ElectricBadger
Members
-
Joined
-
Last visited
Everything posted by ElectricBadger
-
True, though the last time I looked at cloudflare, I got a redirect loop when I tried to view the privacy policy, which put me off somewhat.
-
I have DNS on Gandi, which is does not have a certbot plugin. That is supported by acme.sh, though — along with a whole lot of other DNS providers that certbot doesn't support. As wildcard certificates require DNS verification, this is going to be a bit of a blocker. (I did submit a feature request on the certbot repo for Gandi support, but the reply I got seemed to indicate that it wouldn't happen unless I wrote it myself, so that's unlikely to happen any time soon, alas…) I don't suppose there are any plans to switch the docker from certbot to acme.sh? I'm guessing not, though it's worth asking
-
OK, so I left it overnight and it died again. Now I'm getting this: [0mRecipe: gitlab::gitlab-rails[0m * execute[clear the gitlab-rails cache] action run [32m- execute /opt/gitlab/bin/gitlab-rake cache:clear[0m [0m[0m Running handlers:[0m There was an error running gitlab-ctl reconfigure: execute[/opt/gitlab/embedded/bin/initdb -D /var/opt/gitlab/postgresql/data -E UTF8] (gitlab::postgresql line 80) had an error: Mixlib::ShellOut::ShellCommandFailed: Expected process to exit with [0], but received '1' ---- Begin output of /opt/gitlab/embedded/bin/initdb -D /var/opt/gitlab/postgresql/data -E UTF8 ---- STDOUT: The files belonging to this database system will be owned by user "gitlab-psql". This user must also own the server process. The database cluster will be initialized with locale "C.UTF-8". The default text search configuration will be set to "english". Data page checksums are disabled. STDERR: initdb: directory "/var/opt/gitlab/postgresql/data" exists but is not empty If you want to create a new database system, either remove or empty the directory "/var/opt/gitlab/postgresql/data" or run initdb with an argument other than "/var/opt/gitlab/postgresql/data". ---- End output of /opt/gitlab/embedded/bin/initdb -D /var/opt/gitlab/postgresql/data -E UTF8 ---- Ran /opt/gitlab/embedded/bin/initdb -D /var/opt/gitlab/postgresql/data -E UTF8 returned 1 Running handlers complete [0mChef Client failed. 25 resources updated in 15 seconds[0m I'm also assuming that plenty of other people are managing to use this docker image, so there's probably something I've done wrong, but I can't see what could cause this, unless it's related to this: I have the data folder set to be /mnt/disk6/appdata/gitlab-ce/data, and the log folder set similarly (config remains on cache). However, it seems to have created both /mnt/disk6/appdata/gitlab-ce and /mnt/cache/appdata/gitlab-ce. I'll try stopping the image, nuking both folders and restarting — if it can survive a couple of nights, I guess that fixes it
-
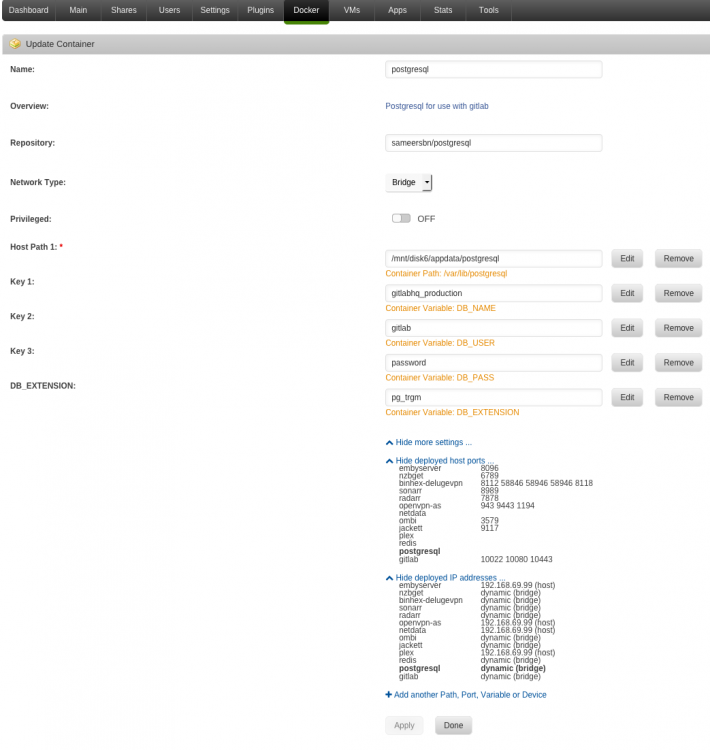
UPDATE: hm, it looks like it might be a similar problem in both versions — despite setting the Postgres data to be on /mnt/disk6/appdata rather than /mnt/cache/appdata, it seems to have created files in both folders. I've stopped the Dockers, nuked both folders, and restarted — so far, everything's correctly appearing just on disk6. I'll run it for a few nights and see if that fixes the problem. I've tried switching to the sameersbn version of gitlab after having terrible trouble getting the GitLab CE Docker image to work. It worked for slightly less than 12 hours, and then postgresql failed overnight and will not restart: ErrorWarningSystemArrayLogin Initializing datadir... Initializing certdir... Initializing logdir... Initializing rundir... Setting resolv.conf ACLs... Creating database user: gitlab Creating database: gitlabhq_production... ‣ Loading pg_trgm extension... ‣ Granting access to gitlab user... Starting PostgreSQL 9.6... LOG: database system was shut down at 2018-03-09 22:52:40 