




vw-kombi
Members
-
Joined
-
Last visited
Everything posted by vw-kombi
-
I am a little out of my depth here with what to do. I have my unraid server and other servers on my main LAN - 192.168.1.0/24. I dont have bridging set. I have three VLANS also : 10.10.10.0/24 (IOT), 10.10.20.0/24 (Home deices, iphones etc), 10.10.30.0/24 (XBoxes with open networking) and 10.10.40.0/24 (Cams). I use unify equipment and have firewall rules from the vlans to allowed servers/ports on the main lan. The issue : I would like to use a container - WatchYourLan. These apps can ONLY find devices on my main network where unraid is - i.e 192.168.1.0/24. I believe it uses an arp ping, which cannot traverse the network, even though unraid and the container can ping these devices on the vlans. I have done some googling and it suggests I need to enable bridging on the nic, and maybe add vlans on unraid network config br0.10, br0.20, br0.30 and br0.40. And I suppose change the unify port for the unraid server to allow all (rather than block all). I do not want to give these VLAN's IP addresses as the unraid server should not be contactable from the VLANs. Any idea what of the above is needed - or if there is another way I should do it ?
-
Confirmed the Issue I posted is now fixed : Upgraded 7.0.1 to 7.1.1 - Mover then reports no space left on device on my media share - New Issue with Manual Split Level Updated the post.
-
Just posting back that the 7.1.2 update has fixed this issue. I just ran mover after update, after confirming a few 'new' things on the cache drive. While monitoring logs I got the all clear, then checked the cache was clear and the array had the folders/files. May 11 16:36:39 Tower emhttpd: shcmd (125): /usr/local/sbin/mover start &> /dev/null & May 11 16:36:40 Tower shfs: /usr/sbin/zfs unmount 'cache/Downloads' 2>&1 May 11 16:36:40 Tower shfs: /usr/sbin/zfs destroy 'cache/Downloads' 2>&1 May 11 16:36:40 Tower shfs: /usr/sbin/zfs unmount 'cache/EmbyBackups' 2>&1 May 11 16:36:40 Tower shfs: /usr/sbin/zfs destroy 'cache/EmbyBackups' 2>&1 May 11 16:36:40 Tower shfs: /usr/sbin/zfs unmount 'cache/EmbyTranscode' 2>&1 May 11 16:36:41 Tower shfs: /usr/sbin/zfs destroy 'cache/EmbyTranscode' 2>&1 May 11 16:40:15 Tower shfs: /usr/sbin/zfs unmount 'cache/Media' 2>&1 May 11 16:40:15 Tower shfs: /usr/sbin/zfs destroy 'cache/Media' 2>&1
-
I guess its going to bite more people once the use case gets hit - i.e manual split more, and needing to create a folder. Or does the issue hit other split modes too ?
-
To try and prove this, I downloaded a movie for testing, this would need a new folder created, and the file of course. Mover logging is still on. So clicked move and this is now in the log : May 10 20:02:12 Tower shfs: assign_disk: /Media/Movies/M/My Hero Academia - World Heroes' Mission (2021)/My Hero Academia - World Heroes' Mission (2021) - WEBDL-1080p - EAC3-5.1.mkv No space left on device May 10 20:02:12 Tower move: move: /mnt/cache/Media/Movies/M/My Hero Academia - World Heroes' Mission (2021)/My Hero Academia - World Heroes' Mission (2021) - WEBDL-1080p - EAC3-5.1.mkv No space left on device So I think this proves the issue...... If you want the full log : May 10 20:02:11 Tower emhttpd: shcmd (506531): /usr/local/sbin/mover start |& logger -t move & May 10 20:02:11 Tower move: mover: started May 10 20:02:11 Tower shfs: /usr/sbin/zfs unmount 'cache/Downloads' 2>&1 May 10 20:02:11 Tower shfs: /usr/sbin/zfs destroy 'cache/Downloads' 2>&1 May 10 20:02:11 Tower shfs: /usr/sbin/zfs unmount 'cache/EmbyTranscode' 2>&1 May 10 20:02:11 Tower shfs: /usr/sbin/zfs destroy 'cache/EmbyTranscode' 2>&1 May 10 20:02:12 Tower shfs: assign_disk: /Media/Movies/M/My Hero Academia - World Heroes' Mission (2021)/My Hero Academia - World Heroes' Mission (2021) - WEBDL-1080p - EAC3-5.1.mkv No space left on device May 10 20:02:12 Tower move: move: /mnt/cache/Media/Movies/M/My Hero Academia - World Heroes' Mission (2021)/My Hero Academia - World Heroes' Mission (2021) - WEBDL-1080p - EAC3-5.1.mkv No space left on device May 10 20:02:12 Tower move: mover: finished
-
I just turned on mover logging as requested and ran the mover - and the stuff that was there for moving - seemed to work OK. I think the difference is that these things folders were already there - whereas the things with the no space on device are things that is would have had to create folders for ? That is what I am thinking anyway. And I guess it may make sense ? Should be easy to test - have a share to manual, then add something that is new, and see what happens ? Diags attachedtower-diagnostics-20250510-1953.zip
-
I read that, but it did not seem to be exact match.
