




shaunsund
Members
-
Joined
-
Last visited
Everything posted by shaunsund
-
Lost my USB drive Sunday sometime. System still was running, Plex worked but the /boot dir was non-existent. The old drive won't show up as a USB device and due to some misconfigurations with my backup system and the Flash backup, I only had 3 month-old backup of my config/ dir. Making lemonade out of lemons, I decided to start from scratch (my config dir had become a mess of old plugins and other detritus ) and throwing caution to the wind I went with a fresh install of 6.12.0-rc3 on a new USB drive. Working on bringing back some Dockers and then VMs, but currently I seem to be having some odd issues: The Apps tab (limited to Safari I think) fails to load all the CSS at times and has misinformed page items (large app logos, wrong fonts, etc). I also get "Did not parse stylesheet at <server address>/plugins/community.applications/skins/Narrow/css.php?v=1678545693 because non CSS MIME types are note allowed in strict mode." and an "avatar FailedToLoad error' on the browser console. I get past this by toggling the "Disable content blockers" setting for the page - until it happens again. Haven't figured out why or what causes it again. I also have seen times where I'l be on a Settings page, for example, and the UI will refresh and take me to the Main page. Got some random times where I can't pull images and the UI is slow to load. I could ping my router from unraid but couldn't ping 1.1.1.1. Yet other devices could ping 1.1.1.1 so it wasn't a loss of my network service. Then, randomly, I can pull images and things work. I doubt I am the first to have issues like these, but haven't found a reason or solution here with Google. the -2108 is the diag from when I lost the drive. -1330 is today after getting some things working. fractal-diagnostics-20230416-2108.zip fractal-diagnostics-20230417-1330.zip
-
I've wiped my app data several times, removed the images and re-downloaed several times, and even rebooted!. Still does it. You ask about Nerd Tools... I'm not sure how that would affect a container, but I do have libffi, libsodium, python3, vim, unrar, iftop, iotop and tmux innstalled.
-
Yes. 6.11.5
-
Cleared the cached docker config, redownloaded from the App Store, deleted the appdata folder for this container and tried again, but still got a segmentation fault.
-
I did find a dump log from MegaSync. It seems to crash after gathering a file list from Mega. 56886e1e-a417-80e0-2834909c-50631d7e.dmp
-
It's unusable. The container restarts.
-
Megasync client segfaults and the container restarts. Basically can't sync.
-
I have suddenly started to get `Error for "xrdb -query" command: "/bin/bash: line 1: xrdb: command not found\n" It will happen everytime it syncs a file list from mega. I have redownloaded and configured the docker several times.
-
A few scripts that run hourly, daily or weekly. Only 2 that run at the start of the array. I have disabled them both and restarted. Still have that strange output.
-
Here ya go! fractal-diagnostics-20230211-2131.zip
-
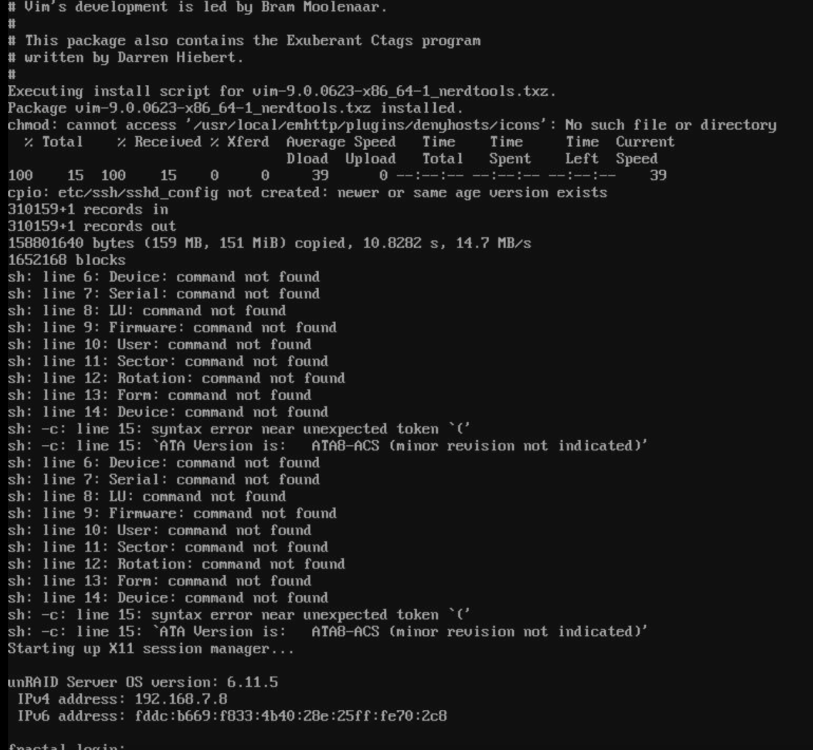
So I got an odd message coming up on my screen on every reboot lately: The lines starting with "sh:" are errors from what appears to be a disk report that somehow is running as a script upon a boot. I must have coped the output to a script or something dumb. Here's the odd thing; I can't find any file in /boot matching any of the terms. I've ran: find /boot -type f -exec grep -l "ATA8-ACS" {} \; find /boot -type f -exec grep -l "Firmware" {} \; The server is working fine. Other than this odd output every time it boots! find and grep seem to be failing me. Can anyone think of where to look or what to do? Thanks in advance.