GMT LOG: MultiXact member wraparound protections are now enabled LOG: database system is ready to accept connections LOG: autovacuum launcher started ERROR: database "gitlabhq_production" already exists STATEMENT: CREATE DATABASE "gitlabhq_production" ENCODING = 'unicode' FATAL: could not open relation mapping file "global/pg_filenode.map": No such file or directory FATAL: could not open relation mapping file "global/pg_filenode.map": No such file or directory FATAL: could not open relation mapping file "global/pg_filenode.map": No such file or directory PANIC: could not open control file "global/pg_control": No such file or directory LOG: checkpointer process (PID 1285) was terminated by signal 6: Aborted LOG: terminating any other active server processes WARNING: terminating connection because of crash of another server process DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory. HINT: In a moment you should be able to reconnect to the database and repeat your command. WARNING: terminating connection because of crash of another server process DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory. HINT: In a moment you should be able to reconnect to the database and repeat your command. WARNING: terminating connection because of crash of another server process DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory. HINT: In a moment you should be able to reconnect to the database and repeat your command. WARNING: terminating connection because of crash of another server process DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory. HINT: In a moment you should be able to reconnect to the database and repeat your command. WARNING: terminating connection because of crash of another server process DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory. HINT: In a moment you should be able to reconnect to the database and repeat your command. LOG: all server processes terminated; reinitializing PANIC: could not open control file "global/pg_control": No such file or directory Initializing datadir... Initializing certdir... Initializing logdir... Initializing rundir... Setting resolv.conf ACLs... Initializing database... initdb: directory "/var/lib/postgresql/9.6/main" exists but is not empty If you want to create a new database system, either remove or empty the directory "/var/lib/postgresql/9.6/main" or run initdb with an argument other than "/var/lib/postgresql/9.6/main". Initializing datadir... Initializing certdir... Initializing logdir... Initializing rundir... Setting resolv.conf ACLs... Initializing database... initdb: directory "/var/lib/postgresql/9.6/main" exists but is not empty If you want to create a new database system, either remove or empty the directory "/var/lib/postgresql/9.6/main" or run initdb with an argument other than "/var/lib/postgresql/9.6/main". Why is it trying to initialise the database every time it starts? Surely the logic should be "if the database already exists, use it, otherwise create it"? I can't see anything odd in the config — the only things I've done are move the /var/lib/postgresql mapping to be on disk6 rather than cache* and add the DB_EXTENSION=pg_trgm. Does anybody know why this is unstable? Thanks * Or is it safe to just point at /mnt/user/appdata/postgresql here? I know the gitlab-ce docker has dire warnings about using cache (too expensive to fill with a massive database) or an explicit disk rather than /mnt/user…
-
I've managed to get it working with my local SMTP server by editing gitlab.rb, but I'm a bit concerned that those changes might get clobbered the next time the docker image is updated. I'd really like to know if it's safe to edit this file. I also fixed the SSH issue by adding another port redirecting to 22 rather than 9022, and using that. Kind of odd that the default points to somewhere that nothing's listening, though
-
