




randomusername
Members
-
Joined
-
Last visited
-
Hi all, For a good while now I have been having files and folders occasionally change permissions and ownership. It started as just a sub-folder of YouTube content downloaded with the Tubesync container, but today I noticed that the entire Media share had been changed to read only (or at least, the Media folder on the array). There are also folders within the appdata folder which are read only - pihole and icloudpd are both read only, with pihole owned by 'root' and icloudpd owned by '???' Assuming it's a docker container that's doing this, I don't know how I would go about figuring out which container it is. My thought is Binhex Krusader, because it has access to all files and folders, but I really don't know what I'm looking for. Any help would be appreciated, diagnostics attached. wessex-diagnostics-20240308-1908.zip
-
Thanks Jorge. It was exactly as you said, I did another balance to RAID1 but the same thing happened, so I backed up and reformatted using Squid's guide and now the balance status shows as: btrfs filesystem df: Data, RAID1: total=245.00GiB, used=243.63GiB System, RAID1: total=32.00MiB, used=64.00KiB Metadata, RAID1: total=1.00GiB, used=737.62MiB GlobalReserve, single: total=288.52MiB, used=0.00B btrfs balance status: No balance found on '/mnt/cache' Current usage ratio: 99.4 % --- No Balance required So that all seems to have gone well. Thanks very much for your help.
-
It might have been the wrong thing to do, but after a while I was concerned at the ~200 million writes on the cache disks so I clicked 'cancel' on the balance operation. Since seeing your post, the array rebooted successfully, but predictably the balance operation did not continue (presumably because I had already cancelled it). Diagnostics attached as you requested, but I'm guessing you will suggest clicking 'balance' again? And if so, should it be 'full balance', or 'convert to RAID1 mode'? wessex-diagnostics-20240208-1505.zip
-
I added a second cache drive to create a cache pool. Balance has been running for the last ~10 hours, initially it progressed, but for at least 8 hours it has been stuck at: Balance on '/mnt/cache' is running 634 out of about 729 chunks balanced (635 considered), 13% left Diagnostics attached, the logs look like the same commands are repeating over and over but I'm not sure how to interpret this. Any help would be appreciated, I don't know where to go from here. Edit: I'm on Unraid version 6.12.6 wessex-diagnostics-20240206-2216.zip
-
Hi all, This is an odd one, every few months my server will be (mostly) uncontactable. It's as though the ethernet connection just stops. Can't connect to Plex at all, at home or away from local network. Unraid connect thinks the server is offline. Not contactable via IP on the local network, though it does respond to ping. Strangely, Wireguard seems able to see and connect to the server, but once connected it is not able to transfer any data. Previously I have had to reboot the server and just accept the consequences, however a few weeks ago I was away for the weirdness and by the time I got home the server was contactable again (4-5 days total outage, it seems like). So I was able to copy the system diagnostics, which are attached. I would really like for this server to be bulletproof, so if anyone can tell what's causing this problem I would be very grateful. wessex-diagnostics-20231124-2227.zip
-
plex.tar.gz/mnt/user/appdata/plex
-
Thanks for the information, the next reboot was fine.
-
Ah, it seems as though Krusader was just being very slow to calculate the Plex folder size - it now says that Plex is 42.6GB compared to 50GB for the plex.tar.gz. Perhaps that is normal? Screenshots attached.