-
I'll add my thoughts on the extended tests: I found the search for duplicate files handy - sometimes in the past a Move operation would do weird things. Would be nice to verify my FS.
-
I see your points. Still don't know why it did it.
-
well if a drive disappeared then the calculation for disk free would change -- although I would expect that to cause a warning before disk usage. I did check while writing the first post, every disk's utilization warning and critical are equal to the global. Also, even if they were different, why did they alarm for 2 disks and report ok for 6 disks a minute later? Like JorgeB mentioned it seems to be "an elusive issue and difficult to replicate"
-
Wow! I should go buy a lottery ticket.
-
So this is odd. I have 8 data disks and all except #1 are nearly full so I set my global warning at 93% and critical is 97% usage so that everything is OK utilization wise. Today was the second time I got the below messages: and also one for disk 8. Yet, a minute later I get the following: also for disk 3, 4, 5, 7, and 8 I got the Warning at 5:19pm and then the Notice emails at 5:20pm. Disks are practically idle during this time. I don't know why they would hiccup these utilization errors. If I had a disk or cache drive drop out then maybe the totals might change but there is no indication in syslog as to a cause for these warnings. fractal-diagnostics-20201104-1804.zip
-
Has anyone else been getting Out of memory errors when it comes to qbittorent? I've had the max memory set to 2G for the longest time but within the last few weeks I always get a OOM error from Unraid. Even upping the memory to 2.5G still gives OOM. Seems like there is now a memory leak. Oct 29 21:10:58 fractal kernel: Memory cgroup out of memory: Kill process 24455 (qbittorrent-nox) score 984 or sacrifice child
-
I have been trying to add a single data drive and a single cache drive with encryption. After entering the password for the encryption, it would show both drives as needing formatting, But after formatting them both, it then says the cache drive needs to be formatted. Allowing it to format the cache drive a second time results in a non-encrypted cache drive. After going through this several times with different disk settings (xfs or Btrfs encryption) I did the format with encryption and then reverted to 6.8.3 without the second format. The cache tab shows it formatted with odd partitioning (can't recall the exact wording) and a correcting format results in a encrypted cache drive. Screenshots and diags included beta29-always formatting cache.zip
-
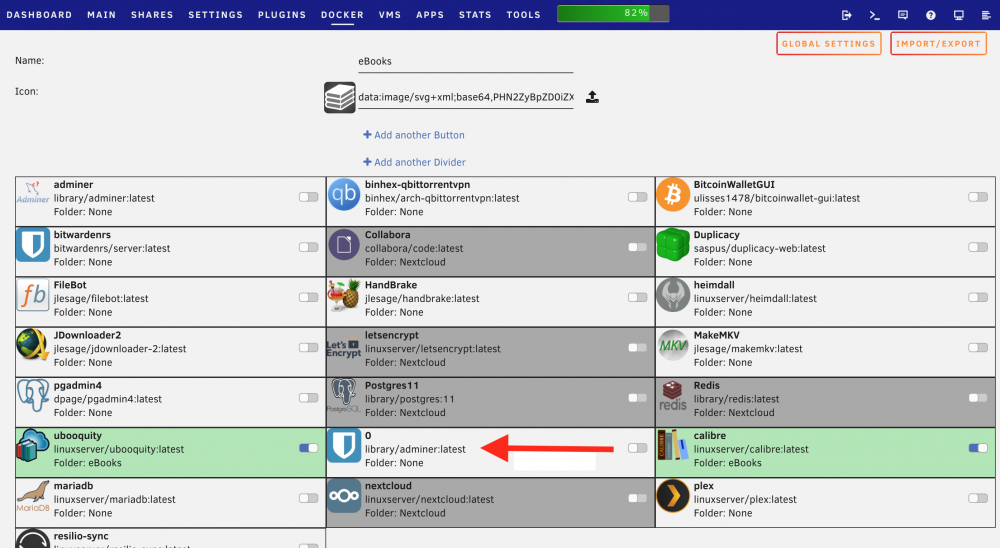
Loving this plugin, but did notice something odd: Image named '0' with wrong Icon for the image name. It can't be a orphaned image; I have a User Script that removes those.
-
With the 6.8 update I have noticed host and dig fail: I am pretty sure a library needs to be included from NerdPack. Not sure which one, though.
