC with 4x GbE (plus another one in the motherboard), and I want to make sure that my config makes sense. I can patch them all up in a managed switch if need be. First of all I need a solid connection to Unraid. Thinking about dedicating 2 of the ports to a failover-bridge for Unraid. I might even patch one of the connections up in my router to have a failover even in case the switch should die on me. Secondly I've got a VM that I want on a separate VLAN. Should I put a port on the NIC on that VLAN, and use that port for the VM? Thirdly I've got a Pihole docker with it's own IP. I've previously and successfully run this on the bridge set up for Unraid, with a fixed IP in the Docker settings. Is there any pros of moving it to a dedicated port? Open to ideas or input, this is not really a territory I know much about
-
This has happend to me too. Did you ever solve it @Convington?
-
This didn't work for me. The entire /mnt/user/appdata/influxdb folder has been wiped for me, I don't know how that could have happend during the update. Just to be clear this was already a InfluxDB v2 docker, it just updated to a newer build Any ideas?
-
I believe the relevant portion of the log is in the spoiler. I don't see any errors indicated here, and the pushover notification definitely says Backup Complete. No trace of what happend with influx either. Running Unraid 6.9.2, plugin dated 2021.03.13 which I see isn't the newest. EDIT: I didn't find the correct line earlier. It does in fact indicate that the source couldn't be found, which is because I've moved my appdata from /mnt/cache/appdata to a new nvme disk at /mnt/cache_nvme/appdata. Oops.. Still no clue why Influxdb messed up so bad EDIT2: It's obviously much better to backup /mnt/user/appdata than pointing it directly to the drives. I don't know what I was thinking when I set it up..
-
So my monthly backups run on the 25th, and like clockwork I've recived a Pushover notification that it has completed the backup. I've suffered data loss, and I have no idea what happend. My influxdb appdata folder is suddenly completely empty (no settings, no database). I figured I'd just restore the latest backup, but they apparently haven't been stored for the past couple of months.. Anyone got any idea what could have happend? Both with the influxdb and with this plugin. My settings:

-
I've removed diagnostics from OP. I think I found the problem myself by scouring the logs. There were indications it was caused by "mongod" which afaik is probably the db used by unifi-controller docker. It makes sense cause that docker has been plagued with problems. Lately it suddenly pumps out insane amounts of data cause of some bug. I've tried reinstalling the entire container now and just restoring config from a backup. Hopefully that can help, but I'll keep an eye out. Is there an easy way I can set a new "starting point" for fix common problems? I.e. I'd like it to notify me about new oom-events, but not the ones I've already seen here.
-
Hi, Every time fix common problems run I'm getting errors that it detects OOM-situations on my server. However I monitor the memory usage, and I'm not seeing anywhere close to full there. Usually hovering around 40%. Is this just a bug in reporting, or is there something I'm not seeing? How can I identify the culprit? Diagnostics attached.
-
Seems that my Windows VM was logged out, and that prevented a normal shutdown for the plugin. I've made it so it stays logged in to the user account, and it performs well now. Thanks
-
Hi, I'm trying to set up this plugin to backup a VM that is running. I.e. it needs to be shut off before the backup. The plugin logs that it tries to shut it off, but it's not working. I've tested and the VM can ble cleanly shut down with "Stop" through the WebUI, so theres nothing preventing the VM from being shut off. Theres also nothing in the syslog indicating that the VM has gotten a shutdown-command, so I'm pretty sure this is not working from the plugin. Any pointers? I obviously don't want to enable force shutdown/kill. Thanks!
