

Dimtar
-
Posts
549 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Dimtar
-
-
3 minutes ago, sparklyballs said:
we don't recommend updating through the webui
for instance you'd be missing a dependency that was added as part of the rebrand
Thanks Sparky, normally I don't update through the container but a broken container wouldn't worry me in this case.
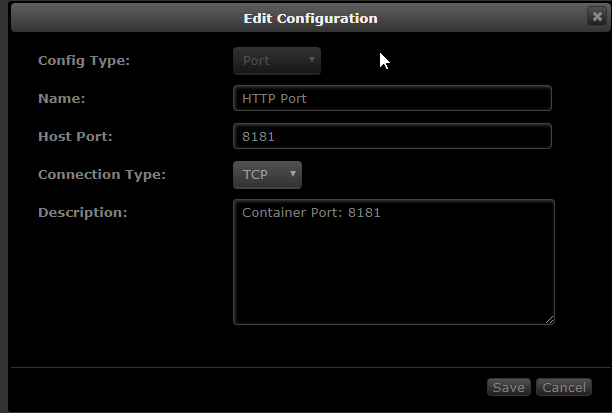
Is there something wrong with the tautilli container template? It seems like its missing the container port?

-
9 hours ago, CHBMB said:
Project has been renamed from Plexpy to Tautulli.
To migrate:
1. Stop the current plexpy container.
2. Use Community Applications to install Tautulli, utilising your existing Plexpy appdata folder for /config.
I clicked the update prompt in the web interface for PlexPy and updated to Tautulli without hassle. It also works after a restart of the container. Are you saying the plexpy and tautulli containers are different?
-
Will there be another version of the docker container released in time to address this or once its broken its broken?
-
2 hours ago, ezbox said:
Good Afternoon,
It seems the latest update of the docker is broken, does not load up, had to go to version 91 again and this fixed the problem.
if you need to do this, change the repository to linuxserver/radarr:91
Just reporting,
Ezbox
PS. Another friend who uses the docker too had the same problem, unable to load.
Just wanted throw my hat in the ring on this one.
-
1 hour ago, thomast_88 said:
Yes. As of now.
Excellent, will test soon. TY
-
6 hours ago, WannabeMKII said:
I'm trying to migrate from v1 to v2. As per the instructions, I've moved the cfg and db files to the root of the hydra2, but when trying to import, I get the following;
But as per the screenshot, the files are there and in the right place?
Where have I gone wrong?
Try /config/settings.cfg /config/nzbhydra.db
-
 1
1
-
-
Has this docker been updated to include the new cache option?
-
On 16/01/2018 at 10:06 AM, saarg said:
I guess this will be the one as there may be some issues migrating to V2. Don't want V1 users to suddenly have a non working container if we pushed V2.
It’s a major new version running on an entirely different language, I think this is the right approach.
On another note, the container is great. Thanks team.
-
Just wanted to report back, I added an additional 8GB of memory to the system. Its only been 24 hours but I have had no load problems and the memory load in the dashboard hasn't went above 27%. Thanks a bunch for your help, I learnt alot during this whole process.
-
Here is a very rough example.
rclone mount --cache-db-path /mnt/user/rclonedb --cache-chunk-path /mnt/user/rclonechunk googlecache: /mnt/user/googlemountYou can just set it all in line, the above example would only work if you created the shares before hand and hopefully put them on a cache drive. Hope this helps somewhat.
-
47 minutes ago, woble said:
Hey @binhex Is upgrade automatic with the newest releases of nzbhydra2 or do you have to upgrade the docker manually for us to get the new version?
I believe its the latter.
-
@Aric There is a command with rclone to set the cache DB location, have you tried that?
-
@carlos28355 I read this on the Plex Roku forum:
QuoteMy fix for this issue on Roku 3 client and a WD NAS Plex server was to go to the web page, Settings -> Debug -> uncheck Direct Play, and then reboot the Plex client app on Roku.
-
On 21/01/2018 at 12:01 AM, johnnie.black said:
You're getting out of memory errors, probably one of the dockers, best bet would be to shut them all down, turn on one by one and leave it a few days to try and find the culprit.
Why am I not getting email notifications of your replies? This comment is not directed at you, just speaking out loud.
