




ElectricBadger
Members
-
Joined
-
Last visited
Everything posted by ElectricBadger
-
@JorgeB Thanks — that's fixed it! Bizarre that the other two VMs were getting the right IP address despite appearing to use virbr0, but now that I've enabled bridging on the interface, they seem to have changed to br0 without any manual intervention! I wonder if they were using bridging all along?
-
Thanks — both are network source virbr0, and network model virtio-net. I don't even have br0 in the list!
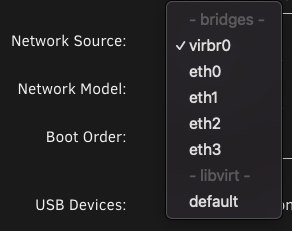
-
My local network is 192.168.69.*, with the Unraid server at 192.168.69.99. The DHCP server is a Pi-hole at 192.168.69.13. I recently tried to set up a new VM, only to find that it could not see the network. I found that Unraid had created something at 192.168.122.1, and was running its own DHCP server on that, meaning the VM was getting an IP address of 192.168.122.196 and could not see or be seen by anything else. I changed my Mac's subnet mask to 255.255.0.0 so I could see what was going on, and nmap found that 192.168.122.1 was exposing the same ports as 192.168.69.99's VMs — I could VNC into each one. Existing VMs behave correctly, and I can't see anything in the new VM setup that tells Unraid to do this. How do I stop Unraid from trying to be a DHCP server? I have a DHCP server, and a second one on some random subnet just breaks things!
-
Far too many links in unRAID don't behave like normal links: if you click them, they open in the same tab; if you ⌘-click (or ctrl-click if not on Mac) then they open in a new tab. Example: On the Docker page, ⌘-click Settings. Expected behaviour: a new tab opens containing the Settings page. The original tab is still on the Docker page. Actual behaviour: both tabs are on the Settings page, because the source for the Settings link is this: <a href="/Settings" onclick="initab('/Settings')">Settings</a> I don't know what initab does, but given the new tab (which is opened by the href and ignores the onclick) seems to work just fine, then it doesn't seem to be particularly necessary. Another example: Click on Apps, and click on the Support button for any app. Click on the Support Forum link. Expected behaviour: it opens in the same tab. If I want to open it in a new tab, I can ⌘-click it to use the standard browser behaviour. If I want to open it in a different browser, I can right-click on it and choose Copy Link Address. Actual behaviour: it opens in a new tab, because it has target="_blank" set, despite my not having been asked if I want this behaviour by default, and not having any way to turn it off. I cannot right-click to copy the link in order to open it in the same tab (or a different window from the one the current tab is in, or a different browser) because unRAID disables right-click on this menu even though it works on other page elements. WHY? SummaryunRAID should not assume how people want to use links; it should just use standard <a href="whatever"> without JavaScript overrides and without target="_blank". I'm fairly sure unRAID users are advanced enough to know about the modifier key to open a link in a new tab if they want it there. But there is no modifier key for "ignore the target attribute and open in this tab"…
-
I'm very confused by all of this. I already know there are multiple sites with man pages online, and that's of no use to me when I'm using ssh to access unRAID. I just want to type man command like on every other Unix-based system and have it work. I don't want to have to manually build man pages — I want unRAID to have an option to include them, and then have it do all the legwork for me. That's why I posted this in the Feature Requests forum — in the hope of getting an "include manpages" checkbox somewhere under Settings 🙂
-
Thanks — there seems to be something I'm missing, though. Install by pasting https://raw.githubusercontent.com/ich777/un-get/master/un-get.plg into the manual install plugin page (you'd think this would be documented in the plugin's README, but it isn't…) Type un-get update Type un-get install mandb man-pages groff Get error Can't find package(s): mandb! Do I need to add something to the sources.list in order to do this?
-
10 seconds. Yes, no wonder it was causing problems. Thanks!