-
Thats a shame. I've been working on my backup, and it's nowhere near as good/fresh/complete as it should have been. Is there any reason I shouldn't trust this drive from your point of view? Thanks again
-
Thanks for getting back to me. Unfortunately it still doesn't find a file system there root@Tower:~# btrfs-select-super -s 1 /dev/sdn1 No valid Btrfs found on /dev/sdn1 Open ctree failed
-
I suspect the drive didn't get re-formatted correctly when I made it into cache_vms, and that's why btrfs commands are not working. I hope it's okay to try and tag @JorgeB here cause I think he or she is the person for the job. Thanks a lot root@Tower:~# fdisk /dev/sdn -l Disk /dev/sdn: 223.57 GiB, 240057409536 bytes, 468862128 sectors Disk model: KINGSTON SV300S3 Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x00000000 Device Boot Start End Sectors Size Id Type /dev/sdn1 2048 468862127 468860080 223.6G 83 Linux root@Tower:~# file -sL /dev/sdn /dev/sdn: DOS/MBR boot sector; partition 1 : ID=0x83, start-CHS (0x0,0,0), end-CHS (0x0,0,0), startsector 2048, 468860080 sectors, extended partition table (last) parted command is not available on unraid it seems.
-
I've also tried restoring backup superblock as outlined here, but got the same results as OP in that thread.
-
Hi, I'm upgrading my server, and wanted to run my VMs from a newly created cache pool. I moved my vdisks to the array, formatted the drive as a cache-pool (btrfs) with a single drive, and moved the vdisks back. I then started the VM and checked everything, it was working well. Now I had to do a reboot since I'd filled up my log-vdisk from running the mover (moved plex-directory with loads of files). After rebooting the new cache_vms is showing as unmountable. I've tried step 1 and 2 from here, but it didn't work. root@Tower:/# mount -o usebackuproot,ro /dev/sdn1 /x mount: /x: wrong fs type, bad option, bad superblock on /dev/sdn1, missing codepage or helper program, or other error. root@Tower:/mnt/disk8# btrfs restore -v /dev/sdn1 /mnt/disk8/restore No valid Btrfs found on /dev/sdn1 Could not open root, trying backup super No valid Btrfs found on /dev/sdn1 Could not open root, trying backup super ERROR: superblock bytenr 274877906944 is larger than device size 240056360960 Now is there any chance of getting my images back? One of the VMs runs my home automations and is kinda critical. I've got a windows backup of the important files, but I was hoping to avoid having to set up a new VM and restoring the data. Diagnostics attached Thanks a bunch! tower-diagnostics-20210718-1547.zip
-
Hi, I wanted to ask just to be sure before doing something very stupid.. I've upgraded my server and with it comes a new nvme drive that I want to use for Dockers. I've created the new cache called cache_nvme, and set Shares "appdata" and "system" to prefer the new cache_nvme. The files are however still left on the old cache, and I've tried to find the "correct" way to move it. Should I: Set the shares to Yes: Cache_nvme Invoke the mover Set the shares to Prefer: cache_nvme Invoke the mover Or is there a better way? I guess I could disable Docker and move with terminal from /mnt/cache/appdata/ to /mnt/cache_nvme/appdata, but that kind of sounds more risky to me. Thanks!
-
Hey guys, I'm about to upgrade my Unraid server, and wanted to check in with you to see if there is anything I'm forgetting or should change before taking the leap. I'm currently on 6.8.2 running on an old Proliant ML350 G6 - 2x Xeon 5650x, 40GB ECC RAM. Drives are attached via a SAS-expander through an LSI (9207-8e I believe) controller. I'm running about 25 Dockers and 2-4 VMs. I've got a 1TB SSD as the main Cache, a 250GB SSD through Unassigned drives for my VMs and a 1TB spinner throught Unassigned drives for temporary downloads (for the extraction). Now I want to upgrade to something a bit more lightweight (power/noise-wise) while keeping most of the oomph. I'm also getting a NVME drive for database performance. Here is my hardware purchase list. I've got a chassis and a PSU. It's a downgrade on the RAM-capacity, but I've got room to expand if need be. I'm choosing previous generation Ryzen as it's more affordable and accessible than the newer 5600X counterpart with roughly the same performance. Ryzen 7 3700X 2x 16GB Corsair Vengeance RGB PRO SL DDR4-3600 DC C18 GIGABYTE B450 AORUS PRO WD Black SN850 PCIe 4.0 NVMe M.2 - 500GB I plan on upgrading to 6.9 and make use of the new cache pools. This is the plan: NVMe drive for Dockers, including the various database applications (InfluxDB for metrics/Grafana, MariaDB for NextCloud, MySQL for various applications/development). Shares using this drive will prefer cache Existing 1TB SSD as my "main" cache which will recieve writes such as downloads and file transfers. Shares that use this will be set up to move to array Existing 250GB SSD will continue to hold my VMs Now as far as I can tell I should be able to build the new server, move the SAS-controller and USB-drive and it should boot into Unraid. I'll then have to set up the new cache pools and be good to go, right? I'd love some input if you've got some. Thanks!
