




vw-kombi
Members
-
Joined
-
Last visited
Everything posted by vw-kombi
-
The unraid connect install has fixed the errors. I wont uninstall it for now - just wont enable the remote access / port forward (I have tailscale and wg for that). May be handy to have another flash backup floating around rather than the manual ones I keep.
-
Rebooted - same issues are seen. I have removed this folder in the plugins also before the reboot - /boot/config/plugins/dynamix.my.servers. Mar 4 12:31:51 Tower nginx: 2024/03/04 12:31:51 [error] 10889#10889: *335 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.1.10, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.7", referrer: "http://192.168.1.7/Dashboard" Mar 4 12:31:56 Tower nginx: 2024/03/04 12:31:56 [error] 10889#10889: *335 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.1.10, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.7", referrer: "http://192.168.1.7/Dashboard" Mar 4 12:32:01 Tower nginx: 2024/03/04 12:32:01 [error] 10889#10889: *335 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.1.10, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.7", referrer: "http://192.168.1.7/Dashboard" Mar 4 12:32:07 Tower nginx: 2024/03/04 12:32:07 [error] 10889#10889: *335 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.1.10, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.7", referrer: "http://192.168.1.7/Dashboard" Mar 4 12:32:12 Tower nginx: 2024/03/04 12:32:12 [error] 10889#10889: *335 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.1.10, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.7", referrer: "http://192.168.1.7/Dashboard"
-
Can’t reboot yet as various things in progress, but plan to do it tomorrow.
-
The unraid upgrade to 6.12.8 fixed the home assistant container to unraid host. It was not working since .4, .6, but now magically the home assistant APC sensors came back to life!!!!!
-
The unraid upgrade to 6.12.8 fixed this issue. It fixed whatever the comms issue was from my home assistant container to the unraid host and so all the apc daemon stuff just started working.
-
Many versions ago I did, but removed ages ago as it offered nothing I did not have with other methods.
-
searched here, found same from Feb. Said to cat /boot/config/plugins/dynamix.my.servers/myservers.cfg and if nothing, delete it. so i did - rm /boot/config/plugins/dynamix.my.servers/myservers.cfg refreshing gui and its still being spammed. Restarting session - still there too - every 5 seconds.
-
It is repeated every 5 seconds......
-
Mar 3 16:56:58 Tower nginx: 2024/03/03 16:56:58 [error] 10907#10907: *240307 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.1.10, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.7", referrer: "http://192.168.1.7/Dashboard" Mar 3 16:57:04 Tower nginx: 2024/03/03 16:57:04 [error] 10907#10907: *240301 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.168.1.10, server: , request: "POST /plugins/dynamix.my.servers/include/unraid-api.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.7", referrer: "http://192.168.1.7/Dashboard" M
-
No worries. Had to push the button in the end. Cancelled the auto parity check. Submitted a new one with corrections. Will monitor.
-
I had home assistant connecting to unraid a while back with the APC deamon plugin - pulling in power used etc etc. I dont want to control it - as HA is docker on unraid anyway. I just want to put in the power used from the integration. I cant remember how I did it. My UPS currently is in stand alone mode. The doco is way too big for me to find out how to do this. Can anyone point me in the correct direction ? Currently like this :

-
Whats this mean - 'he RAM is currently overclocked for your config' My system has not changed in many years - 2019 it was built. No strange changes. I can see how that memory issue wold be an issue now. Unless it s faulty - so memtest I guess.
-
Its not mover - its the parity check.
-
No matter how many times I click to cancel parity check, it will not. It is not really running as disks are spun down as normal. System is all operational. I would like to kill the check from command line or something ? Any ideas ? Diags attached. tower-diagnostics-20240227-1044.zip
-
am i right that the original instructions for the docker ip access as per below are no good anymore with the later unraid release : This is achieved by adding the tunnel endpoint subnet to the gateway (router) which provides the regular access to remote destinations. By default Unraid uses the 10.253.x.x/16 subnet for tunnel endpoint assignments. This subnet needs to be added to the router and points to the LAN (eth0) address of the Unraid server. Below is an example of static routes added to a Ubiquiti router (other brands should offer something similar). It is also needed to disable the "Local Server uses NAT" setting (switch on advanced view).