-
A quick feature request: Have a per SMB share option to select: Version (1,2, or 3) and sec=ntlm as the mount options. (And perhaps even a way to manually change the whole option string). Example: I have a few smb servers that are old so I turn "Force all SMB remote shares to SMB v1?" to Yes. But with that, another server fails to mount: Mar 28 14:07:22 fractal unassigned.devices: Mount SMB/NFS command: mount -t cifs -o rw,nounix,iocharset=utf8,_netdev,file_mode=0777,dir_mode=0777,sec=ntlm,vers=1.0,username='***',password=******* '//RASPIVAULT/LexarCrypt' '/mnt/disks/RASPIVAULT_LexarCrypt' Mar 28 14:07:22 fractal unassigned.devices: Mount of '//RASPIVAULT/LexarCrypt' failed. Error message: mount error(13): Permission denied Refer to the mount.cifs(8) manual page (e.g. man mount.cifs) So I have to change "Force all SMB remote shares to SMB v1?" to No and then I can mount: Mar 28 14:08:21 fractal unassigned.devices: Mount SMB/NFS command: mount -t cifs -o rw,nounix,iocharset=utf8,_netdev,file_mode=0777,dir_mode=0777,,vers=3.0,username='***',password=******* '//RASPIVAULT/LexarCrypt' '/mnt/disks/RASPIVAULT_LexarCrypt' Mar 28 14:08:21 fractal unassigned.devices: Successfully mounted '//RASPIVAULT/LexarCrypt' on '/mnt/disks/RASPIVAULT_LexarCrypt'. The difference between them are "sec=ntlm,vers=1.0" and ",,vers=3.0" respectively. As it is now, to get both of these to mount, there is some config changes to make manually.
-
Sometimes the openvpn-as docker is fragile on upgrading. I upgraded to the most recent docker this morning and the OPENVPN server stopped working. From the openvpn.log it looks like it is missing a config item 'config_db_local': 2019-03-15 05:05:19-0400 [-] Server Shut Down. 2019-03-15T05:05:41-0400 [twisted.scripts._twistd_unix.UnixAppLogger#info] twist d 17.9.0 (/config/bin/python 2.7.11) starting up. 2019-03-15T05:05:41-0400 [twisted.scripts._twistd_unix.UnixAppLogger#info] react or class: twisted.internet.epollreactor.EPollReactor. 2019-03-15T05:05:41-0400 [stdout#info] *** Insecure settings found. Permissions for /config/etc/as.conf were set to 0666. Resetting Permissions to 0600 *** 2019-03-15T05:05:42-0400 [-] Unhandled Error Traceback (most recent call last): File "/config/lib/python2.7/site-packages/Twisted-17.9.0-py2.7-linux-x 86_64.egg/twisted/application/app.py", line 396, in startReactor self.config, oldstdout, oldstderr, self.profiler, reactor) File "/config/lib/python2.7/site-packages/Twisted-17.9.0-py2.7-linux-x 86_64.egg/twisted/application/app.py", line 311, in runReactorWithLogging reactor.run() File "/config/lib/python2.7/site-packages/Twisted-17.9.0-py2.7-linux-x86_64.egg/twisted/internet/base.py", line 1243, in run self.mainLoop() File "/config/lib/python2.7/site-packages/Twisted-17.9.0-py2.7-linux-x86_64.egg/twisted/internet/base.py", line 1252, in mainLoop self.runUntilCurrent() --- <exception caught here> --- File "/config/lib/python2.7/site-packages/Twisted-17.9.0-py2.7-linux-x86_64.egg/twisted/internet/base.py", line 878, in runUntilCurrent call.func(*call.args, **call.kw) File "build/bdist.linux-x86_64/egg/pyovpn/sagent/svcset.py", line 203, in server_agent_init File "build/bdist.linux-x86_64/egg/pyovpn/sagent/svcset.py", line 58, in get_active_config_profile File "build/bdist.linux-x86_64/egg/pyovpn/db/confdb.py", line 811, in get_active_profile File "build/bdist.linux-x86_64/egg/pyovpn/db/dbwrap.py", line 87, in db File "build/bdist.linux-x86_64/egg/pyovpn/sagent/svcset.py", line 56, in <lambda> File "build/bdist.linux-x86_64/egg/pyovpn/util/cdict.py", line 260, in get_req File "build/bdist.linux-x86_64/egg/pyovpn/util/cdict.py", line 303, in get_type File "build/bdist.linux-x86_64/egg/pyovpn/util/cdict.py", line 478, in log pyovpn.util.error.SimpleError: "ConfigDict: required config-key 'config_db_local' is not defined": util/cdict:285,util/cdict:257,util/cdict:521,util/cdict:550 (exceptions.KeyError) Anyone have an idea of what it should be and in what config file?
-
Confirmed. That worked. Thanks!
-
FWIW: I updated to 6.6.1 and still have the error.
-
Both 6.6.0 and 6.6.0-rc4 ... I haven't yet updated to 6.6.1 yet.