-
Is there a way to use this with containers that use SQLite, such as Sonarr or Radarr, without it causing their databases to be corrupted when it stops the container? (Running a backup without stopping the container, obviously — but that's not ideal as the backup could be corrupted!) Unfortunately, whatever method is used to stop the container doesn't seem to wait long enough for Radarr to finish before abruptly terminating the container mid-operation. (It's also possible that Radarr doesn't spot that it's being asked to shut down gracefully and just rampages on until it gets killed…)
-
If I manually set the VNC port for a VM, and enter 5717 (for example) the form accepts it. I don't find out that VNC ports must be 5900 or greater until I try to start the VM, meaning I then have to go back into the editor and change it again. If the port number entered is invalid, that should be shown in the editor (inline, not as a modal alert!) as soon as the focus leaves the port number field.
-
Under unRAID 6, the VMs page showed the VNC port for each VM. In unRAID 7, this is no longer shown. Opening the VNC connection in-browser does not show the port in the URL, either: the port parameter is empty. I should not have to port-scan my server to find how to connect VNC to a VM; I also shouldn't have to manage the ports myself by manually allocating port numbers to VMs where I want to use a separate VNC client. The old method of displaying the port number in the listing worked just fine. Please bring it back.
-
ScenarioI want to use the "find" command to find all files in a folder older than 6 months. ProblemI can't remember the correct syntax. Actual behaviourI type "man find" and get "man: command not found". I type "find --help" and get this, which is not helpful: Tests (N can be +N or -N or N): -amin N -anewer FILE -atime N -cmin N -cnewer FILE -context CONTEXT -ctime N -empty -false -fstype TYPE -gid N -group NAME -ilname PATTERN -iname PATTERN -inum N -iwholename PATTERN -iregex PATTERN -links N -lname PATTERN -mmin N -mtime N -name PATTERN -newer FILE -nouser -nogroup -path PATTERN -perm [-/]MODE -regex PATTERN -readable -writable -executable -wholename PATTERN -size N[bcwkMG] -true -type [bcdpflsD] -uid N -used N -user NAME -xtype [bcdpfls] If I type "man find" on my Mac, I get help for a different version of find, which suggests I can use "-ctime 20w". This does not work in unRAID. Expected behaviourI type "man find" and can get the correct syntax, because unRAID installs the man pages for its commands. Please could unRAID support actually having documentation for its commands? Man pages were working on the old Sun 3/50s that I was using in the late 80s, and they had considerably less CPU and disk space that what any unRAID user is running now. There's room for them! There really is!
-
Why does checking for port forwarding with PIA take so long sometimes? 2025-09-04 09:34:02,652 DEBG 'start-script' stdout output: [info] Port forwarding is enabled [info] Checking endpoint 'georgia.privacy.network' is port forward enabled... 2025-09-04 09:42:03,692 DEBG 'start-script' stdout output: [warn] Json query '.regions | .[] | select(.port_forward==true) | .dns' returns empty result for port forward enabled servers, skipping endpoint port forward check [info] Script finished to assign incoming port Using the PIA Mac desktop app, I can connect directly to that endpoint in a matter of seconds. This took eight minutes and, even then, the line afterwards looks like it timed out and just assumed there was no port forwarding. Is there a variable I can change to reduce the timeout to something a bit more sensible, like 30 seconds? (And now, after it's printed that line, it's sat there for another four minutes, with no VPN connection and no proxy server — meaning that it's now 16 minutes since I started the container at 09:31 and it still isn't up. It never used to take this long — and, as I said, I can connect from my desktop machine using the PIA app in just a few seconds, so it doesn't seem to be PIA at fault…) Further update: it seems to be something with the Georgia endpoint; startup was back to the usual speeds when I switched to a different country. It's a pain to have to do this, though, as some services require you to tell them if you're using a VPN, and which country you're using, so you have to go and edit your profile in all of them…
