




mrbens
Members
-
Joined
-
Last visited
Everything posted by mrbens
-
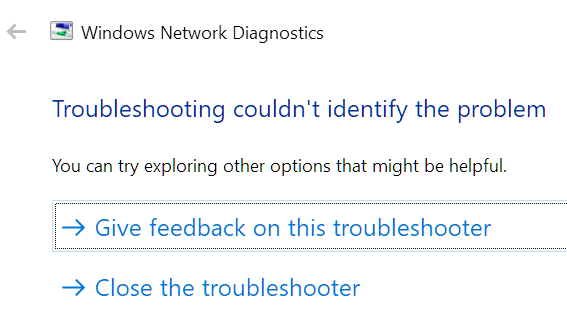
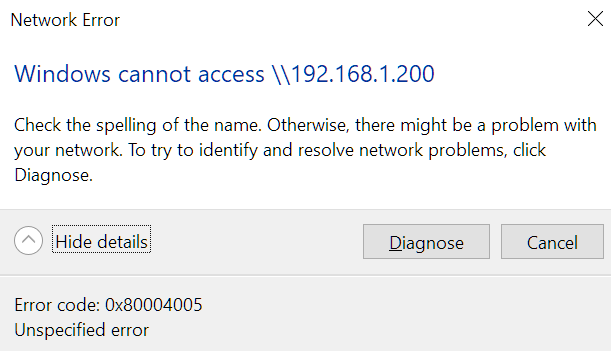
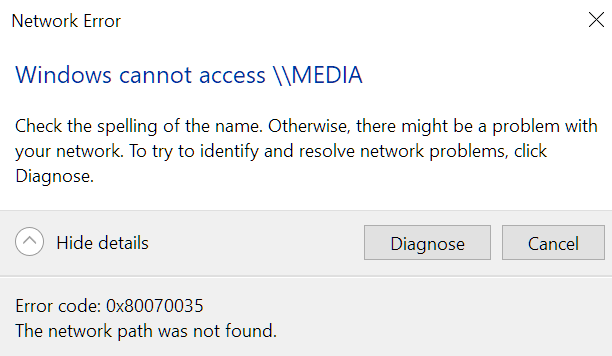
The Nord guys are still unable to find what's causing the issue. NordVPN is just installed on my Windows 10. It's not installed on any of the unraid servers or on my Windows 11 dual boot. From Windows 11 everything still works as normal. It's just on Windows 10 where I ran the network flush that I can't browse to any of the servers any more to access the files or map them as a network drive with a letter. I've just changed the Media server IP to 192.168.1.200 in my router and rebooted the server to see if the IPs were causing the issue somehow since the network flush. It's up again with 192.168.1.200 which I can ping from my Windows 10 PC and can browse to the GUI by both hostname http://media/ and the new IP http://192.168.1.200/ with NordVPN connected and not connected. I can ping it ok and ssh on with the new IP address. Ping statistics for 192.168.1.200: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 0ms, Maximum = 1ms, Average = 0ms Linux 6.1.82-Unraid. root@Media:~# But still can't browse to the server in Windows Explorer by typing \\192.168.1.200 when connected or disconnected from the VPN. Clicking Diagnose doesn't find any issues. I think I'm going to have to reinstall Windows 10 unfortunately. I've uninstalled NordVPN again, ran a network reset as advised by Aria AI but hasn't helped and still can't browse to the servers in Explorer Network or by typing the IP. Can get on the GUIs ok still and ssh on by IP. I can download files from the server over the GUI, but can't connect to any server in Windows Explorer. Anyone have any suggestions?

-
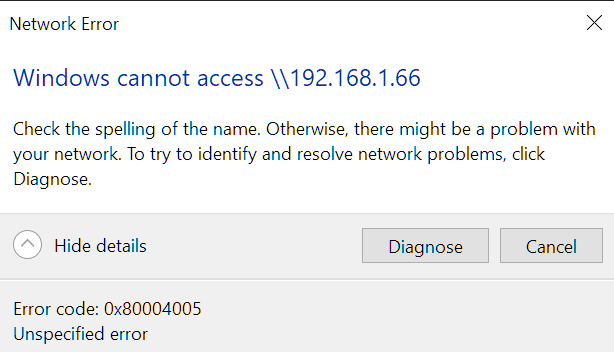
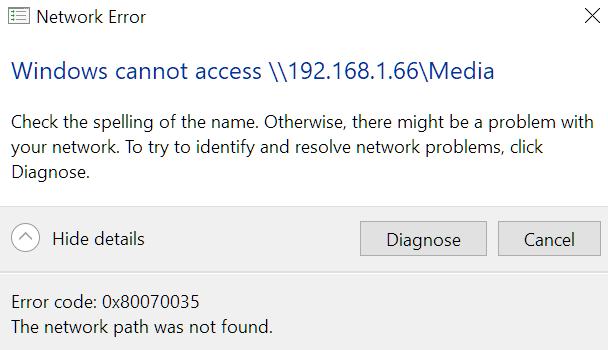
Advice from Nord is that the servers will only be accessible by their IP and not by hostname when on the VPN. I'm still unable to browse to the servers in Windows Explorer by using the IP unfortunately, even with NordVPN uninstalled. And unable to re-map the drives by IP as I'm still getting network path not found. I can get on the GUI ok of all 3 servers by either hostname or IP. I can ping the hostname and IP of all 3 servers. Ping statistics for 192.168.1.66: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss) All on same subnet. I've rebooted my router again and no change. The PC and servers get powered down overnight so have all been power cycled. Checked and made sure the credentials were saved in Windows credential manager for both hostname and IP of all 3 servers. All 3 servers are still accessible fine on my dual boot Windows 11 install which I haven't installed NordVPN yet. I can browse to the servers by IP or hostname in Windows Explorer ok there. In my main Windows 10 I've just reinstalled NordVPN. Made sure kill switch is off and appear invisible is off in case that was causing the issue somehow even with it uninstalled. But still can't access any of the 3 servers in Windows Explorer by IP since the NordVPN network flush 2 days ago. Anyone know what may be causing the issue please?