-
I got an error overnight that I don't understand as the containers are stopped, then backed up : [24.01.2024 04:23:06][❌][UptimeKuma] tar verification failed! Tar said: tar: Removing leading `/' from member names; mnt/user/appdata/uptimekuma/kuma.db.bak20230205165300: Contents differ Is this simply a verification failed message ? or something more sinister ?
-
11 days since I posted this, and no support for it. I would think this was a simple answer that many people would know. I dont know if this is a stupid post and hence met with disdain by anyone reading it - or there is just little support here in this forum. I guess no point in posting again to move this to the top - as no answers in 11 days, then I assume this is dead.
-
Anyone ? https://www.trendmicro.com/en_za/research/19/l/why-running-a-privileged-container-in-docker-is-a-bad-idea.html So if a bad idea - what is the unraid process to fix the issue in post 1 - that was introduced with the latest unraid release ?
-
Surely someone in the docker engine shouldknow the nswer to this - Or have I posted in the wrong section ?
-
Anyone ? I dont think it is ideal to have a container set an privileged is it ?
-
Can I delete them?
-
I have a home assistant container and I am passing through a usb device that talks to a current cost envir unit. I added a device like such : /dev/serial/by-id/usb-Prolific_Technology_Inc._USB-Serial_Controller-if00-port0:/dev/currentcost But this only works if the container is set to Privileged mode. Is this by design ? I was on 6.12.4 and this 'hack' I fond on the support forum worked : Add this to the post arguments - && docker exec -u root homeassistant sh -c "chmod a+rwx /dev/currentcost" But now I upgreaded to 6.12.6, this again needs to be Privileged mode as this hack no longer works.
-
Back again on this - I just upgraded unraid from 6.12.4 to 6.12.6 and the home assistant docker container lost access to its USB controller. I changed it to priveleged and it is working again. So did the upgrade to 6.12.6 break this 'process' of adding this to the post arguments : && docker exec -u root homeassistant sh -c "chmod a+rwx /dev/currentcost" I dont want to have to run this as privelaged if I dont have to......
-