-
Diags attached.tower-diagnostics-20250510-1412.zip
-
I posted in unraid support - mover no longer working (no space left on device) if you have share split level to manual. I am having to move manually now.
-
No other changes my end. I was able to do a manual move so this is not a space issue. Did a search and it says to review the share level settings. As I am very specific about where I put my stuff on the correct disk in the array, I have my split level set to 'Manual: do not automatically split directories' Has mover changed between these versions ? For background, I have my media share set like this : I keep Disk 2 for the non 4K stuff (movies etc) I keep Disk 3/4 for TV Shows I keep Disk 5 for 4K media so :
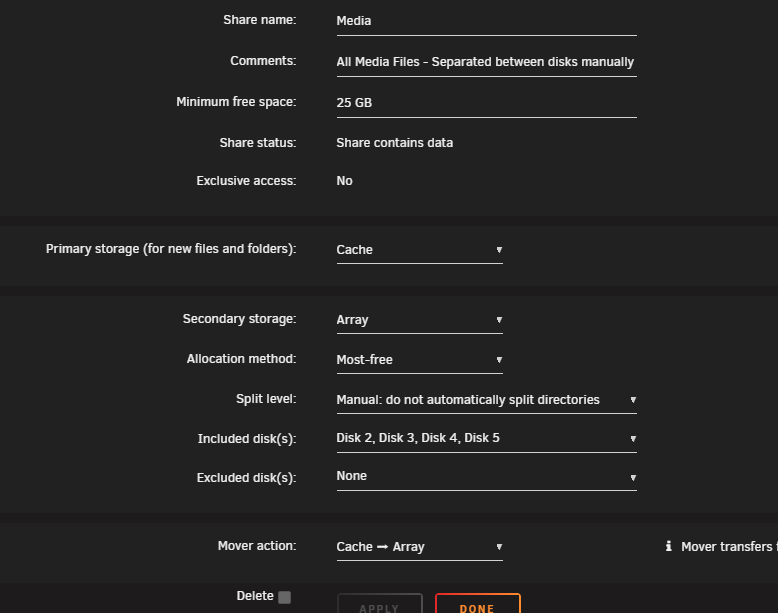
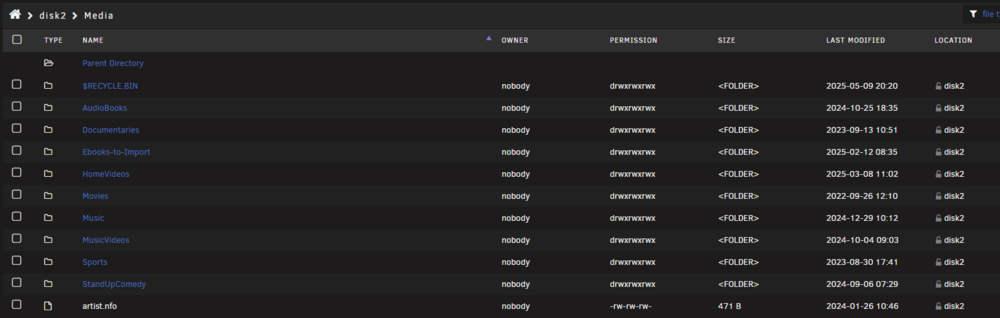


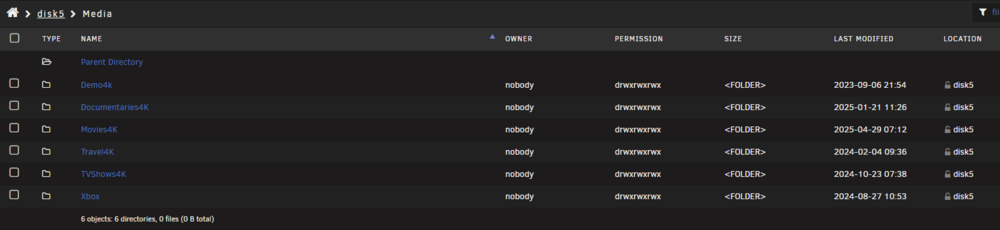
-
Dunno about that - I never did any config to it, or watched any youtubes, just installed it one day, did the setup, then a few days later realised icloudPD container was not working. All other containers were working fine, just not that one. Uninstalled plugin, it works again, I tried installing it again to prove that was it, and it stopped again - never installed it again (I have tailscale with advertise routes on another always on machine (my home assistant and CCTV system) - so its not really needed on unraid.