-
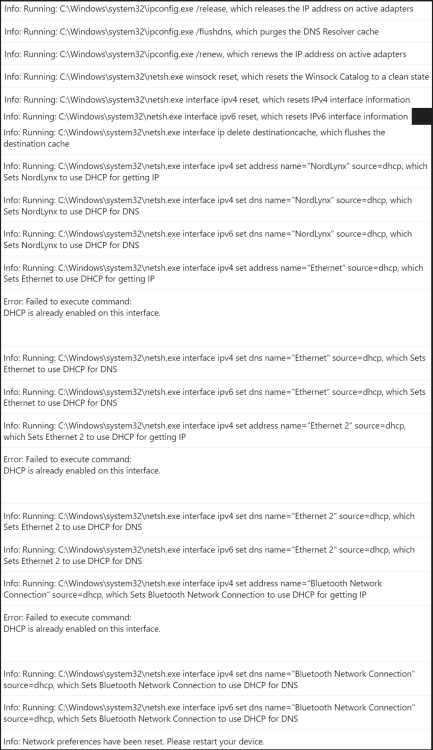
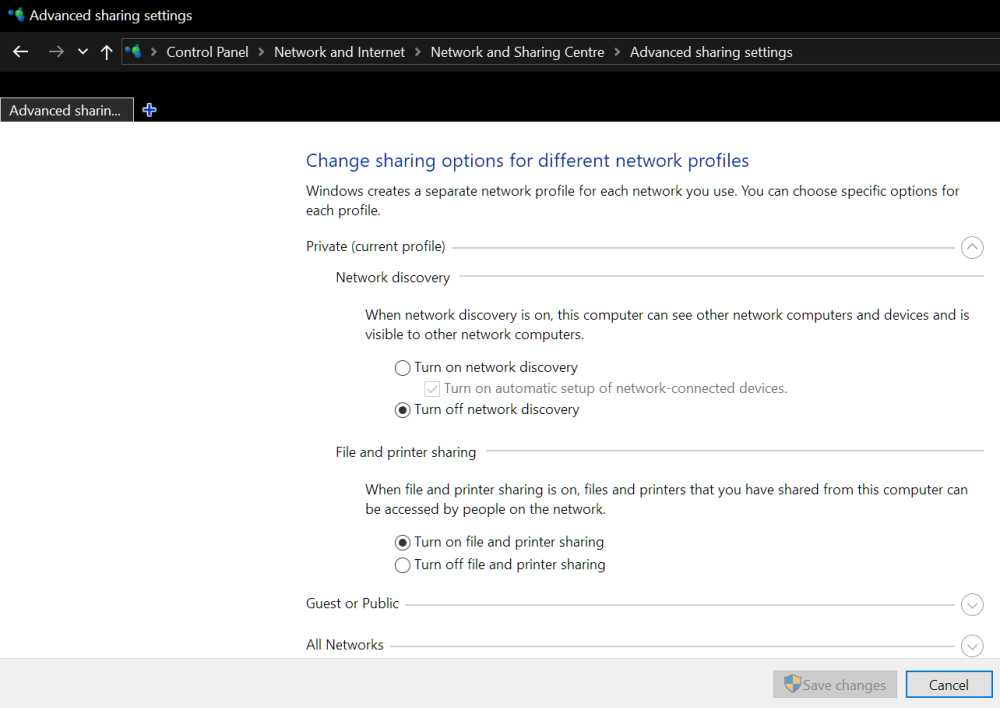
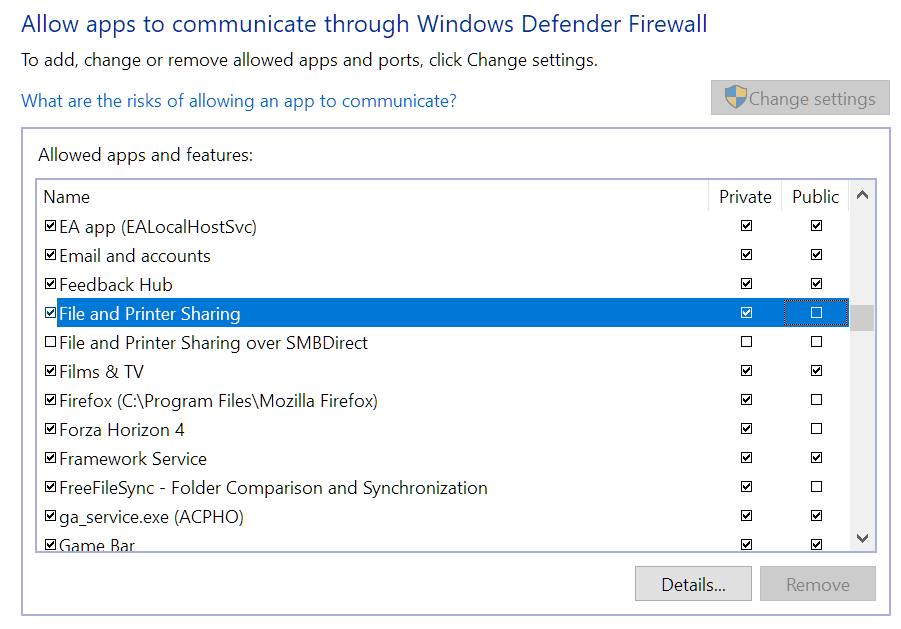
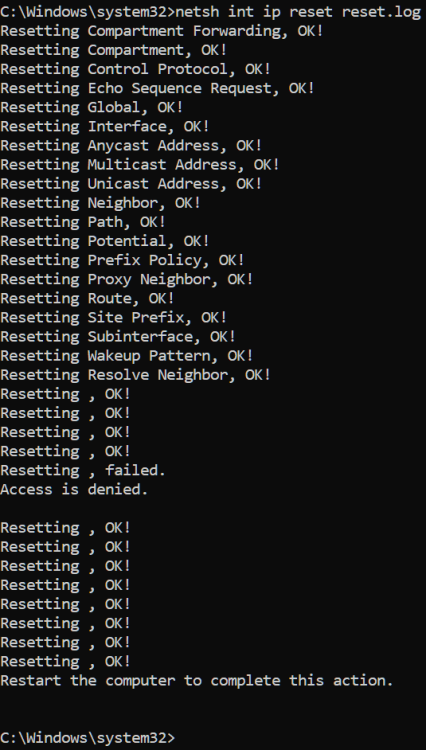
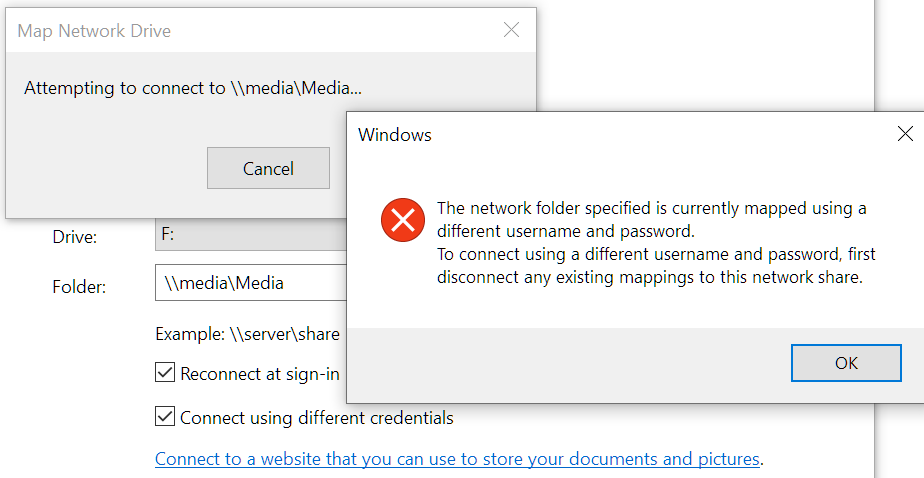
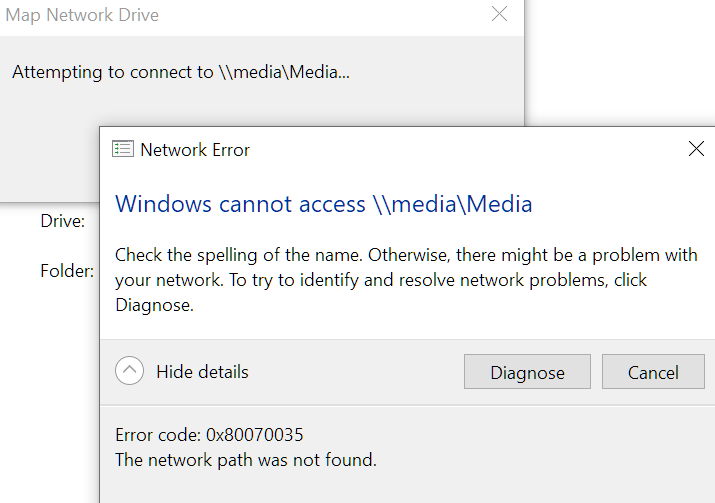
Just got NordVPN 4 days ago and it has been causing issues accessing my 3 unraid servers on the LAN when connected to the VPN. All are on version 6.12.9. The first day when installing it and connecting to the VPN it was just the Backup server I couldn't access at first in Explorer or GUI by hostname. Adding Windows Explorer to the NordVPN exclusion list fixed that. I could still access all my mapped drives mapped by server hostnames. I don't have any mapped for the Backup server. When I booted up my PC and servers the next day, all the mapped network locations were down and couldn't access the servers in Windows Explorer Network as it states network path not found. Also couldn't browse to the GUIs by hostname, only by IP. Disconnecting the VPN allowed access again. The router still showed the correct IP to hostname mappings. Tried NordVPN Network Flush tool which does the following commands. After rebooting my PC, I could access the mapped shares and server GUIs again by hostname and all seemed ok. The next day when booting the same happened again and was fixed by the Network Flush again. Then yesterday when booting the same happened, but unfortunately the Network Flush didn't fix it and has stopped me being able to access any of the servers in Windows Explorer after rebooting my PC. All 3 servers show up in Windows Explorer Network, but say network path not found when clicking into them. Even after uninstalling NordVPN and rebooting I still cannot access any of the servers in Windows Explorer, but strangely can still get to the GUIs by hostname. No issues in the syslogs on any. I dual boot and have my main setup as Windows 10 which had NordVPN installed where I can't access any of the servers now. The same servers are still accessible in my Windows 11 install which I haven't installed NordVPN on, so it doesn't seem to be an issue server side. I've unmapped F: to try remap it to see if this helps, but I can't remap it now in Windows Explorer or cmd due to the network path not found issue. Tried mapping by both hostname and IP and neither work. Servers are pingable by IP and hostname. C:\Windows\System32>ping 192.168.1.66 Pinging 192.168.1.66 with 32 bytes of data: Reply from 192.168.1.66: bytes=32 time<1ms TTL=64 Reply from 192.168.1.66: bytes=32 time<1ms TTL=64 Reply from 192.168.1.66: bytes=32 time<1ms TTL=64 Reply