I'm not receiving emails sent by Gitlab. They appear to be sending OK Started GET "/users/password/new" for 192.168.69.1 at 2018-03-04 10:04:59 +000$ Processing by PasswordsController#new as HTML Completed 200 OK in 149ms (Views: 107.8ms | ActiveRecord: 2.1ms) Started POST "/users/password" for 192.168.69.1 at 2018-03-04 10:05:30 +0000 Processing by PasswordsController#create as HTML Parameters: {"utf8"=>"�..", "authenticity_token"=>"[FILTERED]", "user"=>{"email"=>"[email protected]"}} [ActiveJob] Enqueued ActionMailer::DeliveryJob (Job ID: 16360967-a9f7-4559-969a-883d9342633e) to Sidekiq(maile rs) with arguments: "DeviseMailer", "reset_password_instructions", "deliver_now", gid://gitlab/User/2, "fT5V5L -YHwVzBvdz5yuw", {} Redirected to http://192.168.69.99:9080/users/sign_in Completed 302 Found in 306ms (ActiveRecord: 36.7ms) Started GET "/users/sign_in" for 192.168.69.1 at 2018-03-04 10:05:31 +0000 Processing by SessionsController#new as HTML Completed 200 OK in 14ms (Views: 7.6ms | ActiveRecord: 0.3ms) [ActiveJob] [ActionMailer::DeliveryJob] [16360967-a9f7-4559-969a-883d9342633e] Performing ActionMailer::Delive ryJob from Sidekiq(mailers) with arguments: "DeviseMailer", "reset_password_instructions", "deliver_now", gid: //gitlab/User/2, "fT5V5L-YHwVzBvdz5yuw", {} [ActiveJob] [ActionMailer::DeliveryJob] [16360967-a9f7-4559-969a-883d9342633e] Sent mail to [email protected] (4.2ms) [ActiveJob] [ActionMailer::DeliveryJob] [16360967-a9f7-4559-969a-883d9342633e] Performed ActionMailer::Deliver yJob from Sidekiq(mailers) in 97.42ms but are not showing up in the incoming mail log in my mail server. If I exec a shell on the docker image, ps auxww doesn't appear to show a running mailserver and I wasn't prompted for details of a remote SMTP server anywhere. Looking at https://elijahpaul.co.uk/using-an-smtp-server-with-gitlab/ it appears I need to edit /etc/gitlab/gitlab.rb, but this smells like something that's going to get overwritten the next time the docker gets updated. How can I configure it to send emails and have the settings stick? Ideally, there would be variables in the template that I could configure to use a remote SMTP server. (Even if it's safe to edit gitlab.rb and not have it clobbered on upgrades, it would still be easier this way For the record, these are the lines I had to change (obviously, with actual domain redacted — edit as appropriate) before running gitlab-ctl reconfigure: gitlab_rails['gitlab_email_enabled'] = true gitlab_rails['gitlab_email_from'] = '[email protected]' gitlab_rails['gitlab_email_display_name'] = 'GitLab' gitlab_rails['gitlab_email_reply_to'] = '[email protected]' gitlab_rails['smtp_enable'] = true gitlab_rails['smtp_address'] = "mail.example.co.uk" gitlab_rails['smtp_port'] = 25 gitlab_rails['smtp_domain'] = "example.co.uk" gitlab_rails['smtp_enable_starttls_auto'] = false gitlab_rails['smtp_tls'] = false Also, how do I get ssh working? Running netstat from within the image shows an ssh server running on port 22 and nothing on port 9022, but the XML at https://github.com/tynor88/docker-templates/blob/master/tynor88/gitlab-ce.xml shows 9022 is being mapped to 9022, not to 22. I don't really want to have to pull and push over HTTP, especially with 2FA enabled…
-
Bingo! Removing all three lines has fixed the problem. Thanks a lot for your help
-
LAN_RANGE looks correct to me — the server is at 192.168.69.99, and the local network is 192.168.69.* — could it be the .ovpn file? route-method exe route-delay 2 route 0.0.0.0 0.0.0.0 Is "0.0.0.0 0.0.0.0" correct there? This is what PureVPN supplied…
-
Thanks — should have attached the log in the first place supervisord.UPLOAD.log Looks like the "[debug] Waiting for valid IP address from tunnel" part is the problem — it appears to be running ifconfig 'tun0' 2>/dev/null | grep 'inet' | grep -P -o -m 1 '(?<=inet\s)[^\s]+' which returns an external IP when I run it manually.