-
After the nextcloud container auto-updated last night, it didn't restart (because the mariadb container hadn't finished restarting). Once I restarted it manually, it sat in maintenance mode for ages, then asked me to create a new admin user, as if it had been freshly installed. The existing admin user and non-admin user are still there; neither of them can edit users, either (which is correct for the non-admin user, but the admin user should be able to do this). If, when logged in as the admin user, I go the Administration Privileges page, I have an option for "Administration Privileges — Users" which I can leave empty or set to Local, but if I set it to Local and then log out and back in again, I still don't see a link to User Management. How can I make my original admin user into a super-admin so that I can get on with administering this instance? (And why did it destroy my setup when updating, anyway? Even restoring from an appdata backup didn't get it working again…) UPDATE: oh, wait. For some reason the config.php is 0 bytes long. Despite my having restored it from a backup 🙄 Fortunately, manually restoring that one file and restarting Nextcloud seems to have done the trick. (It also doesn't help that the Nextcloud documentation titles the section User Management and implies there's a User Management link on the Administration Settings, when in fact it's called Accounts and is on the profile icon at the top right. It's probably not the Done Thing to use the rolling eyes emoji twice in the same paragraph, but…
-
Thanks — that seems to work when I try accessing the site in a browser that hasn’t accessed it before. In Vivaldi, opening a new tab and accessing the site also works. Simply reloading an existing tab gives this, which caused a bit of confusion! Off to the Vivaldi bug reporter I go…
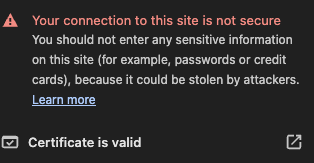
-
Is it possible to have wildcard certificates for more than one domain? Annoyingly, wildcards don't cover subdomains, so a wildcard for *.example.com doesn't cover *.subdomain.example.com as well. I guess I could spin up a second container with its own appdata, but that seems rather wasteful
-
Never mind — I found the problem. Running the htpasswd command directly on macOS produces a password file that's rather different from running that "docker run" command above. Different encryption, perhaps? And the registry container seems particularly fussy about which encryption versions it will use.
-
I can't get authentication to work on this container, and can't find where I'm going wrong. I have the container set up like this: and this Swag config: server { listen *:80; server_name myserver.example.net; server_tokens off; return 301 https://$http_host:$request_uri; client_max_body_size 0; access_log /config/log/nginx/docker_registry_access.log; error_log /config/log/nginx/docker_registry_error.log; } server { listen *:443 ssl; server_name myserver.example.net; server_tokens off; include /config/nginx/ssl.conf; client_max_body_size 0; chunked_transfer_encoding on; access_log /config/log/nginx/docker_registry_access.log; error_log /config/log/nginx/docker_registry_error.log; location / { include /config/nginx/proxy.conf; set $upstream_app docker-registry; set $upstream_port 5000; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } location /v2/ { include /config/nginx/proxy.conf; add_header 'Docker-Distribution-Api-Version' 'registry/2.0' always; set $upstream_app docker-registry; set $upstream_port 5000; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } } I've created the password file with htpasswd -c /mnt/user/appdata/docker-registry/docker_registry_auth/htpasswd username and if I replace "-c" with "-v" and re-enter the password it says it's correct. But If I run "docker login myserver.example.net" I get Error response from daemon: login attempt to https://myserver/v2/ failed with status: 401 Unauthorized Can anybody spot where this is going wrong?