from 192.168.1.66: bytes=32 time<1ms TTL=64 Ping statistics for 192.168.1.66: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 0ms, Maximum = 0ms, Average = 0ms C:\Windows\System32>ping media Pinging media.home [192.168.1.66] with 32 bytes of data: Reply from 192.168.1.66: bytes=32 time<1ms TTL=64 Reply from 192.168.1.66: bytes=32 time<1ms TTL=64 Reply from 192.168.1.66: bytes=32 time<1ms TTL=64 Reply from 192.168.1.66: bytes=32 time<1ms TTL=64 Ping statistics for 192.168.1.66: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 0ms, Maximum = 0ms, Average = 0ms Tried to remap again just now and got an error about credentials. Removed the saved credentials in control panel but still get this error: Rebooted my PC, router and servers. Disabled Acronis antivirus and didn't help. Restarted TCP/IP NetBIOS Helper service but didn't help. Tried Reset TCP/IP and didn't help: netsh int ip reset reset.log Also did these, but these weren't needed before and didn't help: Changed Group Policy to enable insecure guest logons. (Computer Configuration\Administrative Templates\Network\Lanman Workstation) Enabled SMB 1.0 in Windows Features and rebooted. Turned on network discovery and saved changes, but when clicking back in it's always off again. Enabled public in file and printer sharing in Defender firewall (screenshot was before clicking public and saving changes) Network adapter on my PC is still set to Private. Tried everything I could find online, but still can't access the servers. Internet connection and everything else seems to be fine still, just can't access my servers any more. I've attached diagnostics from my main server, but not sure if it will be useful. Would anyone be able to offer some assistance please? Also emailed the details to Nord yesterday, but not sure how long they take to respond or if they'll be able to help. Thanks media-diagnostics-20240411-1827.zip

-
If you first move all the data from the emulated disk so that it's completely empty, you can then use the new config tool to remove the disk from the array and let parity rebuild itself. If you select 'Preserve current assignments' when doing the new config it keeps all the same list of disks. So you can just remove the emulated disk and don't need to worry about re-assigning each of the others into the same slots as they are using now. https://docs.unraid.net/unraid-os/manual/tools/#new-config Make sure you have definitely moved all the data off the disk to other disk(s) first before running the new config tool, as it will invalidate parity and means you can't access the emulated data any more.