-
Yup, that's all correct: /mnt/user/downloads/incomplete_torrents and /mnt/user/downloads/completed_torrents both exist and are mapped correctly when I look inside the docker with docker exec bash. It seems to be an issue with connecting over the VPN though, as I said, it can download the blockfile OK so it must be getting out somehow! Is there anybody else using PureVPN? I'm using the server they said was p2p-enabled — here's the .ovpn file: remote nl2-ovpn-udp.pointtoserver.com 53 client dev tun proto udp persist-key ca ca.crt tls-auth Wdc.key 1 cipher AES-256-CBC comp-lzo verb 1 mute 20 route-method exe route-delay 2 route 0.0.0.0 0.0.0.0 auth-user-pass credentials.conf auth-retry interact explicit-exit-notify 2 ifconfig-nowarn auth-nocache

-
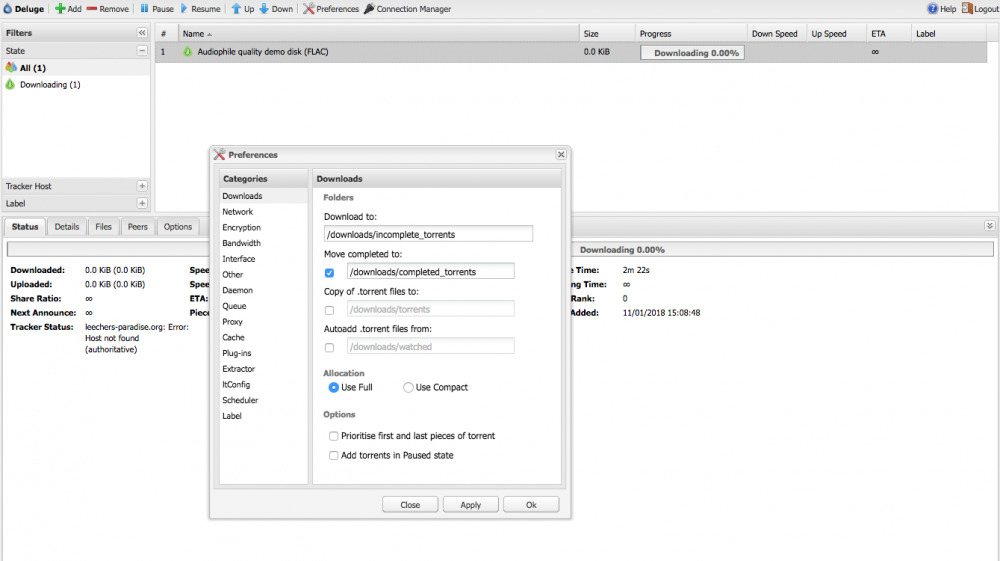
I have this image working with PureVPN, and can access sites through the Amsterdam p2p endpoint. Privoxy is working correctly — using an IP checker site shows that my IP is located in Amsterdam, and I can access sites that are normally IP-blocked in the UK. However, Deluge refuses to connect and download anything — all torrents just sit at "downloading 0.00%" and all trackers time out. If I attempt to add a Ubuntu distro it claims it's unable to download the .torrent file — I can only use Magnet links to add something. But even those torrents won't start, as they can't find the trackers. I can download a blocklist from the link in the Spaceinvader One video, but then the trackers come up with "blocked by IP filter" ¯\_(ツ)_/¯. Without the blocklist, I get things like "coppersurfer.tk: host not found (authoritative)". If I connect my desktop system to the VPN and use Transmission, I can connect to the trackers just fine, and the download starts. Does anybody know what could be going wrong here? The log contains the following lines: 2018-01-10 14:33:21,039 DEBG 'start-script' stdout output: Wed Jan 10 14:33:21 2018 ERROR: Linux route add command failed: external program exited with error status: 2 but unhelpfully it does not say what the 'route add' command actually was. I can't find where this start-script is defined to have a look at it, either. But it seems a little odd that everything works fine through the VPN except Deluge!