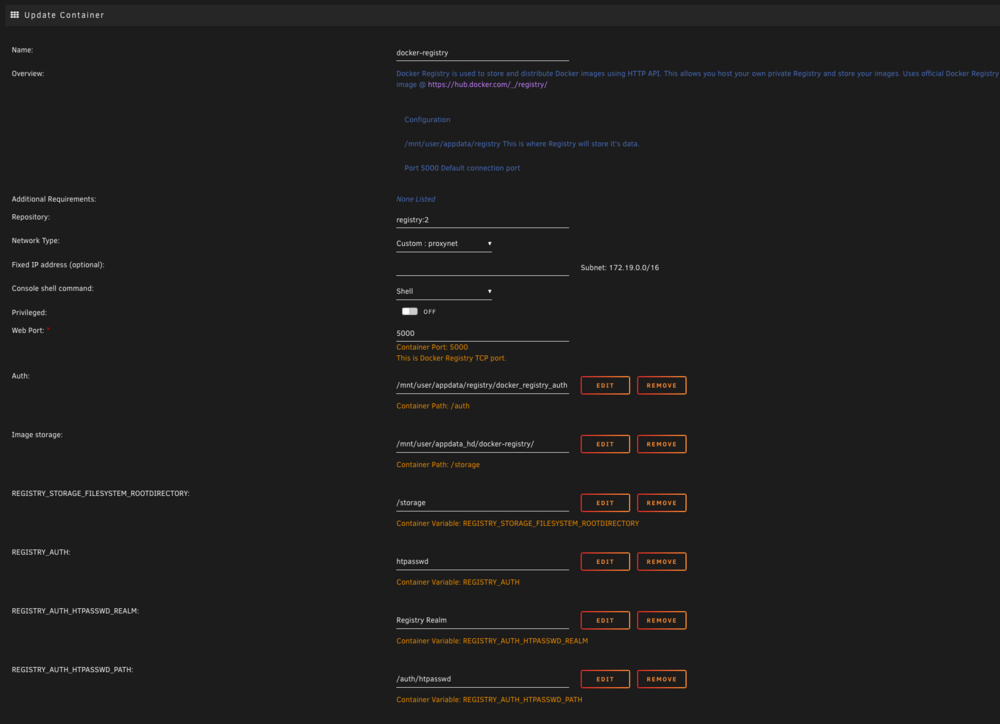
-
It looks like development is now proceeding at https://github.com/nzbgetcom/nzbget and the project is active. It would help if lsio would point the image at this new fork, but I don't know if it meets their requirements yet.
-
Ah yes, the subheadings look the same as the headings. Got it now. Unfortunately, the refresh button didn't do anything, so I guess I'll have to reboot at some point after the parity rebuild. Thanks! Update: it seems to have noticed overnight that the drive had gone, so no need for a reboot. Except there's an unRAID update anyway 😁
-
No, it's not in Unassigned Devices — that's not showing anything. This is what I'm seeing — but Dev 2 (sdq) is no longer physically connected to the server.
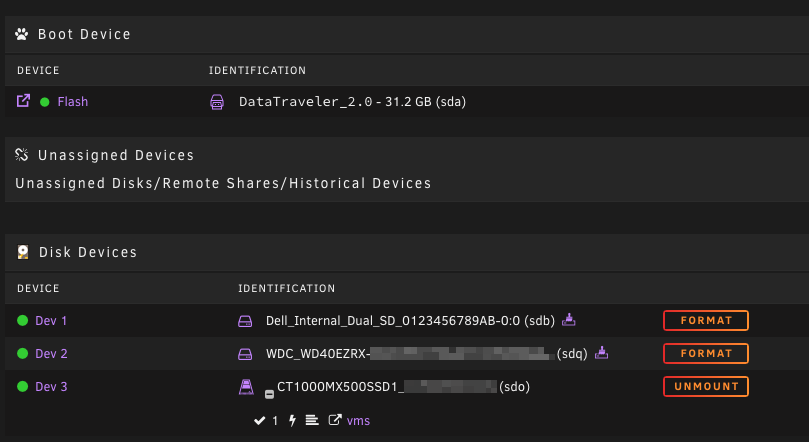
-
I'm using a Dell MD1200 which allows hot-plugging. A failing disk has been removed from the array and is now showing in Disk Devices while the parity rebuilds without it. I've removed the physical drive from its bay, but it's still showing in Disk Devices on the Main screen, with a Format button. How do I get unRAID to refresh its disk list and notice that this drive is no longer attached and should be moved to Historical Devices, without stopping the array or rebooting? There doesn't seem to be a "refresh drive list" button, and clicking on the device name doesn't offer a Remove Device button. Surely, given the amount of hardware that supports hot plugging/unplugging, there must be a way to have unRAID handle this? It's been 30 minutes since I disconnected the disk, and it hasn't even noticed the change yet
-
Thanks — yes, it did finish the parity check successfully; it was about 50% through (and paused during the daytime) when I ran the upgrade — so in progress but paused automatically. UPDATE: While I'm sure I had a notification saying it had finished a couple of days after the reboot, after removing the parity.tuning.restart file I got a notification about half an our later saying the parity check had finished after 9 days, so I guess that gave it a bit of a kick 😁
-
I ran an upgrade to Unraid 6.12.3 while a parity check was running. It paused, and resumed correctly after the upgrade when the resume time came around, and completed successfully after a couple of days. But now, every day at 07:00 (the pause time) I get a Pushover notification saying "Paused. No array operation in progress (0.0% completed)". Is there a way to get rid of this? Would editing the progress.save file be enough to fix it? (Turning "send notifications for pause or resume of increments" off did stop it, but I want those to be on when a check is actually running…) Here's the parity.check.tuning.progress.save file: type|date|time|sbSynced|sbSynced2|sbSyncErrs|sbSyncExit|mdState|mdResync|mdResyncPos|mdResyncSize|mdResyncCorr|mdResyncAction|Description MANUAL|2023 Jul 26 06:34:22|1690349662|1690348691|0|0|0|STARTED|11718885324|129515364|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE|2023 Jul 26 07:00:06|1690351206|1690348691|0|0|0|STARTED|11718885324|334602096|11718885324|1|check P|Manual Correcting Parity-Check| RESUME (MANUAL)|2023 Jul 26 10:24:39|1690363479|1690363219|0|0|0|STARTED|11718885324|369333984|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE|2023 