-
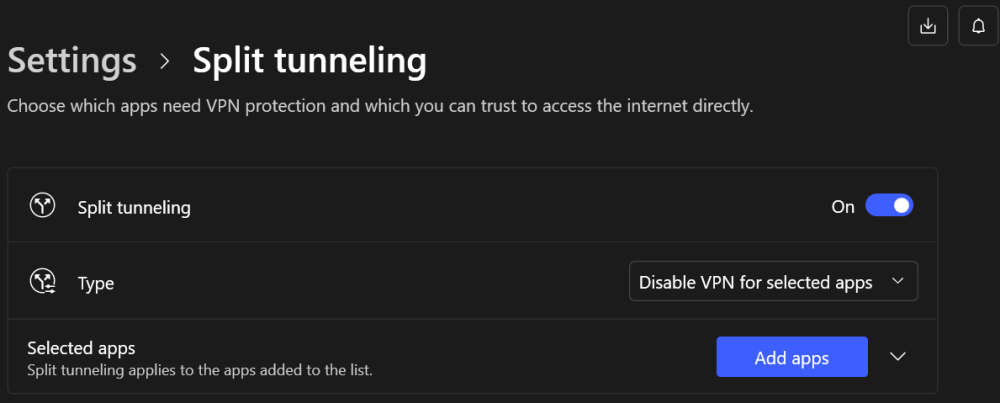
Just got NordVPN and had this same problem, but strangely just on one of my three Unraid servers. When NordVPN was on I could browse the GUI of two servers by hostname, but one server GUI was only accessible by IP and not hostname and also couldn't browse to the server in Windows Explorer Network. Any mapped network shares (I map them by hostname instead of IP) were still accessible for the other two servers. I don't have any mapped shares for the server that wasn't accessible. My router still had the IP to hostname mappings for all three servers. Found a fix by disabling the VPN for Windows Explorer after enabling Split tunneling and I can now browse the server in Windows Explorer Network and also access the GUI by hostname. Click Add apps:

-
Thank you. Swapped out disk 14 for a spare disk I was going to use for backups and moved it to another server to try a Preclear. With all the read errors during the parity-sync, does that mean there's likely to be corrupt files when disk 14 gets rebuilt from parity?
-
Extended SMART test didn't go too well. Got to around 70% and now the disk has been error disabled after a further 1024 errors. This is about the 8th disk recently to fail. Really don't know what's going on. Attached diagnostics. Please advise if there's anything else to do, but guess it'll need replacing. Thank you. tower-diagnostics-20230121-1623.zip
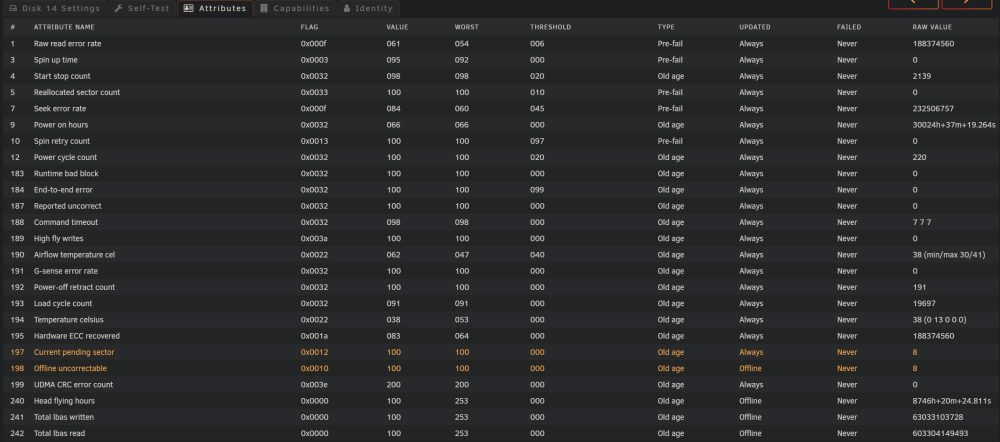
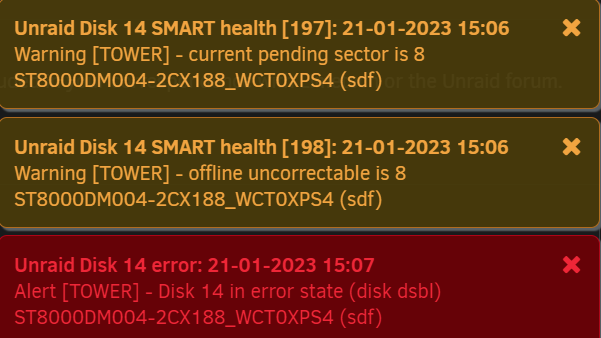
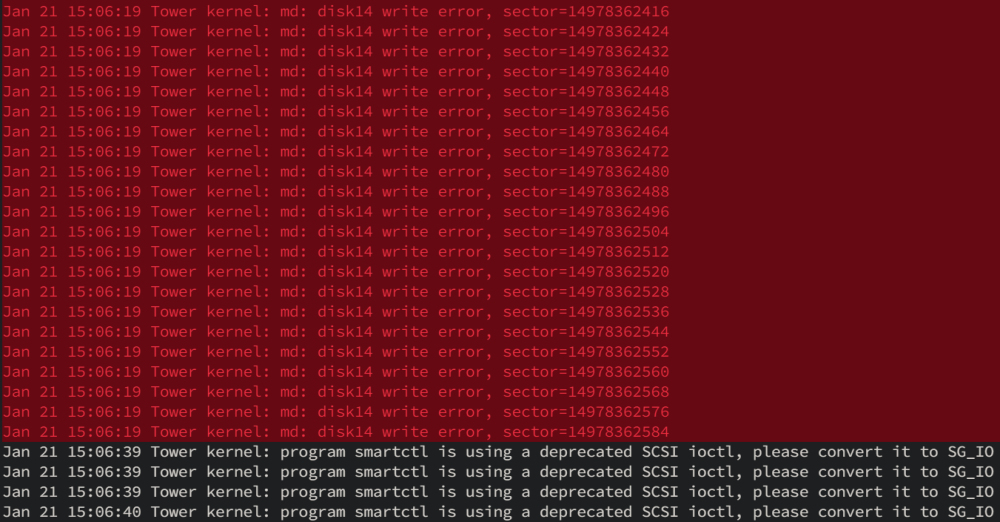
-
Thanks for all the help lately buddy
-
Thank you.