-
I've set Ombi up with Emby, Sonarr and Radarr enabled, but no search form is displayed under the text "Want to watch something that is not currently on Emby?! No problem! Just search for it below and request it!". The web console shows the following error: TypeError: $content is undefined search.js:287:1 focusSearch http://192.168.69.99:3579/Content/search.js:287:1 <anonymous> http://192.168.69.99:3579/Content/search.js:54:5 i http://192.168.69.99:3579/Content/jquery-2.2.1.min.js:2:27060 fireWith http://192.168.69.99:3579/Content/jquery-2.2.1.min.js:2:27828 ready http://192.168.69.99:3579/Content/jquery-2.2.1.min.js:2:29619 J http://192.168.69.99:3579/Content/jquery-2.2.1.min.js:2:29804 There are no ad-blockers running on this page. Unfortunately, I can't file an issue against Ombi itself as the Docker version is 2.2.1678 and the Ombi issue template says that version 2.x is not supported any more, and asks me not to open issues against it. Does anybody know what's going on here? From looking at the JavaScript, it's attempting to focus a tab, but it hasn't rendered any… (yes, I did remember to check the 'Enabled' boxes on Sonarr and Radarr!) FIXED IT: forgot to enable the search types under Ombi Configuration! Slightly odd that every search type defaults to off, but there you go
-
I've got this working (thanks to @gridrunner) but I can't quite see how to get it to pass proxy settings to the client so that web traffic from the client will pass through my local Privoxy (running in the DelugeVPN docker container) before going out to the web. Googling for "openvpn proxy" just returns a load of results about how to access openvpn through a proxy, which isn't what I'm trying to do here, and I didn't find anything obvious in the openvpn-as WebUI… Is there a way to get this to happen automatically on connect, or do I need to manually configure proxy settings each time? The client is the iOS OpenVPN Connect, if it matters… Thanks!
-
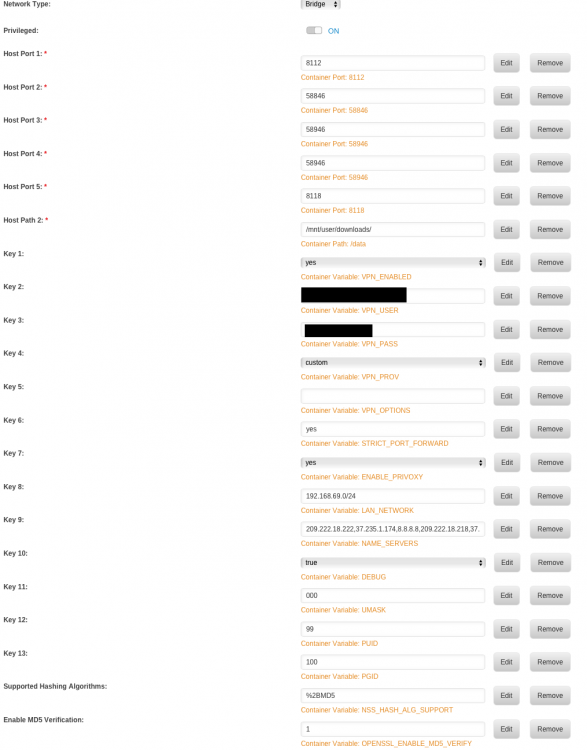
Not sure if you've had an answer to this, but I couldn't find one… Replace the + with %2B — it's being passed through a function like PHP's urldecode() at some point. Where are you setting these? I've tried putting these settings in VPN_OPTIONS, and it falls over, complaining about invalid options to --auth-user-pass. I've tried adding a couple of container variables, as below, and it doesn't enable MD5 verification, as the log shows. Could somebody please explain how I can set this image up to connect to PureVPN? The only solution I've seen suggested is "get PureVPN to upgrade their certificates", which would be ideal, but also not likely to happen any time soon — and in the meantime, I have a subscription I can't use with unRAID… Update: I've also tried removing the two variables I've added, and adding --setenv NSS_HASH_ALG_SUPPORT '%2BMD5' --setenv OPENSSL_ENABLE_MD5_VERIFY '1' in VPN_OPTIONS, but this just results in a command line ending in --auth-user-pass credentials.conf '--setenv NSS_HASH_ALG_SUPPORT '+MD5' --setenv OPENSSL_ENABLE_MD5_VERIFY '1'' which doesn't work either. Surely there must be a way to add these environment variables? log.txt Further update: OK, it seems that the easy solution is to raise a ticket with PureVPN and ask them for a more up-to-date cert. You'll then need to edit the .ovpn file to change the server address to one that supports the new cert (they should provide a list of these in their reply). At least I'm up and running now…