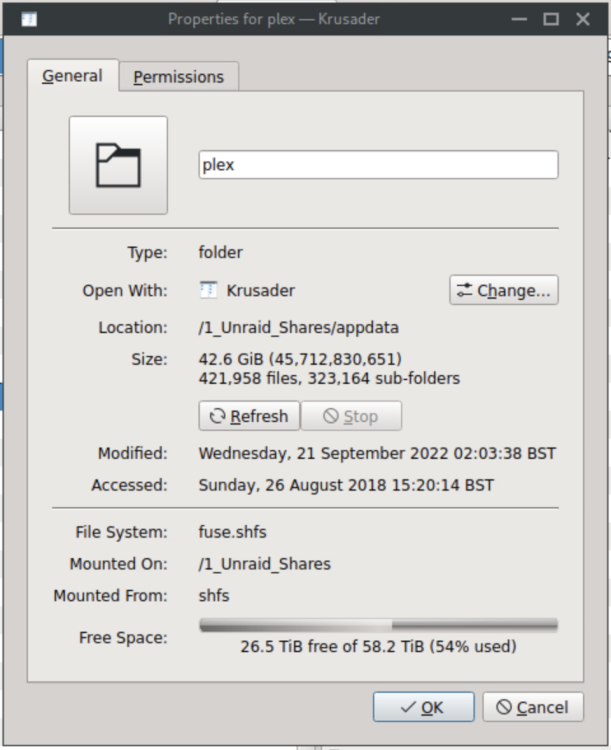
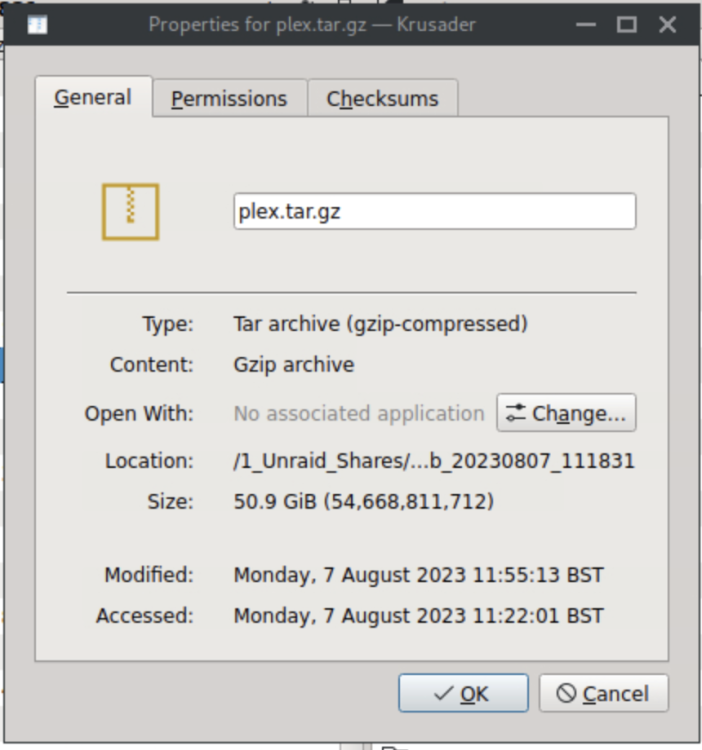
-
Hi, I have just got round to moving from ca.backup2 to this plugin, thanks very much for taking over. In my first backup, Plex took 30 minutes to backup and then 30 minutes to verify, and the output file is 50GB compared to the Plex appdata folder being 25GB. Everything else seemed to go smoothly, but the slow speed and huge size of the Plex backup has me concerned. Do you have any ideas? ab.debug.log ab.log
-
Hi all, I just upgraded to 6.12.3 and then rebooted the server. When it came back up I immediately got a message saying 'unclean shutdown detected' and that unraid will start a parity check. I have not noticed anything strange in usage recently, though during the upgrade process it did take a good few minutes to write to the flash drive, which (from memory) it doesn't usually do when upgrading. Diagnostics attached, though since this happened after a reboot I'm not sure how much use they'll be. Hopefully I've just done something silly and easy to fix. I have recently made the Plex container wait 60 seconds before starting up - I was having problems with it starting up too early and not being accessible outside the network (though I can't remember exactly what caused this, it was sporadic). So perhaps Plex is taking too long to stop as well, and that's timing out the 'clean' reboot process? wessex-diagnostics-20230731-1227.zip
-
I'm trying to get a Sab -> Handbrake workflow going. Currently Sab's 'completed' folder goes into Handbrake's 'watch' folder, but then Handbrake is beginning to transcode before Sab has fully unpacked. Is there any way for Handbrake to ignore certain folders, so it waits until the /_UNPACK folders have gone?
-
This worked perfectly, thank you!
-
Entirely fair, thank you for the support. My unmanic.db file in appdata/unmanic/.unmanic/config is now 5.5GB. For ease of appdata backups, is it okay to delete the unmanic.db file? I know I will lose the history, but is there anything more important/dangerous that will be lost? I assume unmanic won't reconvert the already converted video and audio.
-
Bump, is there a better place to ask for support than this?
-
Hi all, I recently upgraded Radarr for the first time in about six months, and the GUI wouldn't load. Looking at the log, it seems like the whole container is failing. If anyone can figure out what's wrong I'd be grateful. Log attached. radarr-2022-07-30T16-07-21.log