-
Another day, another disk failure. Not having the best luck lately. Moved an 8TB disk from my main server to new HP Gen10 Plus Microserver to Preclear to re-use. The disk has been working fine in my main server for years. It had 73 historic UDMA CRC error count already, but as far as I'm aware that's more a cable issue and not anything to get too worried about. Preclear was going fine until about 60% into the post-read when it failed due to reported uncorrect, current pending sector and offline uncorrectable SMART errors. Attached diagnostics. Please advise if there's anything I should do or if the disk will likely need disposing of. Thank you. backup-diagnostics-20230120-1855.zip
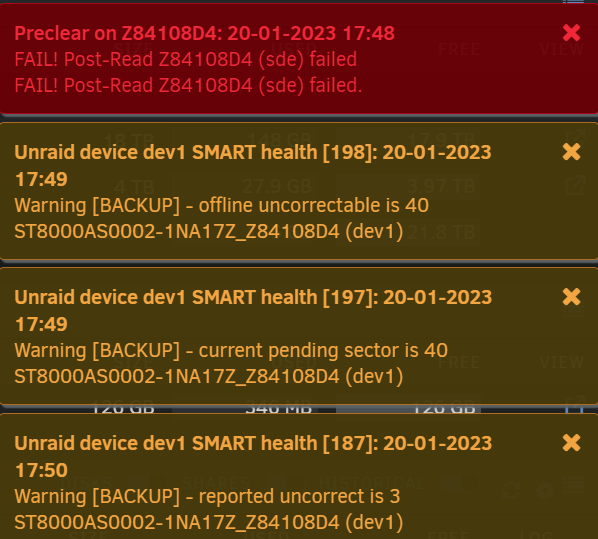
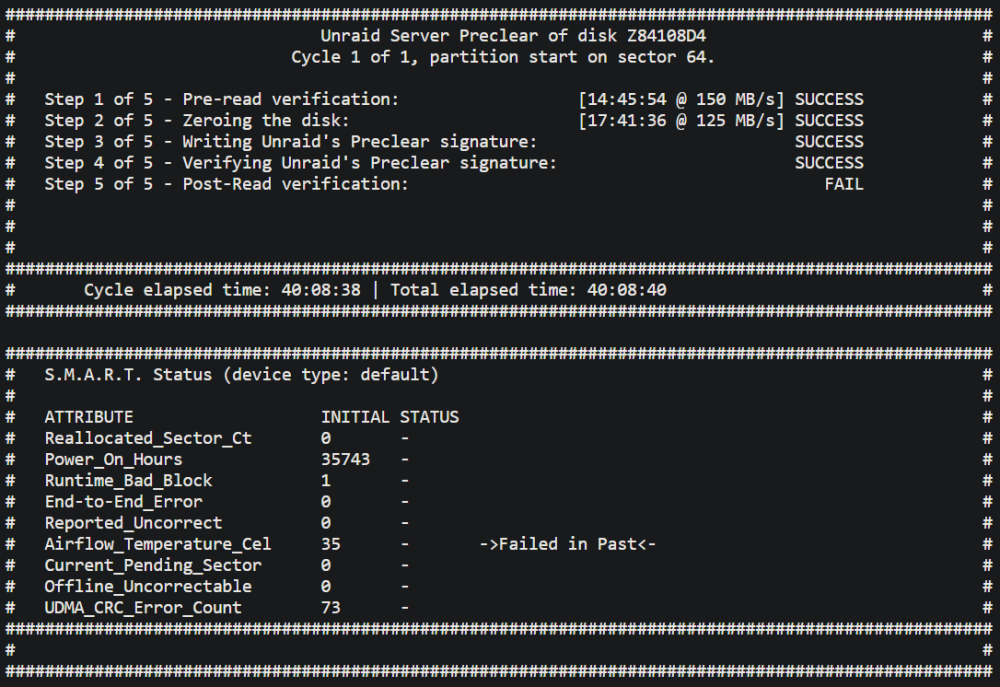
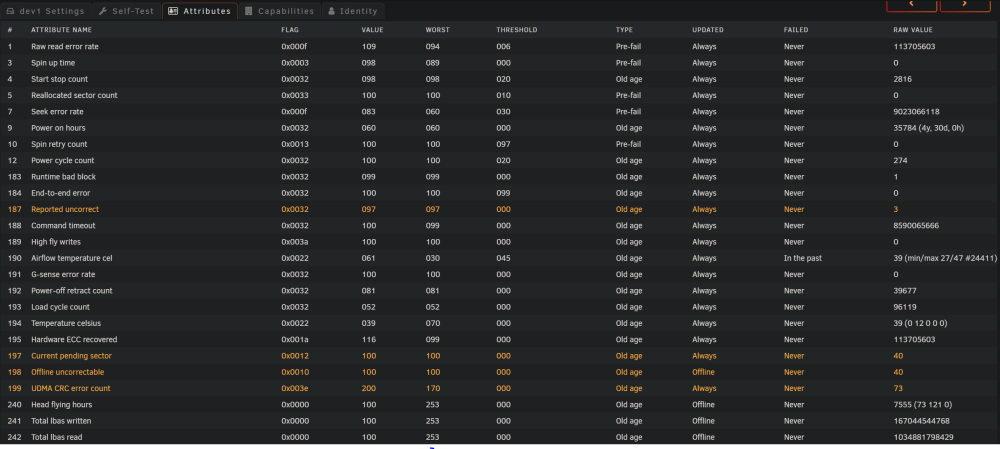
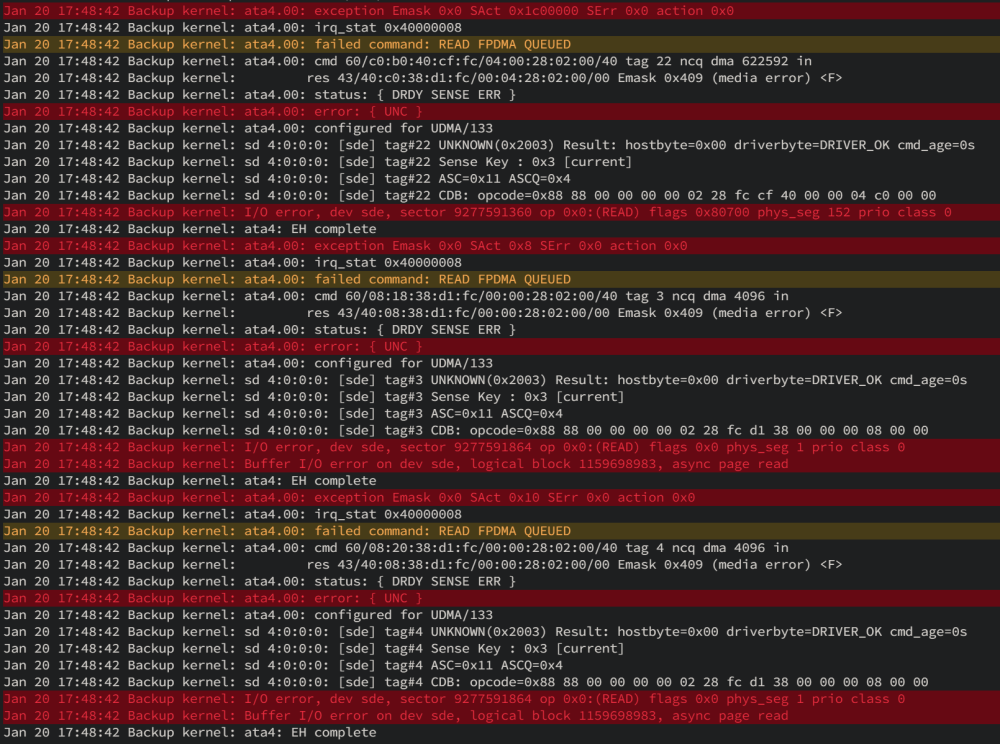
-
Thanks trurl. Parity has about an hour left to finish syncing, then I'll start the extended SMART test. No further errors luckily. Is it worth doing another parity check after the SMART test?