Jul 27 01:00:54|1690416054|1690363219|0|0|0|STARTED|11718885324|6269949784|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE (MANUAL)|2023 Jul 27 01:30:18|1690417818|1690363219|1690416054|0|-4|STARTED|0|6270038284|11718885324|1|check P|Manual Correcting Parity-Check| RESUME (MANUAL)|2023 Jul 27 06:24:22|1690435462|1690435247|0|0|0|STARTED|11718885324|6294077764|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE|2023 Jul 27 07:00:08|1690437608|1690435247|0|0|0|STARTED|11718885324|6526254048|11718885324|1|check P|Manual Correcting Parity-Check| RESUME (MANUAL)|2023 Jul 27 12:30:39|1690457439|1690457240|0|0|0|STARTED|11718885324|6545790780|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE|2023 Jul 28 01:00:48|1690502448|1690457240|0|275|0|STARTED|11718885324|11664698612|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE (MANUAL)|2023 Jul 28 01:12:46|1690503166|1690457240|1690502448|275|-4|STARTED|0|11664770296|11718885324|1|check P|Manual Correcting Parity-Check| RESUME (MANUAL)|2023 Jul 28 06:18:21|1690521501|1690521397|0|275|0|STARTED|11718885324|11674986128|11718885324|1|check P|Manual Correcting Parity-Check| COMPLETED|2023 Jul 28 06:30:16|1690522216|1690521397|1690521948|275|0|STARTED|0|0|11718885324|1|check P|No array operation in progress| And here's the parity.check.tuning.progress: type|date|time|sbSynced|sbSynced2|sbSyncErrs|sbSyncExit|mdState|mdResync|mdResyncPos|mdResyncSize|mdResyncCorr|mdResyncAction|Description SCHEDULED|2023 Aug 21 22:00:07|1692651607|1690521397|1690521948|275|0|STARTED|0|0|11718885324|1|check P|No array operation in progress| PAUSE|2023 Aug 22 07:00:06|1692684006|1692651607|0|0|0|STARTED|11718885324|1975074812|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 22 22:30:08|1692739808|1692651607|1692684006|0|-4|STARTED|0|1975112588|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 23 01:00:27|1692748827|1692739809|0|0|0|STARTED|11718885324|2939569160|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (MANUAL)|2023 Aug 23 01:12:19|1692749539|1692739809|1692748827|0|-4|STARTED|0|2939681292|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 23 22:30:08|1692826208|1692739809|1692748827|0|-4|STARTED|0|2939681292|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 24 01:00:35|1692835235|1692826208|0|0|0|STARTED|11718885324|3717129116|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (MANUAL)|2023 Aug 24 01:30:19|1692837019|1692826208|1692835236|0|-4|STARTED|0|3717246472|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 24 22:30:08|1692912608|1692826208|1692835236|0|-4|STARTED|0|3717246472|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 25 01:00:27|1692921627|1692912609|0|0|0|STARTED|11718885324|4750530368|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (MANUAL)|2023 Aug 25 01:18:23|1692922703|1692912609|1692921628|0|-4|STARTED|0|4750665580|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 25 22:30:07|1692999007|1692912609|1692921628|0|-4|STARTED|0|4750665580|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 26 01:00:25|1693008025|1692999008|0|0|0|STARTED|11718885324|5863042816|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (MANUAL)|2023 Aug 26 