




BF90X
Members
-
Joined
-
Last visited
-
Long story short, the parity appears to have gone back to normal. I tried so many different things, I have no idea what fixed it. -Updated BIOS -Updated to UnRaid 6.10.1 -I tried one of the drives, it originally did not work. (Now that it's working, I did try the other drive instead) So that might be it? -Tried to boot UEFI instead of legacy (Literally hours trying but no luck) -At some point, I wasn't even able to boot with legacy due to the AER issue. I added the following to the syslinux, nvme_core.default_ps_max_latency_us=5500 pci=nommconf Already had, pcie_aspm=off I am still seeing the "Hardware error from APEI Generic Hardware Error" but not as much. The only major issue I am seeing for now is that one of the 2.5 inch drives on one of the ZFS pools is failing. Waiting for the replacement. prdnas002-diagnostics-20220524-1235.zip
-
Thanks for sharing that information, I will follow the steps on that link. Ohhh, I guess that's why core 6 is maxed out. Everything else seems to be working properly. I run docker containers and a coupe of vm's without much issues. One of the steps I tried to troubleshoot the parity rebuild issue was to do a new config. Also, pre-cleared the drives as well. I rebooted on safe mode and try the rebuild as well but got the same speeds. Did not look at the CPU usage when I did that though.
-
Thanks for the input @ChatNoir & @JorgeB I updated the firmware of the HBA and added a temporary fan for additional cooling, ordered a few items to come up with permanent solution to ensure the HBA has better cooling. After making these changes, I am still seeing the same issue. Might not be related but at some point after upgrading to 6.10 I notice I was getting a lot hardware errors. May 23 05:45:24 PRDNAS002 kernel: {20}[Hardware Error]: Hardware error from APEI Generic Hardware Error Source: 512 May 23 05:45:24 PRDNAS002 kernel: {20}[Hardware Error]: It has been corrected by h/w and requires no further action I looked around online and found that someone had to run the following command to eliminate them, setpci -v -s 0000:40:01.2 CAP_EXP+0x8.w setpci -v -s 0000:40:01.2 CAP_EXP+0x8.w=0x2936 Attached is the new diagnostics. Appreciate all the help. prdnas002-diagnostics-20220523-1207.zip
-
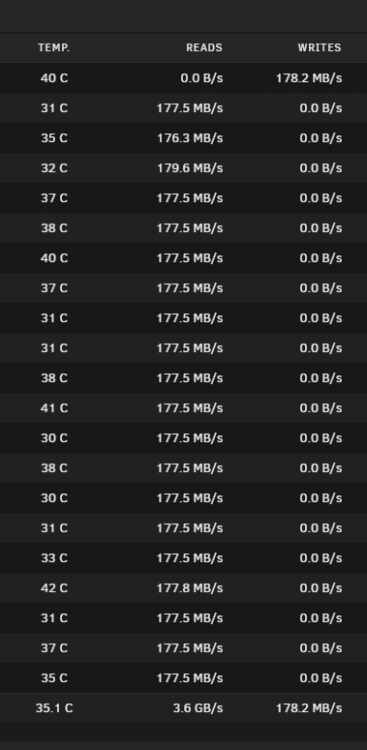
Hello, I was wondering if someone could help me identify why my parity rebuild is slow. Some of the last changes were, - Installed a lsi sas3224 about 5 months or so ago - Replacing all my Seagate drives (Data Drives) I am getting roughly 10-20 MB/sec on the rebuild as of right now. I also have three 3 separate zfs pools, need to replace a drive on the hdd pool. The other two ssd and nvme are working properly. Attached is the diagnostics. prdnas002-diagnostics-20220523-0047.zip
-
Hello, I am experiencing issues with buffering as well. Media doesn't appear to start buffering, stop it and try again and then it would sometimes work. Is there anyway possible to revert back to a previous release of the docker container?
-
I was asked to submit this bug report after speaking with Jonp from support thread.
-
Hello, I really need help after numerous issues with one of my unraid servers. I have tried everything I can think of so far but so far nothing has worked. Randomly, one or many of my drives do not mount properly after inputting the encryption key. This causes me to have to reboot the server and then my parity drives generate errors which then I have to rebuild the parity drive(s). Sorry for reaching out but thus is really frustrating. Thanks in advance. prdnas002-diagnostics-20210929-1030.zip
-
Thanks for the feedback, I appreciate it. It seems like that didn't work for me. It actually caused one of my parity drives to generate a significant amount of errors due to the reboots I had to do to get the drives to mount properly.
-
Having the same issue over and over again. Were you able to find a fix? It's starting to get really frustrating.
-
-
Hello, I am experiencing the same issue. I even started from scratch but now I have even more movies where is able to see the directory but not the files within those directories.
-
Quick Question, Has anyone else been getting this error message? 2019-12-26 14:31:35,294 DEBG 'radarr' stdout output: [Warn] HttpClient: HTTP Error - Res: [GET] https://radarr.aeonlucid.com/v1/update/master?version=0.2.0.1450&os=linux&runtimeVer=5.20.1: 404.NotFound {"errorMessage":"Latest update not found."} 2019-12-26 14:31:35,298 DEBG 'radarr' stdout output: [Error] TaskExtensions: Task Error
-
My aplogies, please disregard. It was my pfblocker causing the issue. Rebooting after update now.
-
Having issues upgrading. Getting the following message, plugin: installing: https://s3.amazonaws.com/dnld.lime-technology.com/stable/unRAIDServer.plg plugin: downloading https://s3.amazonaws.com/dnld.lime-technology.com/stable/unRAIDServer.plg plugin: downloading: https://s3.amazonaws.com/dnld.lime-technology.com/stable/unRAIDServer.plg ... failed (SSL verification failure) plugin: wget: https://s3.amazonaws.com/dnld.lime-technology.com/stable/unRAIDServer.plg download failure (SSL verification failure)
-
Was there an update recently? It seems to be working properly again and I haven't changed anything.