-
Thanks. How do you remove disks without invalidating parity please?
-
Hi trurl, thanks for the reply. I did New Config since I was removing a disk to move to another server and also removing 3 disks that had either died or SMART errors were incrementing that I'd copied the data off (https://forums.unraid.net/topic/133224-6115-disk-9-disabled-after-1175-errors/). Is that the correct way to remove disks from the array? Had a few other changes to make at the same time as removing the disks, so since I needed to do New Config sorted it all at once to let parity rebuild: Added second parity. Added a new data disk. Moved a disk physically in the server and on the GUI to another slot. Cables for disk 14 seem securely in. Is there anything you recommend I do with disk 14 such as extended SMART test or check filesystem? When the parity sync finishes, should I do another parity check to see if it completes without errors?
-
Installed a second parity disk yesterday and the parity sync is currently at 46%. Just got home to see disk 14 has had 327,424 read errors. Doesn't look to be any serious SMART errors. It's connected to a Broadcom 8 Port 6Gbps SAS 9207-8i SGL PCI-E Host Bus Adaptor. Doesn't seem to be any issues with the others disks connected to the controller. Bit worried if it fails as I have no parity at the moment and have had a few disks fail recently. Attached diagnostics. Please advise. tower-diagnostics-20230119-2218.zip
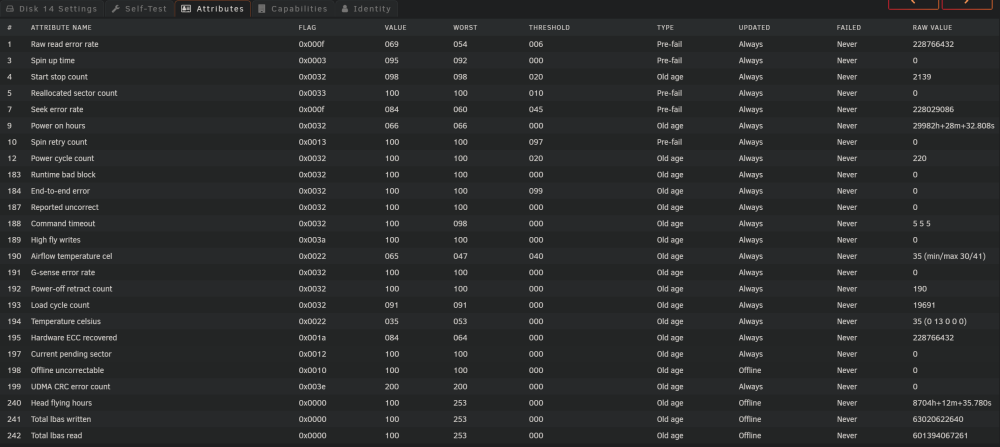
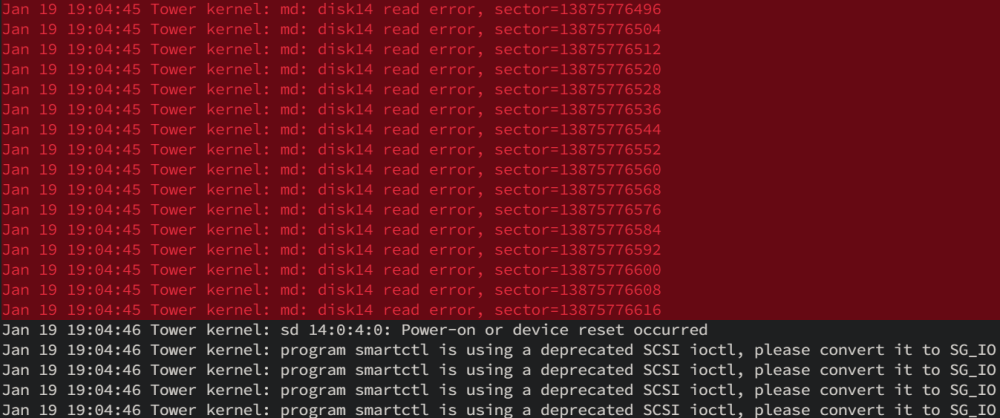
-
Managed to move most data off the 3 disks. Luckily didn't lose anything important. It was getting a bit scary with all the errors on disk 6 which made it slow to copy the data off disks 6 and 9! Probably got some corrupt files, but luckily the disks are in a share of unimportant files. Currently trying to erase and clear them to dispose of, but 2 of them are taking a very long time due to the errors and keep pausing temporarily. Top one says 35MB/s but only does that for a few seconds before pausing for a while. Is it worth skipping the pre and post read on them, or is it recommended to leave them all to finish normally? The bottom disk is erasing at a really slow speed. Guess there's nothing I can do about that.
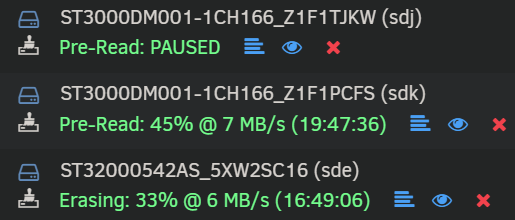
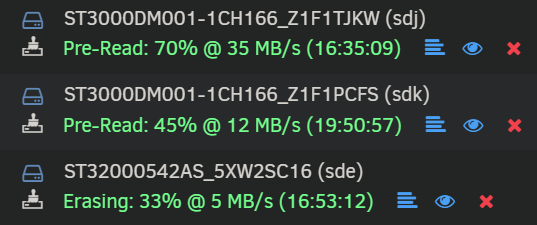
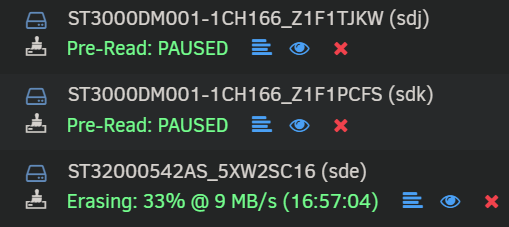


-
Thank you. I'm running it with --rebuild-tree now as it suggested on the read only check. Hope all goes well.