Thanks for the tip, I am pretty sure its the NZBGet docker as its the only container doing anything each day. I also install iotop to help me, thanks for your help I appreciate it.
-
On 19/01/2018 at 11:08 PM, johnnie.black said:
Try getting the diags by typing diagnostics on the console.
Load is currently 67, attached is the diagnostics dump.
-
4 minutes ago, johnnie.black said:
Try getting the diags by typing diagnostics on the console.
Its no longer at load but i'll provide next time.
-
Hi all.
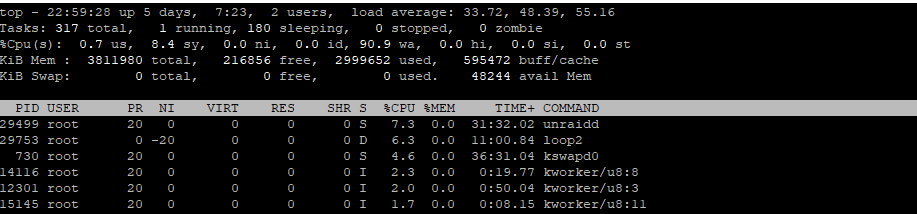
This problem wasn't happening but then it started randomly and its happening more and more. So right now, my server is near un-usable. Its currently sitting at a load of 60. (please see screenshot)
The server isn't doing anything, the load will at some stage come down and the server will be usable again but I am trying to work out what exactly is causing this. If i open netdata during this time, it shows IOwait as the biggest issue but I am not sure what is causing that.
This is the result of "free -hm", am I running out of ram and its swapping to drives?
root@ASTRO:~# free -hm
total used free shared buff/cache available
Mem: 3.6G 2.9G 190M 473M 558M 14M
Swap: 0B 0B 0BLike right now I have 10% of kswap0 and 10% of unraidd, is that it swapping to the disk?
I don't have a cache drive and the server is essentially ideal right now. Any ideas on stuff to look at?
-
Has anyone installed an RSS plugin? I tried the one from the Deluge site but neither of the python versions installed.
-
11 hours ago, ScoHo said:
Trying to set this up with Google Drive and getting the below message when the backup runs. I did enable no-auto-compact. I'm running a fresh backup for the first time so I don't care about losing data on the Google Drive (there isn't any there anyway). Any ideas?
"The backup contains files that belong to another operating system. Proceeding with a backup would cause the database to contain paths from two different operation systems, which is not supported. To proceed without losing remote data, delete all filesets and make sure the --no-auto-compact option is set, then run the backup again to re-use the existing data on the remote store."
Could you try backing up somewhere else? Like B2, just as a test don't do the full backup. Just to work out if its Google Drive or something else?
-
The docker is now available in CA, just an FYI.
This isn't loading for me, this just keeps going in the log over and over:
e":"No such container: f08423aa0af6"}
-
@DZMM I read your thread a few days ago, I am still impressed. I was hoping to hear from others too.
-
Hi all.
So there has been alot of videos and talk about having an unRaid box, running a VM and passing through the graphics card. It makes me wonder, who is actually using this day to day? As in they have a fully functioning desktop PC capable of running Windows with a keyboard/mouse/monitor and running unRaid underneath. Keen to hear all stories.
-
20 minutes ago, binhex said:
11GB, impressive, it must be logging the entire internet :-), i will take a look at this when i get a min, see if i can at the very least redirect it outside of the container.
I have hardly even used it, maybe its just really noisy? Thanks for looking into this, whenever you do.
-
3 minutes ago, DZMM said:
Unfortunately you have to delete your docker image and reinstall each docker (you don't lose app data) afterwards.
Thanks for the fast reply. I added the extra parameters you mentioned and this was enough to give the container a new ID. This deleted the old folder and removed the 11GB file its self. So all should be good now, thanks again.




[Support] Linuxserver.io - Tautulli
in Docker Containers
Posted
For comparison this is the Sonnar container:
I obviously don't know anything about these things but my guess is the template isn't aware the Tautulli container needs a port?