01:12:17|1693008737|1692999008|1693008026|0|-4|STARTED|0|5863140880|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| STOPPING|2023 Aug 26 08:46:08|1693035968|1692999008|1693008026|0|-4|STARTED|0|5863140880|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (RESTART)|2023 Aug 26 08:46:09|1693035969|1692999008|1693008026|0|-4|STARTED|0|5863140880|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME (RESTART)|2023 Aug 26 08:57:18|1693036638|1693036628|0|0|0|STARTED|11718885324|5863827540|11718885324|0|check P|No array operation in progress| RESUME|2023 Aug 26 22:30:07|1693085407|1693036628|1693036640|0|-4|STARTED|0|5864121344|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 27 07:00:06|1693116006|1693085407|0|0|0|STARTED|11718885324|9213726048|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 27 22:30:08|1693171808|1693085407|1693116007|0|-4|STARTED|0|9213817272|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 28 07:00:07|1693202407|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Aug 29 07:00:08|1693288808|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Aug 30 07:00:06|1693375206|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Aug 31 07:00:07|1693461607|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 01 07:00:06|1693548006|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 02 07:00:07|1693634407|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 03 07:00:07|1693720807|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 04 07:00:07|1693807207|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 04 13:50:11|1693831811|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| This is with the 2023.09.03 version of the plugin. I've attached diagnostics, and a syslog with logging set to Testing. Thanks! parity.txtcelestia-diagnostics-20230904-1400.zip
-
Ah, there's the problem. I was still running unRAID 6.9.2. Although 6.12 is still only in the RC stage — but at least I'm now on 6.11.5. Not sure why unRAID stopped telling me there were updates available, but thanks for reminding me 😁
-
Is there a way to specify the order in which containers should be backed up? It takes quite a while for the GitLab backup to run, and I'd like to specify that it run first so that it's finished when I need it in the morning. I also have a couple of questions about the settings page: Is it possible to have a "don't show this again" option on the warning popup saying that Docker containers will be stopped before the backup runs and restarted afterwards? I've seen it about twenty times now. I know. It's annoying to have to keep dismissing the alert every time — it reminds me of Windows Vista! The support link at the bottom of the page still goes to the old thread. That means clicking it, then clicking "go to post" on the pinned new thread announcement, then clicking the link to the new thread. It would be much easier if the link could go straight to the new thread, possibly with a note added saying "an older, read-only, thread is available here"… (Ooh, just noticed one more thing. I have /mnt/user/appdata on an SSD, but I also have /mnt/user/appdata_hd for things that take up too much space for an SSD and don't need the speed. Is there a way to get it to look at both of these? It seems like it can only do one or the other…)