-
Used the rsync command below to copy 8TB disk 3 (resierfs) to 16TB disk 2 (xfs), so I can move disk 3 to another server, but got an error at the end: rsync -avPX /mnt/disk3/ /mnt/disk2/ sent 7,049,131,125,720 bytes received 195,551 bytes 61,352,544.89 bytes/sec total size is 7,035,745,316,299 speedup is 1.00 rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1336) [sender=3.2.7] Think it's just 13 GB that wouldn't copy, but struggling to find how to check the previous errors to see which files(s) were affected. How do I check this please? The following lines repeated many times in the syslog which seem to be related: Jan 12 02:32:32 Tower kernel: REISERFS error (device md3): vs-5150 search_by_key: invalid format found in block 4027868. Fsck? Jan 12 02:32:32 Tower kernel: REISERFS warning: reiserfs-5090 is_tree_node: node level 966 does not match to the expected one 2 There's still 1.5TB free on disk 2. Attached diagnostics. ------------------------------------------------------------------------------------------------------------------------- Currently in the process of converting all my disks to xfs. I'll be adding a new 18TB disk into the disk 3 slot once the 8TB has been removed. Is it better to format the existing resierfs 8TB in slot 3 to xfs, then swap it out for the new 18TB or use New Config to remove the 8TB and add the 18TB into the same slot? I'd think it's best to convert the 8TB to xfs first so just that empty disk has to rebuild instead of having to rebuild the parity leaving the array unprotected for a couple of days but just want to double check. Thank you for any assistance. tower-diagnostics-20230113-1101.zip
-
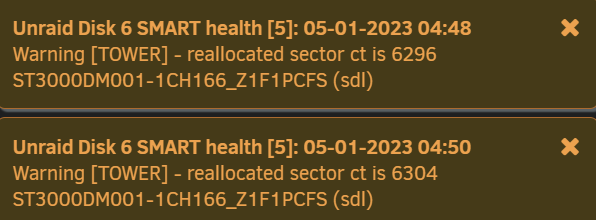
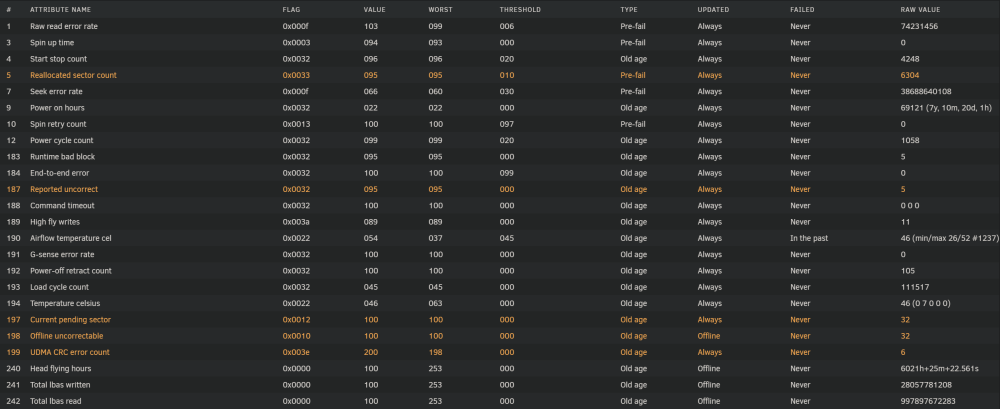
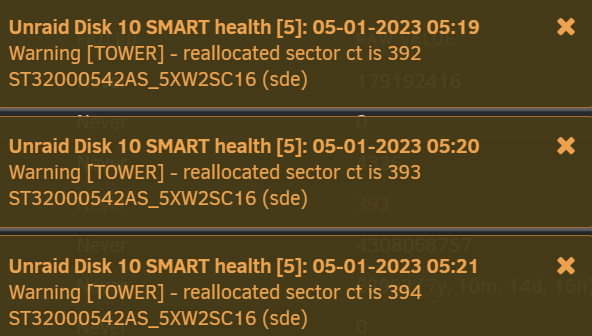
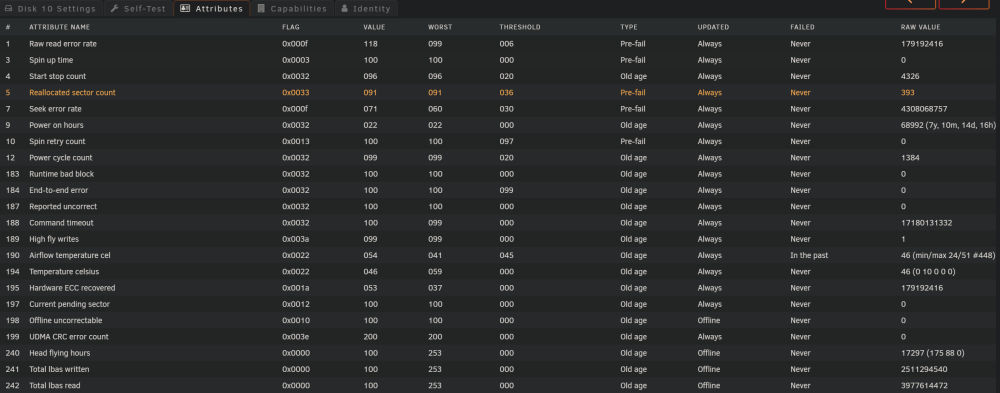
Stopped the short SMART test of disk 6 and the rysnc speed improved again. 1,211,924,480 11% 23.21MB/s 0:06:17 After disk 9 has finished copying to disk 1, I could copy disk 10 and then disk 6 to disk 1 too. Disks 6, 9 and 10 are only small old 3TB and 2TB luckily, so don't mind removing them from the array in case they die soon. Disk 10 now on 760 reallocated sectors. Disk 6 hasn't increased from 6304. Stopped the extended test too and rysnc speed briefly went as high as 49MB/s but then stayed around or under 18MB/s on big files since then. For peace of mind I'd rather copy off all the data quicker and can test them later when they are not part of the array. Had 2 disks fail at the same time before and lost one of them completely, the other I could save a lot with ddrescue but it took months and had a lot of corrupt files.