-
I ended up shutting the system down from vacation. When I came back I re-seated all cables to SAS-expanders and booted again. Parity was marked as invalid. I did a read-check of the array which went without errors. Then I stopped the array, unassigned the parity drives, started the array, stopped the array, assigned parity drives again. It re-built both parity drives without errors, and is seemingly running well now. I'll pay attention to the RAM usage going forward. Thanks.
-
Diagnostics attached, thanks EDIT: Diagnostics removed.
-
Hi guys, I'm on vacation but got some concerning notifications from unRAID l night. Both my parity drives had been disabled within the same minute, I've got errors all over and a warning on my cache drive. I'm afraid to stop the array or reboot. Any advice? Attached screenshot
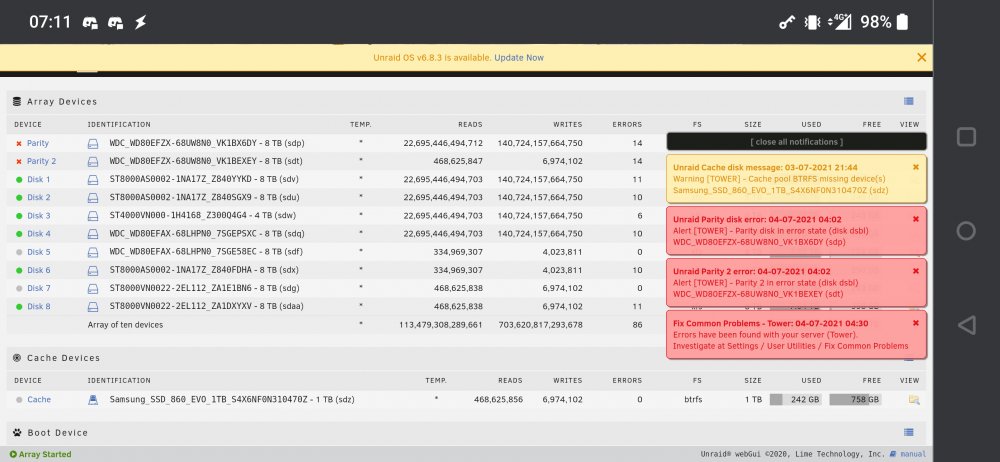
-
I don't know why, but this is not working for me. The server.log is spammed with various warnings about mongod not being shut down correctly and needs repairing. Mongod.log on the other hand has other messages thats equally cryptic to me unfortunately.. Seems to still be a version mismatch: Fatal assertion 28579 UnsupportedFormat: Unable to find metadata for table:index-1--7693998512115095491 Index: {name: site_id_1, ns: ace.account} - version too new for this mongod. See http://dochub.mongodb.org/core/3.4-index-downgrade for detailed instructions on how to handle this error. at src/mongo/db/storage/wiredtiger/wiredtiger_index.cpp 268
-
This is with a Debian bare-metal VPS without GUI so I dont think thats an option unfortunately. I'm trying to contact my influxdb-server using this command: curl -G http://MY-IP:8086/query -u username:password --data-urlencode "q=SHOW DATABASES" The same command works when trying from another computer on the same network, then by using the local IP. I'm obviously using my global IP when trying from VPS. Same username and password works locally. EDIT: Got it! It was my port forwarding that was off, damn Unifi changing the entire UI between each time I edit settings..