-
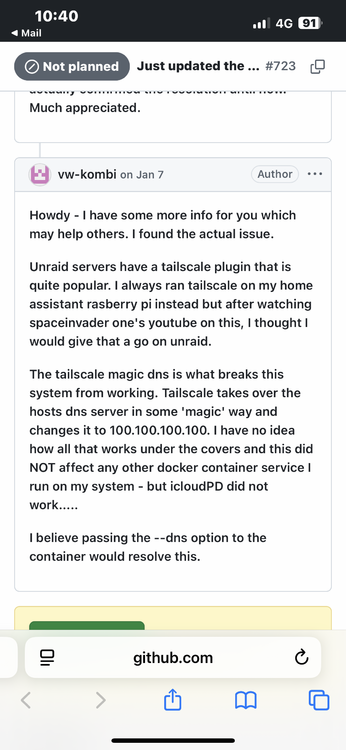
I found where I had this exact same issue. It was with the iCloudPD container. Reason I could not find it here was I posted on their discord support. issue was the tailscale plugin. i uninstalled that and dns worked again. attaching screenshot of my post. Something to do with magic dns.
-
Stop docker, then try the above settings.
-
I remember having something similar for another container. It’s was a while back and not swag. I googled it and maybe I did this - Configure DNS for Docker Containers Docker containers may not inherit the host's DNS settings. To force proper DNS resolution for containers: Edit the Docker daemon configuration file: Go to Settings > Docker in Unraid. Under "Docker custom network DNS server", add 1.1.1.1 and 8.8.8.8. *Sometimes a network reload helps here: /etc/rc.d/rc.docker restart
-
Not seeing this no…..
-
Diags attached : tower-diagnostics-20250413-1621.zip
-
My logs are filling up with this. I suspect this relates to a jellyseer container as that dies a few times a day but I have only now looked back on all the system logs. Apart from just deleting this container and its database, is there anything I should do ? Apr 13 10:47:45 Tower nginx: 2025/04/13 10:47:45 [error] 14141#14141: nchan: Out of shared memory while allocating message of size 11758. Increase nchan_max_reserved_memory. Apr 13 10:47:45 Tower nginx: 2025/04/13 10:47:45 [error] 14141#14141: *10966489 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/devices?buffer_length=1 HTTP/1.1", host: "localhost" Apr 13 10:47:45 Tower nginx: 2025/04/13 10:47:45 [error] 14141#14141: MEMSTORE:01: can't create shared message for channel /devices
-
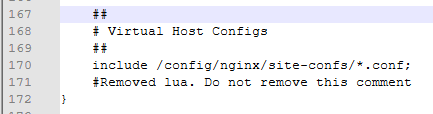
Updated the swag container today, and I get a load of these messages repeated over and over - and while it is started, it does not work. 2025/03/18 07:47:34 [alert] 3024#3024: failed to load the 'resty.core' module (https://github.com/openresty/lua-resty-core); ensure you are using an OpenResty release from https://openresty.org/en/download.html (reason: /usr/share/lua/common/resty/core/base.lua:24: ngx_http_lua_module 0.10.27 required) in /config/nginx/nginx.conf:172 I looked at line 172 that I suppose it is referring to (I am not good with this stuff), and it just has a ')' - so I assume it is that whole section ? Further to this - Editied - I moved in all the sample files and still get this issue........ As I have used nginx, then swag for 10+ years and had a load of my own custom config - so I assume it is in the container itself. FIXED - ok the issue is the crowdsec dockermod for the swag container. ghcr.io/linuxserver/mods:swag-crowdsec If you have the docker mod for this, then this crashes with this error as shown above. I have removed it for now.
-
Just to close this out, I completed a load of data IO things at the same time : Import to immich copy to external disk move stuff around on unraid console. No issues seen, so I suspect the solution given is a fix. Is there an impact of this setting anywhere ? If not, should it not be increased as a default in unraid at install time ?
-
OK - I have done that, restarting array now. Next time I am copying / moving I will place close attention. Ideally an email alert from unraid when all the shares have gone would be a heads up on this. May look at a user script for that.
-
Thanks for that, I need to stop the array to change it, so I will plan for that.
-
I just went through the containers and they are all /mnt/user/xxxxx showing on the dashboard docker tab.
-
It does seem to happen when I am using the unraid file copying thing that’s built in to the interface now. And usually something else (like copying to an external unassigned disk.
-
Hmmm - I dont think I every do that. Is it related to the screenshot I added - showing no disk shares ?
-
Can you explain me those ? user shares I have loads. Not sure what a disk share is though....... If its this, then I am not :