-
Thanks JorgeB. I've got an extended test running now. itimpi just realised I had notices and warnings disabled and just had notifications for OS updates and alerts. I've enabled them now and worryingly it looks like disk 6 is also having issues with reallocated sectors. I'm currently running rsync -avPX /mnt/disk9/ /mnt/disk1/ to do New Config to remove disk 9 as I've got space on disk 1 for now, but worried about doing that in case disk 6 fails and would leave me without parity to rebuild it. Disk 10 now too: Currently up to 592 reallocated sectors 30 minutes later. No new errors on the Main page. Attached new diagnostics. What would you recommend please? rsync speed has also dropped to under 3MB/s while running a SMART extended test of disk 9 and short test of disk 6. 5,150,177,280 100% 25.63MB/s 0:03:11 (xfr#782, ir-chk=1052/2045) 8,468,856,832 46% 2.60MB/s 1:01:37 It was running about 25MB/s earlier, and I think over 50MB/s previously when copying a different disk to convert to xfs a few days ago when no disks were disabled. I can understand why it's slower now with a disabled disk, but should the SMART checks be slowing it down so much from 25MB/s to 3MB/s? Short SMART seems to be stuck on 90%. Holding off running a test on disk 10 while the server is busy. Once I've finished converting all my disks to xfs I'm adding a second parity as I've had issues with a few disks recently. tower-diagnostics-20230105-0529.zip
-
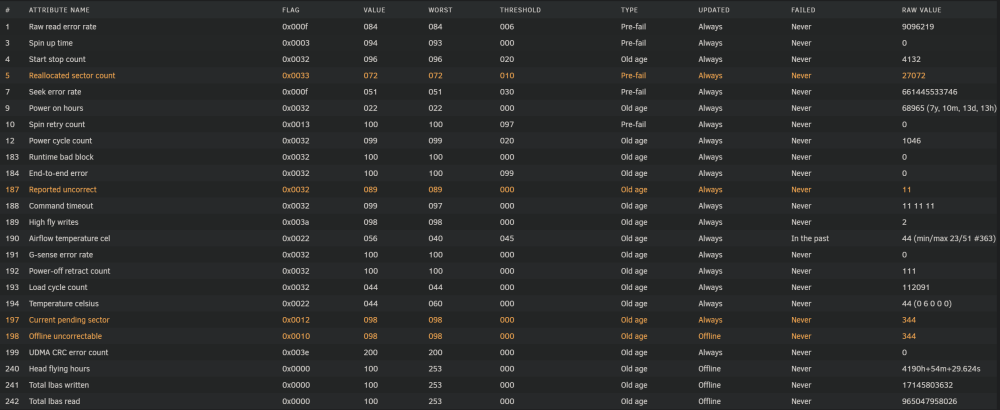
Need some assistance please. Disk 9 has been disabled after 1175 read and write errors. SMART not looking good. Attached diagnostics. Does it look like it'll need binning, or is it worth replacing the SATA cable with a new one and trying a preclear to re-add it? Thanks. tower-diagnostics-20230104-1035.zip
-
Perfect. Thanks again.
-
Thank you, wasn't aware of that. Shall I stop the rebuild and use new config to revert to the 16TB? Would it work If I did this: Re-add the 16TB in unused disk 17 slot after doing new config. Format the 18TB as xfs and set it as disk 1 to copy all data from 16TB disk 17 to it. Then follow the mirror method in https://wiki.unraid.net/File_System_Conversion to format 16TB as xfs and so on for all my disks to eventually get them all to xfs?
-
Hi, I have a problem when trying to upgrade a 16TB disk to an 18TB disk. Shortly after the rebuilding started, the new 18TB disk 1 was marked as read only. Dec 18 09:50:47 Tower kernel: REISERFS error (device md1): vs-4010 is_reusable: block number is out of range 3794305055 (99614707) Dec 18 09:50:47 Tower kernel: REISERFS (device md1): Remounting filesystem read-only It's only showing as 408 GB. Shows ok under the Dynamix Stats page. I have a share that just uses disk 1 mapped to a drive letter, and it shows empty, but when clicking in all the files appear to be there still. Had a disk made read only before and followed https://wiki.unraid.net/index.php/Check_Disk_Filesystems#Drives_formatted_with_ReiserFS_using_unRAID_v5_or_later Disk 1 is still rebuilding onto the 18TB. I haven't done anything with the previous 16TB yet, so could revert to that if needed. Should I let it finish rebuilding onto the 18TB disk and then check the file system? Attached diagnostics. Planning on converting them all to xfs soon. Thanks. tower-diagnostics-20221219-0930.zip


-
I've replaced the SATA cable with a new one and running Preclear again. 30 minutes in and no errors so far. S.M.A.R.T. Status (device type: default) ATTRIBUTE INITIAL STATUS Reallocated_Sector_Ct 0 - Power_On_Hours 32197 - Runtime_Bad_Block 3 - End-to-End_Error 0 - Reported_Uncorrect 0 - Airflow_Temperature_Cel 25 - ->Failed in Past<- Current_Pending_Sector 0 - Offline_Uncorrectable 0 - UDMA_CRC_Error_Count 37 - SMART overall-health self-assessment test result: PASSED
-
The disk just popped back into the Unassigned Devices & Preclear list and is no longer in the Historical Devices list. Preclear had note "Error encountered, please verify the log". I'd tried to run a SMART test after the preclear had began before. Not sure if that's what caused it to fail. After the preclear there were lots of repeated logs like: Dec 7 02:12:20 Tower kernel: ata8: SATA link down (SStatus 0 SControl 300) Dec 7 02:12:14 Tower kernel: ata8: limiting SATA link speed to 1.5 Gbps Then finally: Dec 7 02:12:54 Tower kernel: ata8: SATA link up 1.5 Gbps (SStatus 113 SControl 310) Ran a SMART short self test now which says: Last SMART test result: Completed without error SMART self-test history: No self-tests have been logged. [To run self-tests, use: smartctl -t] Trying preclear again but getting errors again: Dec 7 02:22:40 Tower kernel: print_req_error: 864 callbacks suppressed Dec 7 02:22:40 Tower kernel: blk_update_request: I/O error, dev sdr, sector 66372608 op 0x0:(READ) flags 0x84700 phys_seg 168 prio class 0 Does it look like the disk will need replacing please?





