So - todays fun and games - I came home to my kids complaining emby stopped working. unraid gui not there, no dockers were working. I could ping the unraid server fine, and I could ssh into it so I googled here some command line safe shutdown stuff. Here is what I did if someone can comment if this is correct of not : diagnostics - it just sat there, waited 5 mins before killing it. Tries a restart of the gui with this : /etc/rc.d/rc.php-fpm restart but only got this : Gracefully shutting down php-fpm ................................... failed. Use force-quit Starting php-fpm [ERROR] Another FPM instance seems to already listen on /var/run/php5-fpm.sock [ERROR] FPM initialization failed failed Tried a Stop array with this : #!/bin/bash emcmd cmdStop=Stop (but it just sits there for ages - aborted) ps -ef and top were showing docker containers running still Tried Stop all dockers : docker stop $(docker ps -q) It just sat there - and still the docker containers running Tried Gracefull shutdown from command line : Powerdown (ran, but could ping it forever) - so nothing happened. Shutdown : - ran a shutdown now got this - which looks like it is doinmg the usual Broadcast message from root@Tower (pts/0) (Thu Jan 11 15:16:15 2024): The system is going down to maintenance mode NOW! But - In top and ps-ef, I can still see some dockers...... At this stage i had exhausted my limited knowledge and my known command list above, so I have to hold the power button and get the usual parity rebuild. I dont have diags (due to above), but can anyone tell me a process I should have followed in the above ? The only change I have done recently (yesterday) is to stop the VM engine (as I moved homeassistant and shinobi to docker containers), and I changed the CPU pegging so all containers have the right three pairs and emby has 4 pairs, and the first pair are not set to any (kept for OS - but there is no CPI isolation. Like this :
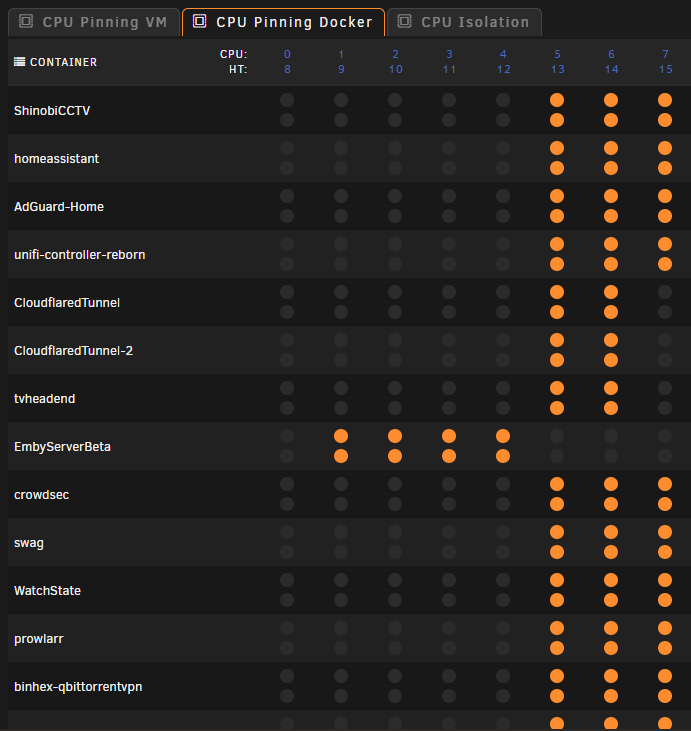
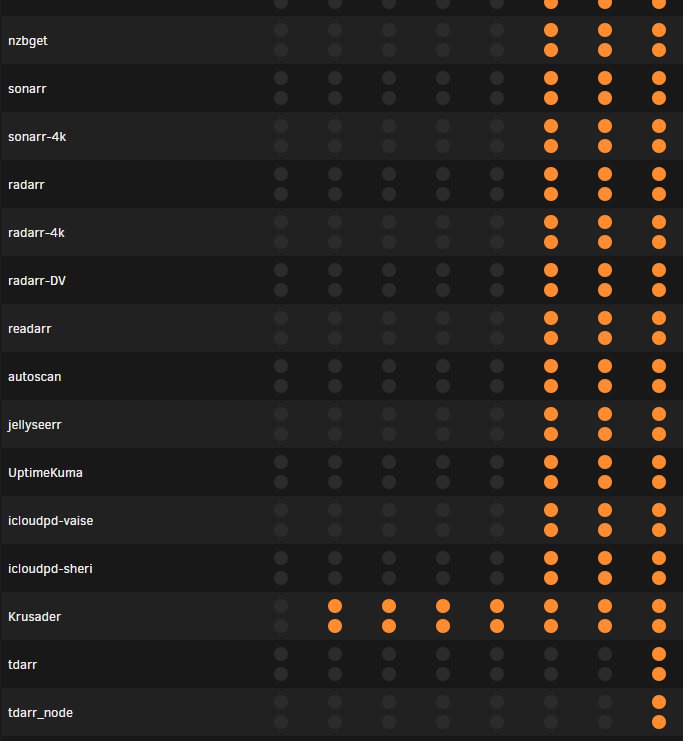
-
OK - I had a strange server issue (posting that next), but took the downtime as an oportunity to re-do the upgrade. This time, it went in all fine and started up all fine with no issues to date - I then installed that realtek driver which was on my list to do. I was a little worried as it was taking a long time on the zipping of the USB, but it seemed to get there in the end. I had a look in my flash saves and there is a load of diags in the logs going back forever - I am going to erase those. There is also a number of FSCK files in the root of it. I am thinking I will re-build this USB and set it up again sometime......



